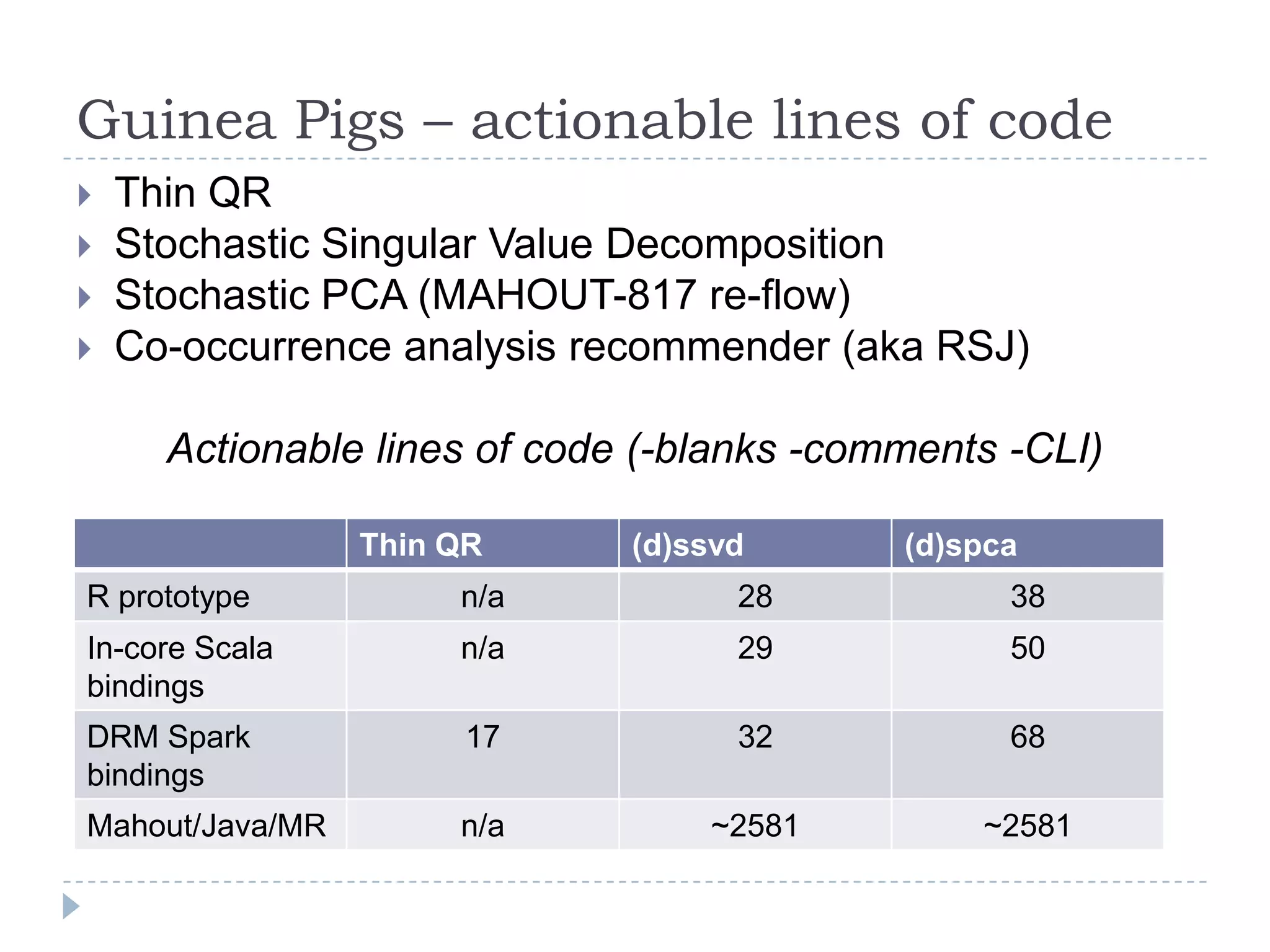
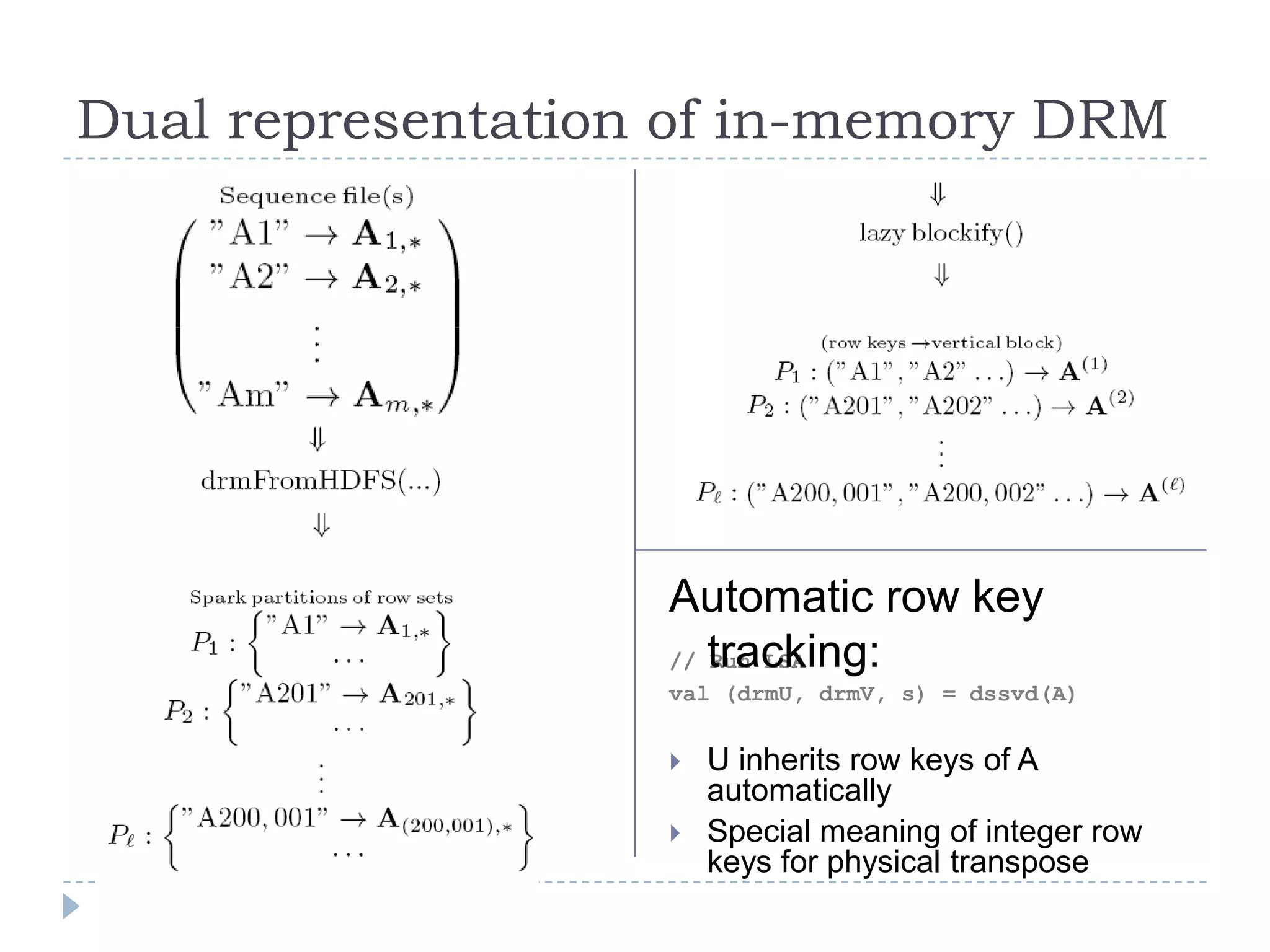
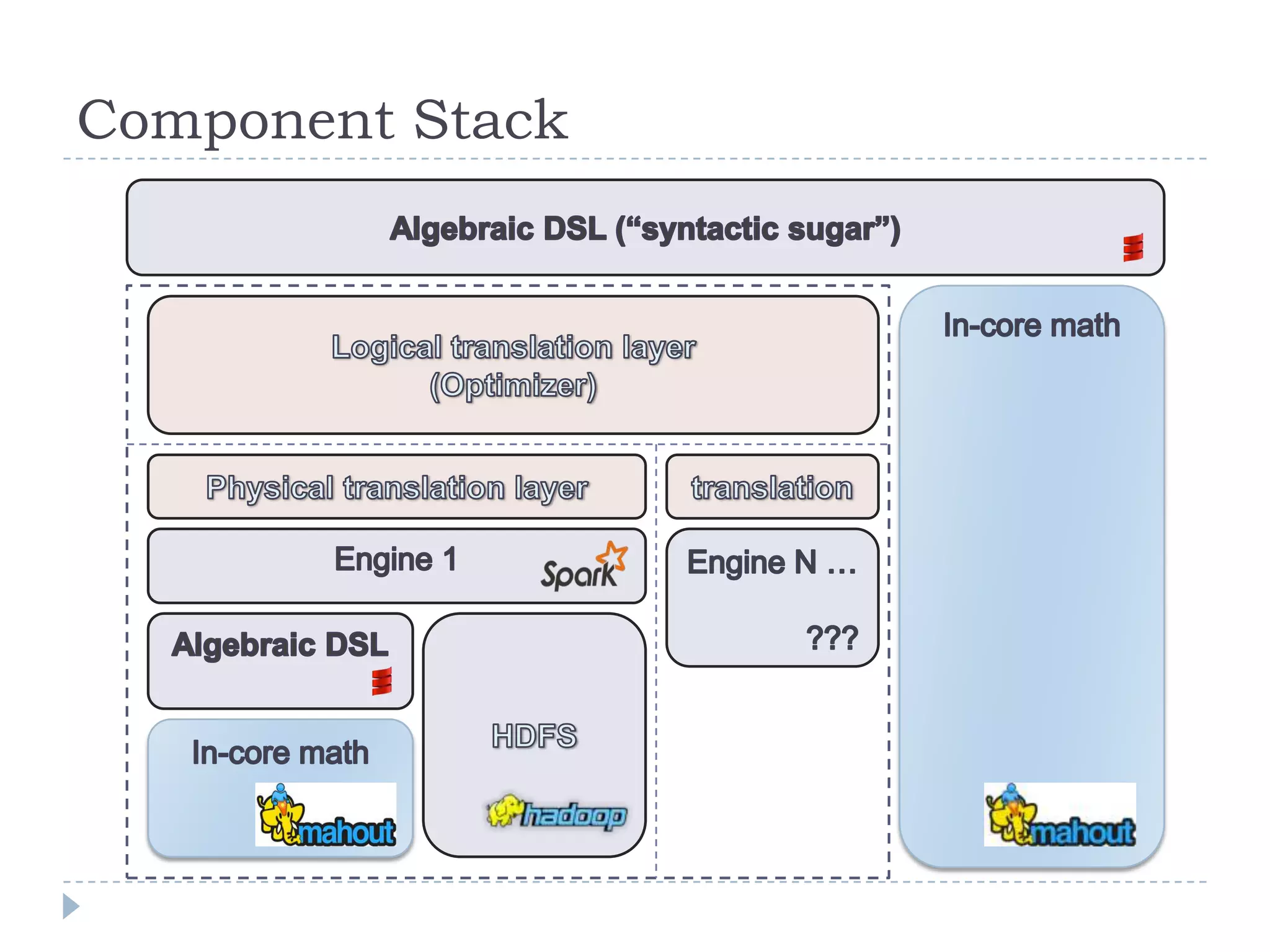
This document introduces Mahout Scala and Spark bindings, which aim to provide an R-like environment for machine learning on Spark. The bindings define algebraic expressions for distributed linear algebra using Spark and provide optimizations. They define data types for scalars, vectors, matrices and distributed row matrices. Features include common linear algebra operations, decompositions, construction/collection functions, HDFS persistence, and optimization strategies. The goal is a high-level semantic environment that can run interactively on Spark.










![Checkpoint caching (maps 1:1 to Spark)
Checkpoint caching is a combination of None | in-
memory | disk | serialized | replicated options
Method “checkpoint()” signature:
def checkpoint(sLevel: StorageLevel =
StorageLevel.MEMORY_ONLY): CheckpointedDrm[K]
Unpin data when no longer needed
drmA.uncache()](https://image.slidesharecdn.com/mahoutscalaandsparkbindings-140418151047-phpapp01/75/Mahout-scala-and-spark-bindings-12-2048.jpg)


![Customization: Externalizing RDDs
Externalizing raw RDD
Triggers optimizer checkpoint implicitly
val rawRdd:DrmRDD[K] = drmA.rdd
Wrapping raw RDD into a DRM
Stitching with data prep pipelines
Building complex distributed algorithm
val drmA = drmWrap(rdd = rddA [, … ])](https://image.slidesharecdn.com/mahoutscalaandsparkbindings-140418151047-phpapp01/75/Mahout-scala-and-spark-bindings-16-2048.jpg)