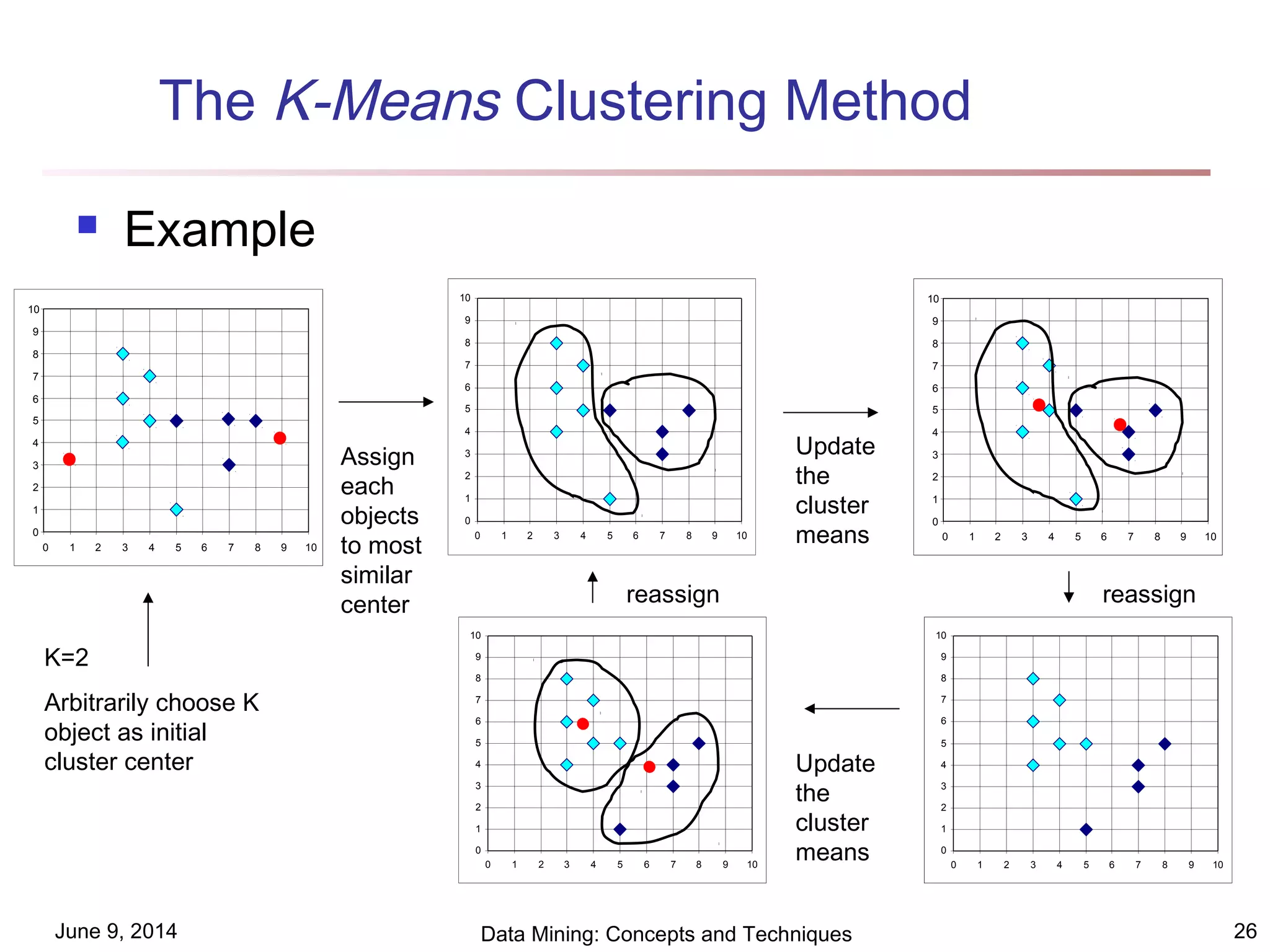
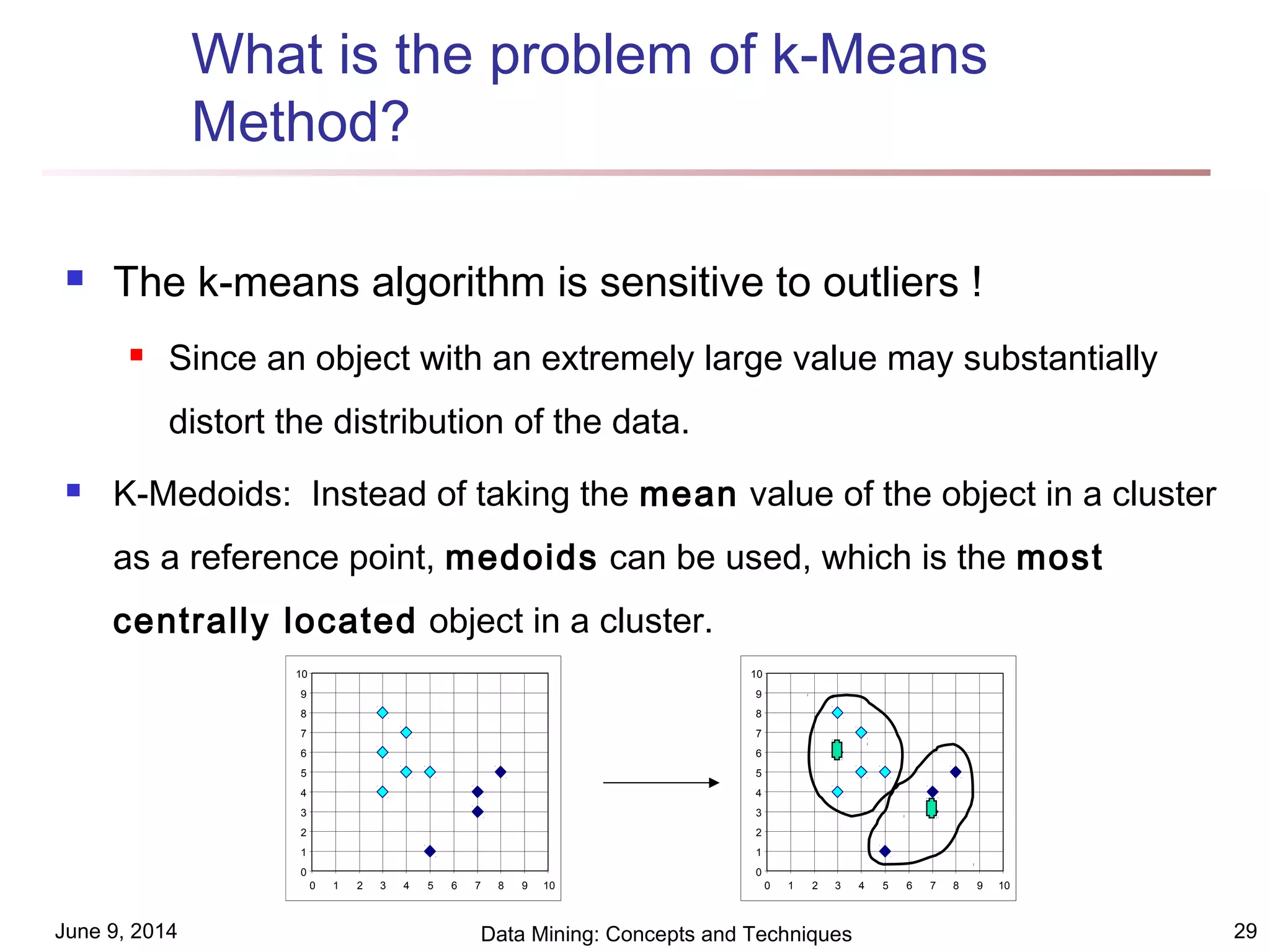
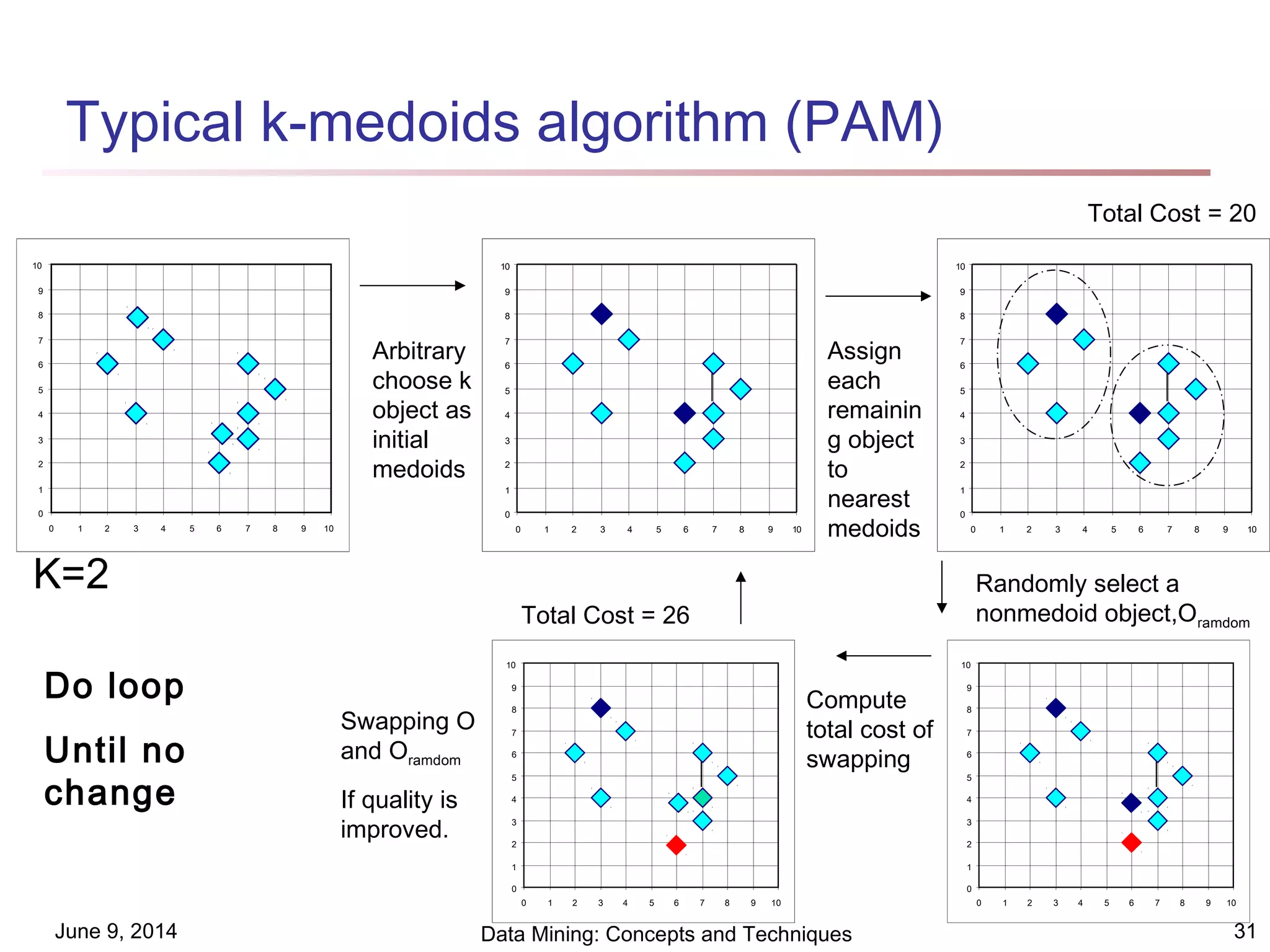
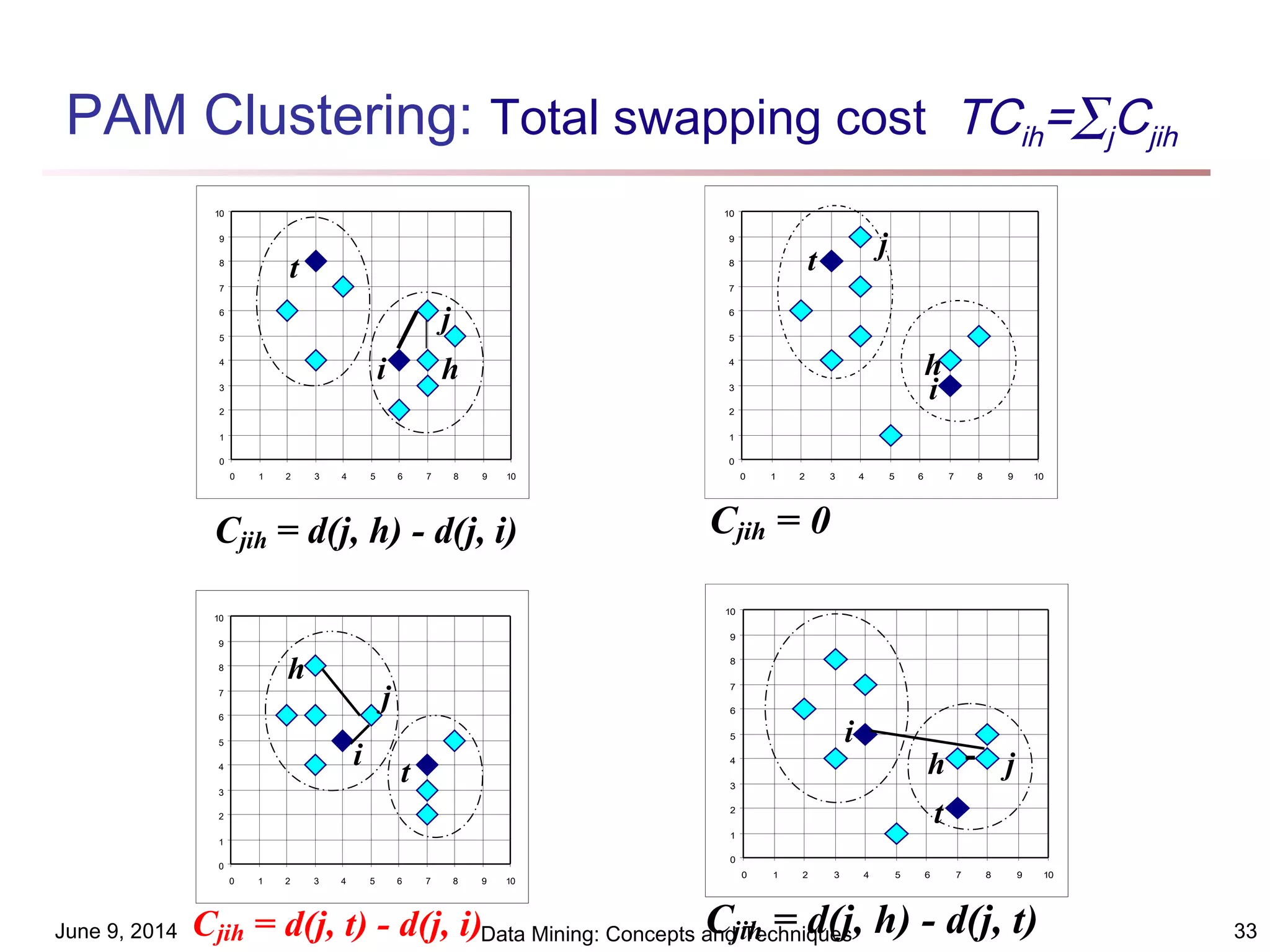
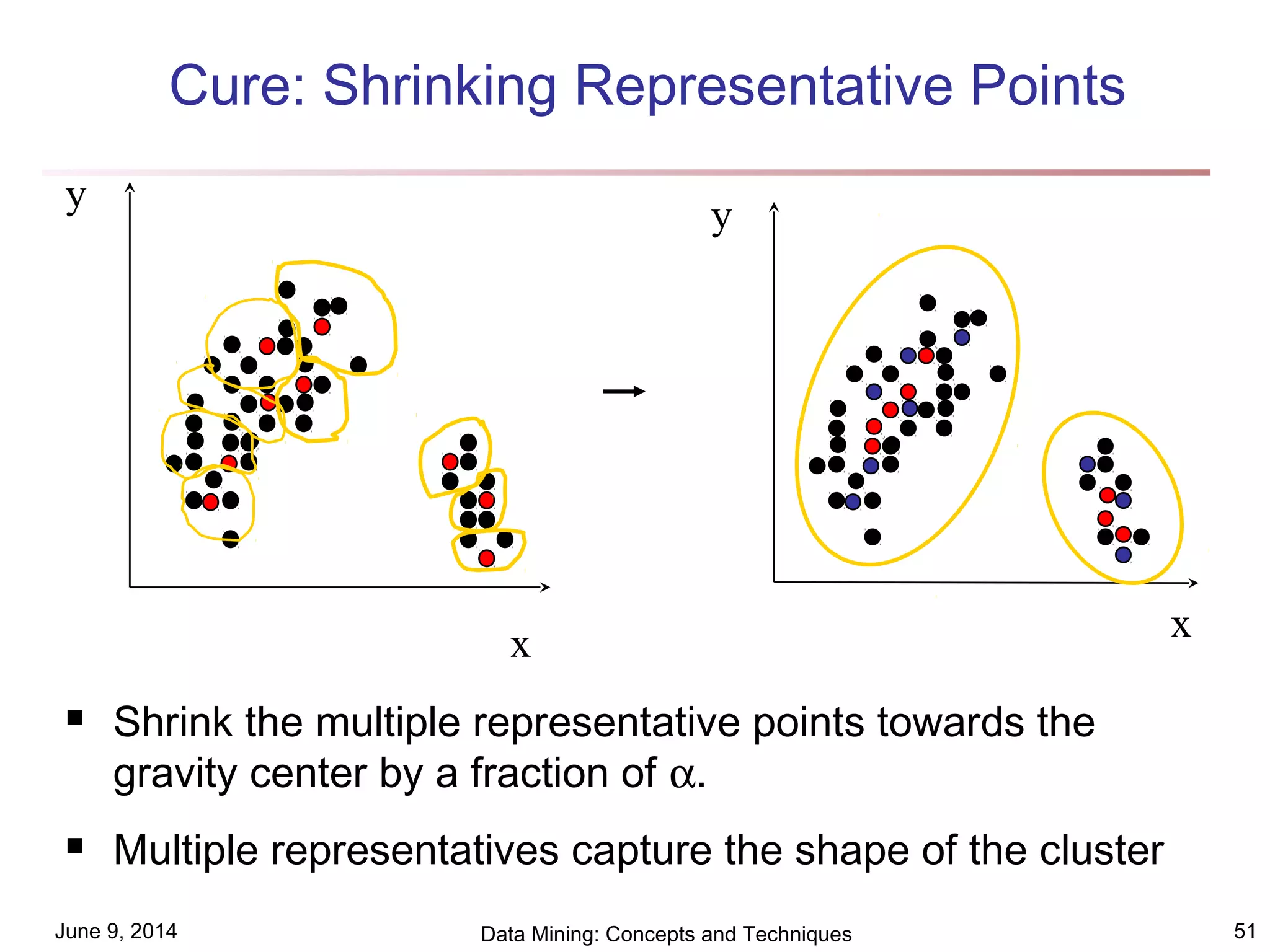
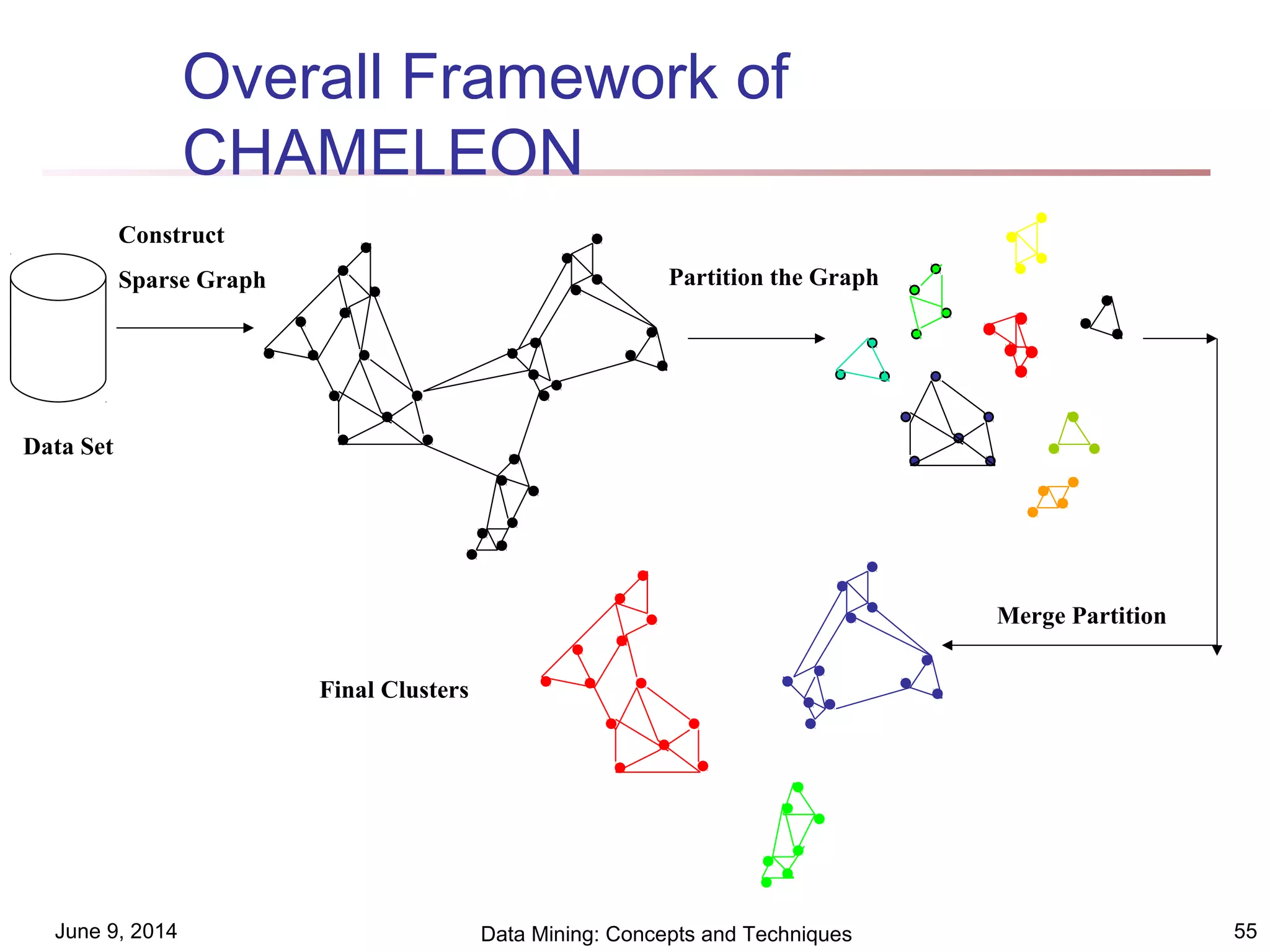
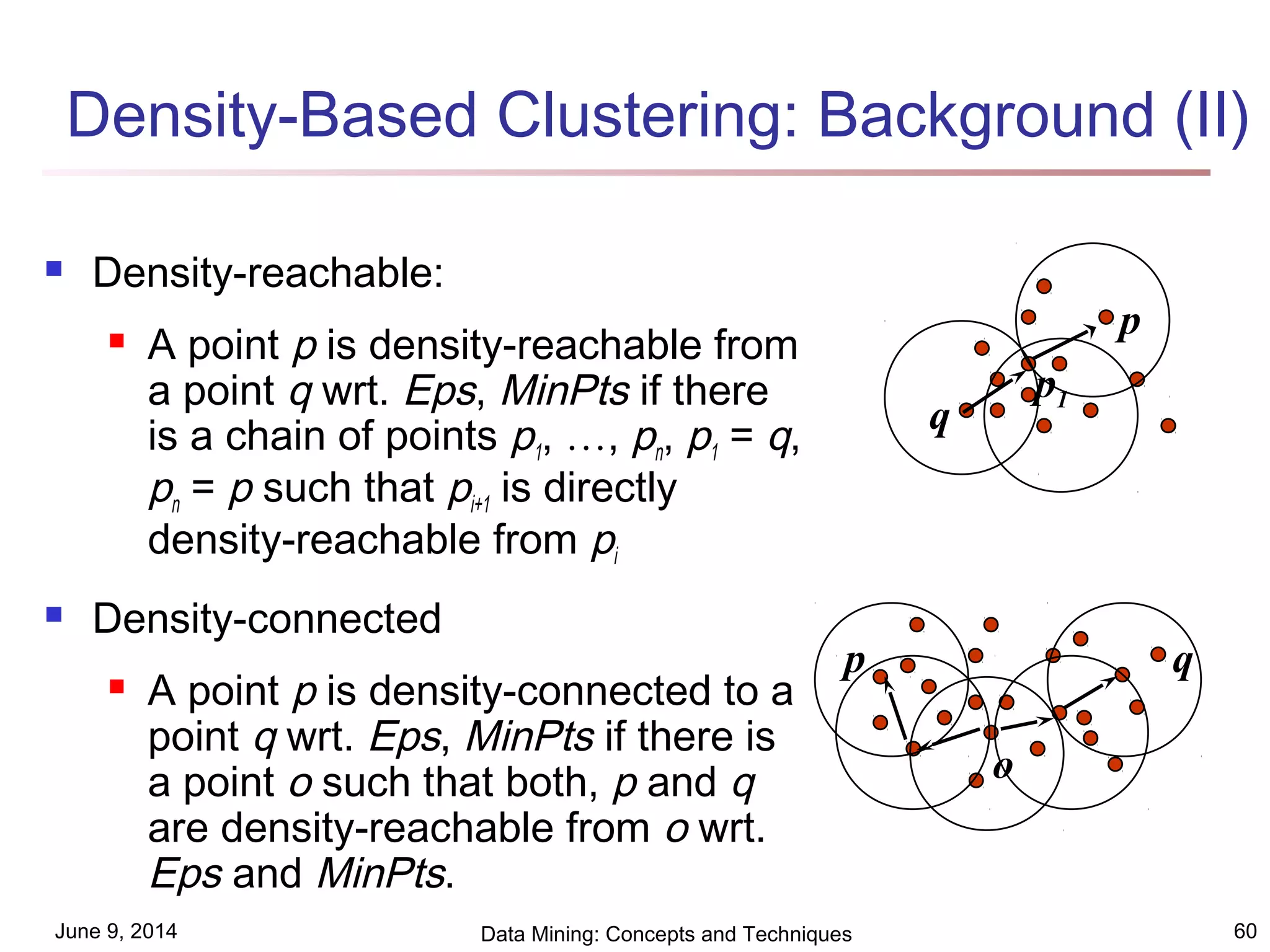
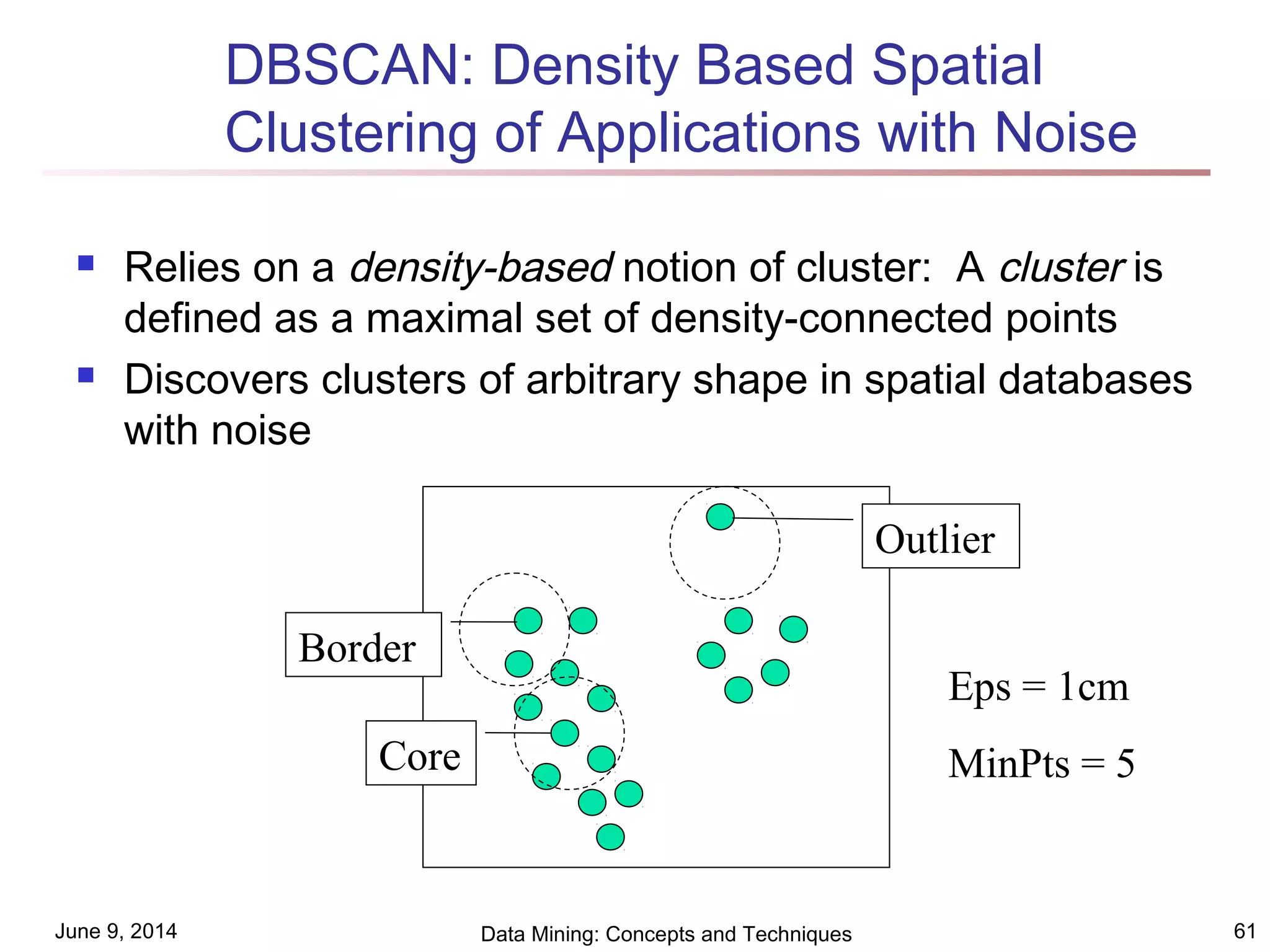
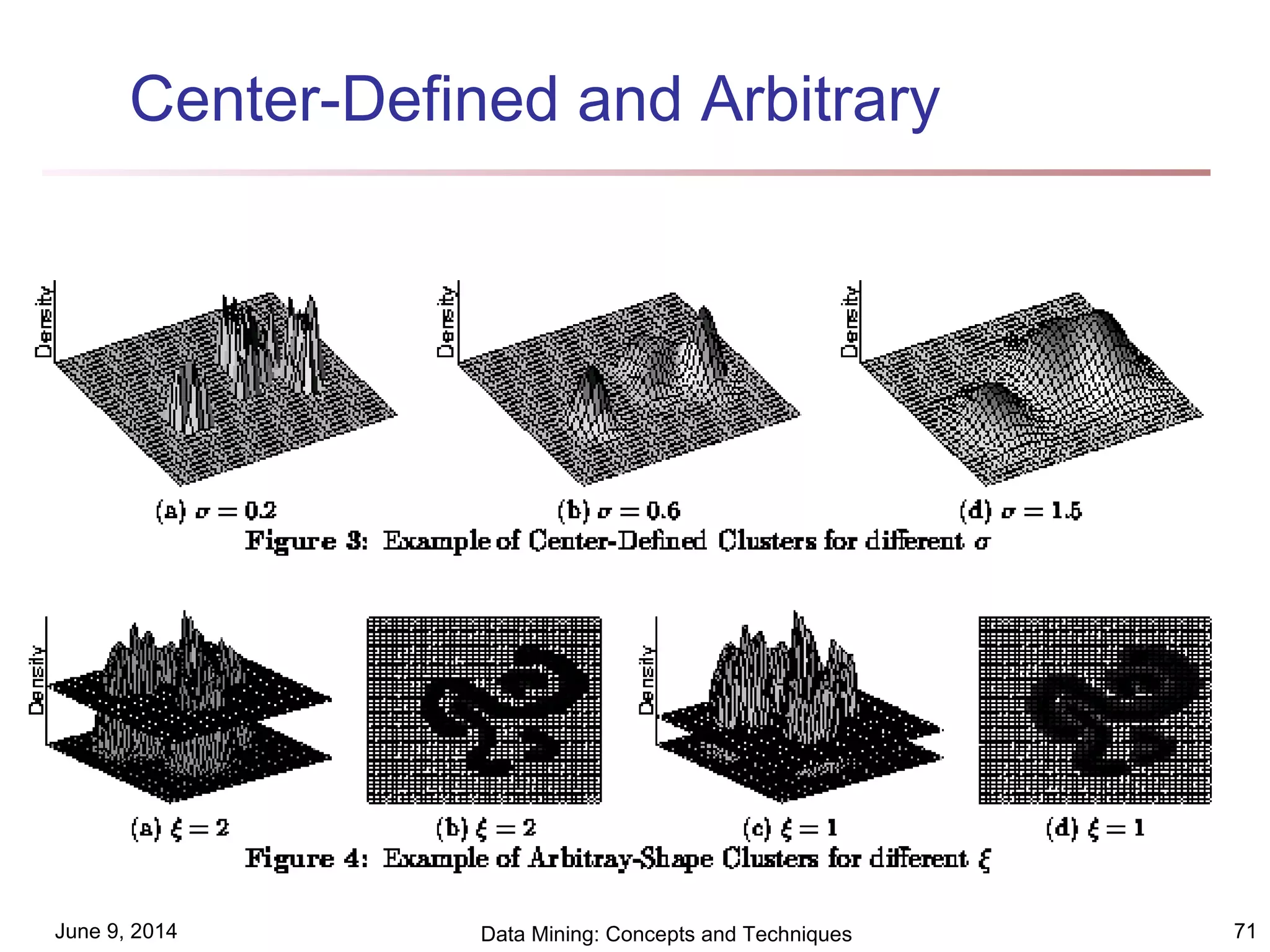
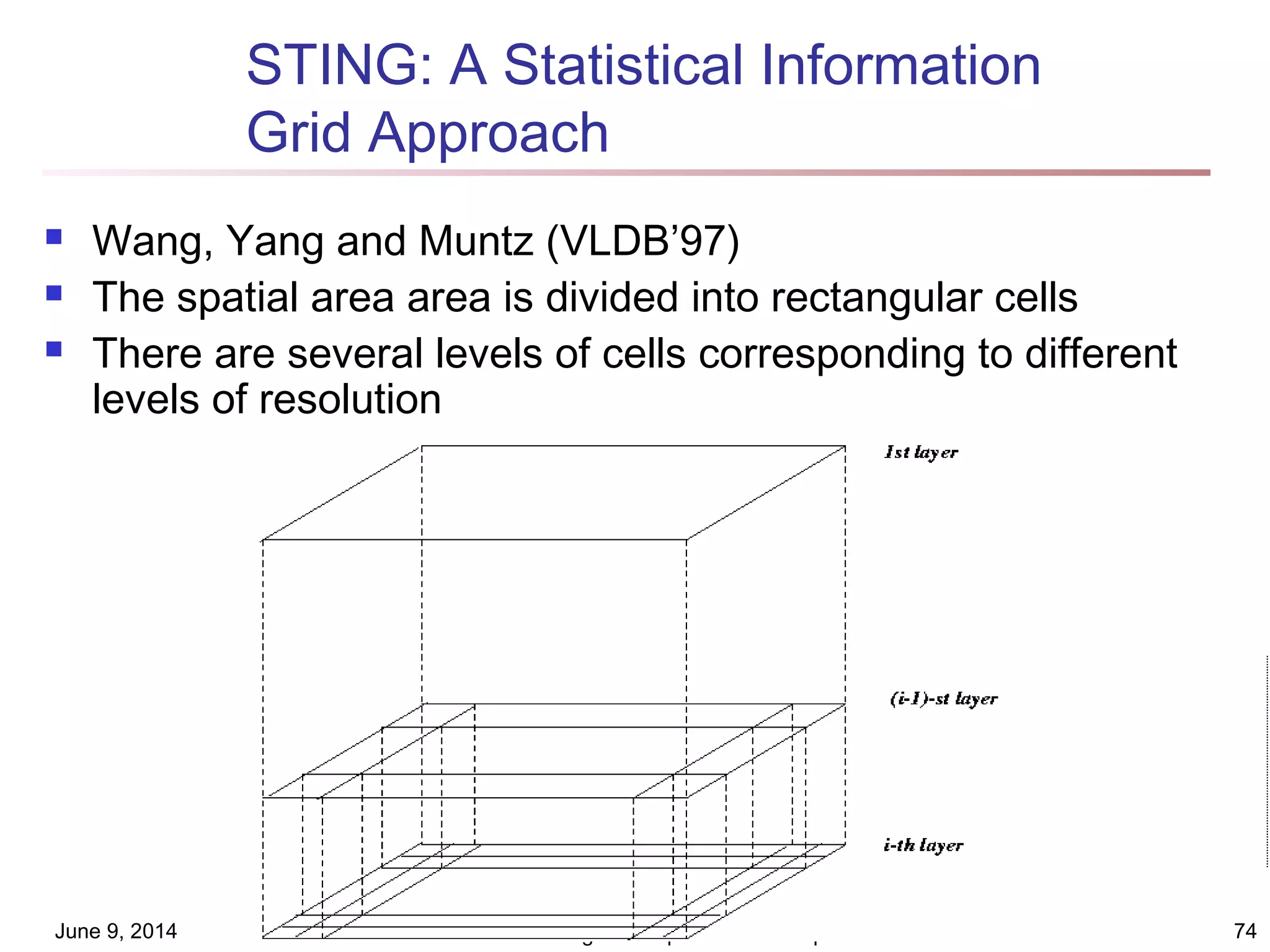
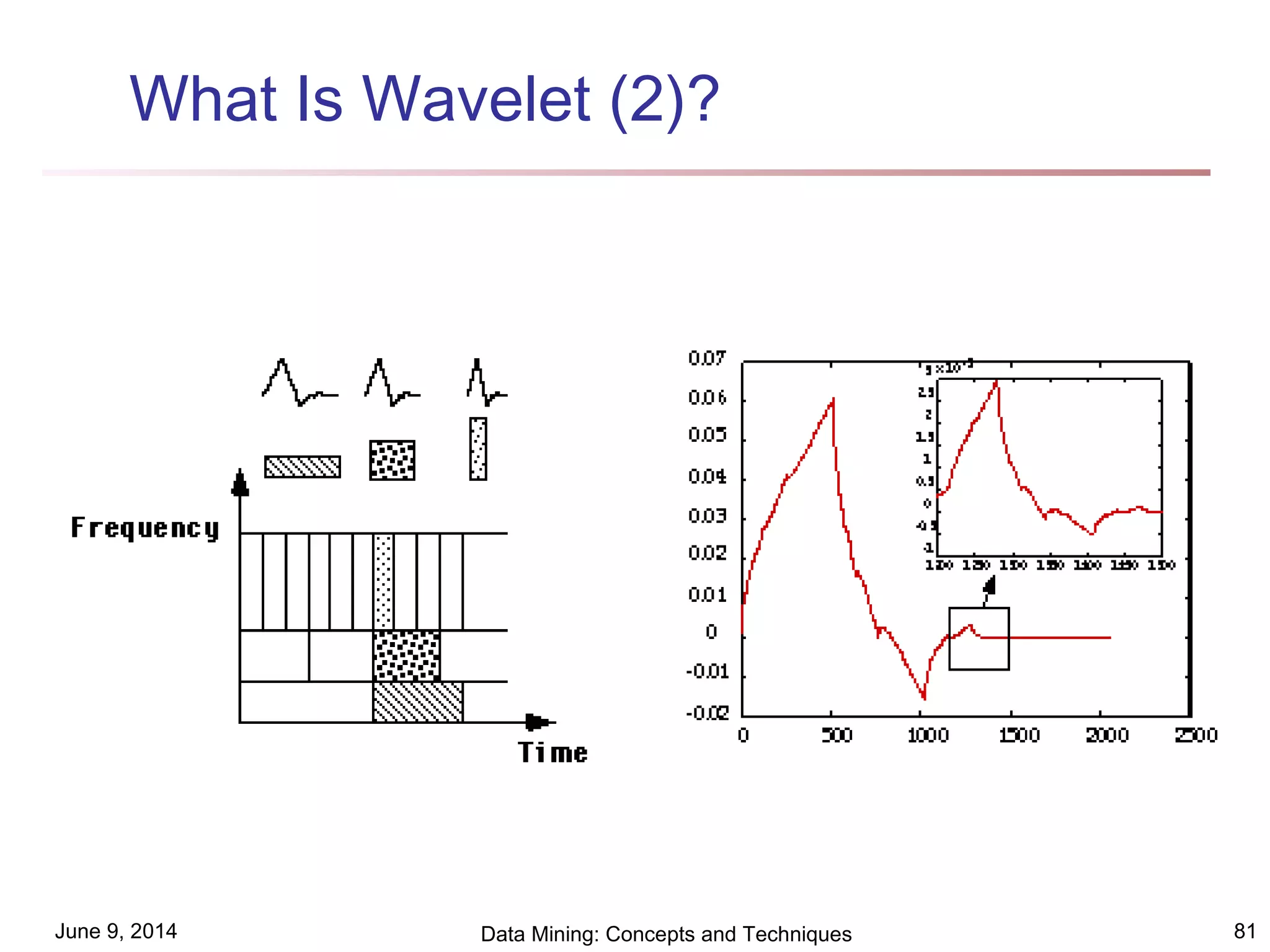
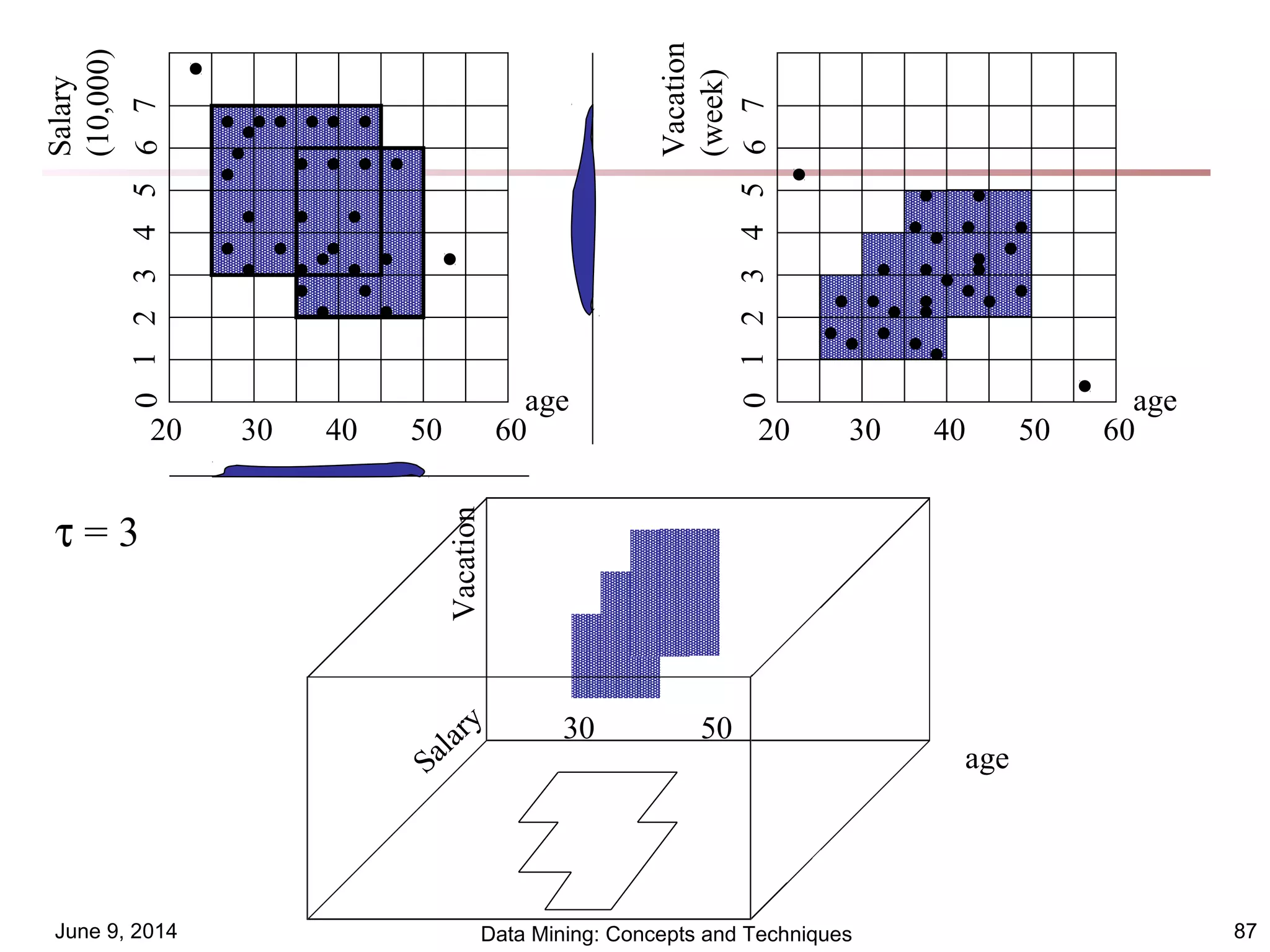
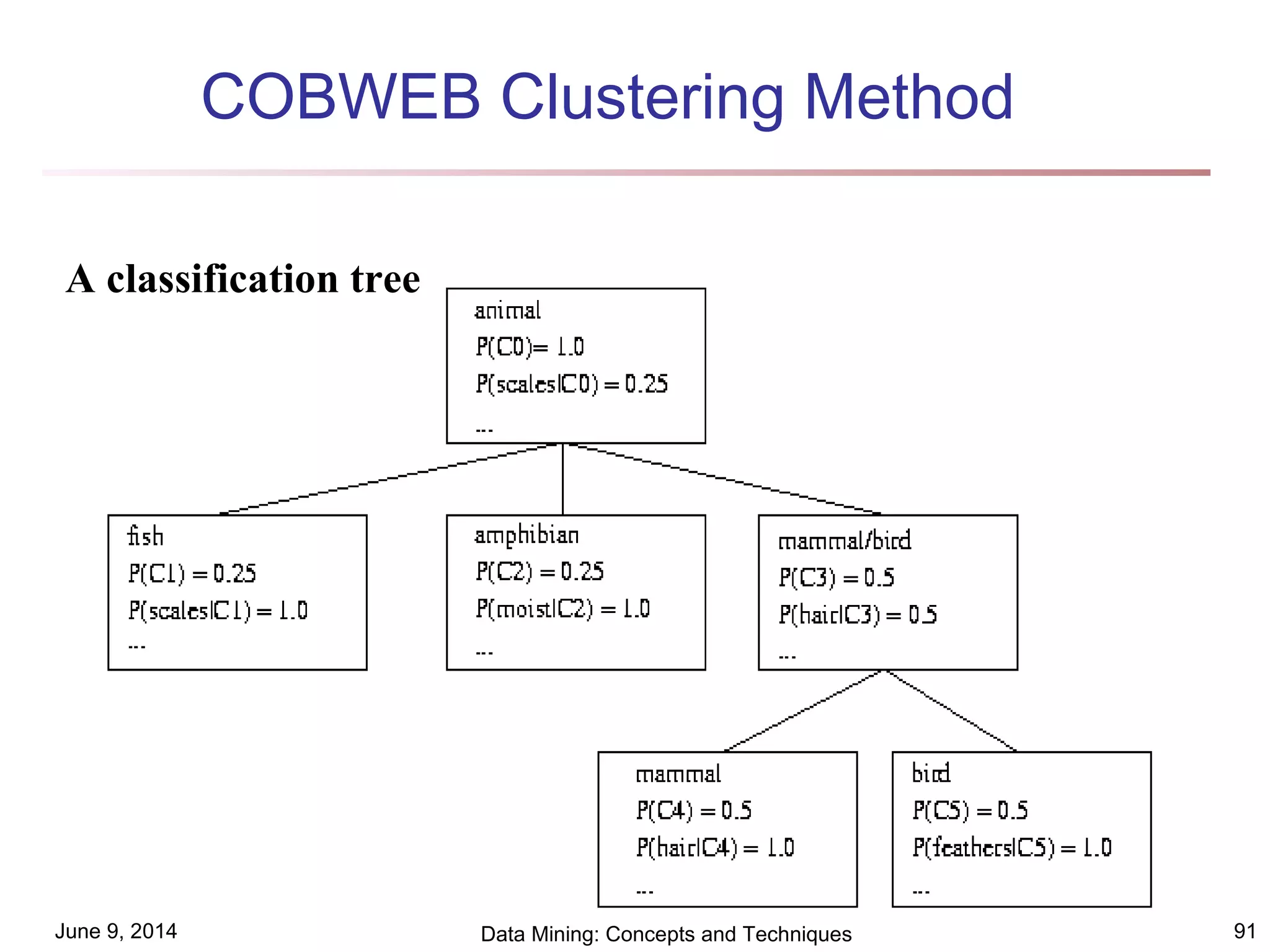
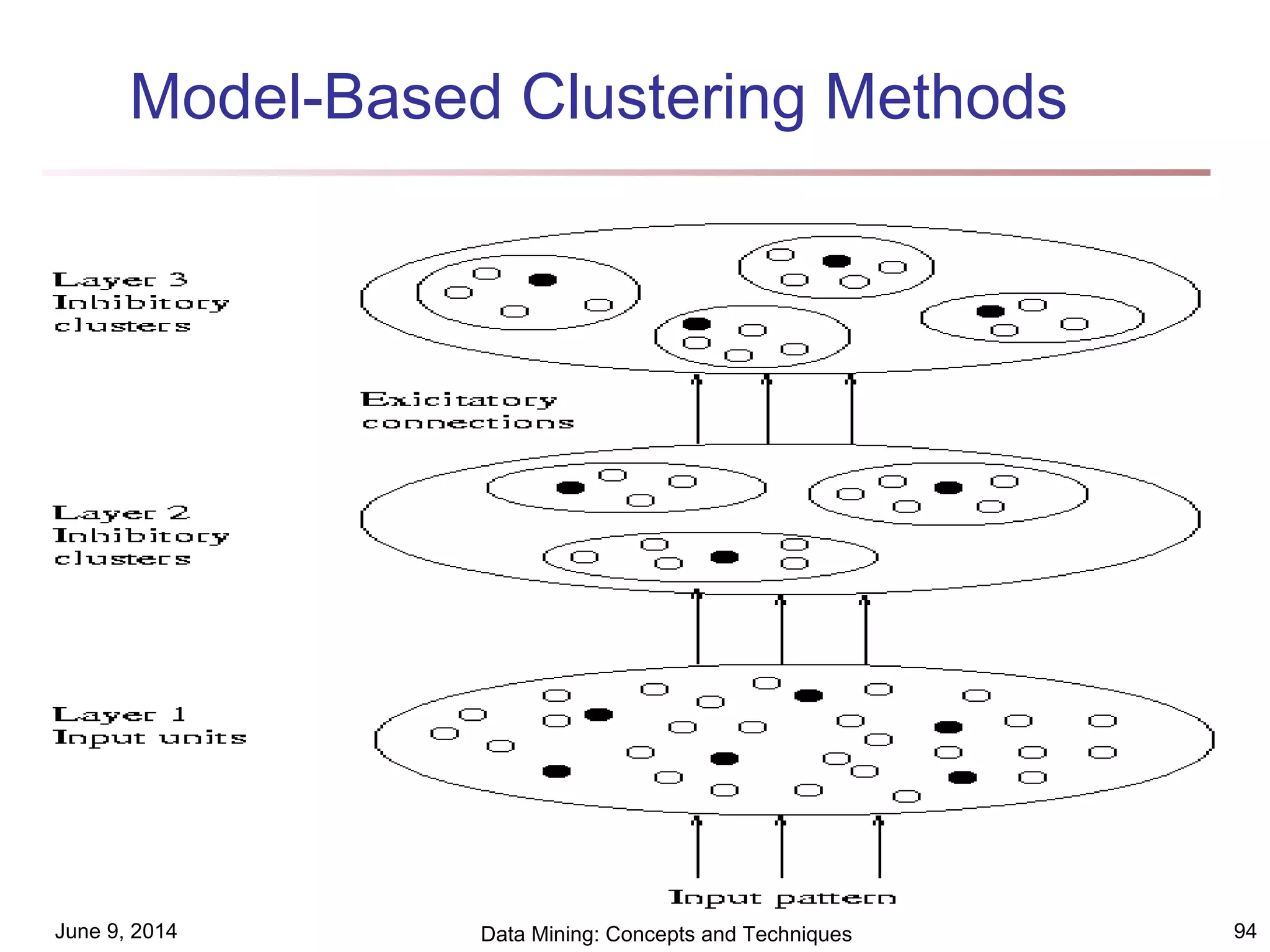
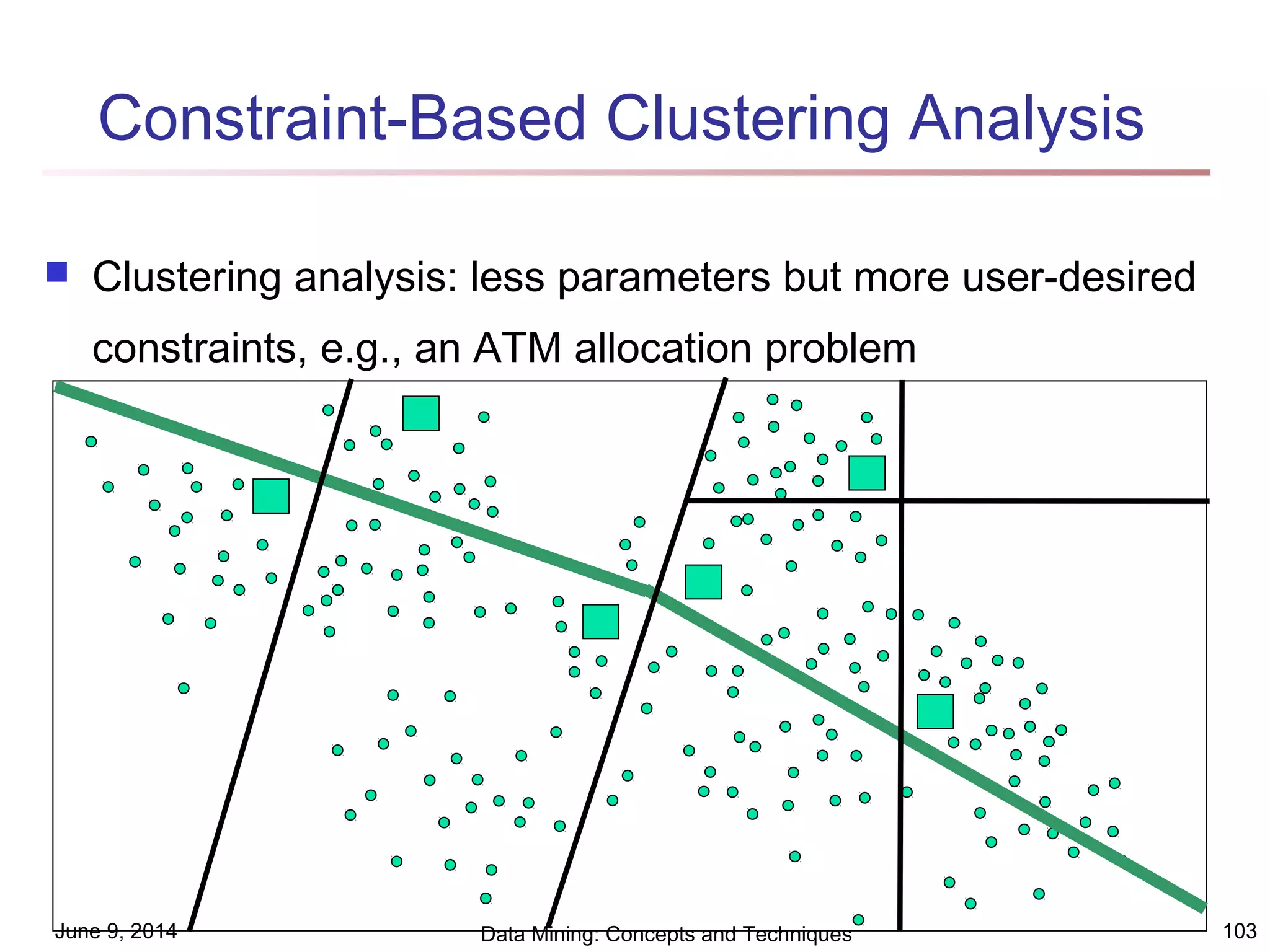
This document discusses different clustering methods in data mining. It begins by defining cluster analysis and its applications. It then categorizes major clustering methods into partitioning methods, hierarchical methods, density-based methods, grid-based methods, and model-based clustering methods. Finally, it provides details on partitioning methods like k-means and k-medoids clustering algorithms.

















![June 9, 2014 Data Mining: Concepts and Techniques 18
Ordinal Variables
An ordinal variable can be discrete or continuous
Order is important, e.g., rank
Can be treated like interval-scaled
replace xif by their rank
map the range of each variable onto [0, 1] by replacing
i-th object in the f-th variable by
compute the dissimilarity using methods for interval-
scaled variables
1
1
−
−
=
f
if
if M
r
z
},...,1{ fif
Mr ∈](https://image.slidesharecdn.com/chapter8-140608191639-phpapp02/75/Chapter8-18-2048.jpg)