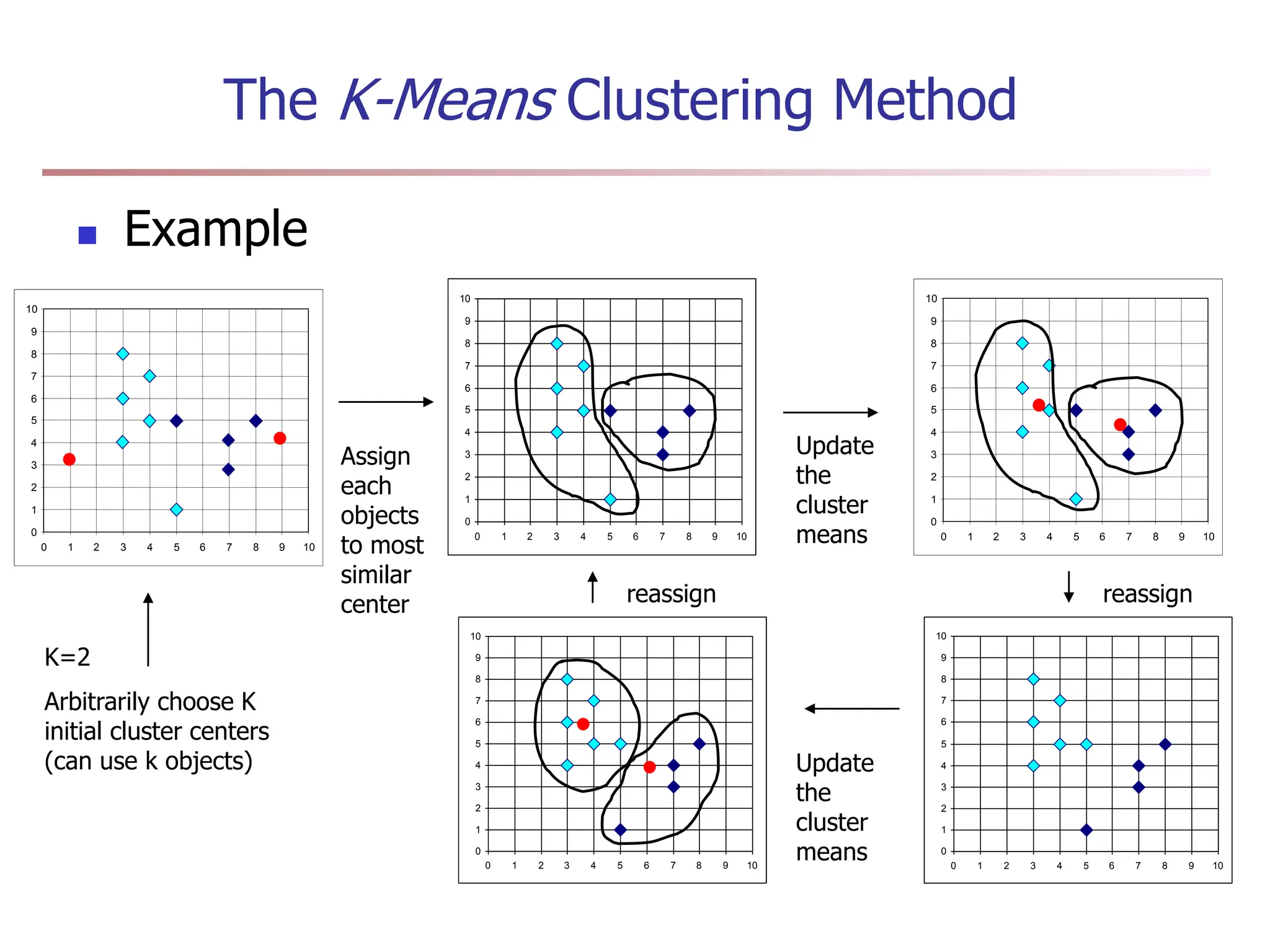
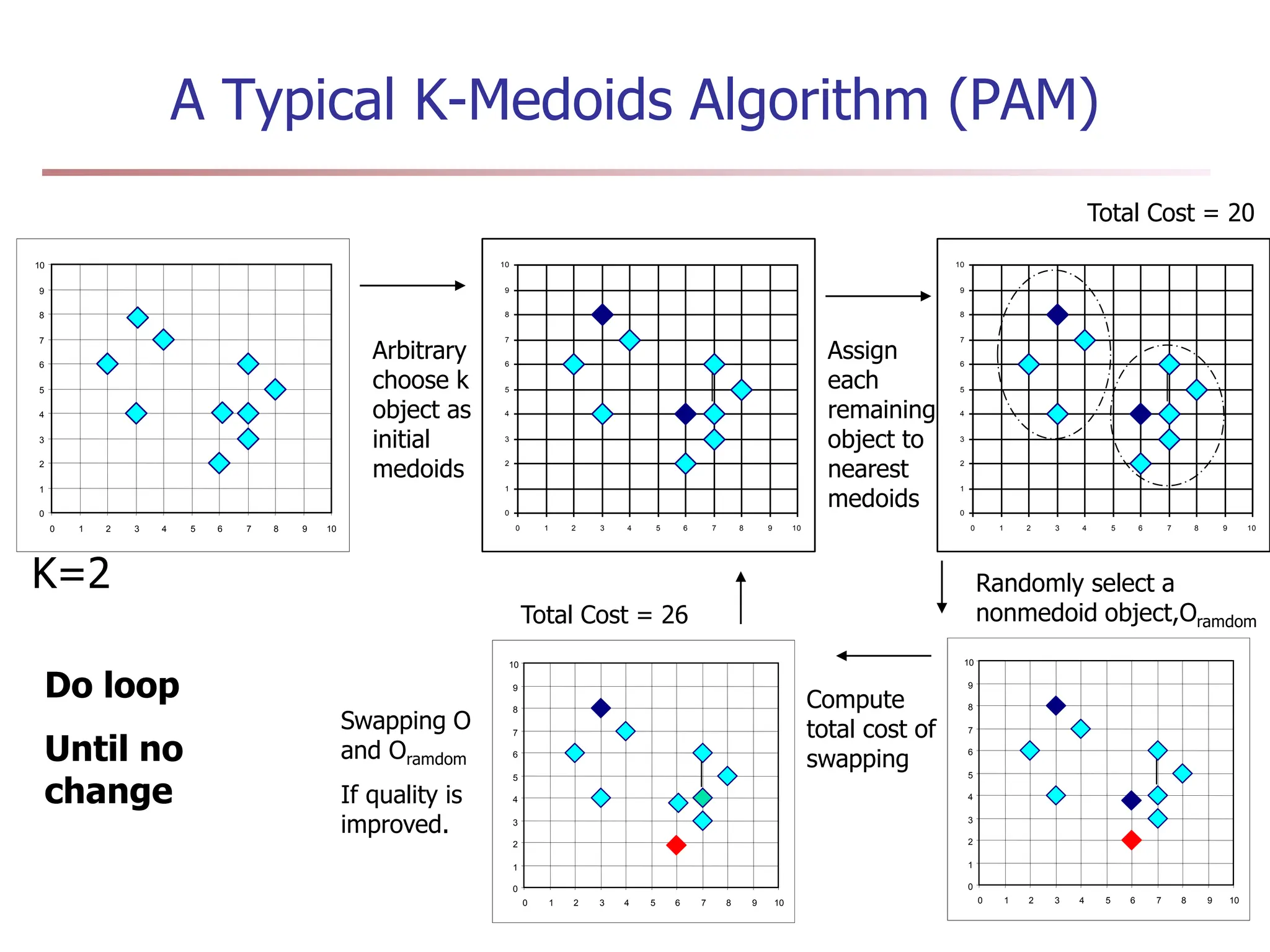
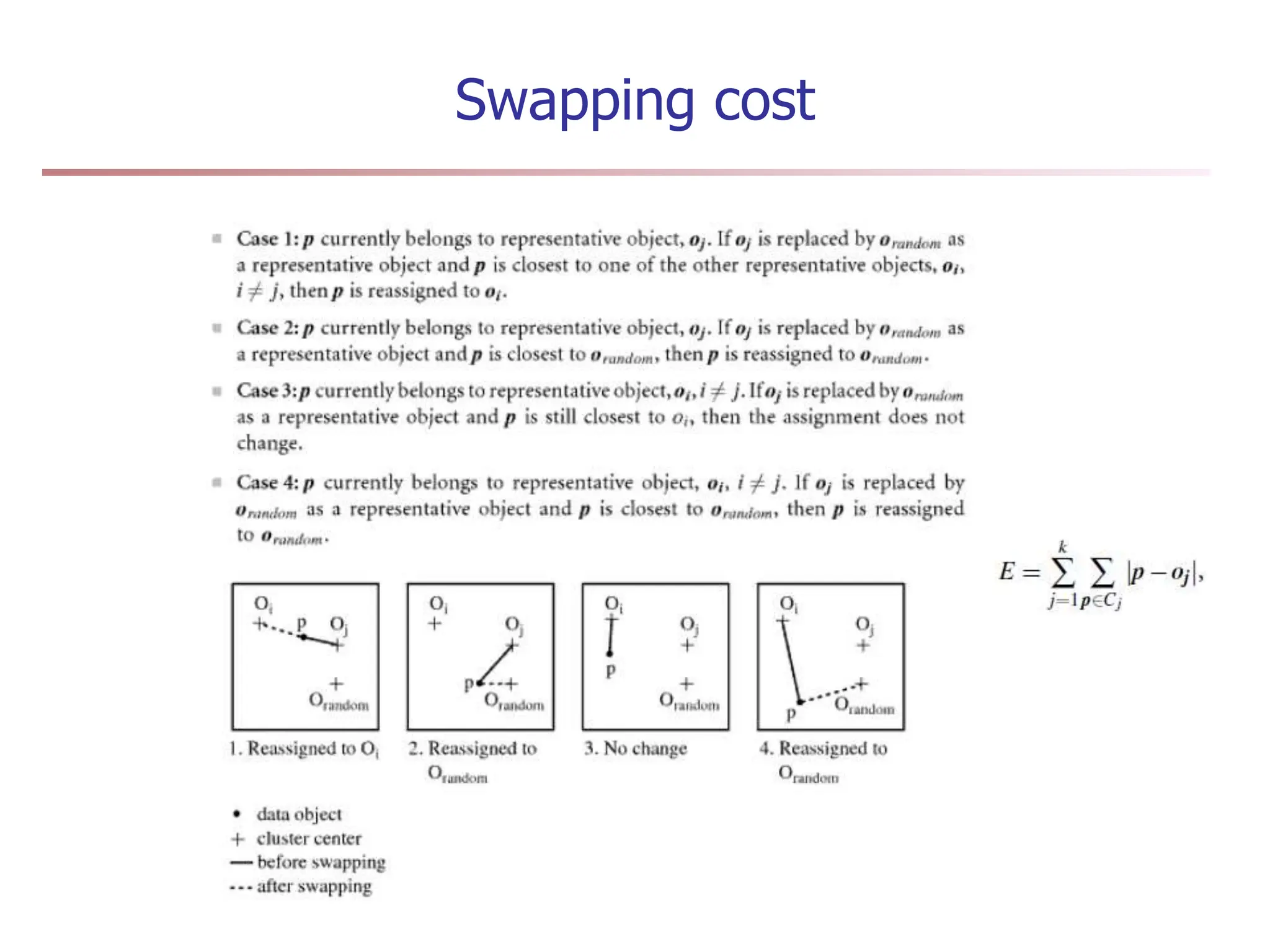
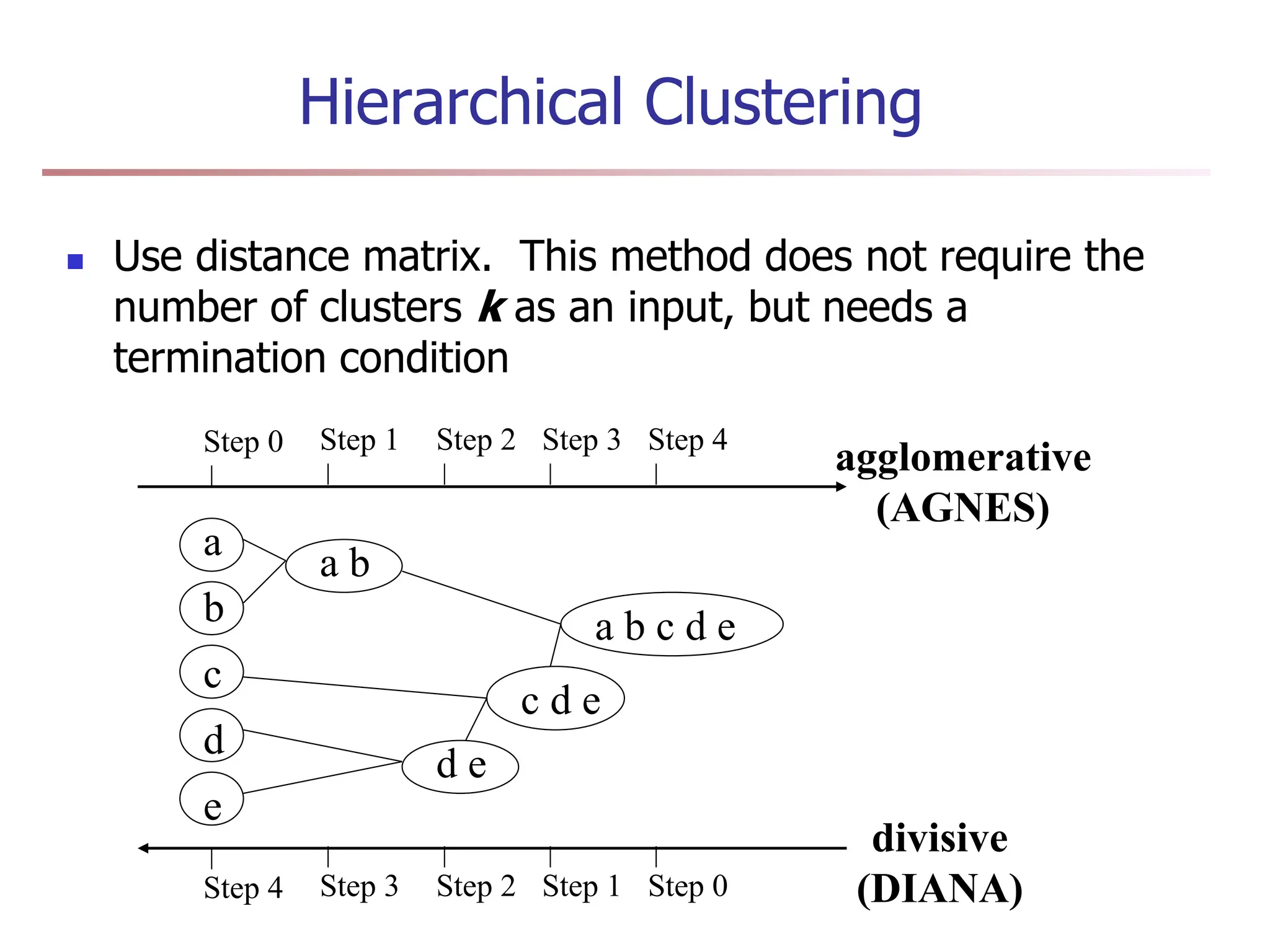
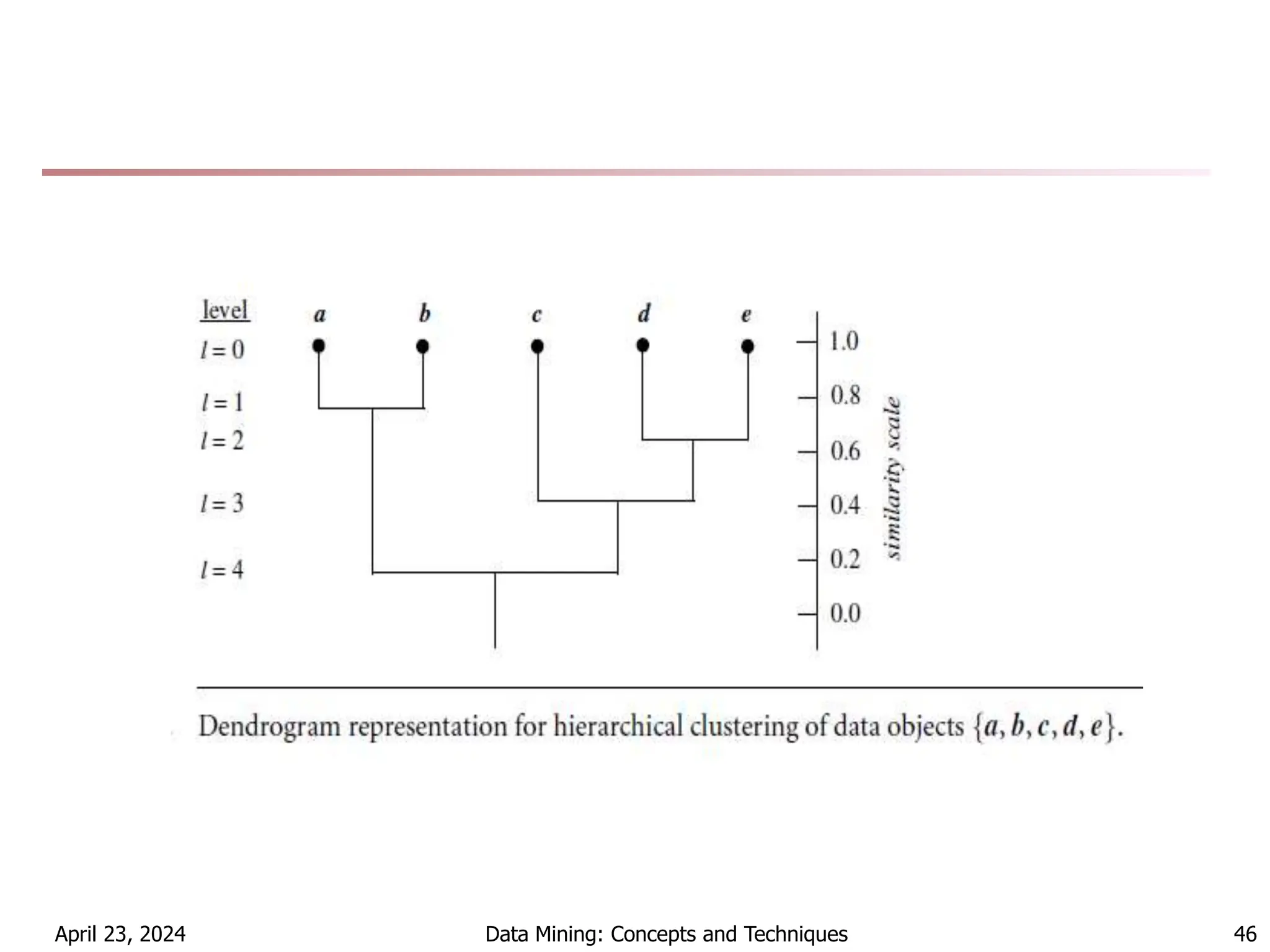
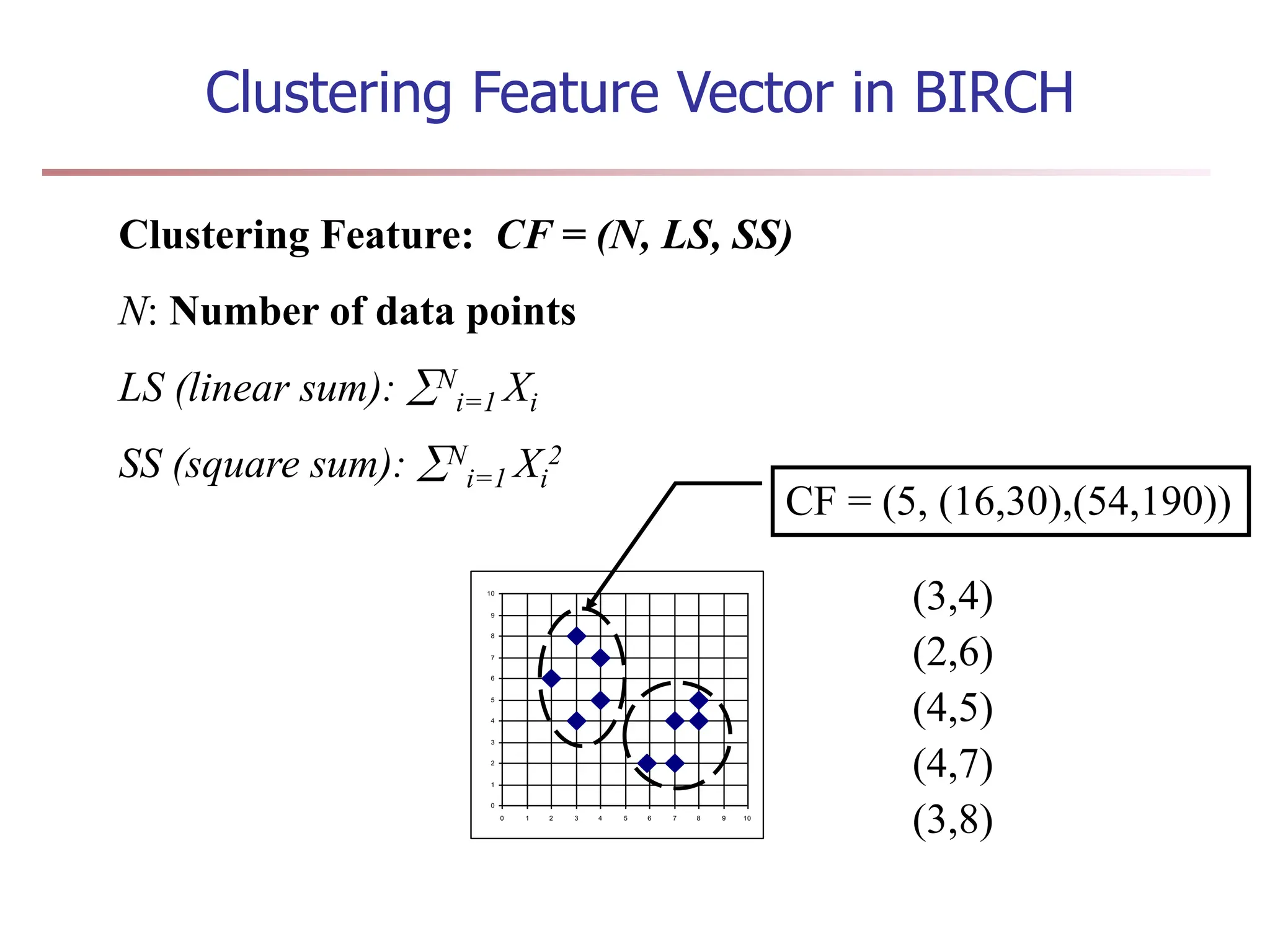
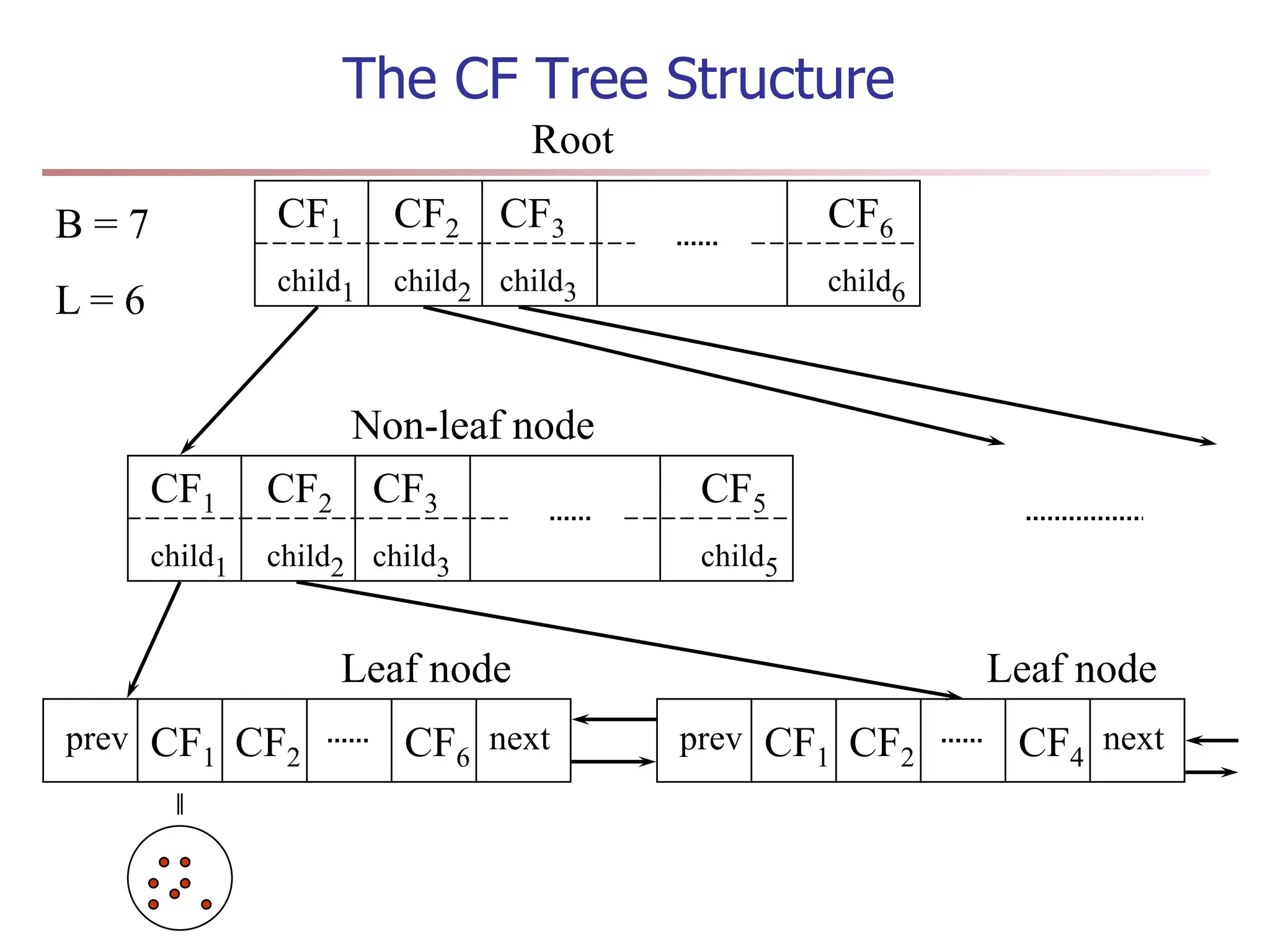
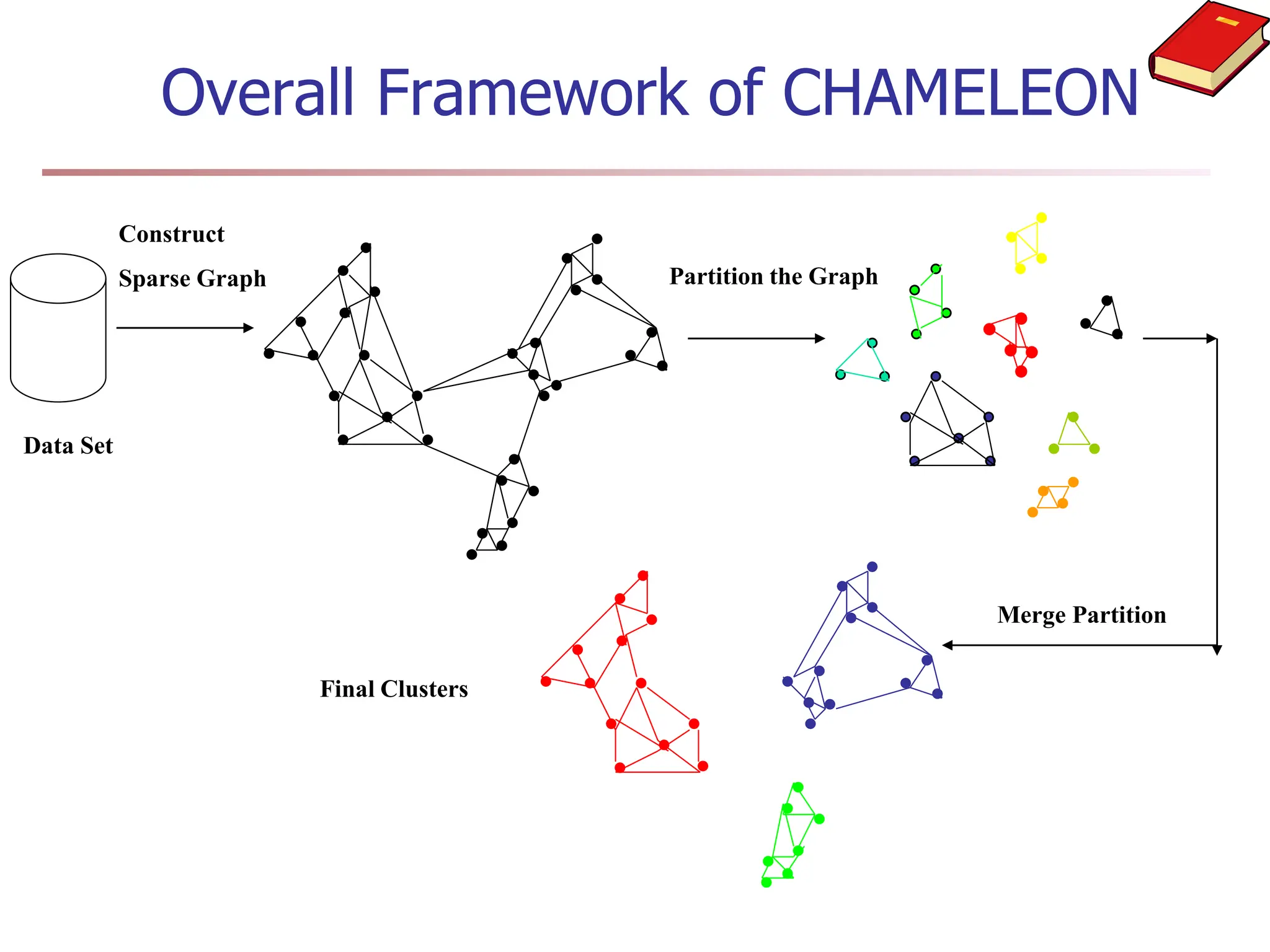
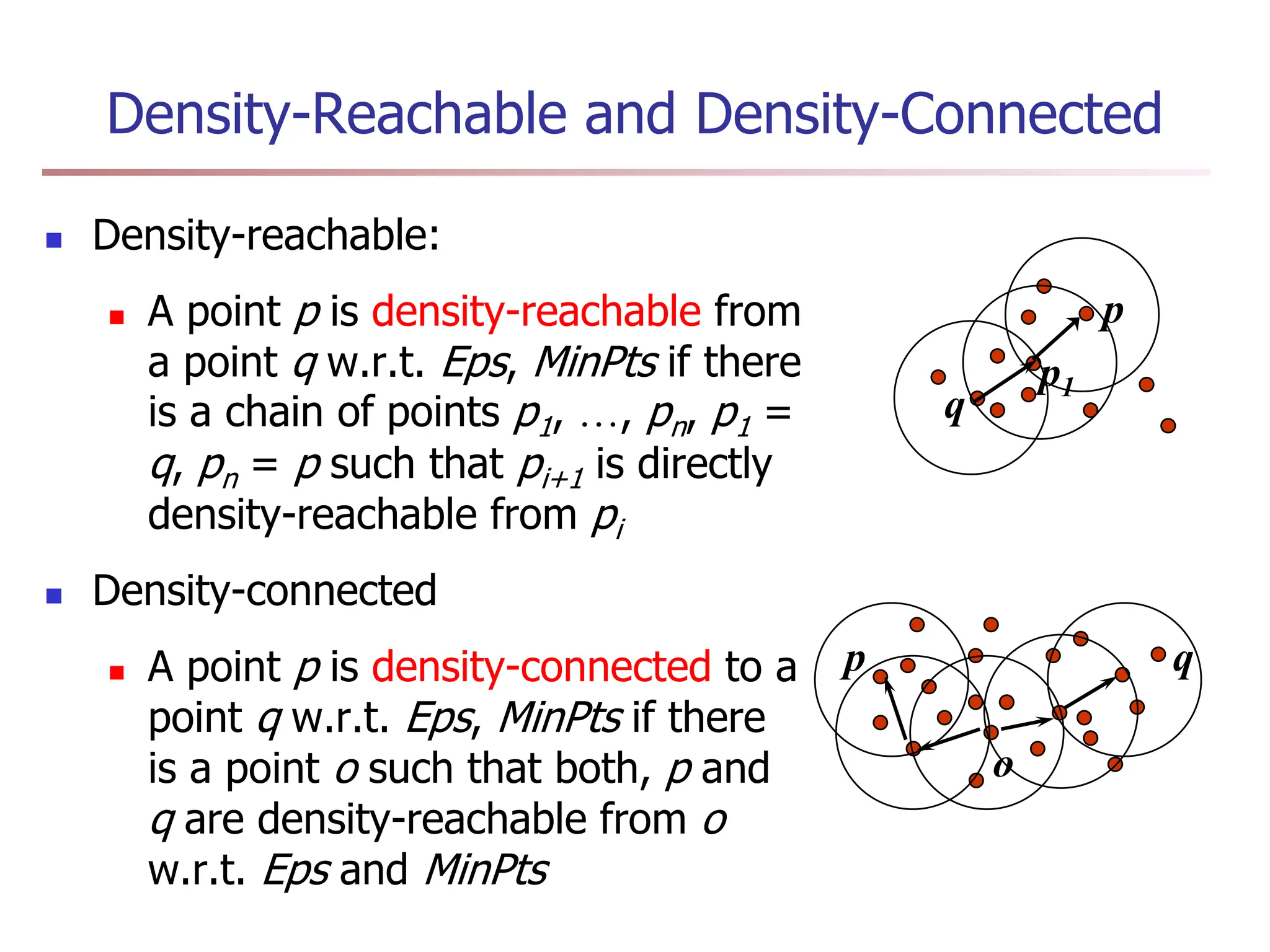
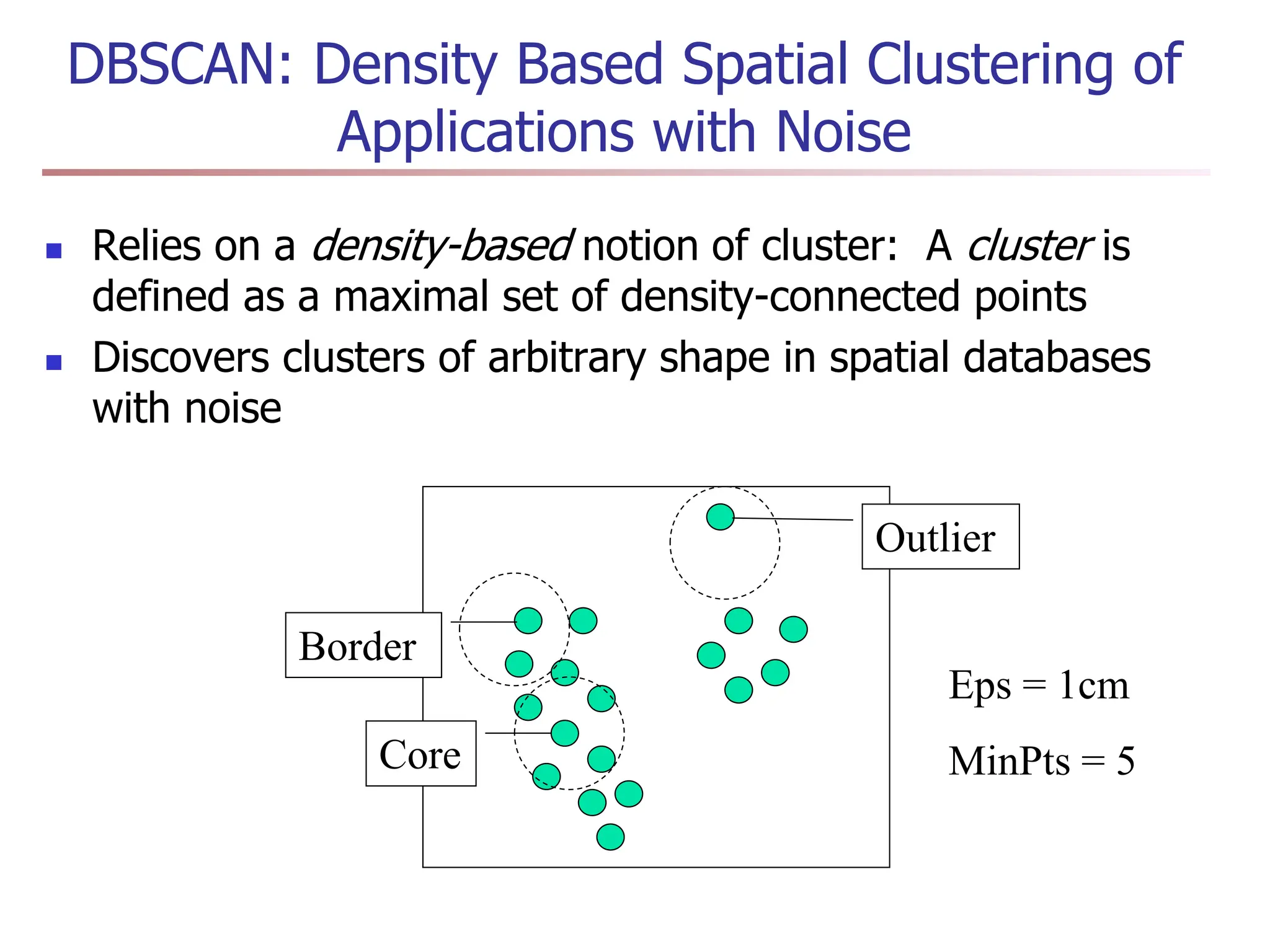
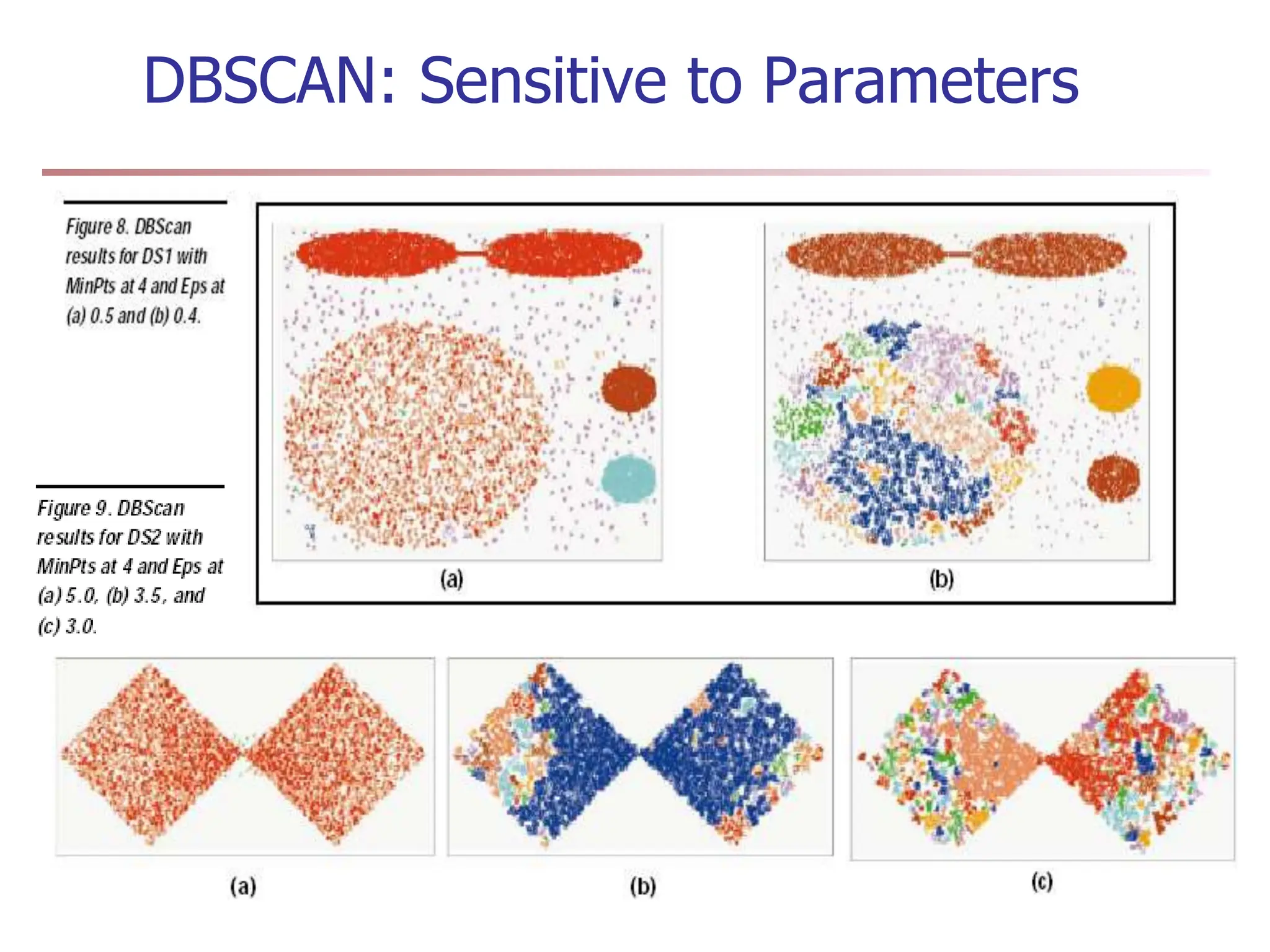
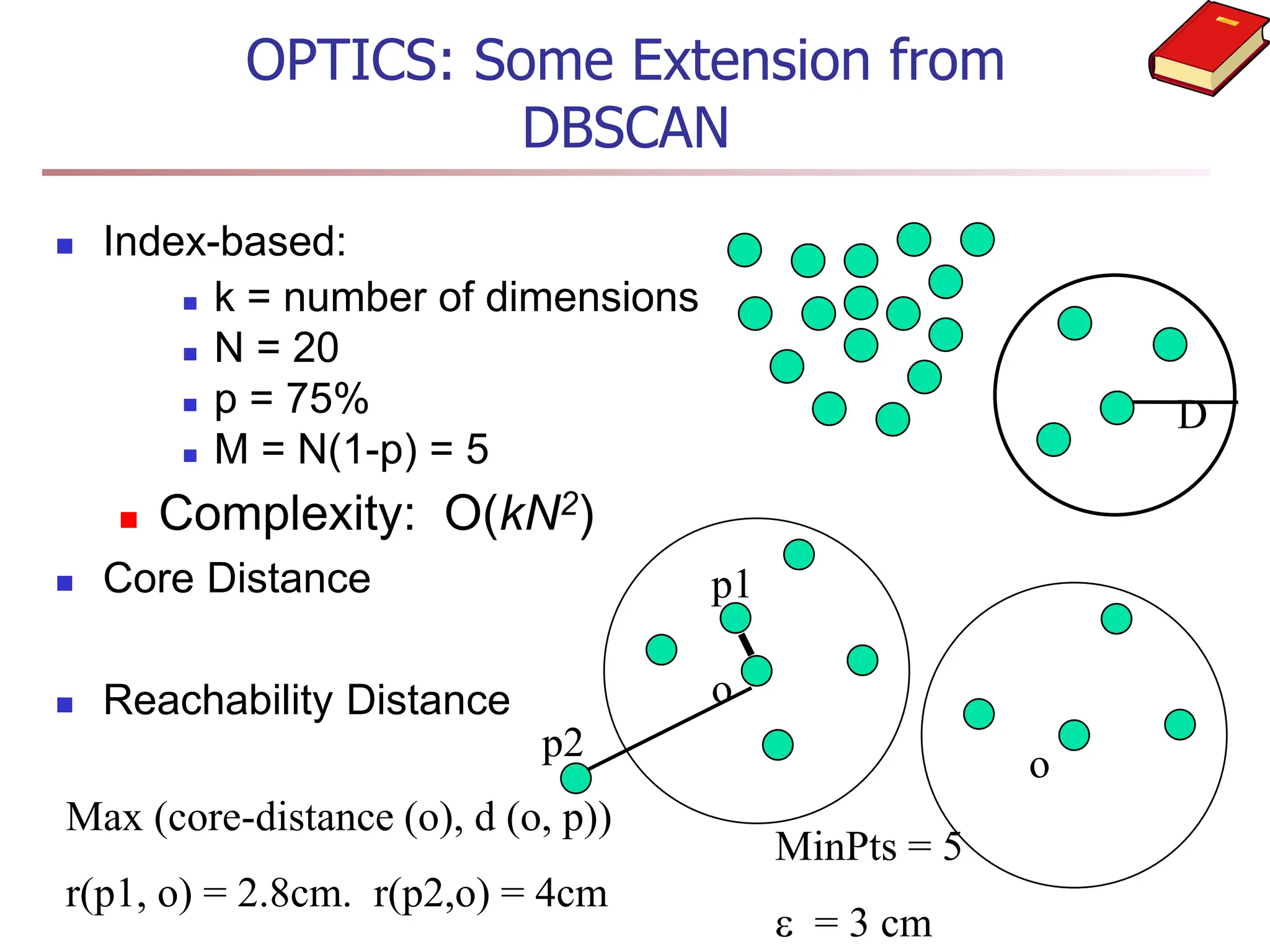
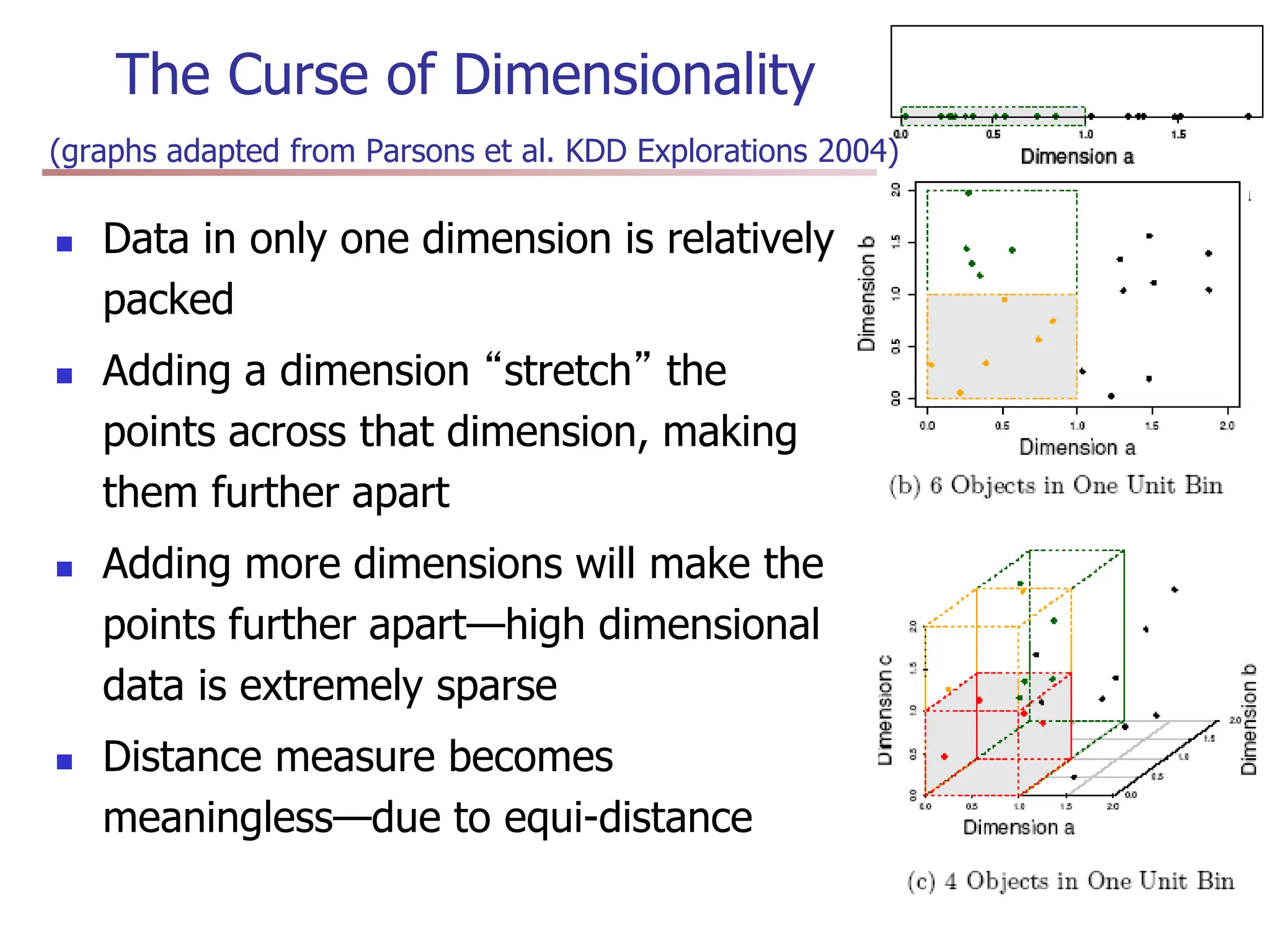
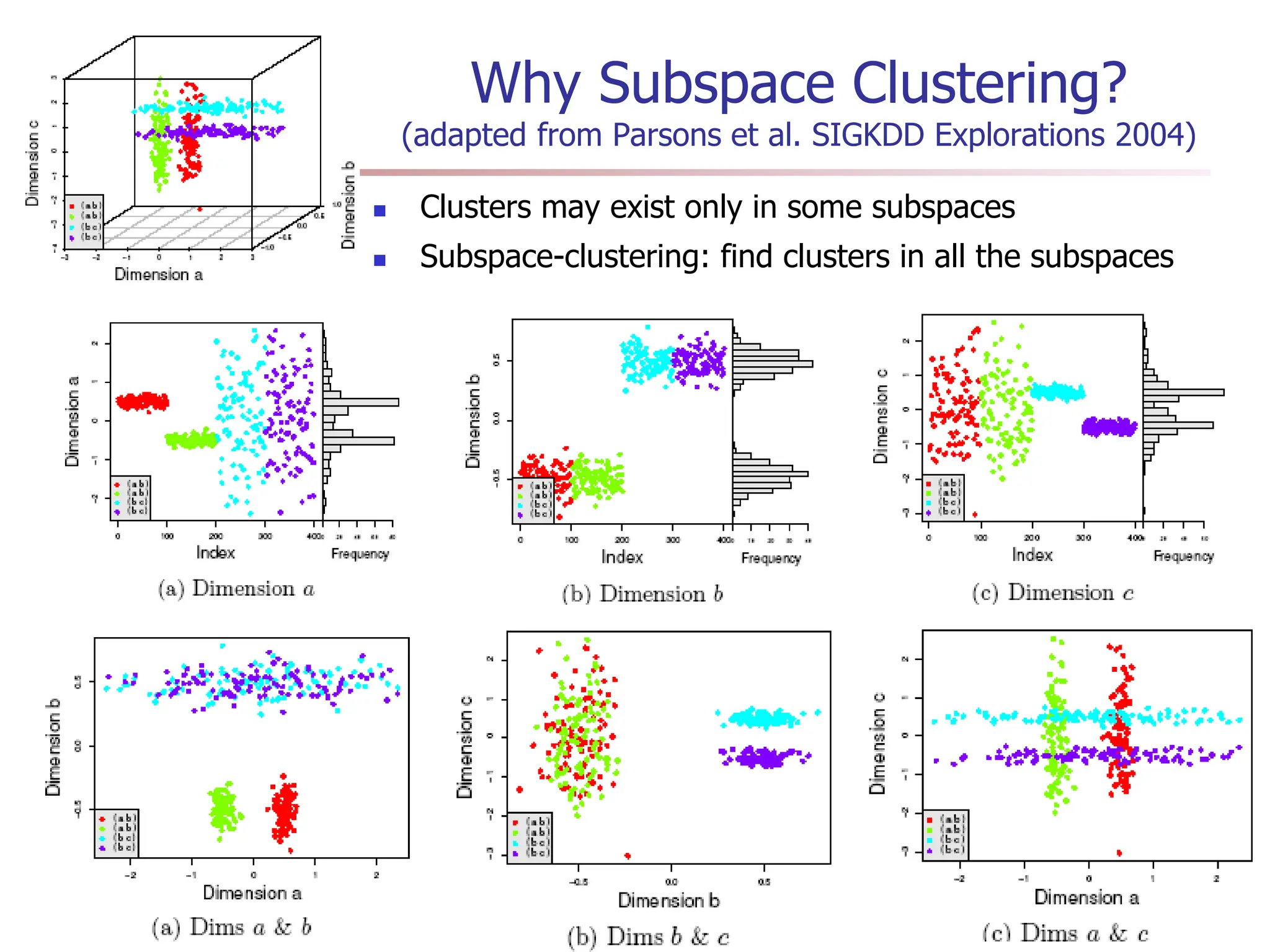
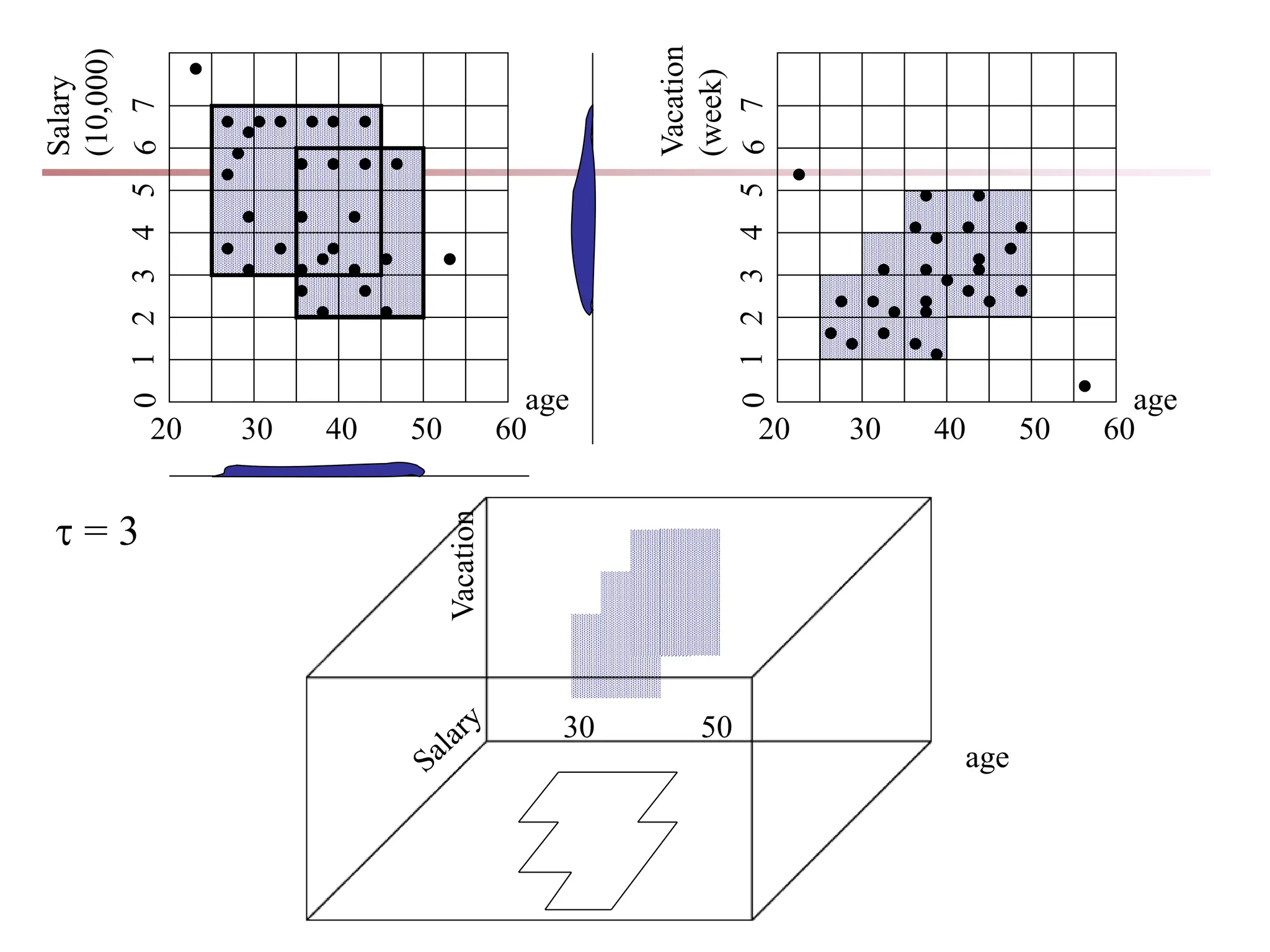
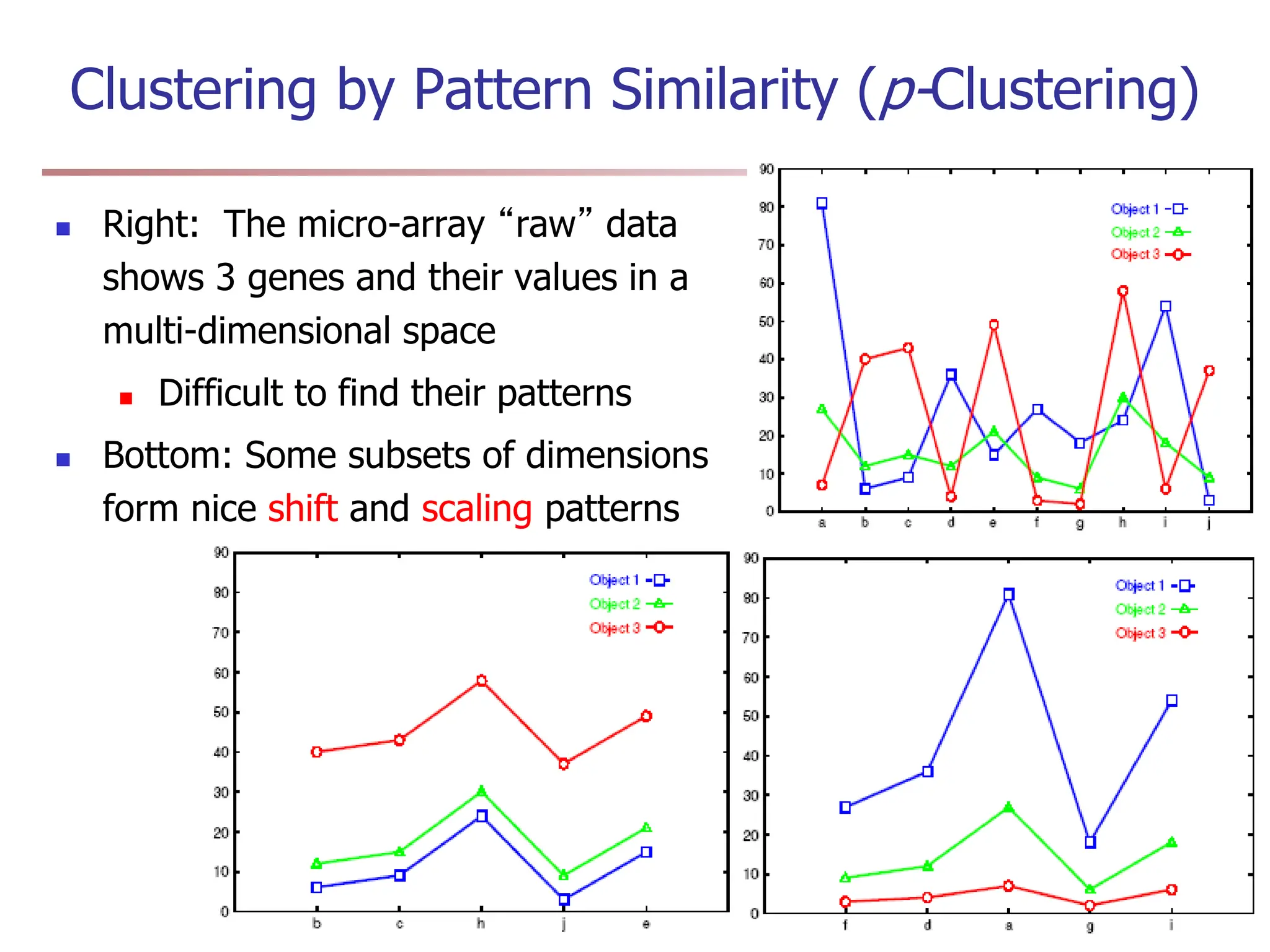
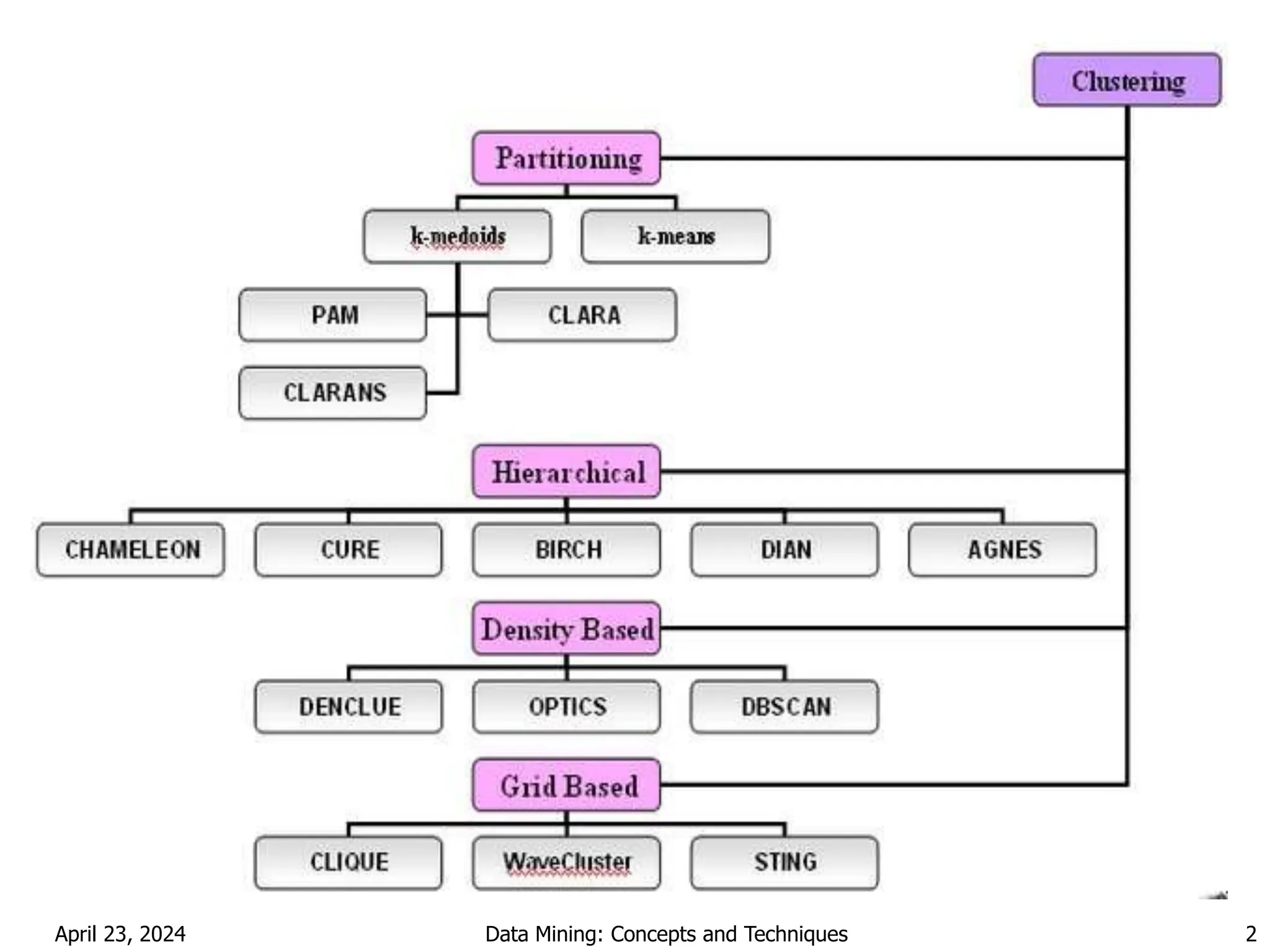
Chapter 7 discusses cluster analysis, which involves grouping similar data objects together based on characteristics to uncover patterns within data. It categorizes various clustering methods, including partitioning, hierarchical, density-based, and model-based approaches, and emphasizes the importance of quality clustering for insight into data distribution. Applications span multiple fields such as marketing, city planning, and geological studies, showcasing the versatility and methodological diversity of cluster analysis.
















![Ordinal Variables
An ordinal variable can be discrete or continuous
Order is important, e.g., rank
Can be treated like interval-scaled
replace xif by their rank
map the range of each variable onto [0, 1] by replacing
i-th object in the f-th variable by
compute the dissimilarity using methods for interval-
scaled variables
1
1
f
if
if M
r
z
}
,...,
1
{ f
if
M
r ](https://image.slidesharecdn.com/dmunit4ppt-240423193324-7028fa54/75/DM-UNIT_4-PPT-for-btech-final-year-students-18-2048.jpg)