Downloaded 31 times


















![Ordinal Variables
An ordinal variable can be discrete or continuous
Order is important, e.g., rank
Can be treated like interval-scaled
replace xif by their rank
rif ∈ 1,..., M f }
{
map the range of each variable onto [0, 1] by replacing
i-th object in the f-th variable by
r −
1
zif = if
M
−
1
f
compute the dissimilarity using methods for intervalscaled variables
November 10, 2013
Data Mining: Concepts and Techniques
19](https://image.slidesharecdn.com/cluster-131109195122-phpapp02/85/Cluster-19-320.jpg)









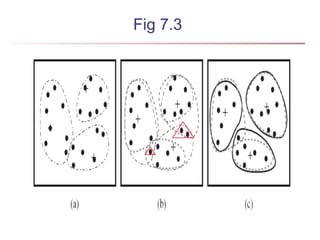


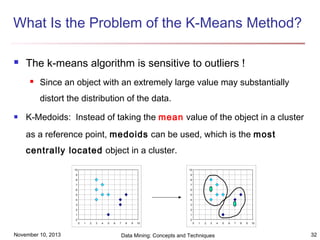

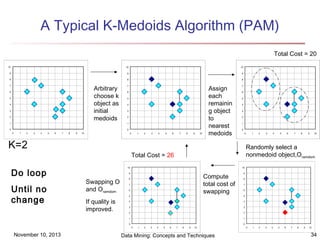






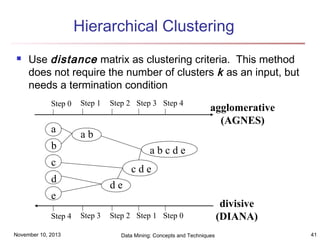


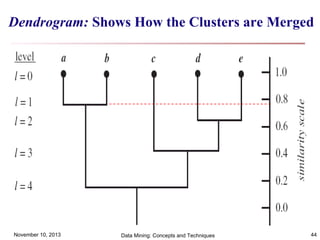

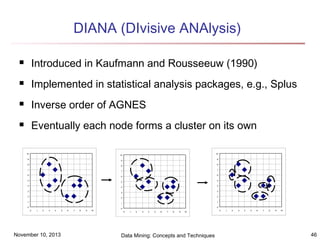








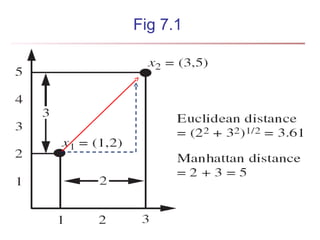
The document discusses cluster analysis and outlier analysis techniques for data mining. It covers key topics such as defining clusters and the goal of cluster analysis, different types of data that can be analyzed via clustering, major categories of clustering methods like partitioning, hierarchical, density-based, and model-based approaches. Specific clustering algorithms discussed include k-means, k-medoids, hierarchical clustering, DBSCAN, and EM. The document provides examples of clustering applications and discusses evaluating clustering quality and requirements for clustering in data mining.























































































