Download as PDF, PPTX
















































This document discusses the sequencing of the human genome and the role of bioinformatics. It notes that in 2000, the human genome was sequenced through a joint British and American effort, marking a major event that changed human history. The document then discusses how bioinformatics uses computational techniques to analyze and manage biological data, allowing things like comparing genetic material of viruses to design medicines. Overall, the document provides a high-level overview of the sequencing of the human genome and introduction to the field of bioinformatics.
Introduction of the speaker, M.Alroy Mascrenghe, discussing the presentation.
In 2000, a pivotal event occurred as the Human Genome was sequenced through a UK and US collaborative race.
Geneticists compare viral genetic material to develop medicines through protein identification from genetic sequences.
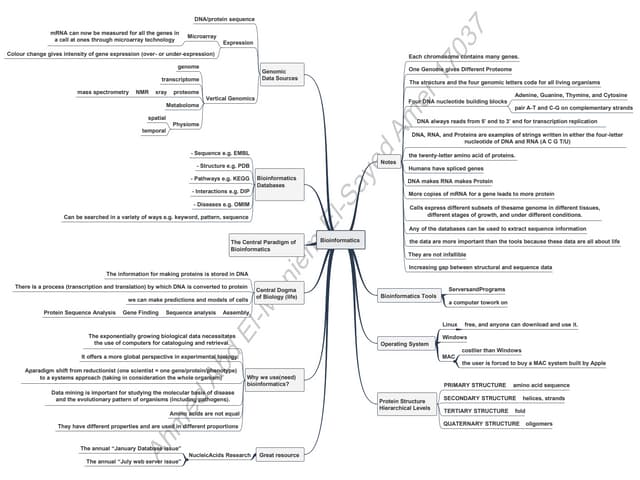
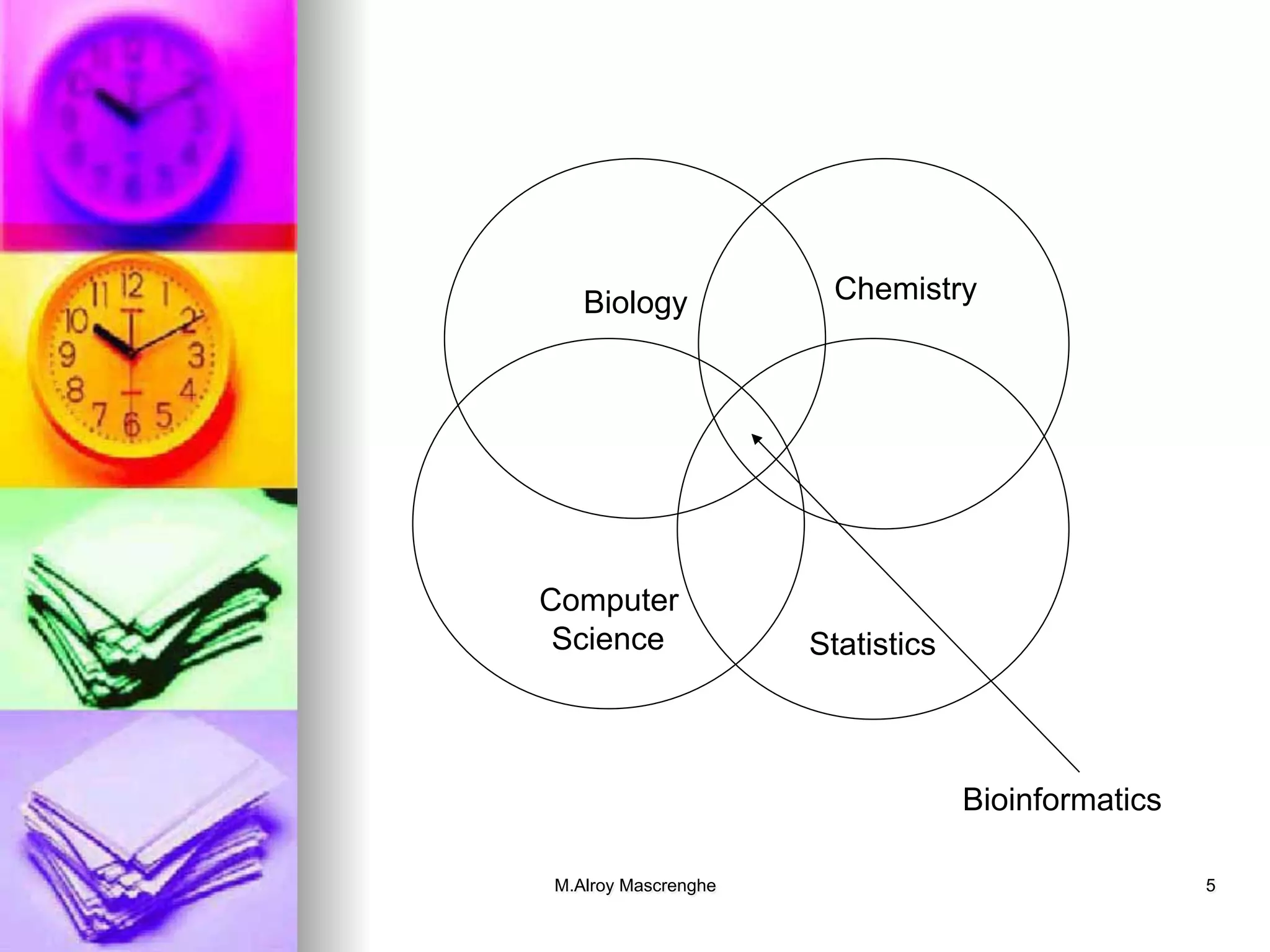
Integration of computer science and molecular biology for biological data management and analysis.
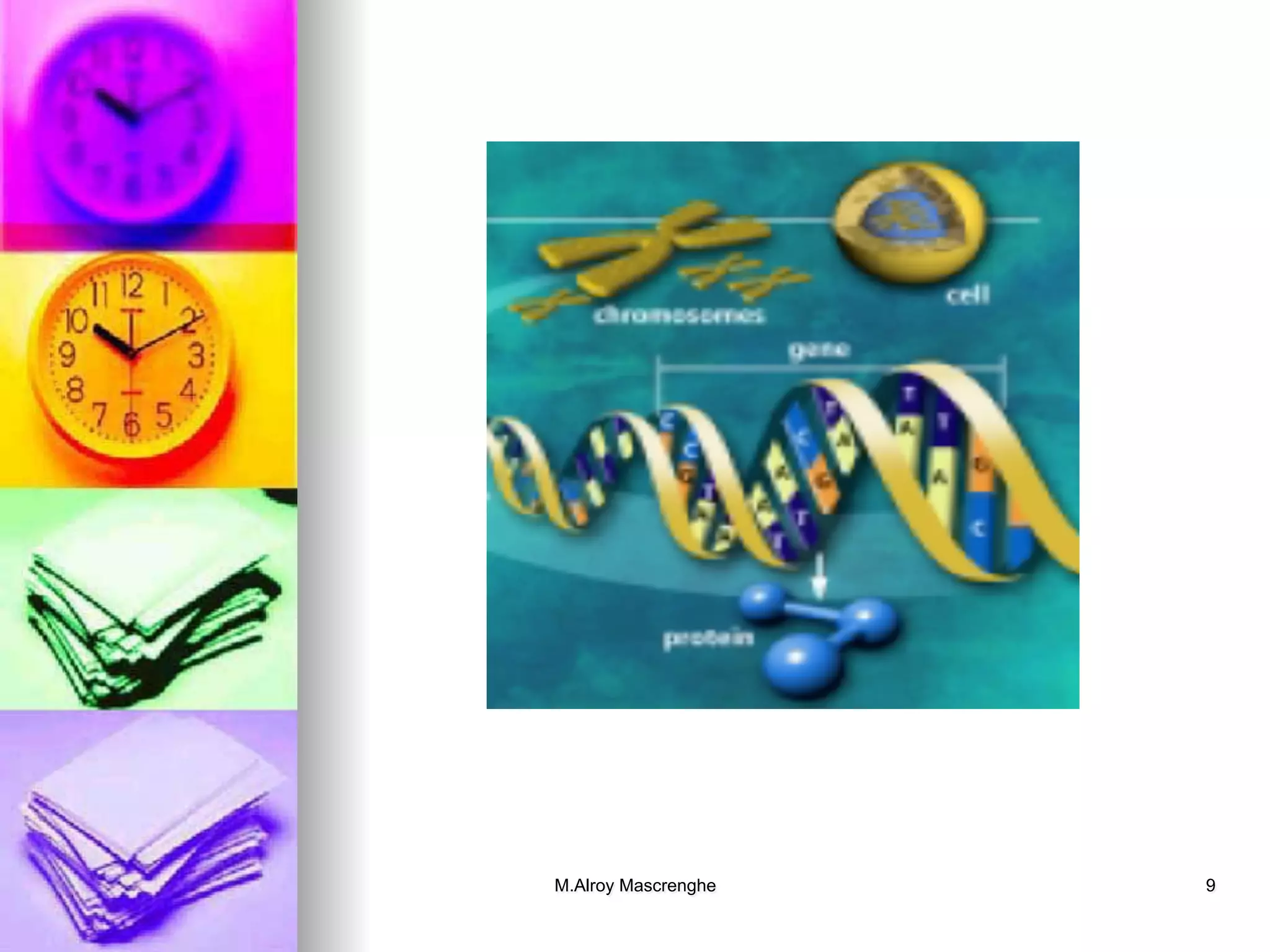
Covers DNA, nucleotides, and chromosomes, explaining genetic information storage and heredity.
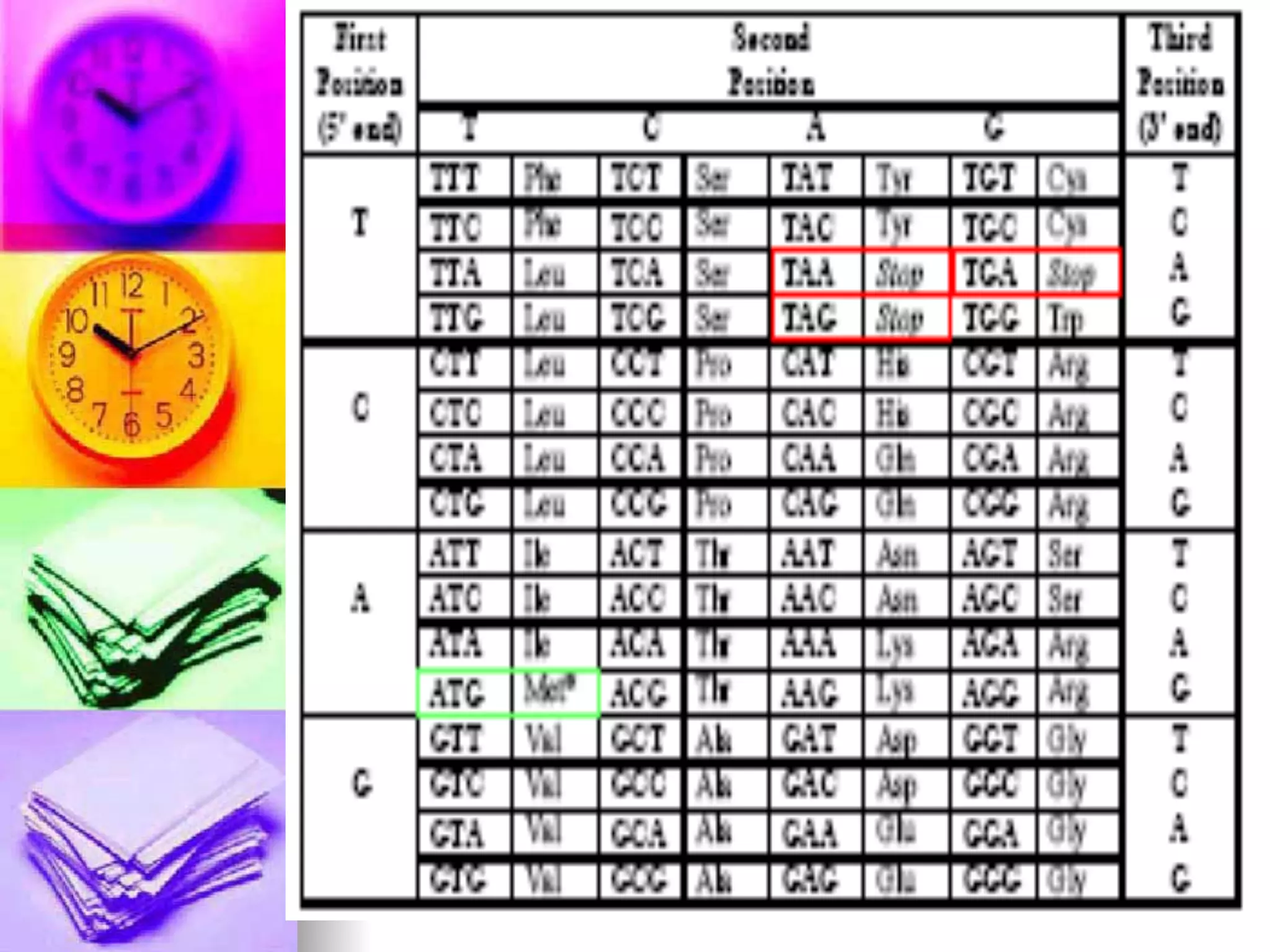
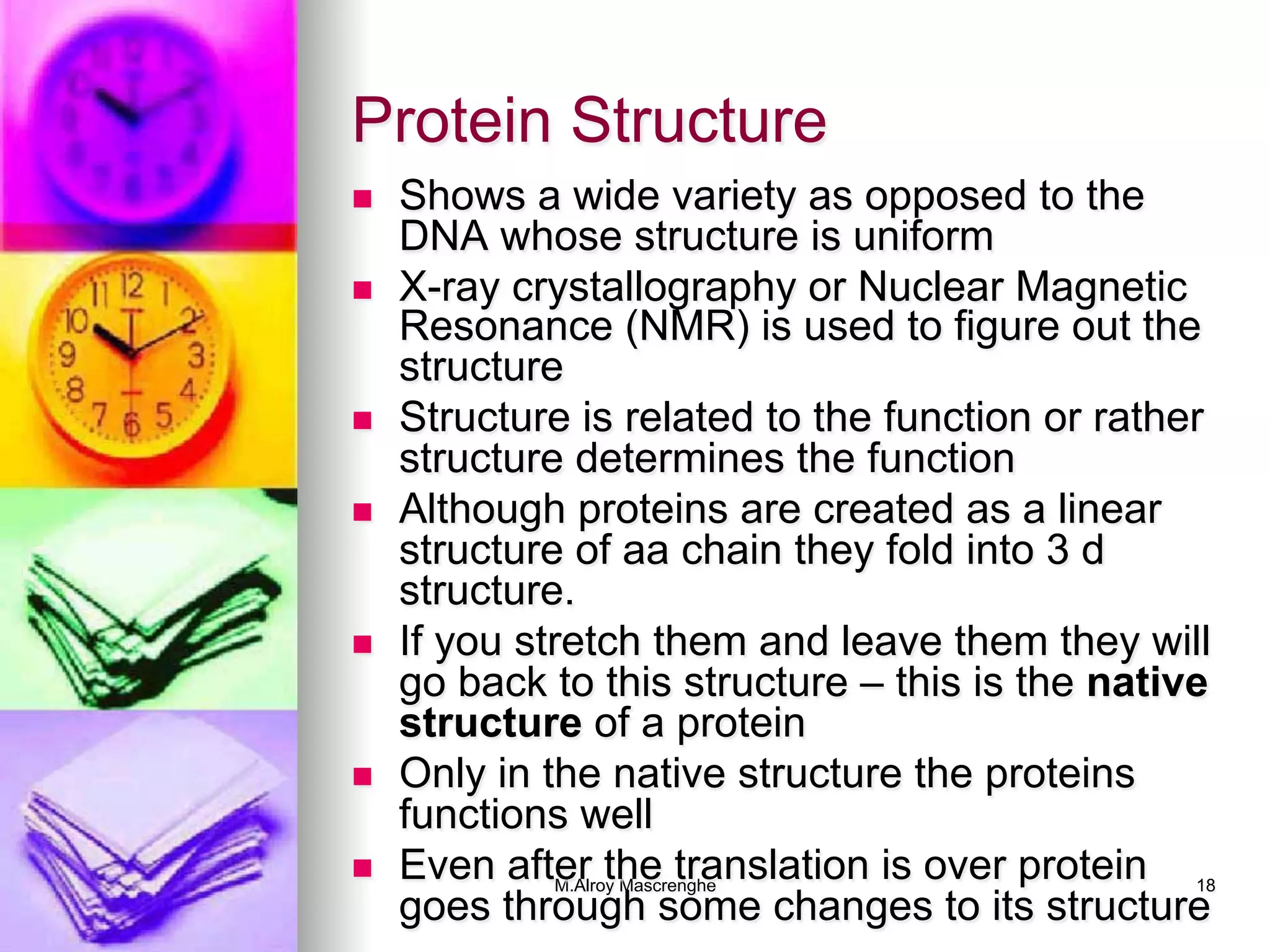
Details on proteins, their structure, formation from amino acids, and the central dogma of molecular biology involving DNA to RNA to protein.
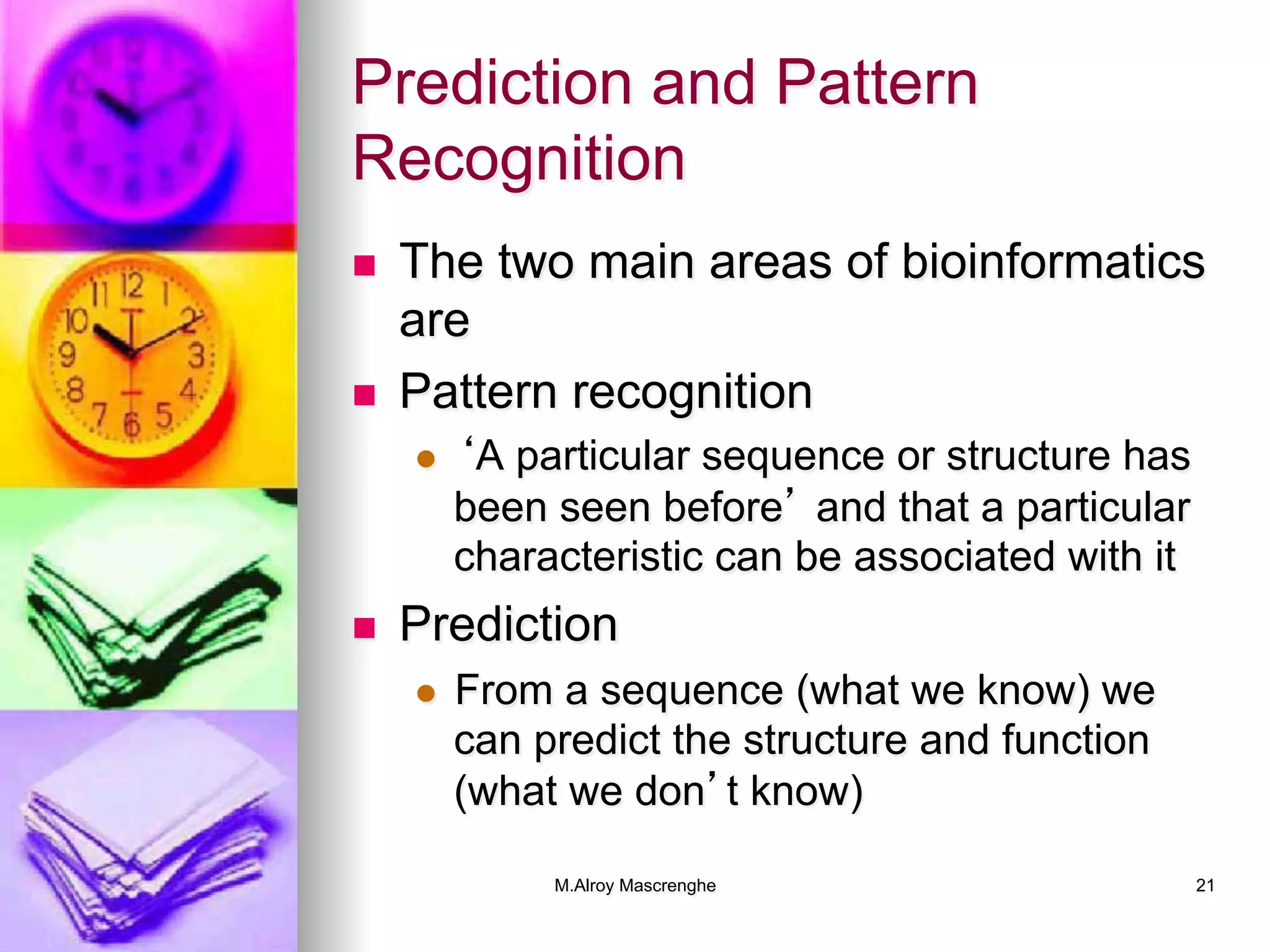
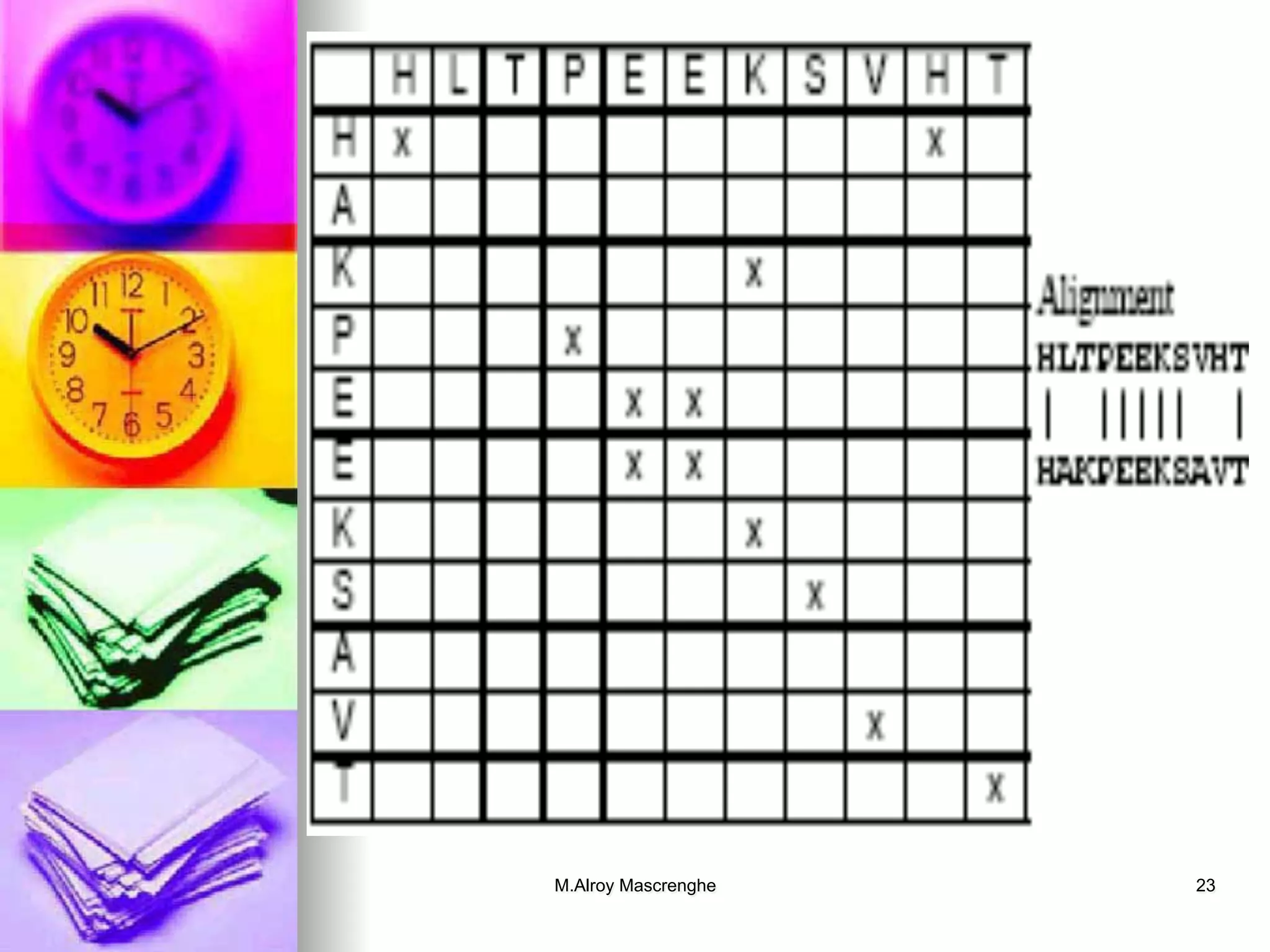
Techniques in bioinformatics including pattern recognition, sequence alignment, and scoring methods.
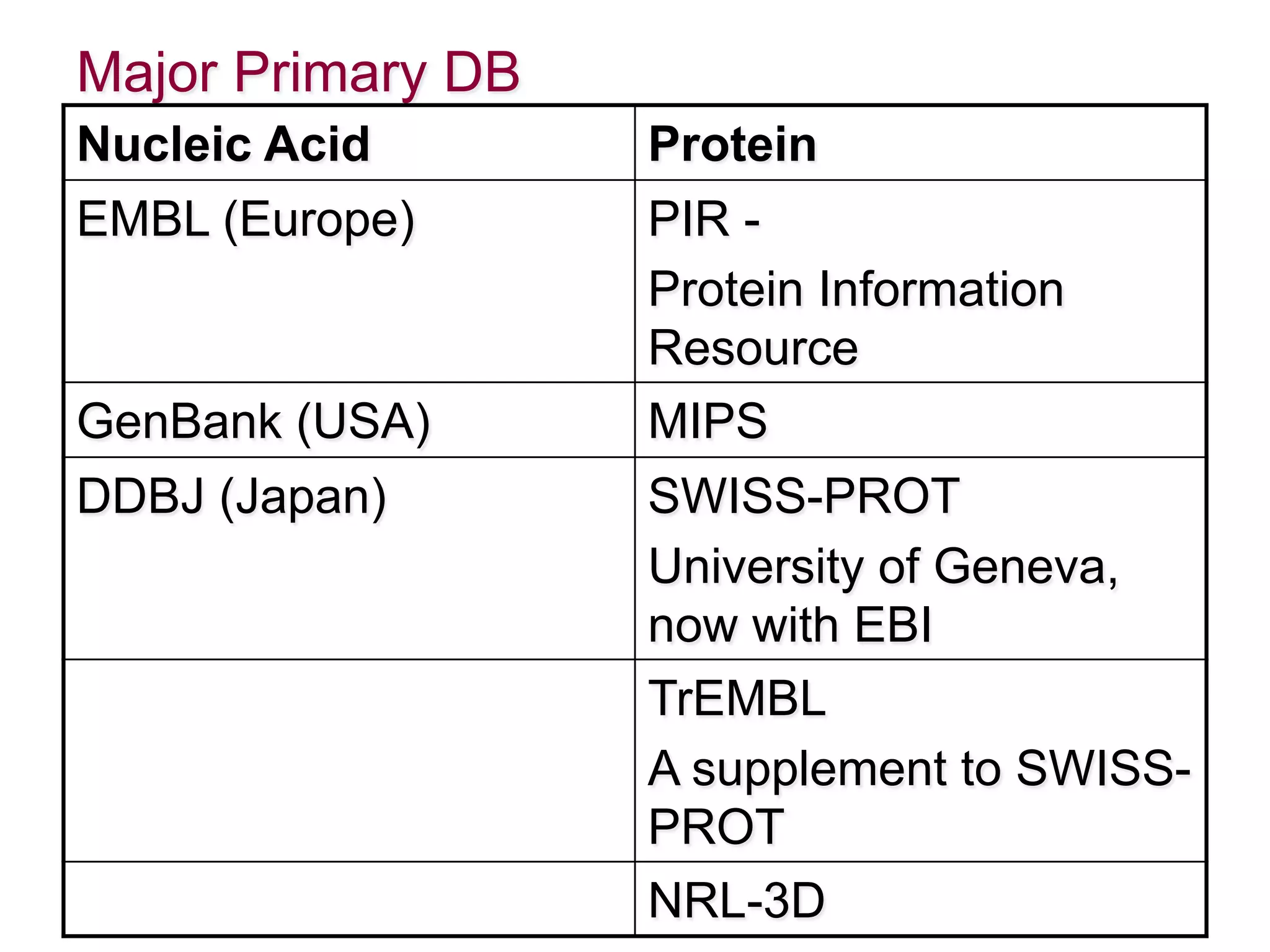
Discussion on various primary and composite databases for storing genetic sequences and the importance of organizing bioinformatics data.
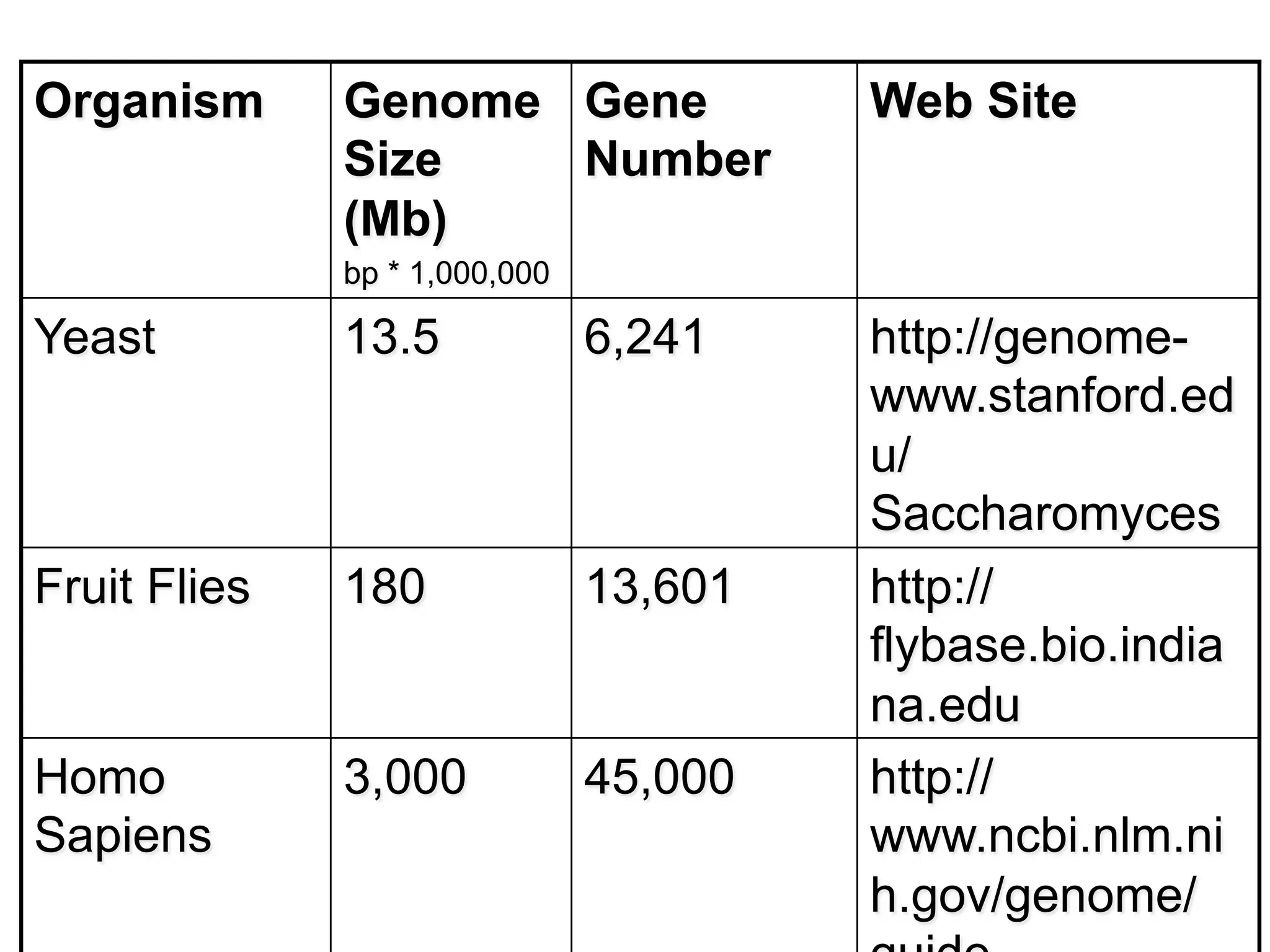
Insights into genomics, gene variations across cell types, and complexities involving the proteome.
The challenges associated with predicting protein structures using various methods including comparative modeling.
Exploration of medical implications, disease diagnosis through genetics, and drug design improvements.
Process of target identification in drug discovery and how bioinformatics is improving traditional methods.
The use of programming languages like PERL, XML for data representation, GRID systems for computation, and network resources for sharing bioinformatics information.Summarization, references used in the presentation, and a thank you note from the speaker.