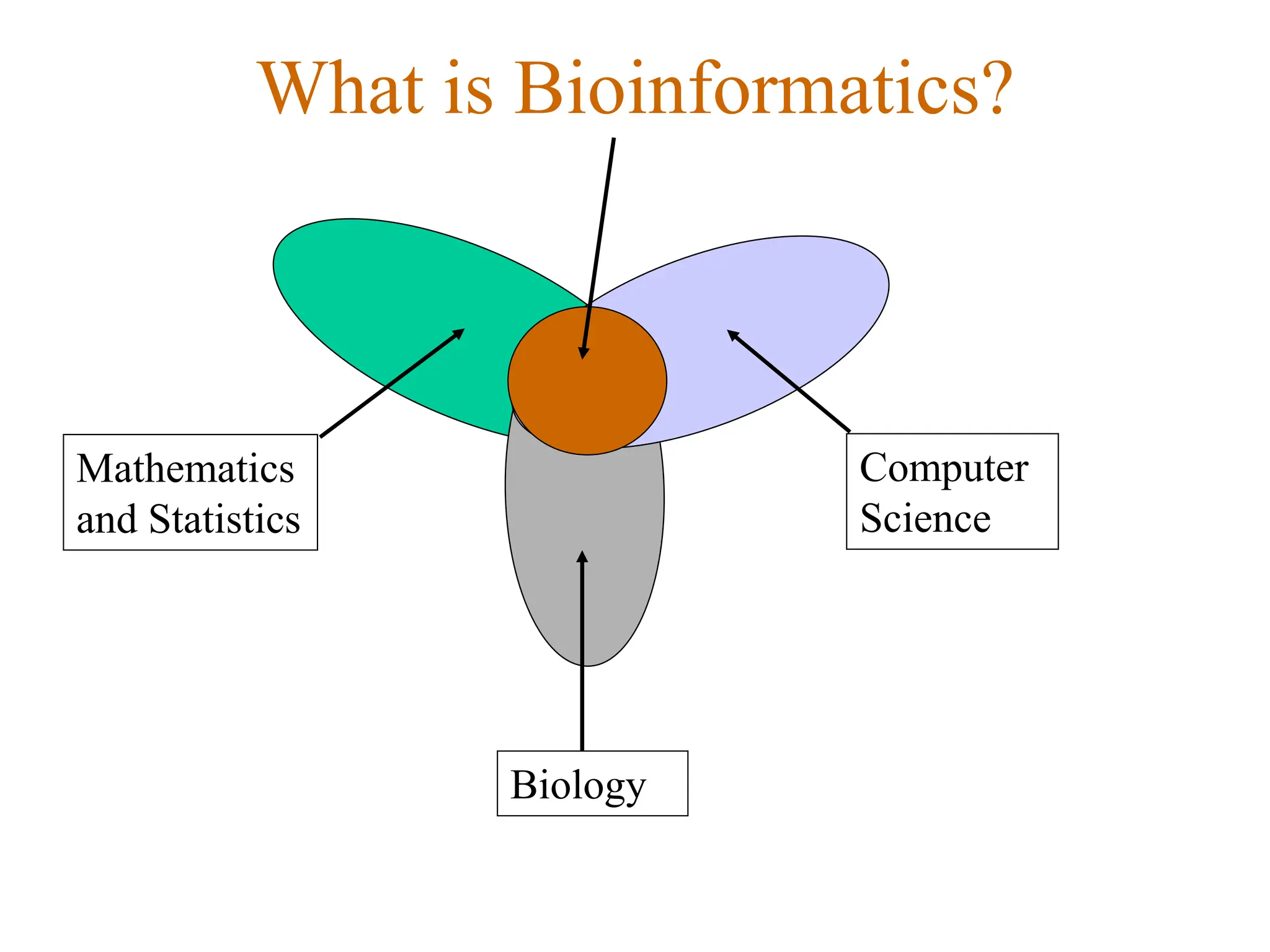
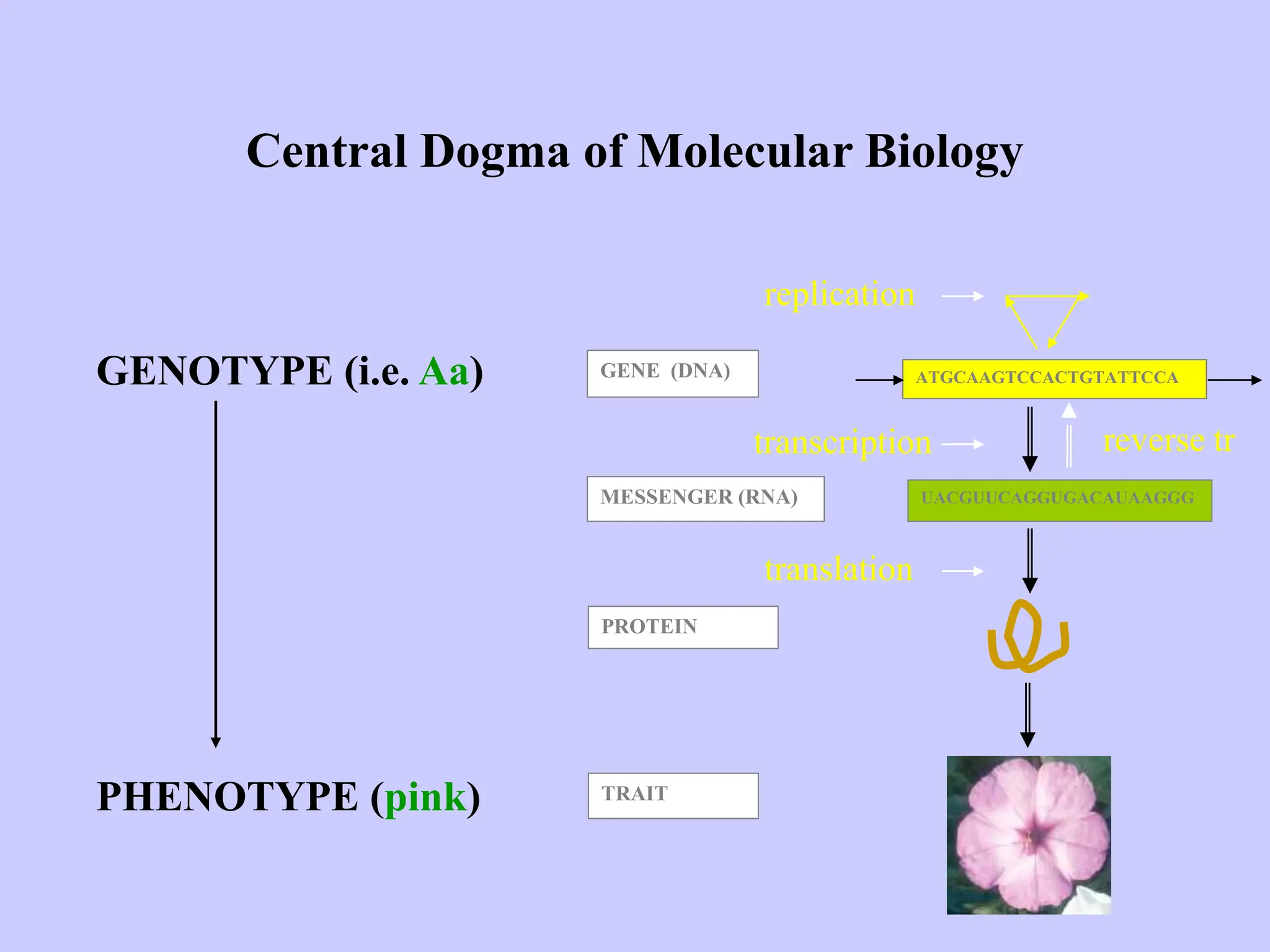
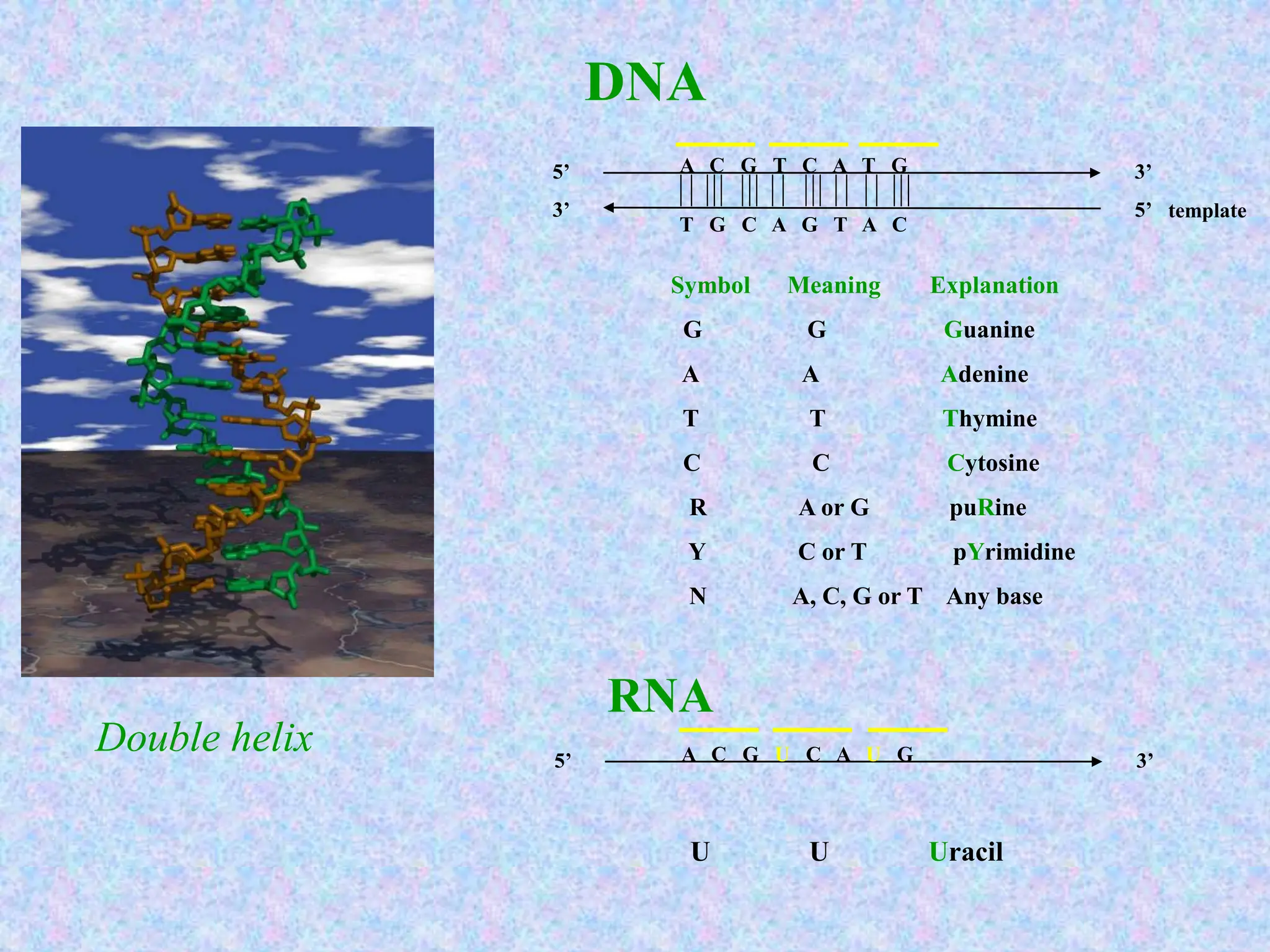
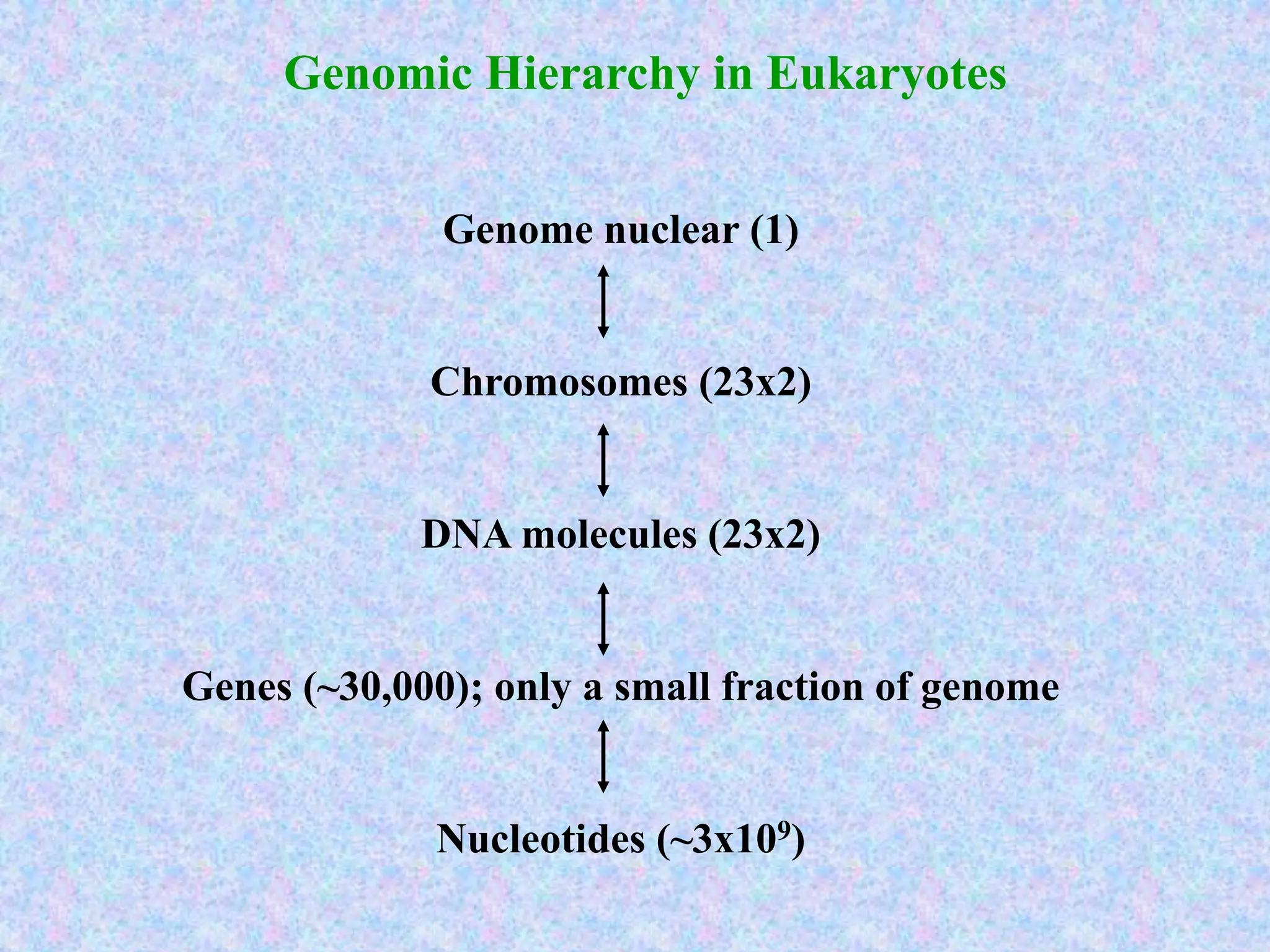
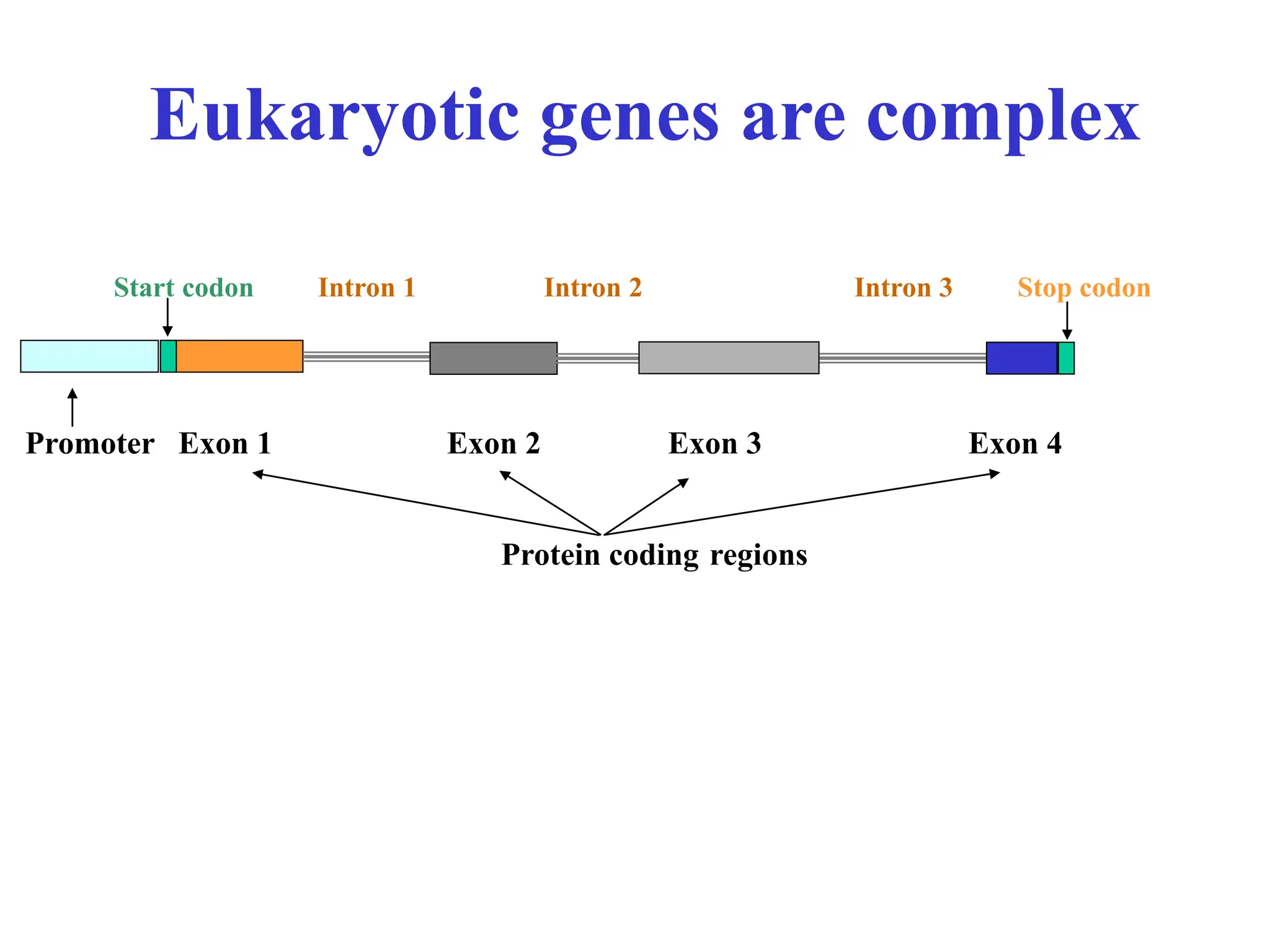
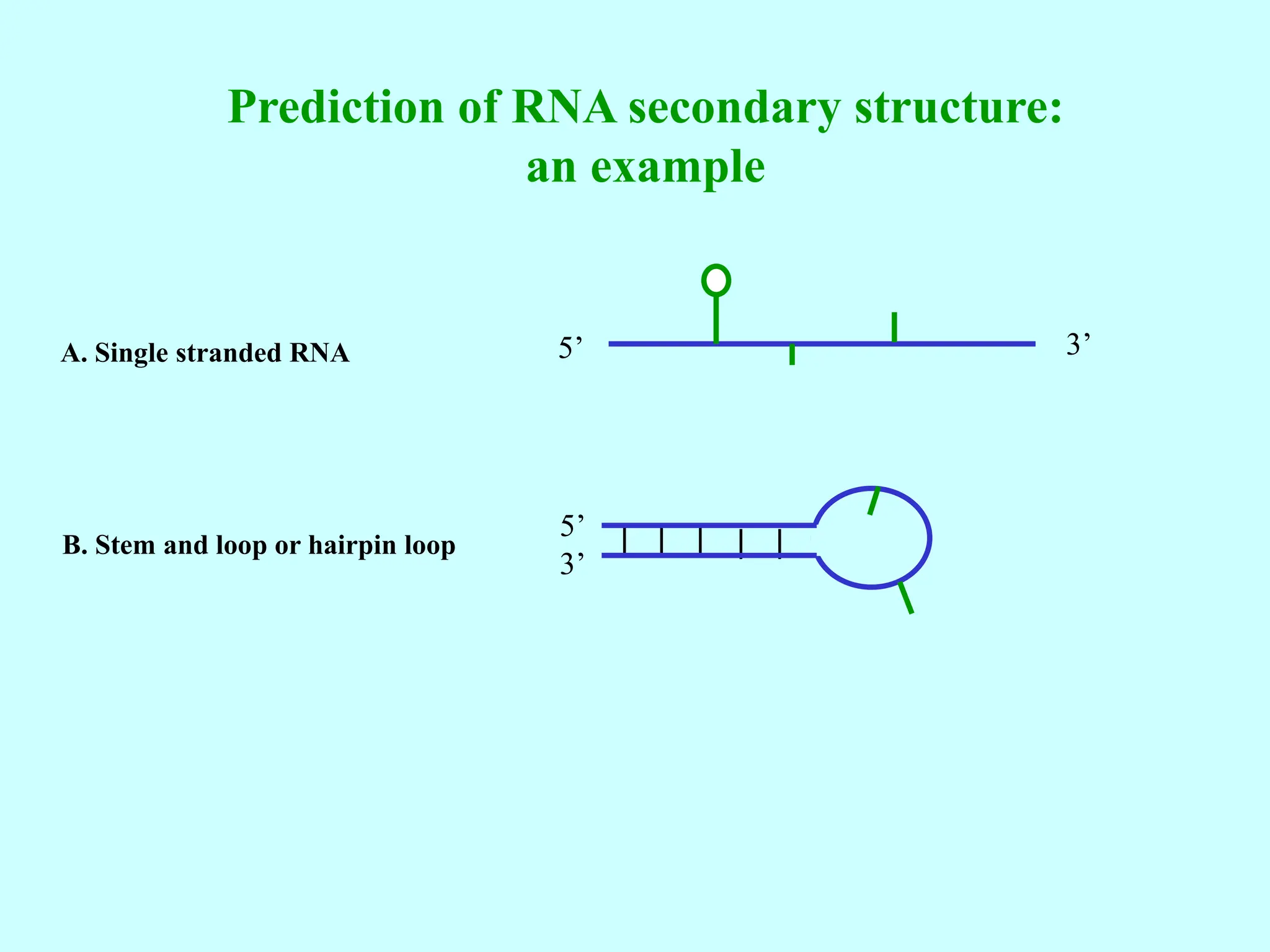
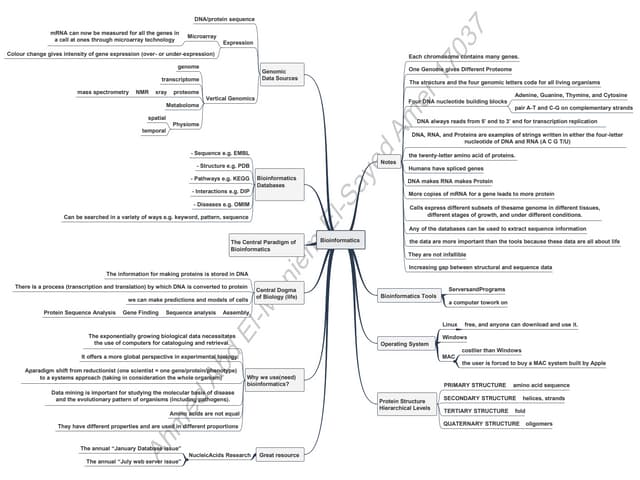
The document provides an overview of bioinformatics, including its definition, history, and key areas of application in molecular biology, medicine, and agriculture. It discusses the challenges faced in bioinformatics, such as data collection, retrieval, and the need for trained professionals. Additionally, it highlights the evolution of bioinformatics databases and the development of analytical techniques for understanding genetic information.