Download to read offline




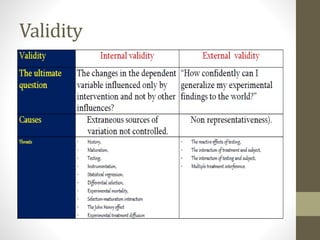
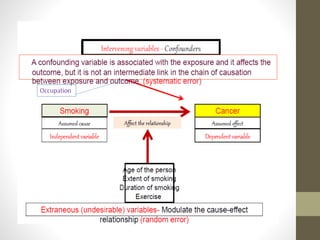






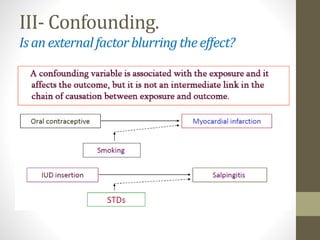


This document discusses types of variables and biases in observational studies. It defines categorical, confounding, continuous, control, dependent, discrete, independent, nominal, ordinal, qualitative, and quantitative variables. Selection bias, information bias, and confounding are described as common types of bias in observational designs. Selection bias results from a lack of comparability between study groups. Information bias occurs from incorrect determination of exposure or outcomes. Confounding involves external factors blurring the effect of the exposure being studied. Methods to address confounding include restriction, matching, stratification, and multivariate analysis techniques.



















































































![PERI-PROSTHETIC FRACTURE NAIL-PLATE CONSTRUCT [NPC].pptx](https://cdn.slidesharecdn.com/ss_thumbnails/drarunkumardrmohamedashrafperiprostheticfrasturenail-plateconstructnpc-260209164459-7e9d15a1-thumbnail.jpg?width=640&height=640&fit=bounds)



