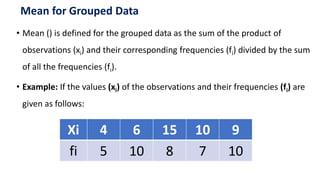
This document provides an overview of 7 basic statistical concepts for data science: 1) descriptive statistics such as mean, mode, median, and standard deviation, 2) measures of variability like variance and range, 3) correlation, 4) probability distributions, 5) regression, 6) normal distribution, and 7) types of bias. Descriptive statistics are used to summarize data, variability measures dispersion, correlation measures relationships between variables, and probability distributions specify likelihoods of events. Regression models relationships, normal distribution is often assumed, and biases can influence analyses.