Download free for 30 days
Sign in
Upload
Language (EN)
Support
Business
Mobile
Social Media
Marketing
Technology
Art & Photos
Career
Design
Education
Presentations & Public Speaking
Government & Nonprofit
Healthcare
Internet
Law
Leadership & Management
Automotive
Engineering
Software
Recruiting & HR
Retail
Sales
Services
Science
Small Business & Entrepreneurship
Food
Environment
Economy & Finance
Data & Analytics
Investor Relations
Sports
Spiritual
News & Politics
Travel
Self Improvement
Real Estate
Entertainment & Humor
Health & Medicine
Devices & Hardware
Lifestyle
Change Language
Language
English
Español
Português
Français
Deutsche
Cancel
Save
Submit search
EN
Uploaded by
Deep Learning Lab(ディープラーニング・ラボ)
PDF, PPTX
3,298 views
[Track2-2] 最新のNVIDIA AmpereアーキテクチャによるNVIDIA A100 TensorコアGPUの特長とその性能を引き出す方法
2020/8/1 Deep Learning Digital Conference エヌビディア合同会社 佐々木 邦暢 氏
Technology
◦
Read more
1
Save
Share
Embed
Embed presentation
Download
Download as PDF, PPTX
1
/ 39
2
/ 39
3
/ 39
4
/ 39
5
/ 39
6
/ 39
7
/ 39
8
/ 39
9
/ 39
10
/ 39
11
/ 39
12
/ 39
13
/ 39
14
/ 39
15
/ 39
16
/ 39
17
/ 39
18
/ 39
19
/ 39
20
/ 39
21
/ 39
22
/ 39
23
/ 39
24
/ 39
25
/ 39
26
/ 39
27
/ 39
28
/ 39
29
/ 39
30
/ 39
31
/ 39
32
/ 39
33
/ 39
34
/ 39
35
/ 39
36
/ 39
37
/ 39
38
/ 39
39
/ 39
More Related Content
PDF
CUDAプログラミング入門
by
NVIDIA Japan
PPTX
CPU / GPU高速化セミナー!性能モデルの理論と実践:理論編
by
Fixstars Corporation
PDF
いまさら聞けない!CUDA高速化入門
by
Fixstars Corporation
PDF
「NVIDIA プロファイラを用いたPyTorch学習最適化手法のご紹介(修正版)」
by
ManaMurakami1
PPTX
Swin Transformer (ICCV'21 Best Paper) を完璧に理解する資料
by
Yusuke Uchida
PDF
Transformer メタサーベイ
by
cvpaper. challenge
PDF
1076: CUDAデバッグ・プロファイリング入門
by
NVIDIA Japan
PDF
RAPIDS 概要
by
NVIDIA Japan
CUDAプログラミング入門
by
NVIDIA Japan
CPU / GPU高速化セミナー!性能モデルの理論と実践:理論編
by
Fixstars Corporation
いまさら聞けない!CUDA高速化入門
by
Fixstars Corporation
「NVIDIA プロファイラを用いたPyTorch学習最適化手法のご紹介(修正版)」
by
ManaMurakami1
Swin Transformer (ICCV'21 Best Paper) を完璧に理解する資料
by
Yusuke Uchida
Transformer メタサーベイ
by
cvpaper. challenge
1076: CUDAデバッグ・プロファイリング入門
by
NVIDIA Japan
RAPIDS 概要
by
NVIDIA Japan
What's hot
PDF
【メタサーベイ】Vision and Language のトップ研究室/研究者
by
cvpaper. challenge
PDF
【メタサーベイ】基盤モデル / Foundation Models
by
cvpaper. challenge
PDF
ゼロから始める深層強化学習(NLP2018講演資料)/ Introduction of Deep Reinforcement Learning
by
Preferred Networks
PDF
Tensorflow Liteの量子化アーキテクチャ
by
HitoshiSHINABE1
PPTX
Triplet Loss 徹底解説
by
tancoro
PDF
分散学習のあれこれ~データパラレルからモデルパラレルまで~
by
Hideki Tsunashima
PPTX
[DL輪読会]相互情報量最大化による表現学習
by
Deep Learning JP
PDF
三次元点群を取り扱うニューラルネットワークのサーベイ
by
Naoya Chiba
PDF
モデルアーキテクチャ観点からのDeep Neural Network高速化
by
Yusuke Uchida
PDF
マルチコアを用いた画像処理
by
Norishige Fukushima
PDF
TensorFlow計算グラフ最適化処理
by
Atsushi Nukariya
PDF
Visual slam
by
Takuya Minagawa
PDF
UE4ディープラーニングってやつでなんとかして!環境構築編(Python3+TensorFlow)
by
エピック・ゲームズ・ジャパン Epic Games Japan
PDF
【論文読み会】Deep Clustering for Unsupervised Learning of Visual Features
by
ARISE analytics
PDF
組み込み関数(intrinsic)によるSIMD入門
by
Norishige Fukushima
PDF
SSII2022 [OS3-02] Federated Learningの基礎と応用
by
SSII
PDF
BERT入門
by
Ken'ichi Matsui
PDF
1070: CUDA プログラミング入門
by
NVIDIA Japan
PDF
2015年度GPGPU実践プログラミング 第15回 GPU最適化ライブラリ
by
智啓 出川
PDF
第12回 配信講義 計算科学技術特論B(2022)
by
RCCSRENKEI
【メタサーベイ】Vision and Language のトップ研究室/研究者
by
cvpaper. challenge
【メタサーベイ】基盤モデル / Foundation Models
by
cvpaper. challenge
ゼロから始める深層強化学習(NLP2018講演資料)/ Introduction of Deep Reinforcement Learning
by
Preferred Networks
Tensorflow Liteの量子化アーキテクチャ
by
HitoshiSHINABE1
Triplet Loss 徹底解説
by
tancoro
分散学習のあれこれ~データパラレルからモデルパラレルまで~
by
Hideki Tsunashima
[DL輪読会]相互情報量最大化による表現学習
by
Deep Learning JP
三次元点群を取り扱うニューラルネットワークのサーベイ
by
Naoya Chiba
モデルアーキテクチャ観点からのDeep Neural Network高速化
by
Yusuke Uchida
マルチコアを用いた画像処理
by
Norishige Fukushima
TensorFlow計算グラフ最適化処理
by
Atsushi Nukariya
Visual slam
by
Takuya Minagawa
UE4ディープラーニングってやつでなんとかして!環境構築編(Python3+TensorFlow)
by
エピック・ゲームズ・ジャパン Epic Games Japan
【論文読み会】Deep Clustering for Unsupervised Learning of Visual Features
by
ARISE analytics
組み込み関数(intrinsic)によるSIMD入門
by
Norishige Fukushima
SSII2022 [OS3-02] Federated Learningの基礎と応用
by
SSII
BERT入門
by
Ken'ichi Matsui
1070: CUDA プログラミング入門
by
NVIDIA Japan
2015年度GPGPU実践プログラミング 第15回 GPU最適化ライブラリ
by
智啓 出川
第12回 配信講義 計算科学技術特論B(2022)
by
RCCSRENKEI
Similar to [Track2-2] 最新のNVIDIA AmpereアーキテクチャによるNVIDIA A100 TensorコアGPUの特長とその性能を引き出す方法
PDF
A100 GPU 搭載! P4d インスタンス 使いこなしのコツ
by
Kuninobu SaSaki
PDF
Automatic Mixed Precision の紹介
by
Kuninobu SaSaki
PPTX
機械学習 / Deep Learning 大全 (4) GPU編
by
Daiyu Hatakeyama
PDF
【de:code 2020】 AI とデータ サイエンスを加速する NVIDIA の最新 GPU アーキテクチャ
by
日本マイクロソフト株式会社
PDF
【A-1】AIを支えるGPUコンピューティングの今
by
Developers Summit
PDF
2009/12/10 GPUコンピューティングの現状とスーパーコンピューティングの未来
by
Preferred Networks
PDF
GPUディープラーニング最新情報
by
ReNom User Group
PDF
【旧版】2009/12/10 GPUコンピューティングの現状とスーパーコンピューティングの未来
by
Preferred Networks
PDF
GTC 2020 発表内容まとめ
by
NVIDIA Japan
PDF
GTC 2020 発表内容まとめ
by
Aya Owosekun
PDF
NVIDIA TESLA V100・CUDA 9 のご紹介
by
NVIDIA Japan
PDF
[db analytics showcase Sapporo 2017] B14: GPU コンピューティング最前線 by エヌビディア 佐々木邦暢
by
Insight Technology, Inc.
KEY
GPGPU deいろんな問題解いてみた
by
Ryo Sakamoto
PDF
Cuda
by
Shumpei Hozumi
PDF
GTC 2017 基調講演からディープラーニング関連情報のご紹介
by
NVIDIA Japan
PDF
20170421 tensor flowusergroup
by
ManaMurakami1
PDF
機械学習とこれを支える並列計算: ディープラーニング・スーパーコンピューターの応用について
by
ハイシンク創研 / Laboratory of Hi-Think Corporation
PDF
Deep Learning Lab MeetUp 学習編 AzureインフラとBatch AI
by
喜智 大井
PDF
AWS Webinar 20201224
by
陽平 山口
DOC
GPGPUによるパーソナルスーパーコンピュータの可能性
by
Yusaku Watanabe
A100 GPU 搭載! P4d インスタンス 使いこなしのコツ
by
Kuninobu SaSaki
Automatic Mixed Precision の紹介
by
Kuninobu SaSaki
機械学習 / Deep Learning 大全 (4) GPU編
by
Daiyu Hatakeyama
【de:code 2020】 AI とデータ サイエンスを加速する NVIDIA の最新 GPU アーキテクチャ
by
日本マイクロソフト株式会社
【A-1】AIを支えるGPUコンピューティングの今
by
Developers Summit
2009/12/10 GPUコンピューティングの現状とスーパーコンピューティングの未来
by
Preferred Networks
GPUディープラーニング最新情報
by
ReNom User Group
【旧版】2009/12/10 GPUコンピューティングの現状とスーパーコンピューティングの未来
by
Preferred Networks
GTC 2020 発表内容まとめ
by
NVIDIA Japan
GTC 2020 発表内容まとめ
by
Aya Owosekun
NVIDIA TESLA V100・CUDA 9 のご紹介
by
NVIDIA Japan
[db analytics showcase Sapporo 2017] B14: GPU コンピューティング最前線 by エヌビディア 佐々木邦暢
by
Insight Technology, Inc.
GPGPU deいろんな問題解いてみた
by
Ryo Sakamoto
Cuda
by
Shumpei Hozumi
GTC 2017 基調講演からディープラーニング関連情報のご紹介
by
NVIDIA Japan
20170421 tensor flowusergroup
by
ManaMurakami1
機械学習とこれを支える並列計算: ディープラーニング・スーパーコンピューターの応用について
by
ハイシンク創研 / Laboratory of Hi-Think Corporation
Deep Learning Lab MeetUp 学習編 AzureインフラとBatch AI
by
喜智 大井
AWS Webinar 20201224
by
陽平 山口
GPGPUによるパーソナルスーパーコンピュータの可能性
by
Yusaku Watanabe
More from Deep Learning Lab(ディープラーニング・ラボ)
PDF
深層強化学習と実装例
by
Deep Learning Lab(ディープラーニング・ラボ)
PDF
Jetson x Azure ハンズオン DeepStream Azure IoT
by
Deep Learning Lab(ディープラーニング・ラボ)
PDF
深層強化学習を用いた複合機の搬送制御
by
Deep Learning Lab(ディープラーニング・ラボ)
PDF
Edge AI ソリューションを支える Azure IoT サービス
by
Deep Learning Lab(ディープラーニング・ラボ)
PDF
Jetson x Azure ハンズオン DeepStream With Azure IoT
by
Deep Learning Lab(ディープラーニング・ラボ)
PDF
[Track3-2] AI活用人材の社内育成に関する取り組みについて ~ダイキン情報技術大学~
by
Deep Learning Lab(ディープラーニング・ラボ)
PDF
[Track1-2] ディープラーニングを用いたワインブドウの収穫量予測
by
Deep Learning Lab(ディープラーニング・ラボ)
PDF
厚生労働分野におけるAI技術の利活用について
by
Deep Learning Lab(ディープラーニング・ラボ)
PDF
Jetson 活用による スタートアップ企業支援
by
Deep Learning Lab(ディープラーニング・ラボ)
PDF
Intel AI in Healthcare 各国事例からみるAIとの向き合い方
by
Deep Learning Lab(ディープラーニング・ラボ)
PDF
Jetson x Azure ハンズオン DeepStream With Azure IoT 事前準備
by
Deep Learning Lab(ディープラーニング・ラボ)
PDF
AIによる細胞診支援技術の紹介と、AI人材が考える医療バイオ領域における参入障壁の乗り越え方
by
Deep Learning Lab(ディープラーニング・ラボ)
PDF
Azure ML 強化学習を用いた最新アルゴリズムの活用手法
by
Deep Learning Lab(ディープラーニング・ラボ)
PDF
[Track1-1] AIの売上予測を発注システムに組み込んだリンガーハットのデータ活用戦略
by
Deep Learning Lab(ディープラーニング・ラボ)
PDF
「言語」×AI Digital Device
by
Deep Learning Lab(ディープラーニング・ラボ)
PDF
医学と工学の垣根を越えた医療AI開発
by
Deep Learning Lab(ディープラーニング・ラボ)
PDF
[Track 4-6] ディープラーニングxものづくりが日本を強くする ~高専DCONの挑戦~
by
Deep Learning Lab(ディープラーニング・ラボ)
PDF
DLLAB Healthcare Day 2021 Event Report
by
Deep Learning Lab(ディープラーニング・ラボ)
PDF
先端技術がもたらす「より良いヘルスケアのかたち」
by
Deep Learning Lab(ディープラーニング・ラボ)
PPTX
ICTを用いた健康なまちづくりの 取り組みとAI活用への期待
by
Deep Learning Lab(ディープラーニング・ラボ)
深層強化学習と実装例
by
Deep Learning Lab(ディープラーニング・ラボ)
Jetson x Azure ハンズオン DeepStream Azure IoT
by
Deep Learning Lab(ディープラーニング・ラボ)
深層強化学習を用いた複合機の搬送制御
by
Deep Learning Lab(ディープラーニング・ラボ)
Edge AI ソリューションを支える Azure IoT サービス
by
Deep Learning Lab(ディープラーニング・ラボ)
Jetson x Azure ハンズオン DeepStream With Azure IoT
by
Deep Learning Lab(ディープラーニング・ラボ)
[Track3-2] AI活用人材の社内育成に関する取り組みについて ~ダイキン情報技術大学~
by
Deep Learning Lab(ディープラーニング・ラボ)
[Track1-2] ディープラーニングを用いたワインブドウの収穫量予測
by
Deep Learning Lab(ディープラーニング・ラボ)
厚生労働分野におけるAI技術の利活用について
by
Deep Learning Lab(ディープラーニング・ラボ)
Jetson 活用による スタートアップ企業支援
by
Deep Learning Lab(ディープラーニング・ラボ)
Intel AI in Healthcare 各国事例からみるAIとの向き合い方
by
Deep Learning Lab(ディープラーニング・ラボ)
Jetson x Azure ハンズオン DeepStream With Azure IoT 事前準備
by
Deep Learning Lab(ディープラーニング・ラボ)
AIによる細胞診支援技術の紹介と、AI人材が考える医療バイオ領域における参入障壁の乗り越え方
by
Deep Learning Lab(ディープラーニング・ラボ)
Azure ML 強化学習を用いた最新アルゴリズムの活用手法
by
Deep Learning Lab(ディープラーニング・ラボ)
[Track1-1] AIの売上予測を発注システムに組み込んだリンガーハットのデータ活用戦略
by
Deep Learning Lab(ディープラーニング・ラボ)
「言語」×AI Digital Device
by
Deep Learning Lab(ディープラーニング・ラボ)
医学と工学の垣根を越えた医療AI開発
by
Deep Learning Lab(ディープラーニング・ラボ)
[Track 4-6] ディープラーニングxものづくりが日本を強くする ~高専DCONの挑戦~
by
Deep Learning Lab(ディープラーニング・ラボ)
DLLAB Healthcare Day 2021 Event Report
by
Deep Learning Lab(ディープラーニング・ラボ)
先端技術がもたらす「より良いヘルスケアのかたち」
by
Deep Learning Lab(ディープラーニング・ラボ)
ICTを用いた健康なまちづくりの 取り組みとAI活用への期待
by
Deep Learning Lab(ディープラーニング・ラボ)
Recently uploaded
PDF
エンジニアが選ぶべきAIエディタ & Antigravity 活用例@ウェビナー「触ってみてどうだった?Google Antigravity 既存IDEと...
by
NorihiroSunada
PPTX
楽々ナレッジベース「楽ナレ」3種比較 - Dify / AWS S3 Vector / Google File Search Tool
by
Kiyohide Yamaguchi
PDF
Machine Tests Benchmark Suite. Explain github.com/alexziskind1/machine_tests #2
by
Tasuku Takahashi
PDF
Machine Tests Benchmark Suite. Explain github.com/alexziskind1/machine_tests #1
by
Tasuku Takahashi
PDF
流行りに乗っかるClaris FileMaker 〜AI関連機能の紹介〜 by 合同会社イボルブ
by
Evolve LLC.
PDF
20251210_MultiDevinForEnterprise on Devin 1st Anniv Meetup
by
Masaki Yamakawa
エンジニアが選ぶべきAIエディタ & Antigravity 活用例@ウェビナー「触ってみてどうだった?Google Antigravity 既存IDEと...
by
NorihiroSunada
楽々ナレッジベース「楽ナレ」3種比較 - Dify / AWS S3 Vector / Google File Search Tool
by
Kiyohide Yamaguchi
Machine Tests Benchmark Suite. Explain github.com/alexziskind1/machine_tests #2
by
Tasuku Takahashi
Machine Tests Benchmark Suite. Explain github.com/alexziskind1/machine_tests #1
by
Tasuku Takahashi
流行りに乗っかるClaris FileMaker 〜AI関連機能の紹介〜 by 合同会社イボルブ
by
Evolve LLC.
20251210_MultiDevinForEnterprise on Devin 1st Anniv Meetup
by
Masaki Yamakawa
[Track2-2] 最新のNVIDIA AmpereアーキテクチャによるNVIDIA A100 TensorコアGPUの特長とその性能を引き出す方法
1.
佐々木邦暢 (@_ksasaki) エヌビディア合同会社 最新の NVIDIA
AMPERE アーキテクチャに よる NVIDIA A100 TENSOR コア GPU の 特長とその性能を引き出す方法
2.
2 NVIDIA A100 Tensor
コア GPU かつてない飛躍 - Volta 比最大 20 倍のピーク性能 54B XTOR | 826mm2 | TSMC 7N | 40GB Samsung HBM2 | 600 GB/s NVLink ピーク性能 V100 比 FP32 トレーニング 312 TFLOPS 20X INT8 インファレンス 1,248 TOPS 20X FP64 HPC 19.5 TFLOPS 2.5X Multi-instance GPU (MIG) 7X GPUs
3.
Tensor コアによる混合精度トレーニング
4.
https://arxiv.org/abs/1710.03740
5.
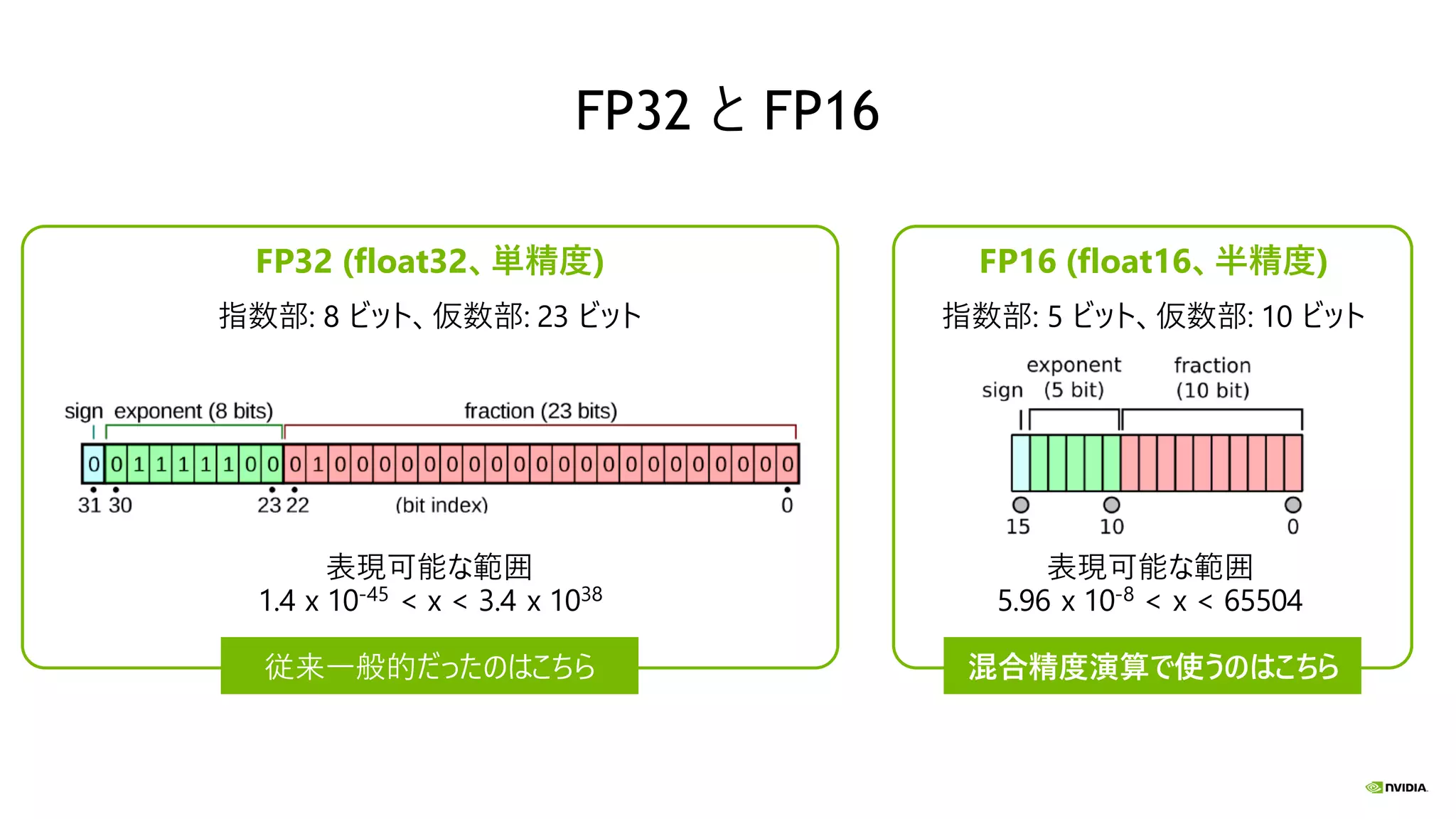
FP32 と FP16 FP32
(float32、単精度) FP16 (float16、半精度) 指数部: 8 ビット、仮数部: 23 ビット 指数部: 5 ビット、仮数部: 10 ビット 表現可能な範囲 1.4 x 10-45 < x < 3.4 x 1038 表現可能な範囲 5.96 x 10-8 < x < 65504 従来一般的だったのはこちら 混合精度演算で使うのはこちら
6.
FP16 を使うことの利点 メモリが節約できる、だけではない "half-precision math
throughput in recent GPUs is 2× to 8× higher than for single-precision." 「最近の GPU では FP16 の演算スループットが FP32 の 2 倍から 8 倍高い」 https://arxiv.org/abs/1710.03740
7.
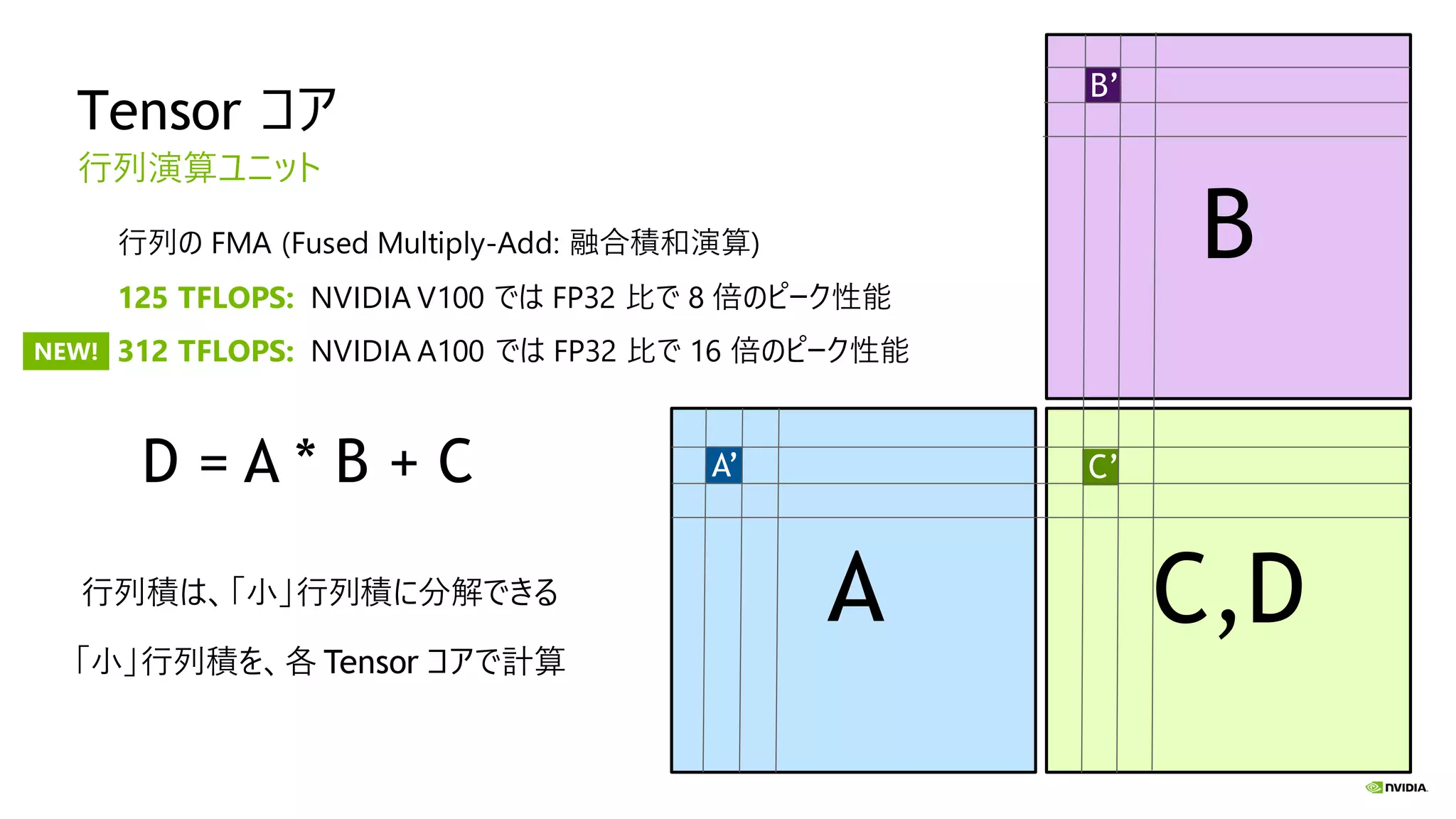
Tensor コア 行列演算ユニット D =
A * B + C C,DA B 行列積は、「小」行列積に分解できる 「小」行列積を、各 Tensor コアで計算 A’ B’ C’ 行列の FMA (Fused Multiply-Add: 融合積和演算) 125 TFLOPS: NVIDIA V100 では FP32 比で 8 倍のピーク性能 312 TFLOPS: NVIDIA A100 では FP32 比で 16 倍のピーク性能NEW!
8.
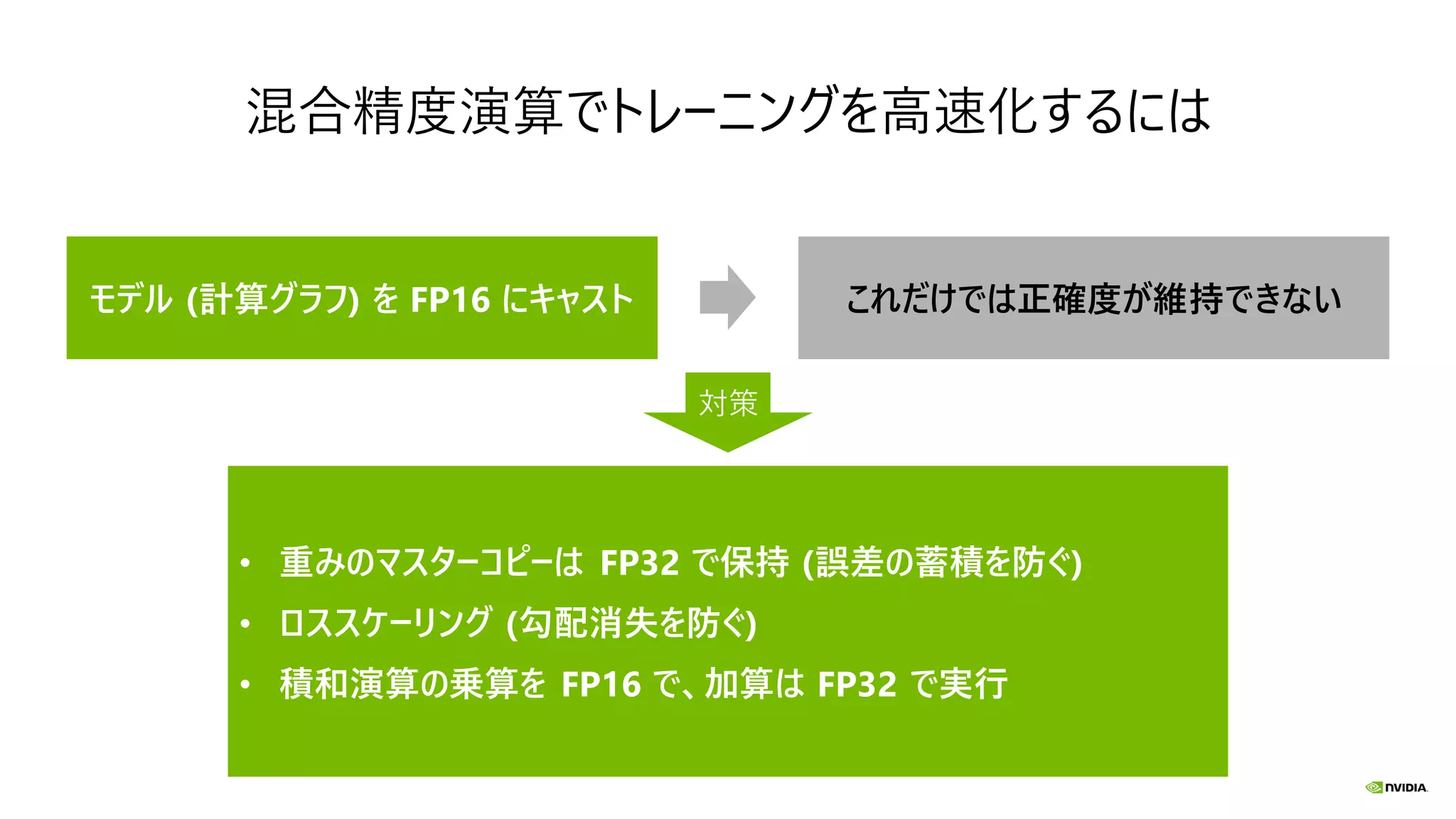
混合精度演算でトレーニングを高速化するには モデル (計算グラフ) を
FP16 にキャスト • 重みのマスターコピーは FP32 で保持 (誤差の蓄積を防ぐ) • ロススケーリング (勾配消失を防ぐ) • 積和演算の乗算を FP16 で、加算は FP32 で実行 これだけでは正確度が維持できない 対策
9.
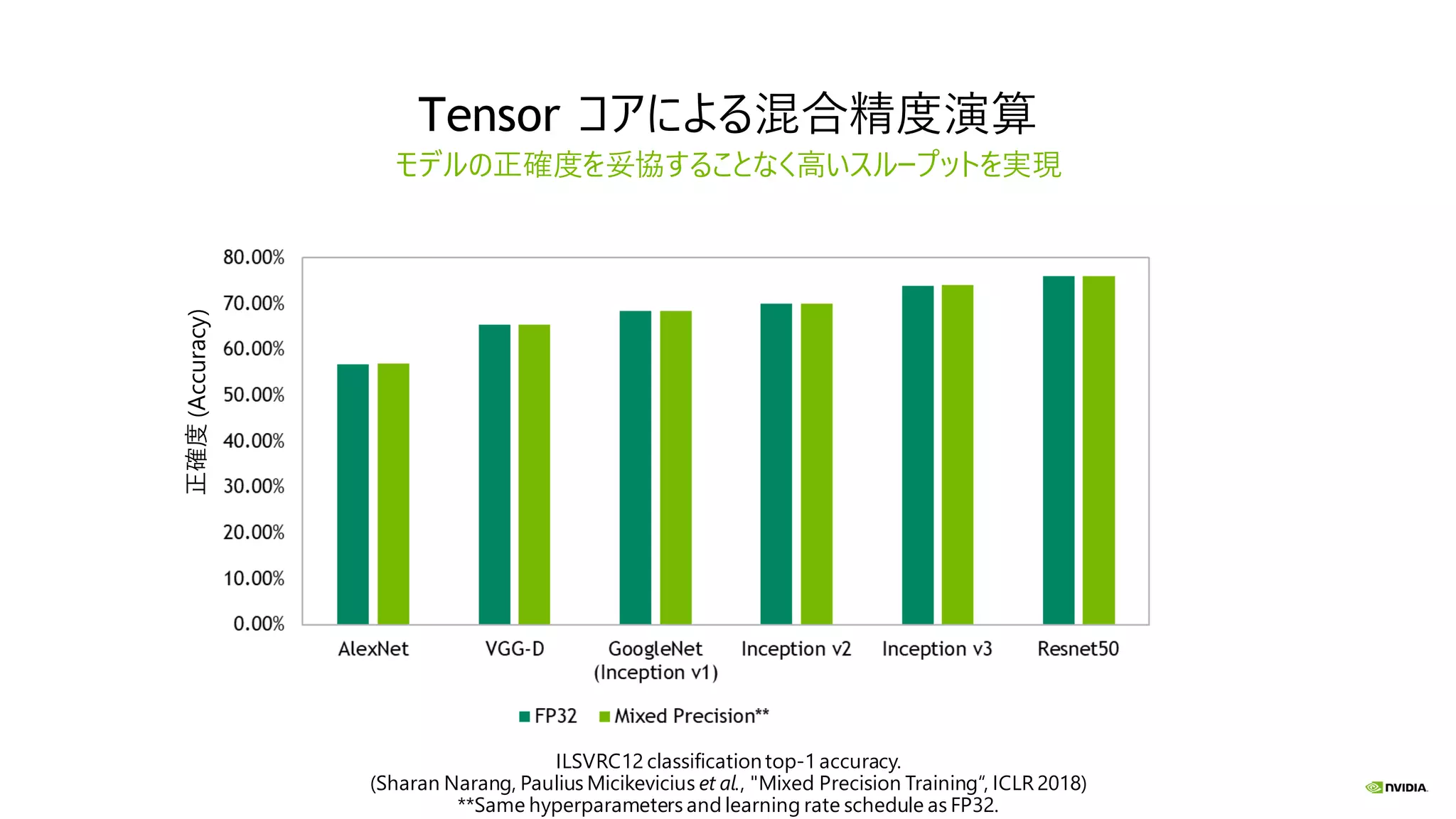
Tensor コアによる混合精度演算 モデルの正確度を妥協することなく高いスループットを実現 ILSVRC12 classificationtop-1
accuracy. (Sharan Narang, Paulius Micikevicius et al., "Mixed Precision Training“, ICLR 2018) **Same hyperparameters and learning rate schedule as FP32. 正確度(Accuracy)
10.
Automatic Mixed Precision 自動混合精度演算
11.
自動混合精度演算 (AMP) の有効化 わずか数行の追加で高速化 詳しくはこちら:
https://developer.nvidia.com/automatic-mixed-precision TensorFlow NVIDIANGC コンテナイメージ19.07以降、TF 1.14 以降及びTF 2 以降では、オプティマイザのラッパーが利用可能: opt = tf.train.experimental.enable_mixed_precision_graph_rewrite (opt) Keras mixed precision API in TF 2.1+ for eager execution https://tensorflow.org/api_docs/python/tf/train/experimental/enable_mixed_precision_graph_rewrite PyTorch PyTorch はネイティブにAMP をサポート。詳細は公式ドキュメントを: https://pytorch.org/docs/stable/amp.html https://pytorch.org/docs/stable/notes/amp_examples.html MXNet NVIDIANGC コンテナイメージ19.04以降、MXNet 1.5 以降は、わずかな追加コードでAMP を利用可能: amp.init() amp.init_trainer(trainer) with amp.scale_loss (loss, trainer) as scaled_loss: autograd.backward(scaled_loss) https://mxnet.apache.org/api/python/docs/tutorials/performance/backend/amp.html
12.
17 NVIDIA A100 Tensorコア
GPU
13.
18 NVIDIA A100 Tensor
コア GPU かつてない飛躍 - Volta 比最大 20 倍のピーク性能 54B XTOR | 826mm2 | TSMC 7N | 40GB Samsung HBM2 | 600 GB/s NVLink ピーク性能 V100 比 FP32 トレーニング 312 TFLOPS 20X INT8 インファレンス 1,248 TOPS 20X FP64 HPC 19.5 TFLOPS 2.5X Multi-instance GPU (MIG) 7X GPUs
14.
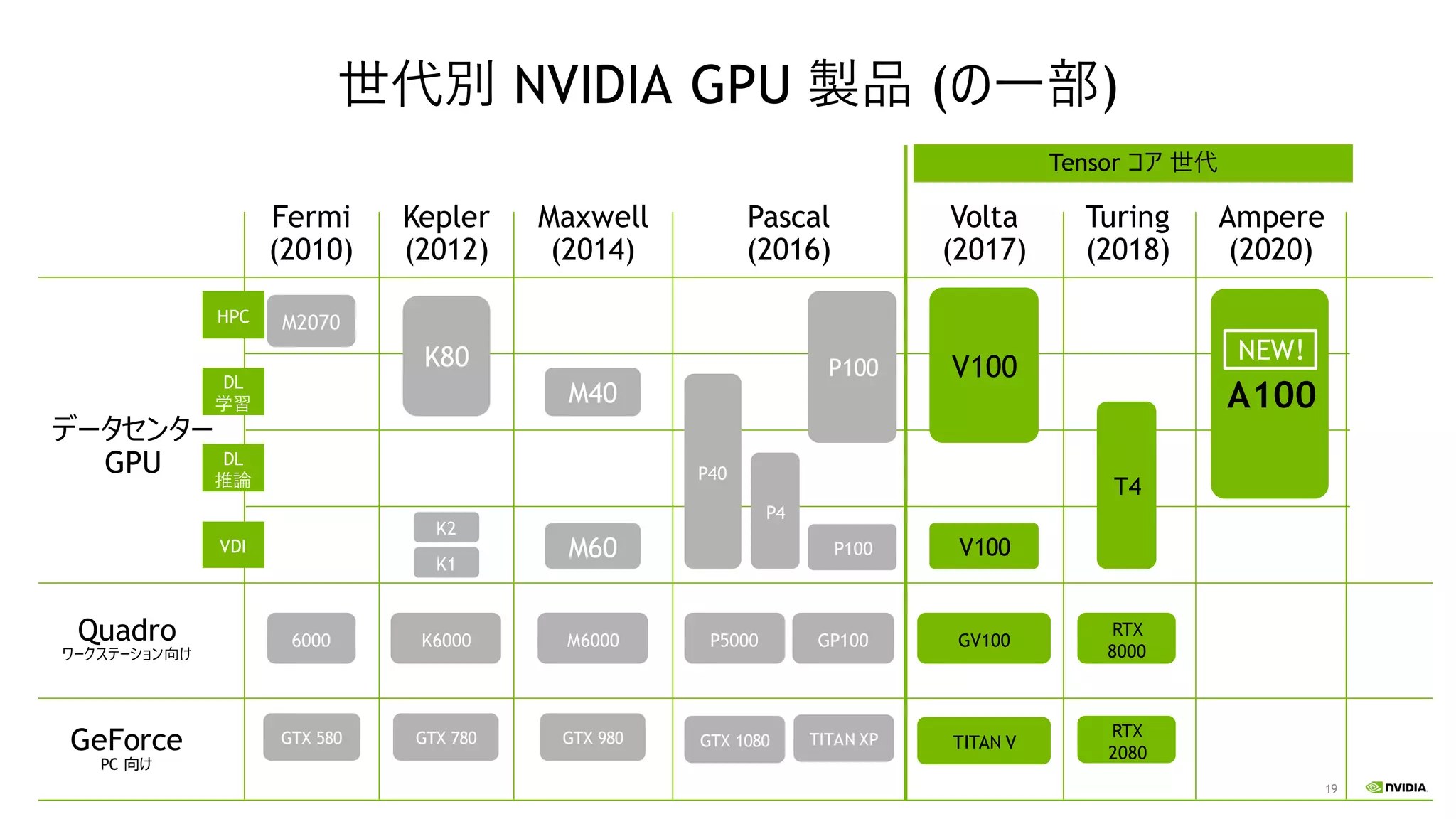
19 世代別 NVIDIA GPU
製品 (の一部) GeForce PC 向け Quadro ワークステーション向け データセンター GPU Fermi (2010) M2070 6000 GTX 580 Kepler (2012) K6000 GTX 780 K80 K2 K1 Maxwell (2014) M40 M6000 GTX 980 M60 Volta (2017) V100 TITAN V GV100 Pascal (2016) GP100P5000 GTX 1080 P40 P100 Turing (2018) T4 RTX 2080 Ampere (2020) A100 HPC DL 学習 DL 推論 VDI P4 RTX 8000 TITAN XP NEW! V100P100 Tensor コア 世代
15.
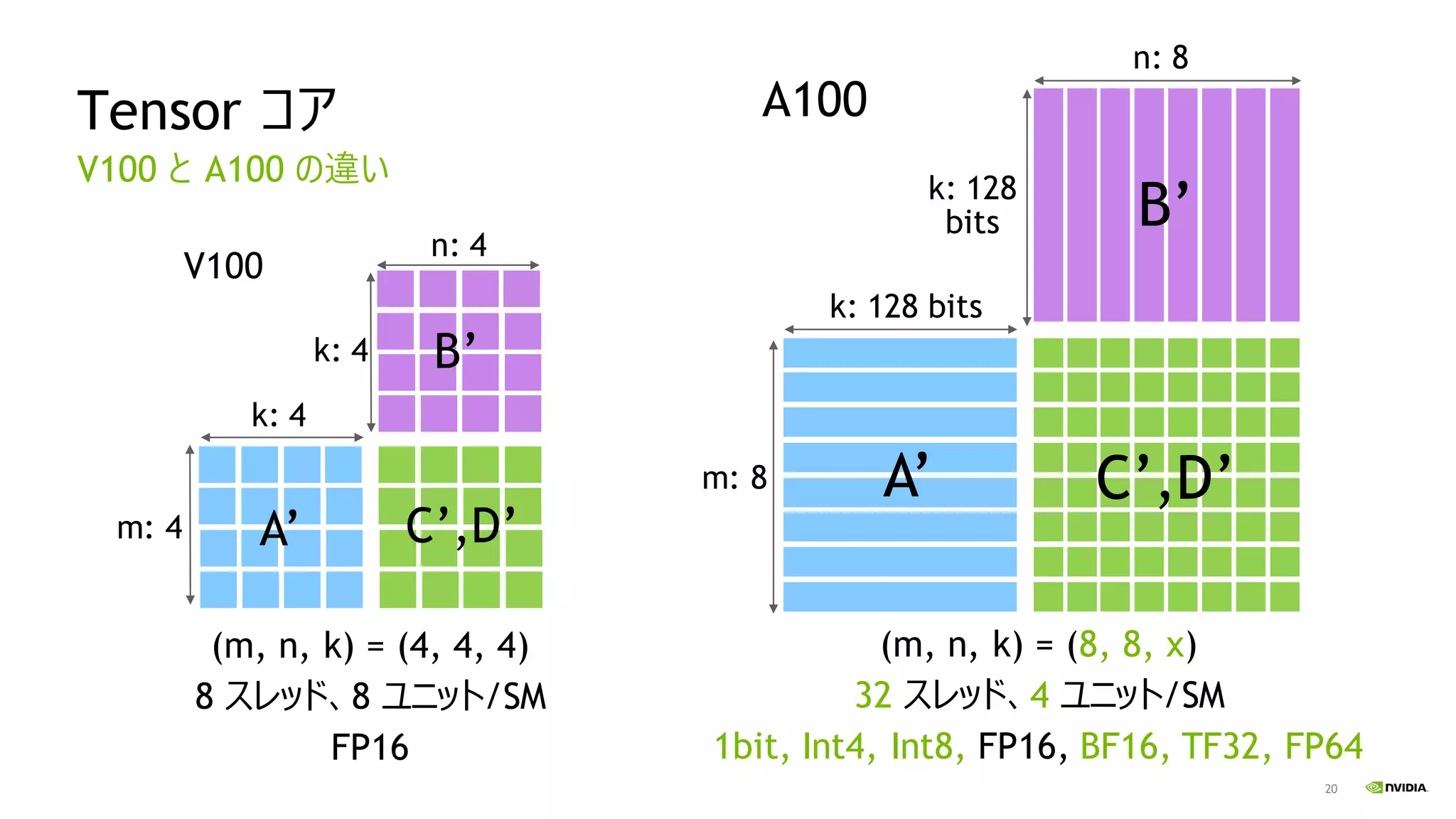
20 Tensor コア V100 と
A100 の違い m: 4 n: 4 k: 4 (m, n, k) = (4, 4, 4) 8 スレッド、8 ユニット/SM FP16 V100 k: 4 A’ C’,D’ B’ A100 n: 8 m: 8 k: 128 bits (m, n, k) = (8, 8, x) 32 スレッド、4 ユニット/SM 1bit, Int4, Int8, FP16, BF16, TF32, FP64 k: 128 bits A’ C’,D’ B’
16.
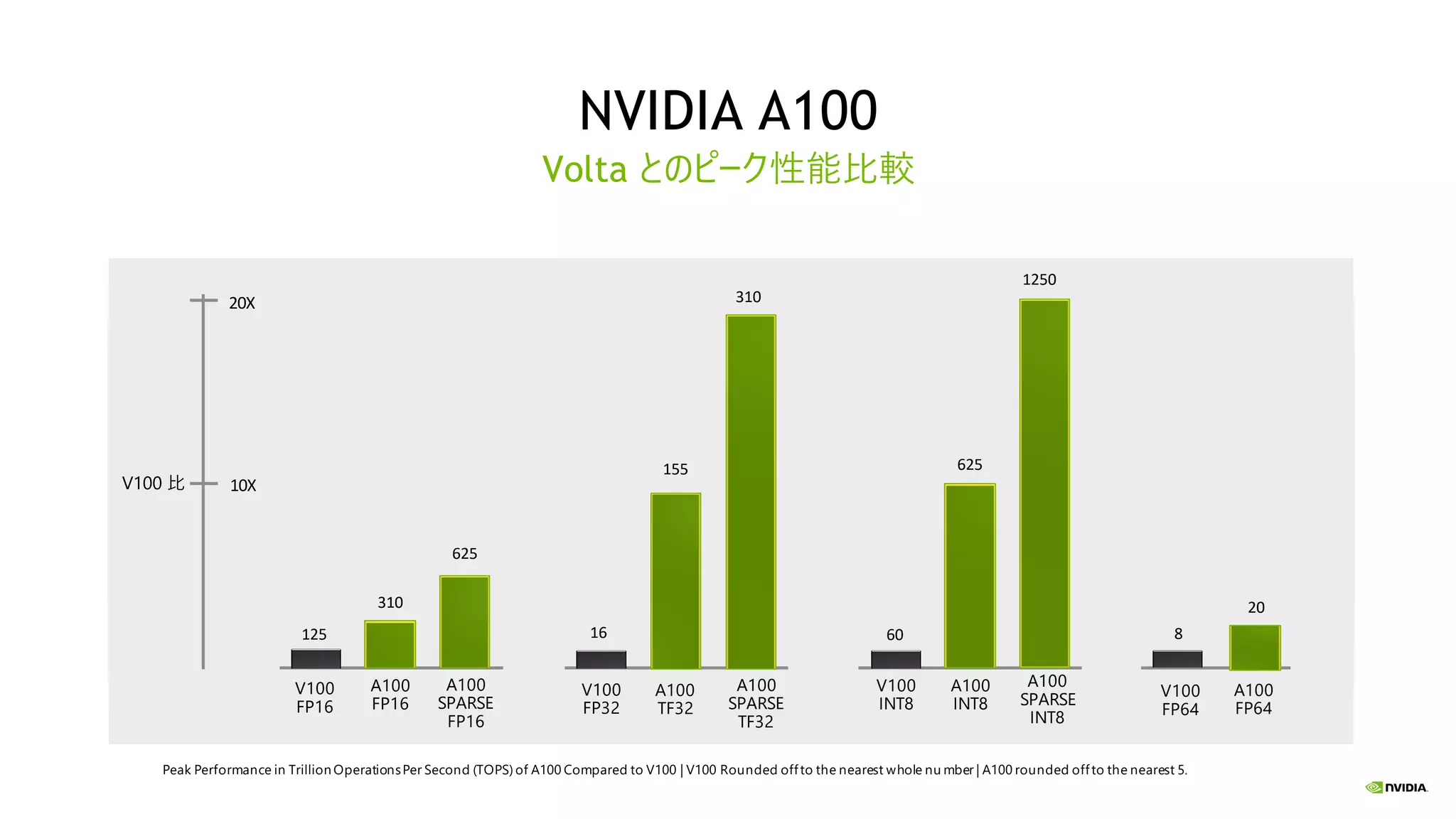
NVIDIA A100 Volta とのピーク性能比較 20X 10XV100
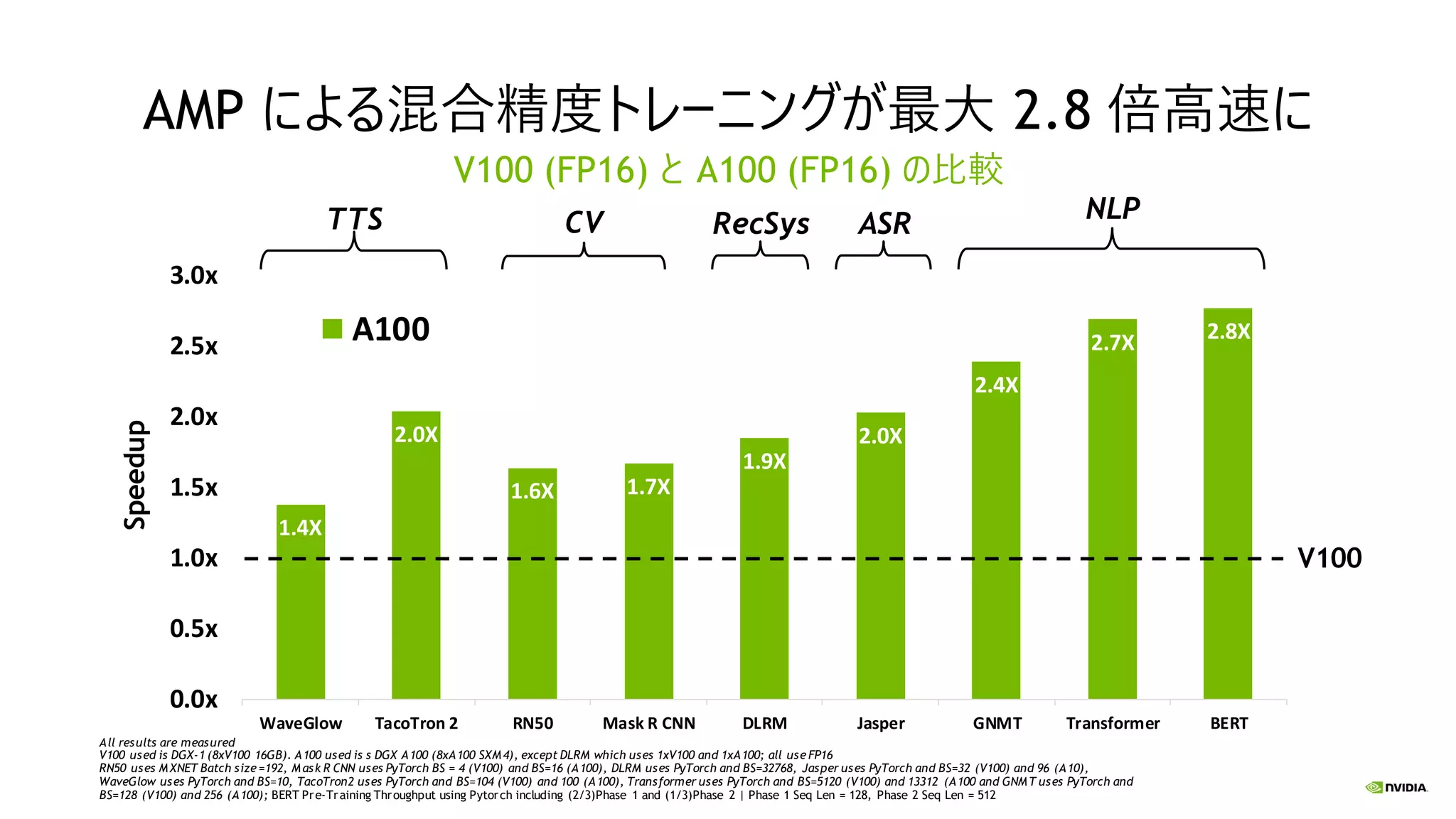
比 A100 SPARSE TF32 A100 TF32 155 V100 FP32 16 310 A100 SPARSE FP16 A100 FP16 310 V100 FP16 125 625 A100 INT8 V100 INT8 60 625 A100 SPARSE INT8 1250 A100 FP64 20 V100 FP64 8 Peak Performance in Trillion OperationsPer Second (TOPS) of A100 Compared to V100 | V100 Rounded offto the nearest whole nu mber | A100 rounded offto the nearest 5.
17.
1.4X 2.0X 1.6X 1.7X 1.9X 2.0X 2.4X 2.7X 2.8X 0.0x 0.5x 1.0x 1.5x 2.0x 2.5x 3.0x WaveGlow
TacoTron 2 RN50 Mask R CNN DLRM Jasper GNMT Transformer BERT A100 AMP による混合精度トレーニングが最大 2.8 倍高速に V100 (FP16) と A100 (FP16) の比較 CV ASRRecSysTTS NLP Speedup V100 All results are measured V100 used is DGX-1 (8xV100 16GB). A100 used is s DGX A100 (8xA100 SXM4), except DLRM which uses 1xV100 and 1xA100; all use FP16 RN50 uses MXNET Batch size =192, Mask R CNN uses PyTorch BS = 4 (V100) and BS=16 (A100), DLRM uses PyTorch and BS=32768, Jasper uses PyTorch and BS=32 (V100) and 96 (A10), WaveGlow uses PyTorch and BS=10, TacoTron2 uses PyTorch and BS=104 (V100) and 100 (A100), Transformer uses PyTorch and BS=5120 (V100) and 13312 (A100 and GNMT uses PyTorch and BS=128 (V100) and 256 (A100); BERT Pre-Training Throughput using Pytorch including (2/3)Phase 1 and (1/3)Phase 2 | Phase 1 Seq Len = 128, Phase 2 Seq Len = 512
18.
TF32 TENSOR コア FP32
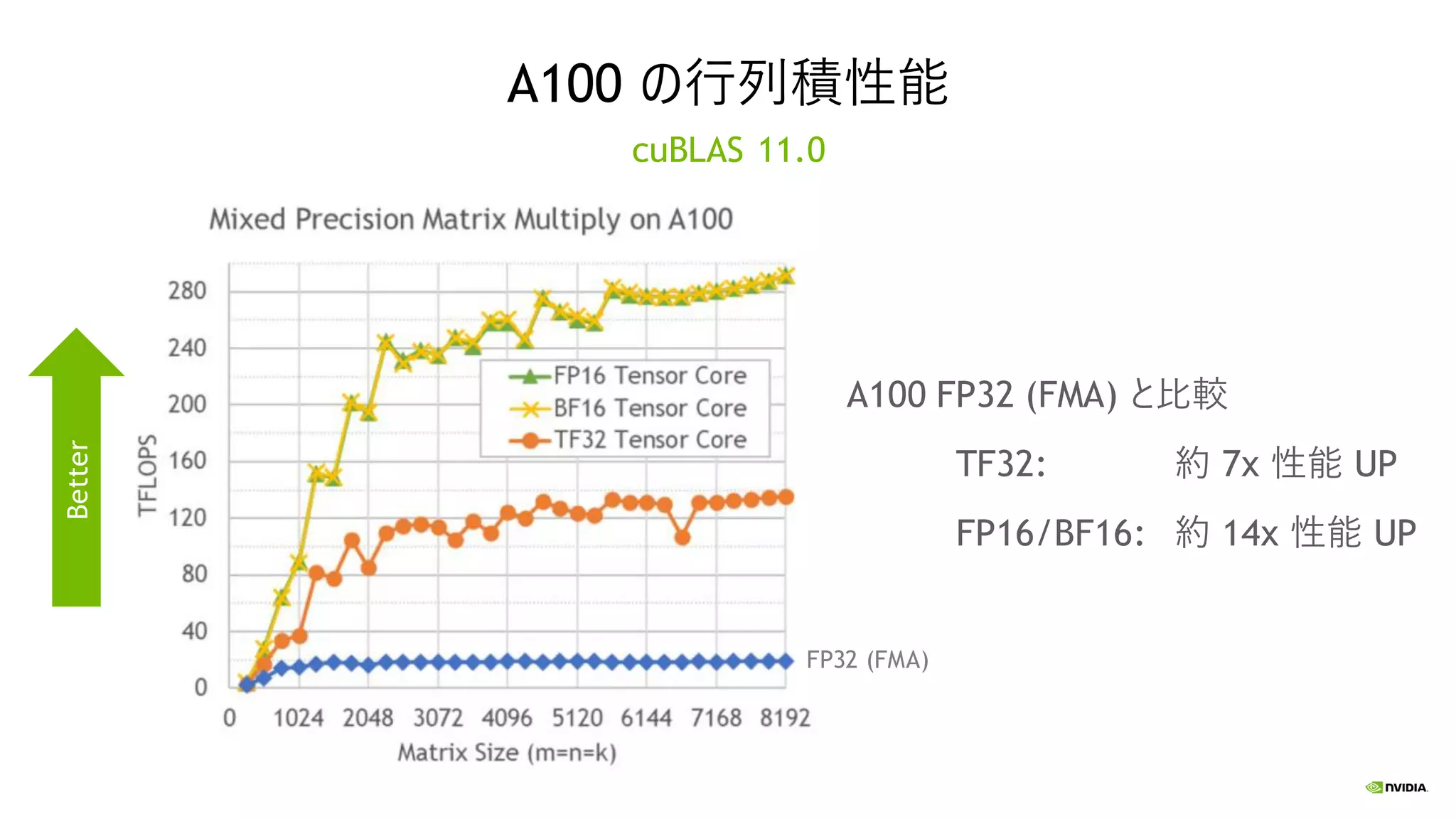
のレンジと FP16 の精度を合わせ持つ新しい数値データ型 ➢ FP32 の指数部、FP16 の仮数部 ➢ FP32 を受け取り、TF32で乗算して FP32 で加算 ➢ コード変更不要でモデルのトレーニングを高速化 FP32 TENSOR FLOAT 32 (TF32) FP16 BFLOAT16 8 ビット 23 ビット 8 ビット 10 ビット 5 ビット 10 ビット 8 ビット 7 ビット 指数部 仮数部符号部 FP32 のレンジ FP16 の精度 FP32 行列 FP32 行列 TF32 フォーマットで乗算 FP32 で加算 FP32 行列
19.
A100 の行列積性能 A100 FP32
(FMA) と比較 TF32: 約 7x 性能 UP FP16/BF16: 約 14x 性能 UP cuBLAS 11.0 FP32 (FMA) Better
20.
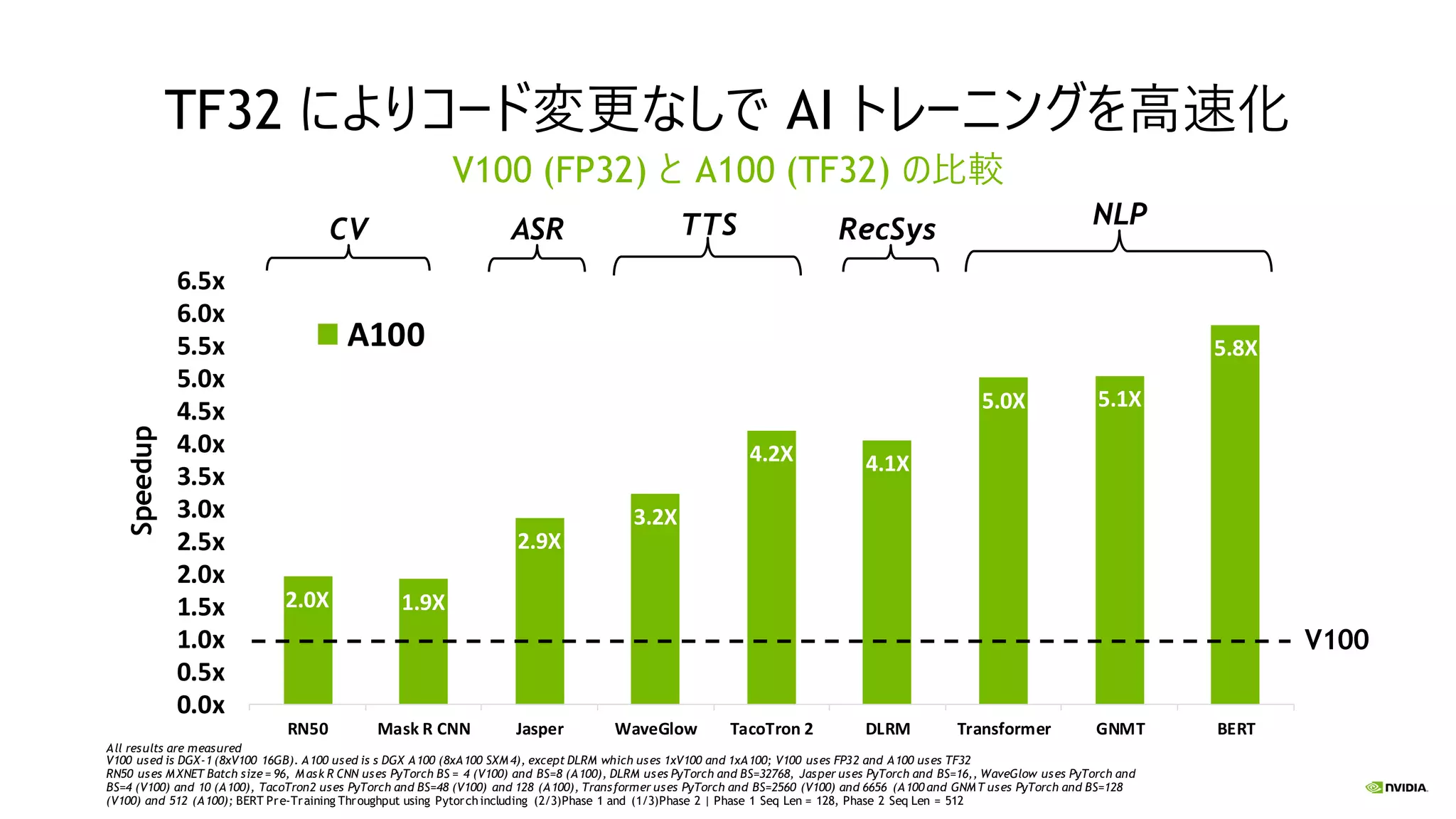
2.0X 1.9X 2.9X 3.2X 4.2X 4.1X 5.0X
5.1X 5.8X 0.0x 0.5x 1.0x 1.5x 2.0x 2.5x 3.0x 3.5x 4.0x 4.5x 5.0x 5.5x 6.0x 6.5x RN50 Mask R CNN Jasper WaveGlow TacoTron 2 DLRM Transformer GNMT BERT A100 TF32 によりコード変更なしで AI トレーニングを高速化 V100 (FP32) と A100 (TF32) の比較 CV RecSysASR TTS NLP All results are measured V100 used is DGX-1 (8xV100 16GB). A100 used is s DGX A100 (8xA100 SXM4), except DLRM which uses 1xV100 and 1xA100; V100 uses FP32 and A100 uses TF32 RN50 uses MXNET Batch size = 96, Mask R CNN uses PyTorch BS = 4 (V100) and BS=8 (A100), DLRM uses PyTorch and BS=32768, Jasper uses PyTorch and BS=16,, WaveGlow uses PyTorch and BS=4 (V100) and 10 (A100), TacoTron2 uses PyTorch and BS=48 (V100) and 128 (A100), Transformer uses PyTorch and BS=2560 (V100) and 6656 (A100 and GNMT uses PyTorch and BS=128 (V100) and 512 (A100); BERT Pre-Training Throughput using Pytorchincluding (2/3)Phase 1 and (1/3)Phase 2 | Phase 1 Seq Len = 128, Phase 2 Seq Len = 512 Speedup V100
21.
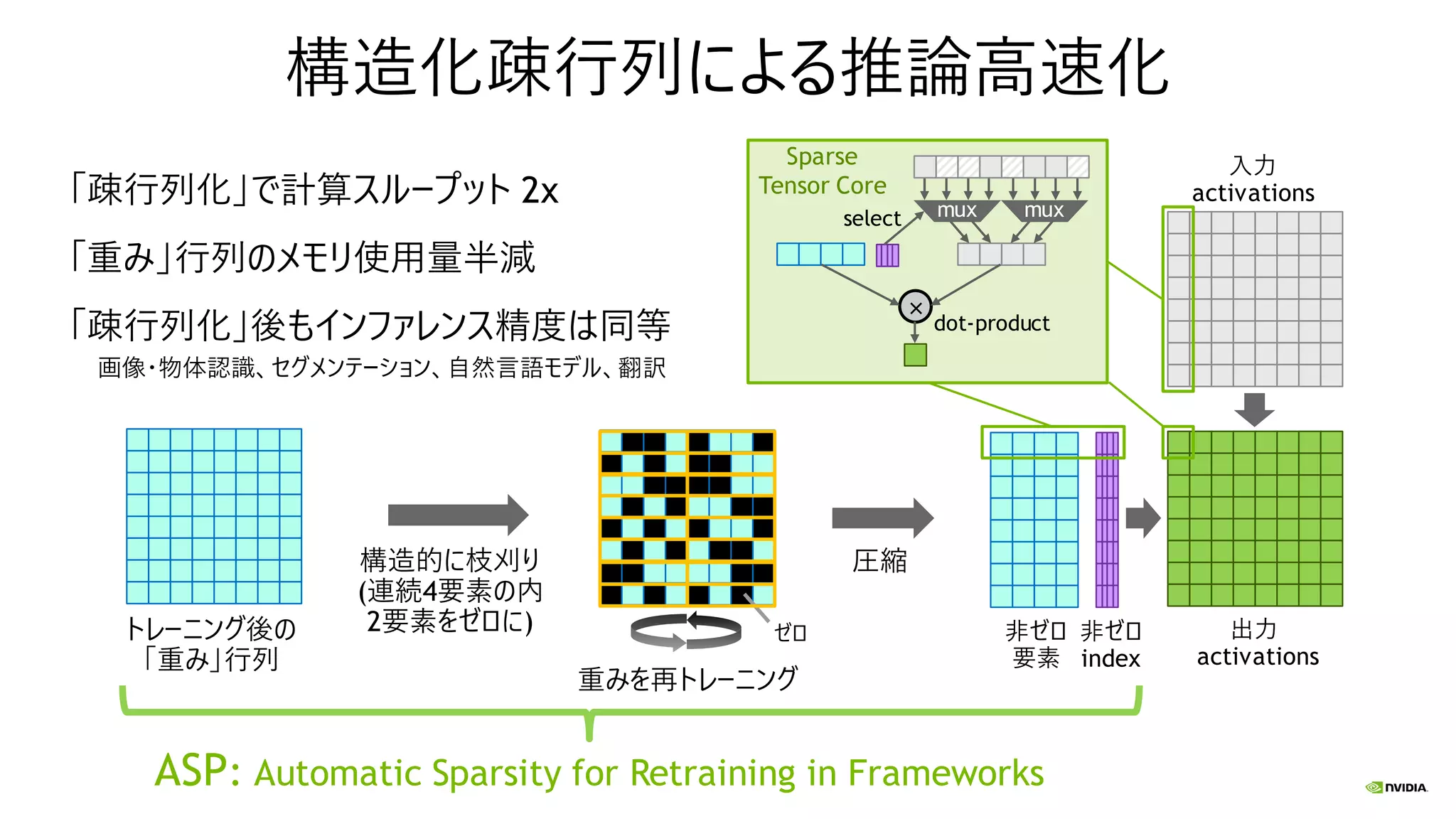
構造化疎行列による推論高速化 構造的に枝刈り (連続4要素の内 2要素をゼロに) 圧縮 非ゼロ index 非ゼロ 要素 ゼロ × dot-product トレーニング後の 「重み」行列 入力 activations mux 重みを再トレーニング 出力 activations select 「疎行列化」で計算スループット 2x 「重み」行列のメモリ使用量半減 「疎行列化」後もインファレンス精度は同等 画像・物体認識、セグメンテーション、自然言語モデル、翻訳 Sparse Tensor Core mux ASP:
Automatic Sparsity for Retraining in Frameworks
22.
倍精度演算のピーク性能が 2.5 倍に A100
の Tensor コアは FP64 に対応 1.5x 2x 0 1 2 LSMS BerkeleyGW A100 Speedup vs. V100 (FP64) Application [Benchmarks]: BerkeleyGW [Chi Sum + MTXEL] using DGX-1V (8xV100) and DGX-A100 (8xA100) | LSMS [Fe128] single V100 SXM2 vs. A100 SXM4 • IEEE 754 準拠の倍精度浮動小数点数 • cuBLAS, cuTensor, cuSolver 等のライブラリで対応 NVIDIA V100 FP64 NVIDIA A100 Tensor コア FP64
23.
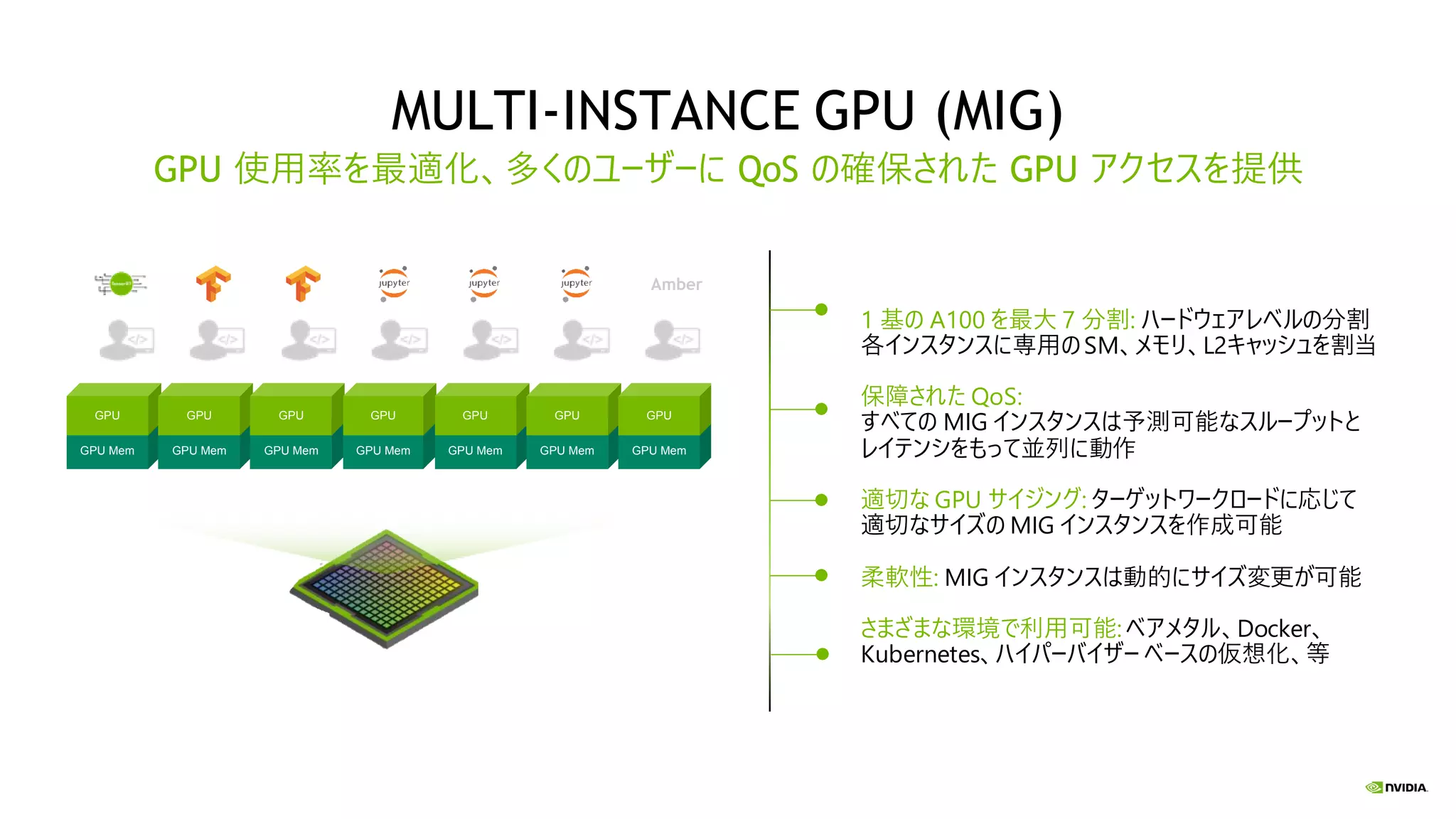
MULTI-INSTANCE GPU (MIG) GPU
使用率を最適化、多くのユーザーに QoS の確保された GPU アクセスを提供 1 基の A100 を最大 7 分割: ハードウェアレベルの分割 各インスタンスに専用のSM、メモリ、L2キャッシュを割当 保障された QoS: すべての MIG インスタンスは予測可能なスループットと レイテンシをもって並列に動作 適切な GPU サイジング: ターゲットワークロードに応じて 適切なサイズの MIG インスタンスを作成可能 柔軟性: MIG インスタンスは動的にサイズ変更が可能 さまざまな環境で利用可能:ベアメタル、Docker、 Kubernetes、ハイパーバイザー ベースの仮想化、等 Amber GPU Mem GPU GPU Mem GPU GPU Mem GPU GPU Mem GPU GPU Mem GPU GPU Mem GPU GPU Mem GPU
24.
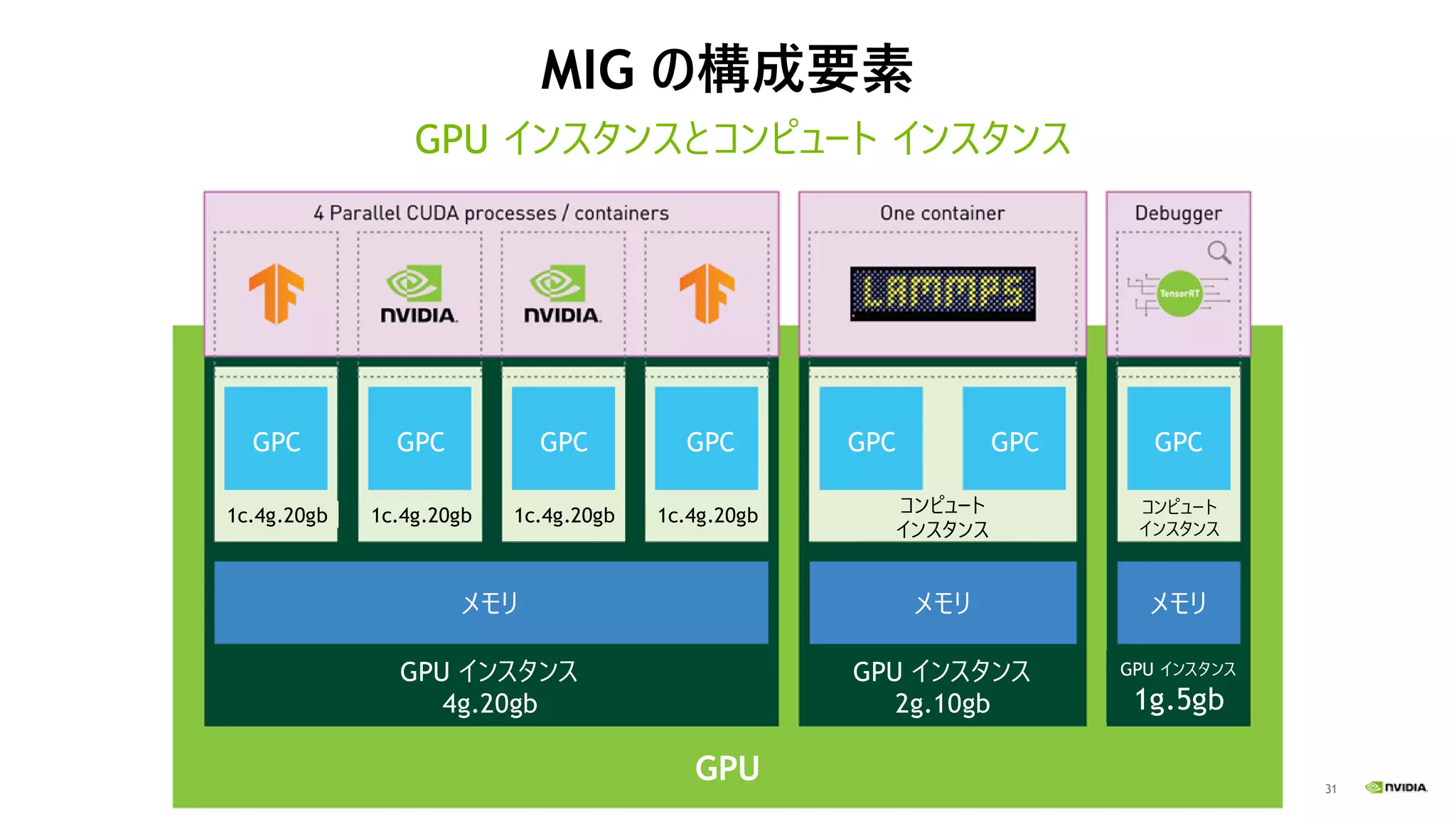
31 MIG の構成要素 GPU インスタンスとコンピュート
インスタンス メモリ メモリ メモリ GPU インスタンス 4g.20gb GPU インスタンス 2g.10gb GPU インスタンス 1g.5gb GPU コンピュート インスタンス コンピュート インスタンス 1c.4g.20gb 1c.4g.20gb 1c.4g.20gb 1c.4g.20gb GPC GPC GPC GPC GPC GPC GPC
25.
33 GPU「共有」のレベル カーネル 同時実行 アドレス空間 分離 演算性能 分離 メモリ性能 分離 エラー 分離 CUDA ストリーム Yes No No
No No MPS Yes Yes Yes (*) No No Compute インスタンス Yes Yes Yes No Yes GPU インスタンス Yes Yes Yes Yes Yes CUDAストリーム、MPS、Compute インスタンス、GPU インスタンス (*) 環境変数で各プロセスが使用するSM数の上限を設定可能、完全な分離ではない
26.
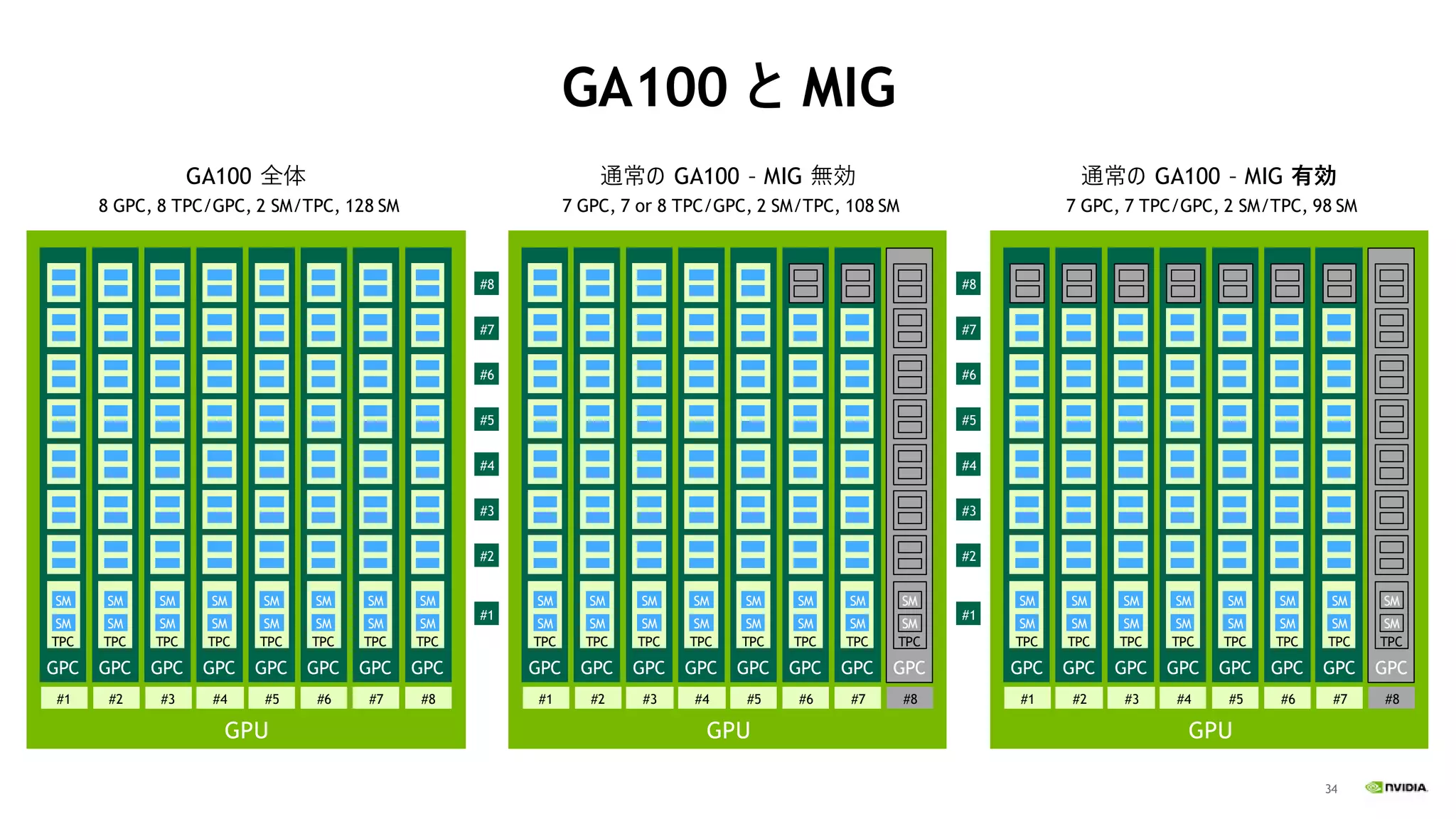
34 GA100 と MIG GPU GPC TPC SM SM #1 GPC TPC SM SM #2 GPC TPC SM SM #3 GPC TPC SM SM #4 GPC TPC SM SM #5 GPC TPC SM SM #6 GPC TPC SM SM #7 GPC TPC SM SM #8 #1 #2 #3 #4 #5 #6 #7 #8 GPU GPC TPC SM SM #1 GPC TPC SM SM #2 GPC TPC SM SM #3 GPC TPC SM SM #4 GPC TPC SM SM #5 GPC TPC SM SM #6 GPC TPC SM SM #7 GPC TPC SM SM #8 GA100
全体 8 GPC, 8 TPC/GPC, 2 SM/TPC, 128 SM 通常の GA100 – MIG 無効 7 GPC, 7 or 8 TPC/GPC, 2 SM/TPC, 108 SM GPU GPC TPC SM SM #1 GPC TPC SM SM #2 GPC TPC SM SM #3 GPC TPC SM SM #4 GPC TPC SM SM #5 GPC TPC SM SM #6 GPC TPC SM SM #7 GPC TPC SM SM #8 通常の GA100 – MIG 有効 7 GPC, 7 TPC/GPC, 2 SM/TPC, 98 SM #1 #2 #3 #4 #5 #6 #7 #8
27.
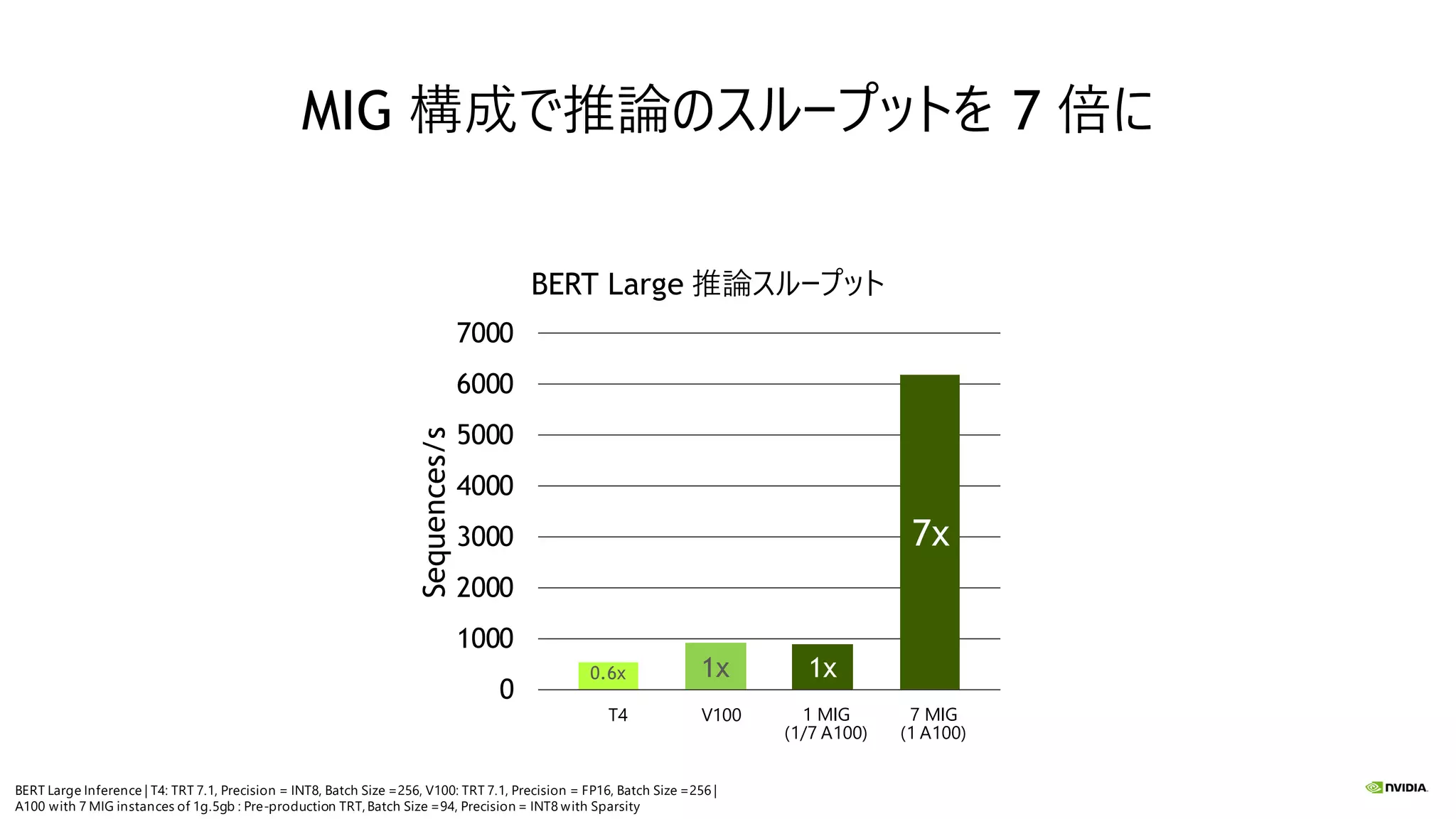
MIG 構成で推論のスループットを 7
倍に 0.6x 1x 1x 7x 0 1000 2000 3000 4000 5000 6000 7000 Sequences/s BERT Large 推論スループット V100T4 1 MIG (1/7 A100) 7 MIG (1 A100) BERT Large Inference | T4: TRT 7.1, Precision = INT8, Batch Size =256, V100: TRT 7.1, Precision = FP16, Batch Size =256 | A100 with 7 MIG instances of 1g.5gb : Pre-production TRT,Batch Size =94, Precision = INT8 with Sparsity
28.
38 A100 提供形態 NVIDIA HGX
A100 4-GPU • 4 基の NVIDIA A100 SXM4 • さまざまなワークロードに対応 NVIDIA HGX A100 8-GPU • 8 基の NVIDIA A100 SXM4 • 6 基の NVIDIA NVSwitch • ハイエンド機向け NVIDIA A100 PCIe • SXM4 版と同じピーク性能 (実アプリ性能は 10% 程度ダウン) • TDP: 250W
29.
39 NVIDIA DGX A100 5
ペタフロップスの混合精度演算性能 8 基の NVIDIA A100 GPU で合計 320GB の HBM2 メモリ GPU 毎に V100 の 2 倍となる 600GB/s の NVLink PCIe Gen4 の最大 10 倍の帯域幅 6 基の NVSwitch で全ての GPU を接続 4.8TB/s のバイセクションバンド幅 HD ビデオ 426 時間分に相当するデータを 1 秒で転送 2 基の AMD EPYC 7742 - 合計 128 コア PCIe Gen4 128 レーン 1 TB のメモリを標準搭載、2 TB に拡張可能
30.
40 ノード間通信とストレージアクセスに最高の性能を クラスター ネットワーク ストレージネットワーク シングルポート CX-6 NIC クラスター ネットワーク クラスターネットワーク: 8 枚のシングルポート
Mellanox ConnectX-6 HDR/HDR100/EDR InfiniBand と 200GigE をサポート データ/ストレージネットワーク: 2ポートの Mellanox ConnectX-6 を標準で 1 枚 Supporting: 200/100/50/40/25/10Gb Ethernet default or HDR/HDR100/EDR InfiniBand オプションで同じ ConnectX-6 をもう 1 枚追加可能 450GB/sec のバイセクション バンド幅 全ての I/O を PCIe Gen4 化、Gen3 の 2 倍高速 複数の DGX A100 ノードを Mellanox Quantum スイッチでスケール可能 MELLANOX ネットワーキングによる比類なき拡張性
31.
41 電力性能比は 20 GFLOPS/W
を突破 DGX A100 ベースの SuperPOD が Green500 #2 “Selene”- DGX A100 ベースの SuperPOD 280 ノードの DGX A100 合計 2,240 基の NVIDIA A100 Tensor コア GPU 494 基の NVIDIA Mellanox 200G HDR スイッチ 7 PB のオールフラッシュストレージ FP64 (HPL) : 27.6 PetaFLOPS FP16/FP32 の混合精度演算では 1 ExaFLOPS越え
32.
42 身近な GPU リソース
33.
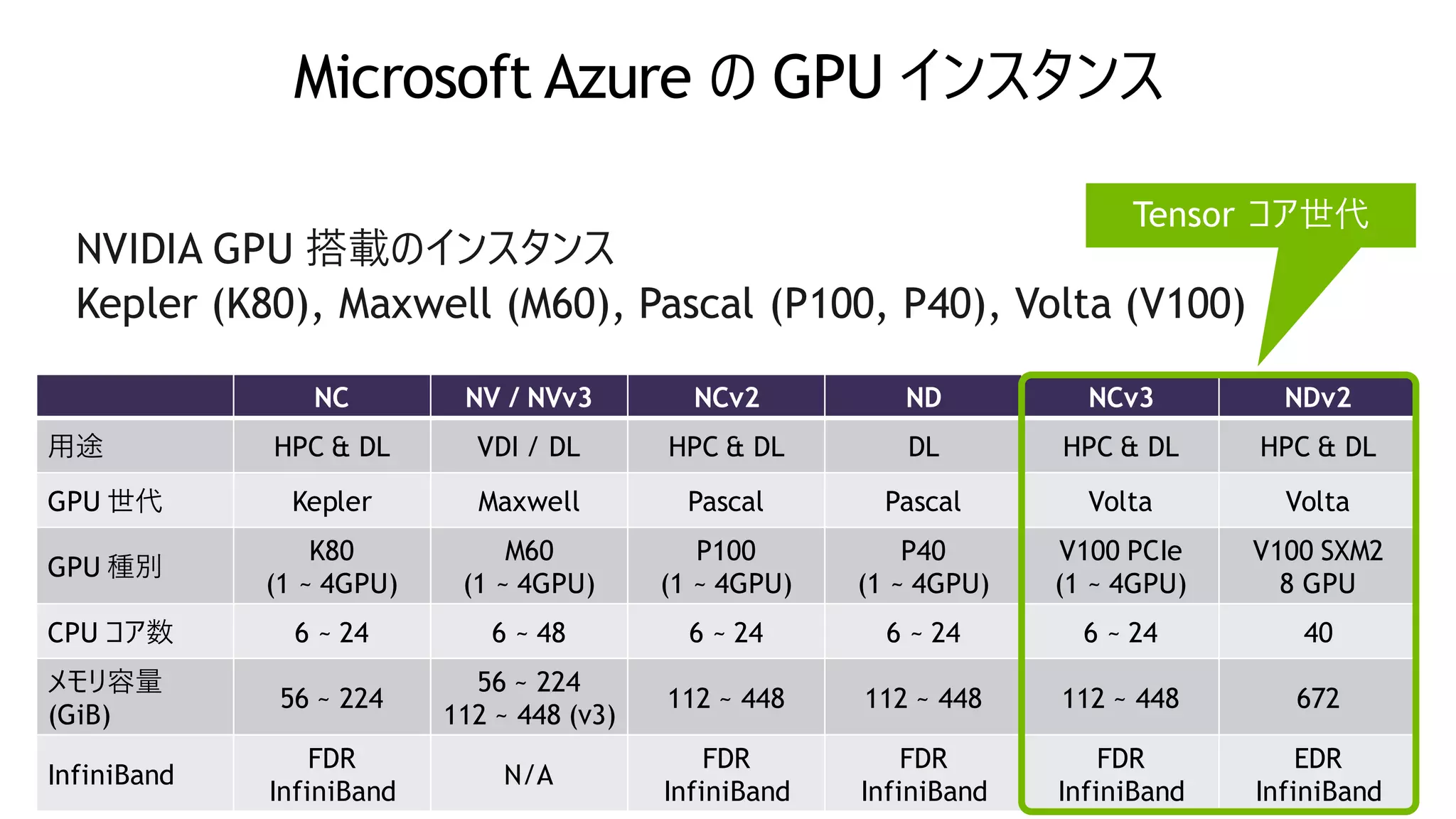
Microsoft Azure の
GPU インスタンス NC NV / NVv3 NCv2 ND NCv3 NDv2 用途 HPC & DL VDI / DL HPC & DL DL HPC & DL HPC & DL GPU 世代 Kepler Maxwell Pascal Pascal Volta Volta GPU 種別 K80 (1 ~ 4GPU) M60 (1 ~ 4GPU) P100 (1 ~ 4GPU) P40 (1 ~ 4GPU) V100 PCIe (1 ~ 4GPU) V100 SXM2 8 GPU CPU コア数 6 ~ 24 6 ~ 48 6 ~ 24 6 ~ 24 6 ~ 24 40 メモリ容量 (GiB) 56 ~ 224 56 ~ 224 112 ~ 448 (v3) 112 ~ 448 112 ~ 448 112 ~ 448 672 InfiniBand FDR InfiniBand N/A FDR InfiniBand FDR InfiniBand FDR InfiniBand EDR InfiniBand
34.
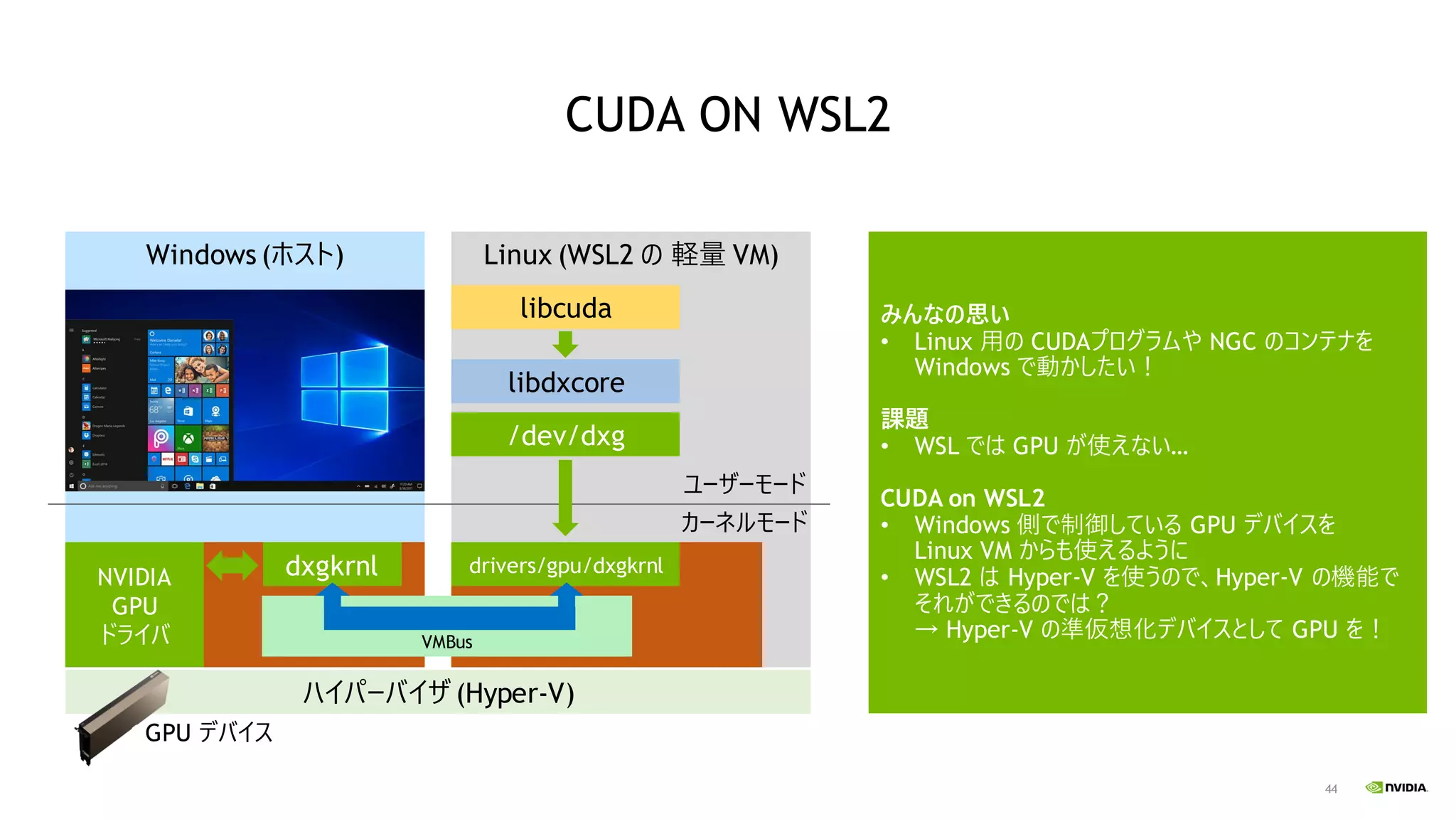
44 Linux (WSL2 の
軽量 VM) CUDA ON WSL2 libcuda libdxcore /dev/dxg drivers/gpu/dxgkrnl Windows (ホスト) ハイパーバイザ (Hyper-V) NVIDIA GPU ドライバ dxgkrnl VMBus ユーザーモード カーネルモード GPU デバイス みんなの思い • Linux 用の CUDAプログラムや NGC のコンテナを Windows で動かしたい! 課題 • WSL では GPU が使えない… CUDA on WSL2 • Windows 側で制御している GPU デバイスを Linux VM からも使えるように • WSL2 は Hyper-V を使うので、Hyper-V の機能で それができるのでは? → Hyper-V の準仮想化デバイスとして GPU を!
35.
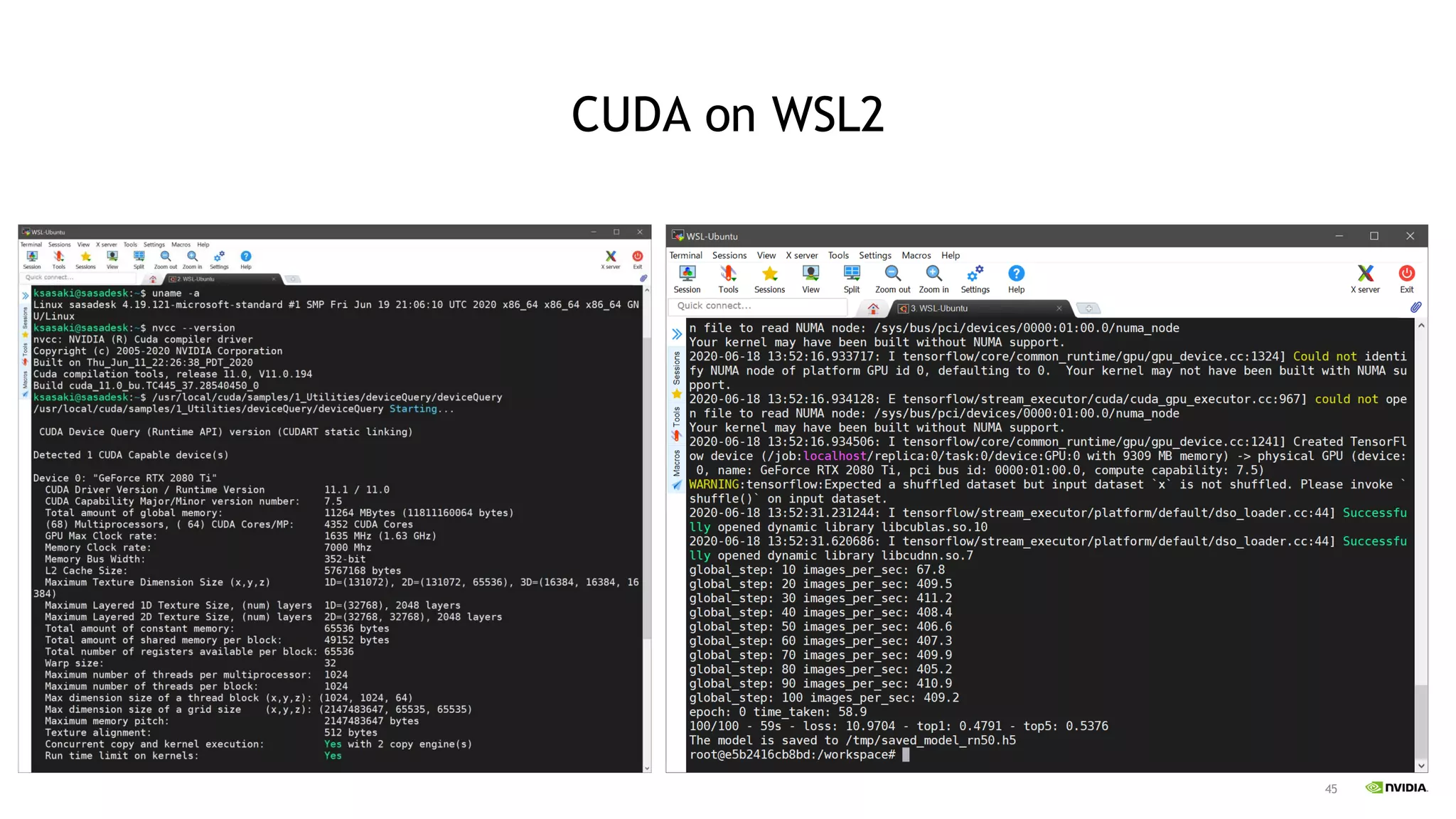
45 CUDA on WSL2
36.
46 https://qiita.com/ksasaki/items/ee864abd74f95fea1efa
37.
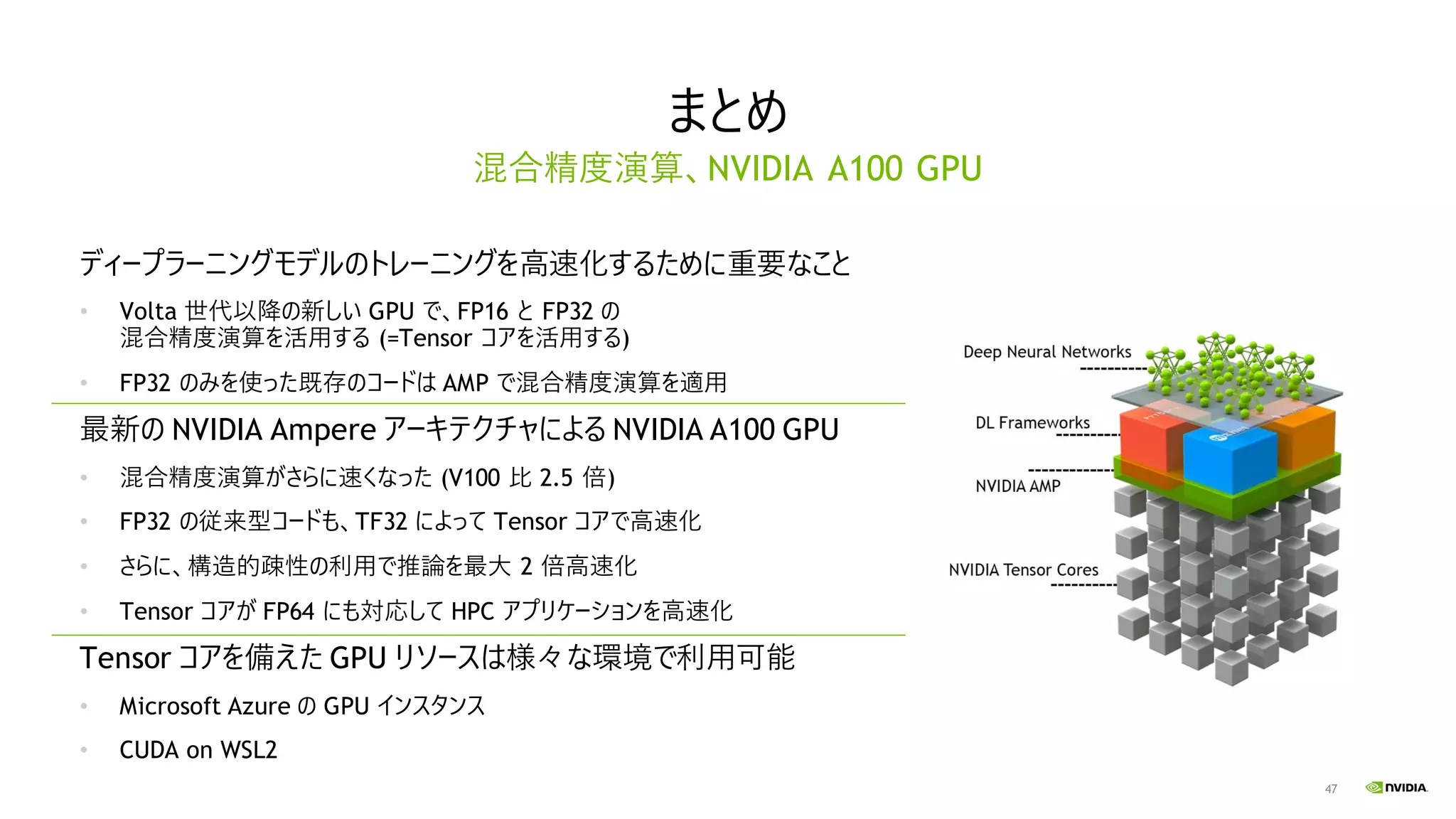
47 まとめ ディープラーニングモデルのトレーニングを高速化するために重要なこと • Volta 世代以降の新しい
GPU で、FP16 と FP32 の 混合精度演算を活用する (=Tensor コアを活用する) • FP32 のみを使った既存のコードは AMP で混合精度演算を適用 最新の NVIDIA Ampere アーキテクチャによる NVIDIA A100 GPU • 混合精度演算がさらに速くなった (V100 比 2.5 倍) • FP32 の従来型コードも、TF32 によって Tensor コアで高速化 • さらに、構造的疎性の利用で推論を最大 2 倍高速化 • Tensor コアが FP64 にも対応して HPC アプリケーションを高速化 Tensor コアを備えた GPU リソースは様々な環境で利用可能 • Microsoft Azure の GPU インスタンス • CUDA on WSL2 混合精度演算、NVIDIA A100 GPU
38.
48
Download









![倍精度演算のピーク性能が 2.5 倍に
A100 の Tensor コアは FP64 に対応
1.5x
2x
0
1
2
LSMS BerkeleyGW
A100 Speedup vs. V100 (FP64)
Application [Benchmarks]: BerkeleyGW [Chi Sum + MTXEL] using DGX-1V (8xV100) and DGX-A100 (8xA100) | LSMS [Fe128] single V100 SXM2 vs. A100 SXM4
• IEEE 754 準拠の倍精度浮動小数点数
• cuBLAS, cuTensor, cuSolver 等のライブラリで対応
NVIDIA V100 FP64 NVIDIA A100 Tensor コア FP64](https://image.slidesharecdn.com/2020801nvidia-200807073343/75/Track2-2-NVIDIA-Ampere-NVIDIA-A100-Tensor-GPU-22-2048.jpg)








![[Track2-2] 最新のNVIDIA AmpereアーキテクチャによるNVIDIA A100 TensorコアGPUの特長とその性能を引き出す方法](https://image.slidesharecdn.com/2020801nvidia-200807073343/75/Track2-2-NVIDIA-Ampere-NVIDIA-A100-Tensor-GPU-39-2048.jpg)















![[DL輪読会]相互情報量最大化による表現学習](https://cdn.slidesharecdn.com/ss_thumbnails/20190913iwasawa-190913002312-thumbnail.jpg?width=640&height=640&fit=bounds)








![SSII2022 [OS3-02] Federated Learningの基礎と応用](https://cdn.slidesharecdn.com/ss_thumbnails/ssii2022-os3-02-220607020834-2b5f93ff-thumbnail.jpg?width=640&height=640&fit=bounds)















![[db analytics showcase Sapporo 2017] B14: GPU コンピューティング最前線 by エヌビディア 佐々木邦暢](https://cdn.slidesharecdn.com/ss_thumbnails/20170630dbassprnvidia-170707074715-thumbnail.jpg?width=640&height=640&fit=bounds)













![[Track3-2] AI活用人材の社内育成に関する取り組みについて ~ダイキン情報技術大学~](https://cdn.slidesharecdn.com/ss_thumbnails/3-2dllabconferencedaikinisid2020-07-20-2-200819034039-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Track1-2] ディープラーニングを用いたワインブドウの収穫量予測](https://cdn.slidesharecdn.com/ss_thumbnails/dldc20200801nssoltokutake-200819025900-thumbnail.jpg?width=640&height=640&fit=bounds)






![[Track1-1] AIの売上予測を発注システムに組み込んだリンガーハットのデータ活用戦略](https://cdn.slidesharecdn.com/ss_thumbnails/datumstudiomitsuda-200819031400-thumbnail.jpg?width=640&height=640&fit=bounds)


![[Track 4-6] ディープラーニングxものづくりが日本を強くする ~高専DCONの挑戦~](https://cdn.slidesharecdn.com/ss_thumbnails/integraixdllpdf-200819065852-thumbnail.jpg?width=640&height=640&fit=bounds)








