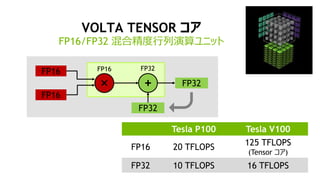
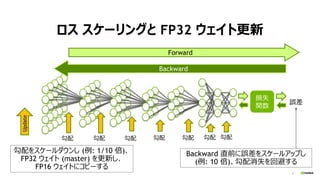
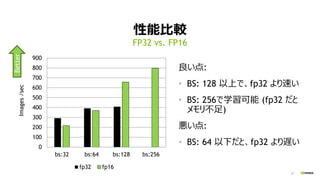
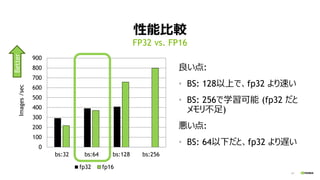
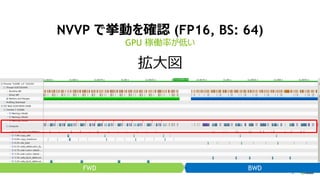
34
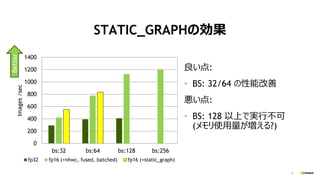
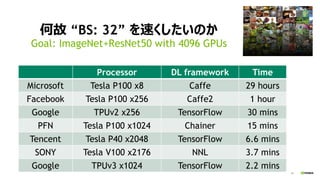
何故 “BS: 32”を速くしたいのか
Goal: ImageNet+ResNet50 with 4096 GPUs
Processor DL framework Time
Microsoft Tesla P100 x8 Caffe 29 hours
Facebook Tesla P100 x256 Caffe2 1 hour
Google TPUv2 x256 TensorFlow 30 mins
PFN Tesla P100 x1024 Chainer 15 mins
Tencent Tesla P40 x2048 TensorFlow 6.6 mins
SONY Tesla V100 x2176 NNL 3.7 mins
Google TPUv3 x1024 TensorFlow 2.2 mins
35.
35
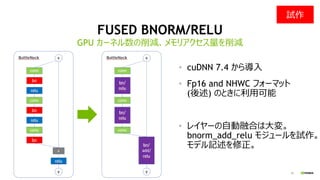
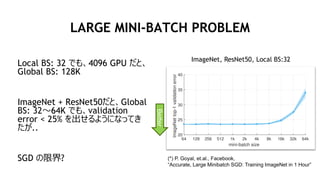
LARGE MINI-BATCH PROBLEM
LocalBS: 32 でも、4096 GPU だと、
Global BS: 128K
ImageNet + ResNet50だと、Global
BS: 32~64K でも、validation
error < 25% を出せるようになってき
たが..
SGD の限界?
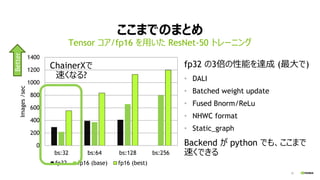
ImageNet, ResNet50, Local BS:32
(*) P. Goyal, et.al., Facebook,
“Accurate, Large Minibatch SGD: Training ImageNet in 1 Hour”
Better
36.
36
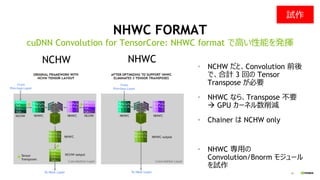
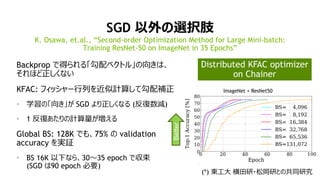
SGD 以外の選択肢
Backprop で得られる「勾配ベクトル」の向きは、
それほど正しくない
KFAC:フィッシャー行列を近似計算して勾配補正
• 学習の「向き」が SGD より正しくなる (反復数減)
• 1 反復あたりの計算量が増える
Global BS: 128K でも、75% の validation
accuracy を実証
• BS 16K 以下なら、30~35 epoch で収束
(SGD は90 epoch 必要)
K. Osawa, et.al., “Second-order Optimization Method for Large Mini-batch:
Training ResNet-50 on ImageNet in 35 Epochs”
(*) 東工大 横田研・松岡研との共同研究
ImageNet + ResNet50
Better
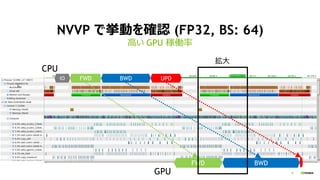
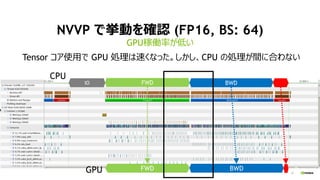
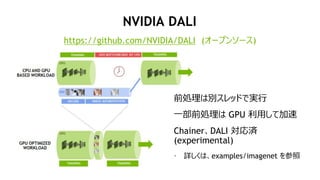
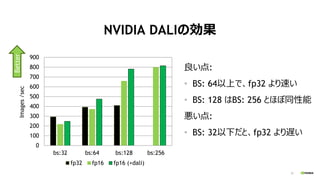
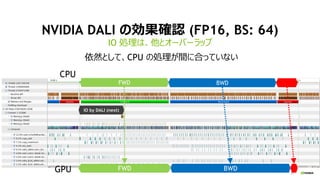
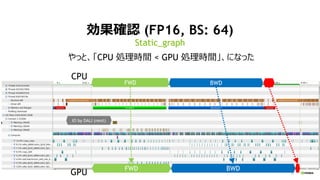
Distributed KFAC optimizer
on Chainer
















![[DL輪読会]Disentangling by Factorising](https://cdn.slidesharecdn.com/ss_thumbnails/20180720disentanglingbyfactorising-180720000930-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DL輪読会]GLIDE: Guided Language to Image Diffusion for Generation and Editing](https://cdn.slidesharecdn.com/ss_thumbnails/glide2-220107030326-thumbnail.jpg?width=640&height=640&fit=bounds)



![[DL輪読会]Life-Long Disentangled Representation Learning with Cross-Domain Laten...](https://cdn.slidesharecdn.com/ss_thumbnails/20180914iwasawa-180919025635-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DL輪読会]GANとエネルギーベースモデル](https://cdn.slidesharecdn.com/ss_thumbnails/dlseminar20200828-210519065921-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]Vision Transformer with Deformable Attention (Deformable Attention Tra...](https://cdn.slidesharecdn.com/ss_thumbnails/dl0114-220114032933-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DL輪読会]Swin Transformer: Hierarchical Vision Transformer using Shifted Windows](https://cdn.slidesharecdn.com/ss_thumbnails/swintransformer-210514020542-thumbnail.jpg?width=640&height=640&fit=bounds)





![[DL輪読会]Learning Transferable Visual Models From Natural Language Supervision](https://cdn.slidesharecdn.com/ss_thumbnails/dlkobayashi0115-210115012308-thumbnail.jpg?width=640&height=640&fit=bounds)



![[DL輪読会]"CyCADA: Cycle-Consistent Adversarial Domain Adaptation"&"Learning Se...](https://cdn.slidesharecdn.com/ss_thumbnails/20180803dlakuzawa-180803003349-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]Reward Augmented Maximum Likelihood for Neural Structured Prediction](https://cdn.slidesharecdn.com/ss_thumbnails/dlhacks0804-170803075139-thumbnail.jpg?width=640&height=640&fit=bounds)



![SSII2021 [OS2-01] 転移学習の基礎:異なるタスクの知識を利用するための機械学習の方法](https://cdn.slidesharecdn.com/ss_thumbnails/os2-02final-210610091211-thumbnail.jpg?width=640&height=640&fit=bounds)
![[GTCJ2018] Optimizing Deep Learning with Chainer PFN得居誠也](https://cdn.slidesharecdn.com/ss_thumbnails/gtcj2018optimizingdeeplearningwithpfnseiyatokui-181009073509-thumbnail.jpg?width=640&height=640&fit=bounds)














![[db analytics showcase Sapporo 2017] B14: GPU コンピューティング最前線 by エヌビディア 佐々木邦暢](https://cdn.slidesharecdn.com/ss_thumbnails/20170630dbassprnvidia-170707074715-thumbnail.jpg?width=640&height=640&fit=bounds)























