Download free for 30 days
Sign in
Upload
Language (EN)
Support
Business
Mobile
Social Media
Marketing
Technology
Art & Photos
Career
Design
Education
Presentations & Public Speaking
Government & Nonprofit
Healthcare
Internet
Law
Leadership & Management
Automotive
Engineering
Software
Recruiting & HR
Retail
Sales
Services
Science
Small Business & Entrepreneurship
Food
Environment
Economy & Finance
Data & Analytics
Investor Relations
Sports
Spiritual
News & Politics
Travel
Self Improvement
Real Estate
Entertainment & Humor
Health & Medicine
Devices & Hardware
Lifestyle
Change Language
Language
English
Español
Português
Français
Deutsche
Cancel
Save
Submit search
EN
Uploaded by
HitoshiSHINABE1
4,624 views
Tensorflow Liteの量子化アーキテクチャ
2020年8月1日 Deep Learning Digital Conference [Track2-8] Tensorflow Liteの量子化アーキテクチャ のセッション資料です
Software
◦
Read more
3
Save
Share
Embed
Embed presentation
1
/ 25
2
/ 25
3
/ 25
4
/ 25
5
/ 25
6
/ 25
7
/ 25
8
/ 25
9
/ 25
10
/ 25
11
/ 25
12
/ 25
13
/ 25
14
/ 25
Most read
15
/ 25
16
/ 25
Most read
17
/ 25
18
/ 25
Most read
19
/ 25
20
/ 25
21
/ 25
22
/ 25
23
/ 25
24
/ 25
25
/ 25
More Related Content
PPTX
畳み込みニューラルネットワークの高精度化と高速化
by
Yusuke Uchida
PPTX
[DL輪読会]YOLOv4: Optimal Speed and Accuracy of Object Detection
by
Deep Learning JP
PPTX
【DL輪読会】言語以外でのTransformerのまとめ (ViT, Perceiver, Frozen Pretrained Transformer etc)
by
Deep Learning JP
PPTX
backbone としての timm 入門
by
Takuji Tahara
PDF
[DL輪読会]ICLR2020の分布外検知速報
by
Deep Learning JP
PPTX
Curriculum Learning (関東CV勉強会)
by
Yoshitaka Ushiku
PDF
グラフニューラルネットワーク入門
by
ryosuke-kojima
PDF
Graph Attention Network
by
Takahiro Kubo
畳み込みニューラルネットワークの高精度化と高速化
by
Yusuke Uchida
[DL輪読会]YOLOv4: Optimal Speed and Accuracy of Object Detection
by
Deep Learning JP
【DL輪読会】言語以外でのTransformerのまとめ (ViT, Perceiver, Frozen Pretrained Transformer etc)
by
Deep Learning JP
backbone としての timm 入門
by
Takuji Tahara
[DL輪読会]ICLR2020の分布外検知速報
by
Deep Learning JP
Curriculum Learning (関東CV勉強会)
by
Yoshitaka Ushiku
グラフニューラルネットワーク入門
by
ryosuke-kojima
Graph Attention Network
by
Takahiro Kubo
What's hot
PDF
【メタサーベイ】基盤モデル / Foundation Models
by
cvpaper. challenge
PDF
研究効率化Tips Ver.2
by
cvpaper. challenge
PPTX
近年のHierarchical Vision Transformer
by
Yusuke Uchida
PDF
【メタサーベイ】数式ドリブン教師あり学習
by
cvpaper. challenge
PPTX
Deep Learningのための専用プロセッサ「MN-Core」の開発と活用(2022/10/19東大大学院「 融合情報学特別講義Ⅲ」)
by
Preferred Networks
PDF
【DL輪読会】A Path Towards Autonomous Machine Intelligence
by
Deep Learning JP
PPTX
学習時に使ってはいないデータの混入「リーケージを避ける」
by
西岡 賢一郎
PPTX
You Only Look One-level Featureの解説と見せかけた物体検出のよもやま話
by
Yusuke Uchida
PDF
TensorFlow Lite Delegateとは?
by
Mr. Vengineer
PDF
失敗から学ぶ機械学習応用
by
Hiroyuki Masuda
PDF
[GTCJ2018]CuPy -NumPy互換GPUライブラリによるPythonでの高速計算- PFN奥田遼介
by
Preferred Networks
PPTX
[DL輪読会] マルチエージェント強化学習と心の理論
by
Deep Learning JP
PDF
Optimizer入門&最新動向
by
Motokawa Tetsuya
PDF
Deep Learningによる画像認識革命 ー歴史・最新理論から実践応用までー
by
nlab_utokyo
PDF
Transformerを多層にする際の勾配消失問題と解決法について
by
Sho Takase
PDF
Active Learning 入門
by
Shuyo Nakatani
PDF
Lucas kanade法について
by
Hitoshi Nishimura
PPTX
PFNにおける研究開発(2022/10/19 東大大学院「融合情報学特別講義Ⅲ」)
by
Preferred Networks
PPTX
モデル高速化百選
by
Yusuke Uchida
PDF
画像認識のための深層学習
by
Saya Katafuchi
【メタサーベイ】基盤モデル / Foundation Models
by
cvpaper. challenge
研究効率化Tips Ver.2
by
cvpaper. challenge
近年のHierarchical Vision Transformer
by
Yusuke Uchida
【メタサーベイ】数式ドリブン教師あり学習
by
cvpaper. challenge
Deep Learningのための専用プロセッサ「MN-Core」の開発と活用(2022/10/19東大大学院「 融合情報学特別講義Ⅲ」)
by
Preferred Networks
【DL輪読会】A Path Towards Autonomous Machine Intelligence
by
Deep Learning JP
学習時に使ってはいないデータの混入「リーケージを避ける」
by
西岡 賢一郎
You Only Look One-level Featureの解説と見せかけた物体検出のよもやま話
by
Yusuke Uchida
TensorFlow Lite Delegateとは?
by
Mr. Vengineer
失敗から学ぶ機械学習応用
by
Hiroyuki Masuda
[GTCJ2018]CuPy -NumPy互換GPUライブラリによるPythonでの高速計算- PFN奥田遼介
by
Preferred Networks
[DL輪読会] マルチエージェント強化学習と心の理論
by
Deep Learning JP
Optimizer入門&最新動向
by
Motokawa Tetsuya
Deep Learningによる画像認識革命 ー歴史・最新理論から実践応用までー
by
nlab_utokyo
Transformerを多層にする際の勾配消失問題と解決法について
by
Sho Takase
Active Learning 入門
by
Shuyo Nakatani
Lucas kanade法について
by
Hitoshi Nishimura
PFNにおける研究開発(2022/10/19 東大大学院「融合情報学特別講義Ⅲ」)
by
Preferred Networks
モデル高速化百選
by
Yusuke Uchida
画像認識のための深層学習
by
Saya Katafuchi
Tensorflow Liteの量子化アーキテクチャ
1.
Tensorflow Liteの量⼦化アーキテクチャ 2020.8.1 ax
Inc. Presenter : Hitoshi Shinabe ( ax Inc. ) 1
2.
本セッションについて Tensorflow Liteを例に機械学習モデルの量⼦化のアーキテクチャを解説します ※資料については、Connpassイベントページにアップ予定です 2
3.
「量⼦化」について 3
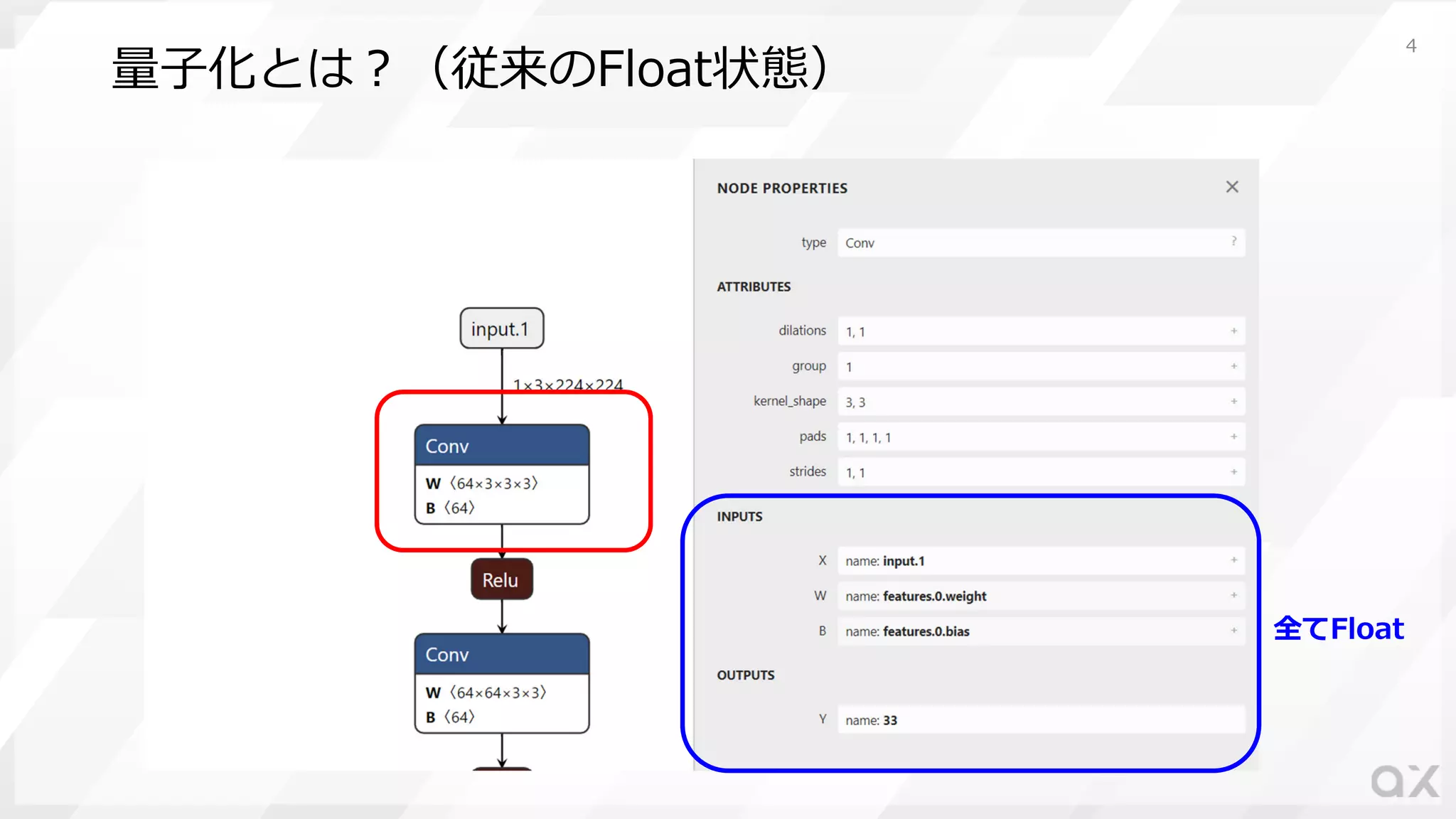
4.
量⼦化とは︖(従来のFloat状態) 全てFloat 4
5.
量⼦化するとなぜ良いのか︖ • 演算(処理速度)が速くなる • メモリが節約できる •
モデルが⼩さくなる → 組み込み機器や低パフォーマンス機器でも実⾏可能になる 5
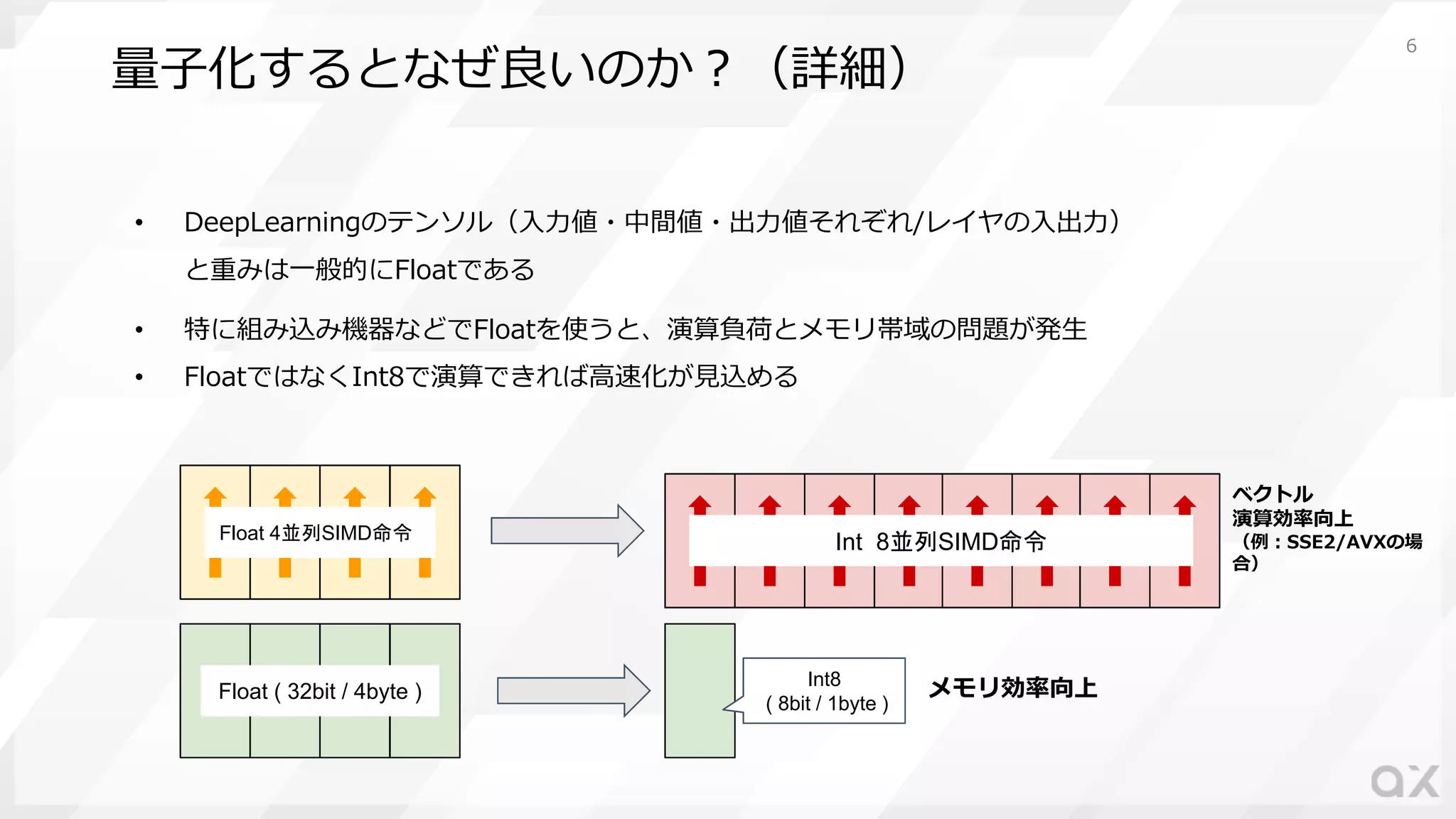
6.
量⼦化するとなぜ良いのか︖(詳細) • DeepLearningのテンソル(⼊⼒値・中間値・出⼒値それぞれ/レイヤの⼊出⼒) と重みは⼀般的にFloatである • 特に組み込み機器などでFloatを使うと、演算負荷とメモリ帯域の問題が発⽣ •
FloatではなくInt8で演算できれば⾼速化が⾒込める ベクトル 演算効率向上 (例︓SSE2/AVXの場 合) メモリ効率向上 Float 4並列SIMD命令 Int 8並列SIMD命令 Float ( 32bit / 4byte ) Int8 ( 8bit / 1byte ) 6
7.
量⼦化のデメリット とはいえ良いことずくめでもない ❖ 精度が落ちる ➢ 単純に演算精度が落ちるため、最終的な認識精度も落ちる ➢
いかに実⽤的な精度に落として量⼦化をするかがポイント ★ 対策 ○ 量⼦化に強いネットワークを使う ○ 量⼦化の⽅法を⼯夫する(今回はこちらの解説) 7
8.
TensorFlowでの量⼦化について 8
9.
Tensorflowにおける量⼦化⽅式(1.15.0以降) ・ダイナミックレンジ量⼦化︓重みだけInt8にする ・完全な整数量⼦化︓重みとテンソルをInt8にする ← 今回はこちらを解説(Post-training
integer quantization) 引用:https://www.tensorflow.org/lite/performance/post_training_quantization 歴史的に出てきた順番 9
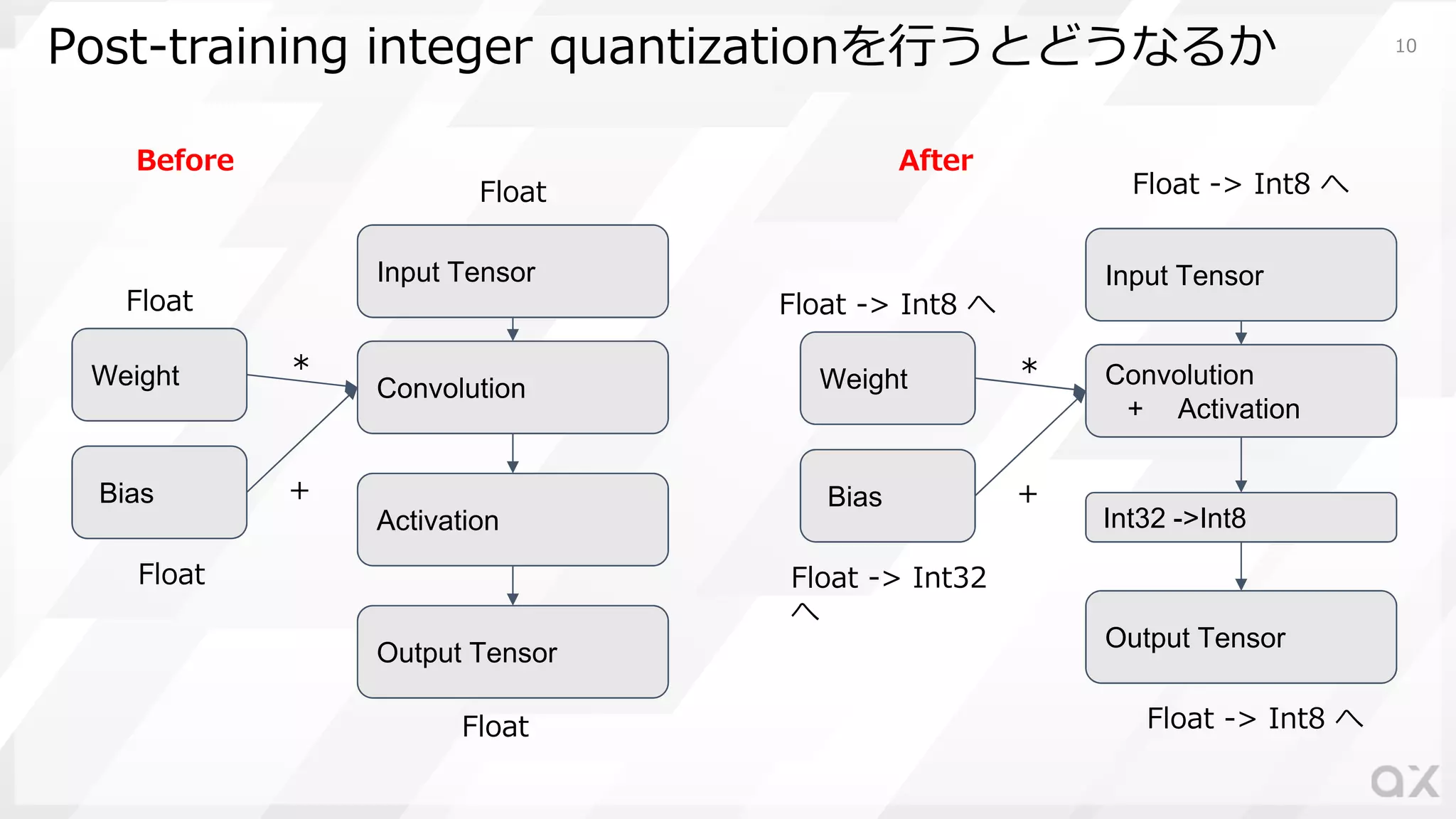
10.
Post-training integer quantizationを⾏うとどうなるか Input
Tensor Convolution + Activation Output Tensor Weight Float -> Int8 へ Float -> Int8 へ Float -> Int8 へ Bias Float -> Int32 へ Int32 ->Int8 * + Input Tensor Convolution Output Tensor Weight Float Float Float Bias Float Activation * + Before After 10
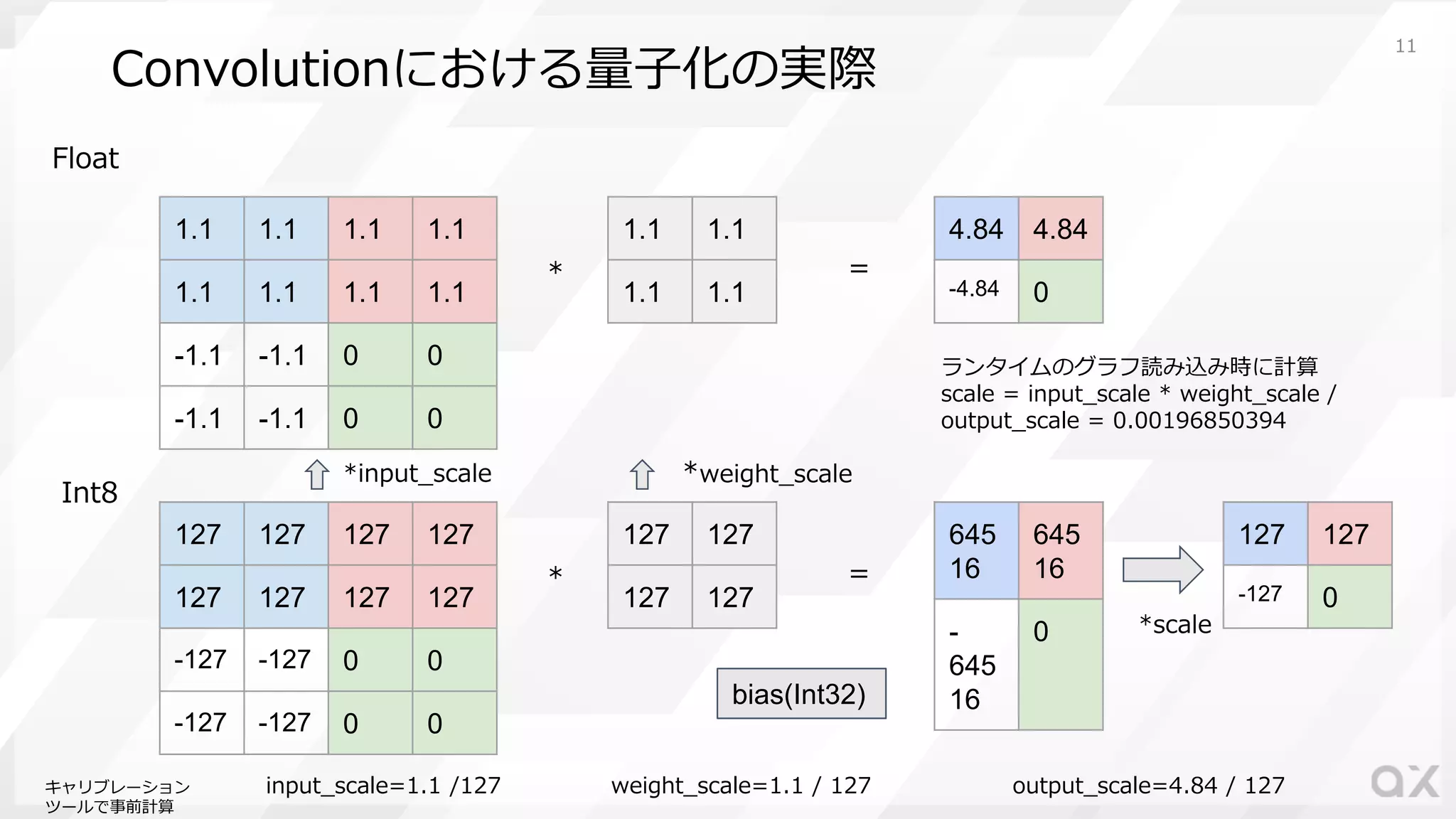
11.
Convolutionにおける量⼦化の実際 1.1 1.1 1.1
1.1 1.1 1.1 1.1 1.1 -1.1 -1.1 0 0 -1.1 -1.1 0 0 1.1 1.1 1.1 1.1 * 4.84 4.84 -4.84 0 = 127 127 127 127 127 127 127 127 -127 -127 0 0 -127 -127 0 0 127 127 127 127 * 645 16 645 16 - 645 16 0 = input_scale=1.1 /127 weight_scale=1.1 / 127 127 127 -127 0 output_scale=4.84 / 127 ランタイムのグラフ読み込み時に計算 scale = input_scale * weight_scale / output_scale = 0.00196850394 *scale *input_scale *weight_scale Float Int8 キャリブレーション ツールで事前計算 bias(Int32) 11
12.
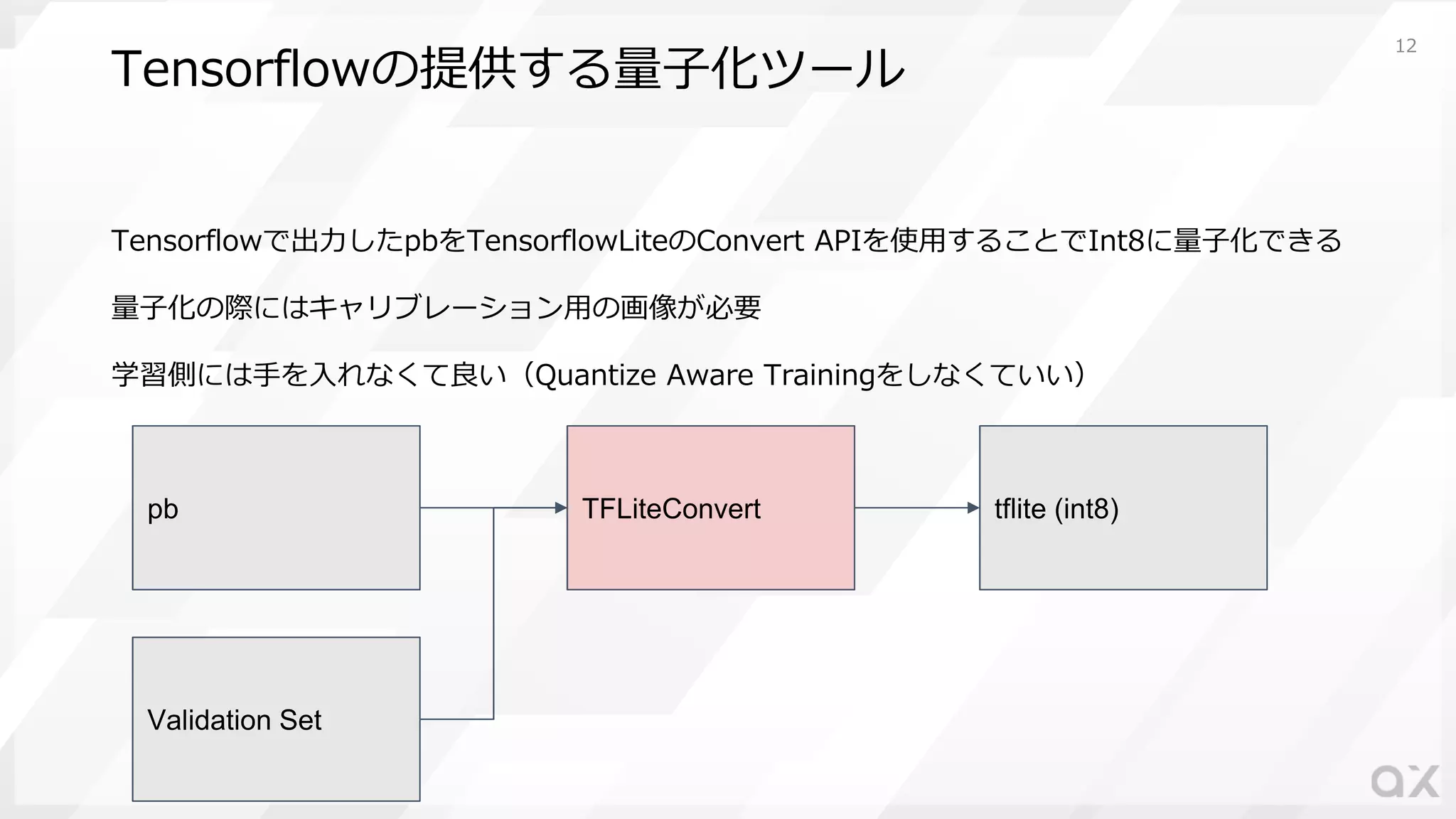
Tensorflowの提供する量⼦化ツール Tensorflowで出⼒したpbをTensorflowLiteのConvert APIを使⽤することでInt8に量⼦化できる 量⼦化の際にはキャリブレーション⽤の画像が必要 学習側には⼿を⼊れなくて良い(Quantize Aware
Trainingをしなくていい) pb tflite (int8)TFLiteConvert Validation Set 12
13.
量⼦化のスクリプトの例 Python APIのTFLiteConverter.from_frozen_graphを呼び出す supported_opsにTFLITE_BUILTINS_INT8を指定する 13
14.
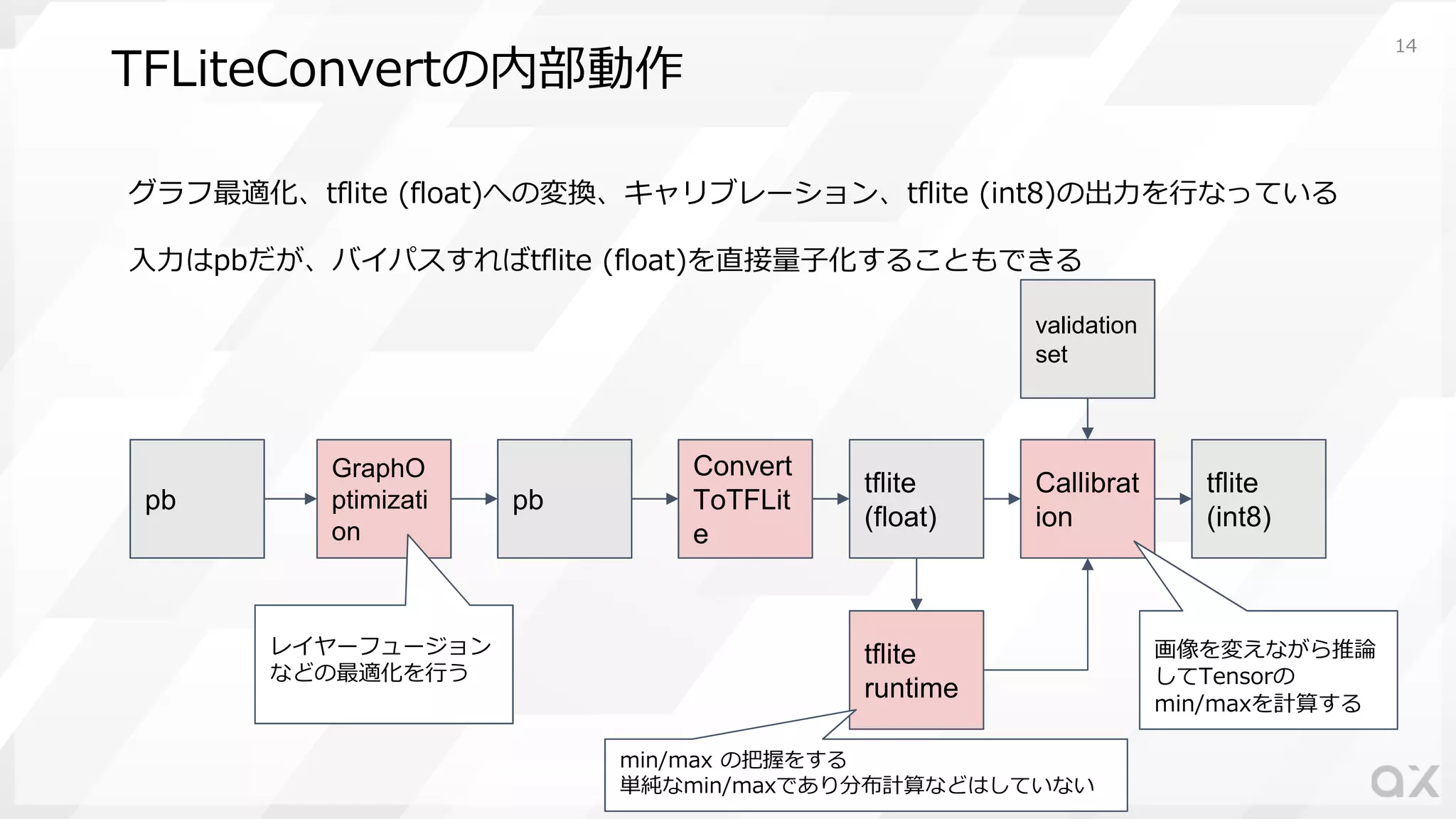
TFLiteConvertの内部動作 グラフ最適化、tflite (float)への変換、キャリブレーション、tflite (int8)の出⼒を⾏なっている ⼊⼒はpbだが、バイパスすればtflite
(float)を直接量⼦化することもできる pb GraphO ptimizati on pb Convert ToTFLit e tflite (float) Callibrat ion tflite (int8) tflite runtime validation set レイヤーフュージョン などの最適化を⾏う 画像を変えながら推論 してTensorの min/maxを計算する min/max の把握をする 単純なmin/maxであり分布計算などはしていない 14
15.
キャリブレーションにおけるmin/max テンソルのFloatの値の最⼩値と最⼤値を計算 スケールはzero_point=0の場合、最⼩値と最⼤値の絶対値の⼤きい⽅となる -7.0 -6.0 -5.0
-4.0 -3.0 -2.0 -1.0 0 1.0 2.0 3.0 4.0 5.0 6.0 7.0 8.0 min_v = -7.0 max_v = 8.0 scale = max(abs(min_v),abs(max_v)) / 127 15
16.
量⼦化したモデルの推論 tf.lite.Interpreterに量⼦化したモデルを与えることで推論できる 16
17.
量⼦化したモデルのフォーマットとパラメータへのアクセス⽅法 tflite (float)と同じくFlatBuffersになるが、tfliteのAPIではper-axis(チャンネル毎)の量⼦化パ ラメータは取得できないため、FlatBuffersに直接、アクセスする必要がある 17
18.
量⼦化の仕様 テンソルもしくはテンソル内のチャンネルごとにscaleとzero_pointを持つ scaleはfloatでtfliteファイルに格納される、zero_pointは64bit整数でtfliteファイルに格納される TensorFlow Lite 8-bit
quantization specification 引用:https://www.tensorflow.org/lite/performance/quantization_spec FloatとInt8の対応関係 18
19.
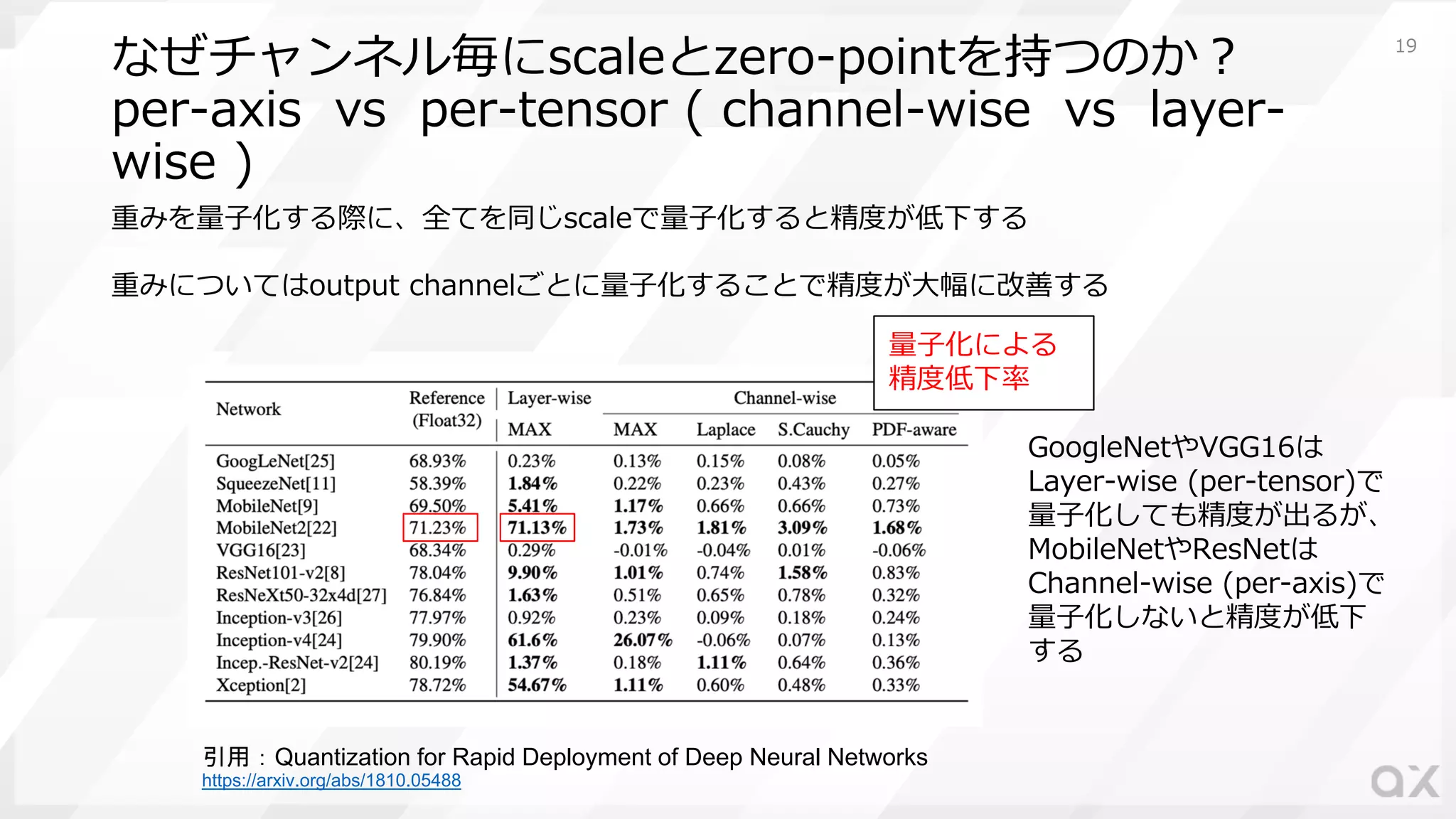
なぜチャンネル毎にscaleとzero-pointを持つのか︖ per-axis vs per-tensor
( channel-wise vs layer- wise ) 重みを量⼦化する際に、全てを同じscaleで量⼦化すると精度が低下する 重みについてはoutput channelごとに量⼦化することで精度が⼤幅に改善する 引用:Quantization for Rapid Deployment of Deep Neural Networks https://arxiv.org/abs/1810.05488 GoogleNetやVGG16は Layer-wise (per-tensor)で 量⼦化しても精度が出るが、 MobileNetやResNetは Channel-wise (per-axis)で 量⼦化しないと精度が低下 する 量⼦化による 精度低下率 19
20.
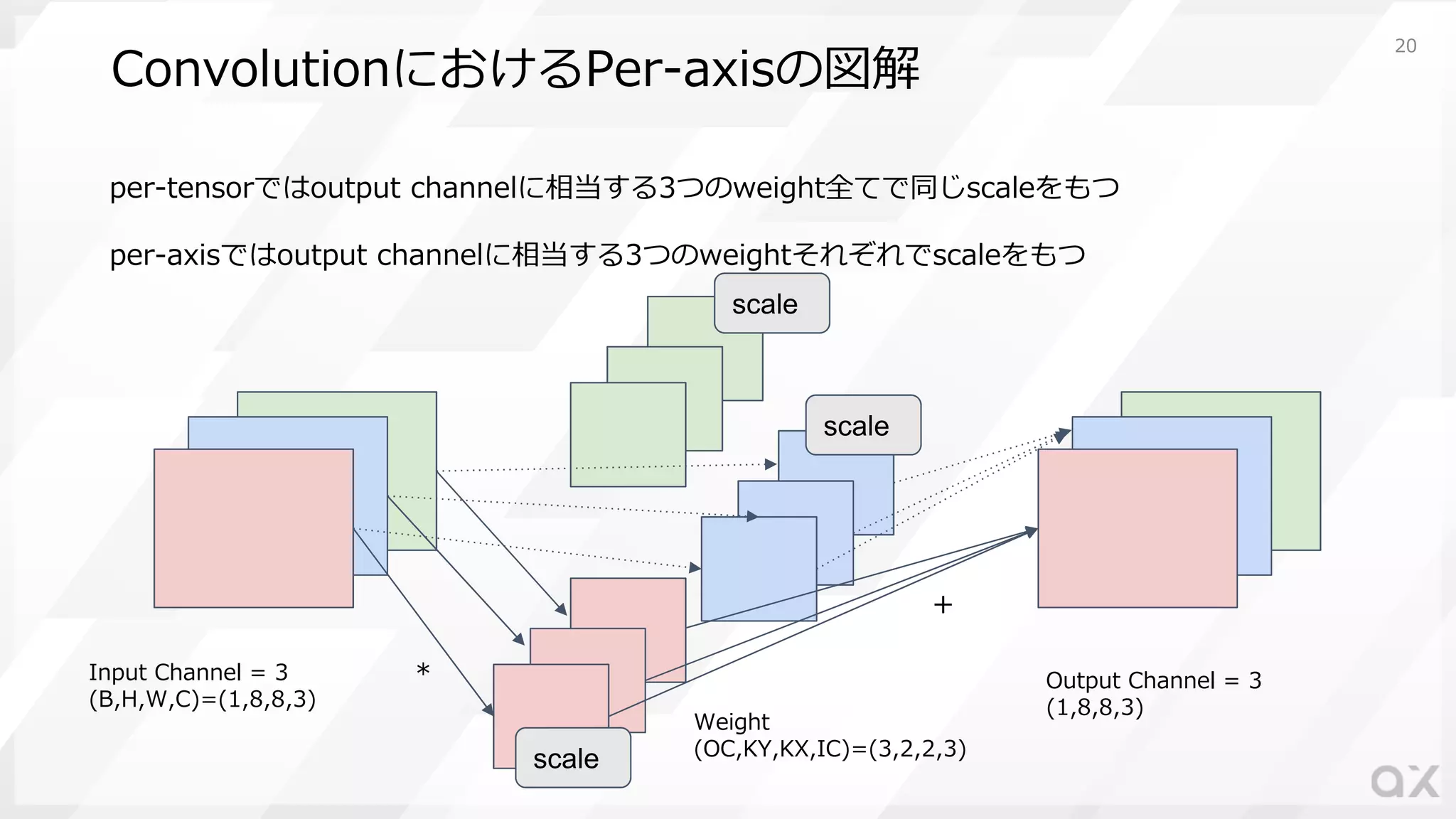
ConvolutionにおけるPer-axisの図解 per-tensorではoutput channelに相当する3つのweight全てで同じscaleをもつ per-axisではoutput channelに相当する3つのweightそれぞれでscaleをもつ Input
Channel = 3 (B,H,W,C)=(1,8,8,3) Output Channel = 3 (1,8,8,3) Weight (OC,KY,KX,IC)=(3,2,2,3) scale scale scale + * 20
21.
レイヤーごとの量⼦化設定 各レイヤーがどういう設定で量⼦化されるかが定義されている https://www.tensorflow.org/lite/performance/quantization_spec Output Channelご との量⼦化 22
22.
Tensorflowでの量⼦化の精度の例 MobileNetV2を量子化して時計の画像を入力した場合のクラス Per-axis Quantizationによってかなり高精度に推論できる MobileNetV2 keras model Predicted:
[('n02708093', 'analog_clock', 0.47966293), ('n04548280', 'wall_clock', 0.17145523), ('n04328186', 'stopwatch', 0.019265182)] tf lite float Predicted: [('n02708093', 'analog_clock', 0.47966337), ('n04548280', 'wall_clock', 0.171455), ('n04328186', 'stopwatch', 0.01926511)] tf lite int8 Predicted: [('n02708093', 'analog_clock', 104), ('n04548280', 'wall_clock', 48), ('n04328186', 'stopwatch', 8)] 23
23.
まとめ 量⼦化を⾏うことで精度をある程度、維持しながら演算速度を向上させることができる Tensorflow LiteのPost-training Quantizationを使⽤することで学習のやり⽅は変えずに量⼦化 できる 24
24.
ax株式会社について • クロスプラットフォームでGPUを使⽤した⾼速推論ができる「ailia SDK」を開発・提供 •
ailia SDKは無償評価版提供中︕詳しくはailia SDKのWEBサイトへ。 • 推論フレームワークをフルスクラッチで⾃社開発しています • AIチップ向け、組み込み機器向けに8bit量⼦化に対応中 • 組み込み機器でのディープラーニングでお困りの事がありましたらご相談下さい 25 ax株式会社 https://axinc.jp/ ailia SDK https://ailia.jp/
25.
ご清聴有り難うございました https://ailia.jp/ ご質問はDLLABのSlackにて︕ 26













![Tensorflowでの量⼦化の精度の例
MobileNetV2を量子化して時計の画像を入力した場合のクラス
Per-axis Quantizationによってかなり高精度に推論できる
MobileNetV2
keras model
Predicted: [('n02708093', 'analog_clock', 0.47966293), ('n04548280', 'wall_clock', 0.17145523), ('n04328186', 'stopwatch',
0.019265182)]
tf lite float
Predicted: [('n02708093', 'analog_clock', 0.47966337), ('n04548280', 'wall_clock', 0.171455), ('n04328186', 'stopwatch',
0.01926511)]
tf lite int8
Predicted: [('n02708093', 'analog_clock', 104), ('n04548280', 'wall_clock', 48), ('n04328186', 'stopwatch', 8)]
23](https://image.slidesharecdn.com/tensorflowlitequantizationaxinc-200804085227/75/Tensorflow-Lite-22-2048.jpg)




![[DL輪読会]YOLOv4: Optimal Speed and Accuracy of Object Detection](https://cdn.slidesharecdn.com/ss_thumbnails/200515dlseminar-200515082345-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DL輪読会]ICLR2020の分布外検知速報](https://cdn.slidesharecdn.com/ss_thumbnails/iclr2020ood-190927011524-thumbnail.jpg?width=640&height=640&fit=bounds)













![[GTCJ2018]CuPy -NumPy互換GPUライブラリによるPythonでの高速計算- PFN奥田遼介](https://cdn.slidesharecdn.com/ss_thumbnails/gtcj2018cupypfnryosukeokuta-181009073034-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会] マルチエージェント強化学習と心の理論](https://cdn.slidesharecdn.com/ss_thumbnails/0917imai-211210044729-thumbnail.jpg?width=640&height=640&fit=bounds)







