Download free for 30 days
Sign in
Upload
Language (EN)
Support
Business
Mobile
Social Media
Marketing
Technology
Art & Photos
Career
Design
Education
Presentations & Public Speaking
Government & Nonprofit
Healthcare
Internet
Law
Leadership & Management
Automotive
Engineering
Software
Recruiting & HR
Retail
Sales
Services
Science
Small Business & Entrepreneurship
Food
Environment
Economy & Finance
Data & Analytics
Investor Relations
Sports
Spiritual
News & Politics
Travel
Self Improvement
Real Estate
Entertainment & Humor
Health & Medicine
Devices & Hardware
Lifestyle
Change Language
Language
English
Español
Português
Français
Deutsche
Cancel
Save
Submit search
EN
Uploaded by
Yasuhiro Yoshimura
PDF, PPTX
5,378 views
【関東GPGPU勉強会#4】GTX 1080でComputer Vision アルゴリズムを色々動かしてみる
【関東GPGPU勉強会#4】GTX 1080でComputer Vision アルゴリズムを色々動かしてみる
Technology
◦
Related topics:
Computer Vision Insights
•
Read more
2
Save
Share
Embed
Embed presentation
Download
Download as PDF, PPTX
1
/ 38
2
/ 38
3
/ 38
4
/ 38
5
/ 38
6
/ 38
7
/ 38
8
/ 38
9
/ 38
10
/ 38
11
/ 38
12
/ 38
13
/ 38
14
/ 38
15
/ 38
16
/ 38
17
/ 38
18
/ 38
19
/ 38
20
/ 38
21
/ 38
22
/ 38
23
/ 38
24
/ 38
25
/ 38
26
/ 38
27
/ 38
28
/ 38
29
/ 38
30
/ 38
31
/ 38
32
/ 38
33
/ 38
34
/ 38
35
/ 38
36
/ 38
37
/ 38
38
/ 38
More Related Content
PDF
いまさら聞けない!CUDA高速化入門
by
Fixstars Corporation
PDF
CPU / GPU高速化セミナー!性能モデルの理論と実践:実践編
by
Fixstars Corporation
PDF
CUDAのアセンブリ言語基礎のまとめ PTXとSASSの概説
by
Takateru Yamagishi
PDF
GPGPU Seminar (GPU Accelerated Libraries, 3 of 3, Thrust)
by
智啓 出川
PPTX
画像処理ライブラリ OpenCV で 出来ること・出来ないこと
by
Norishige Fukushima
PDF
実践で学ぶネットワーク分析
by
Mitsunori Sato
PDF
何となく勉強した気分になれるパーサ入門
by
masayoshi takahashi
PDF
Crfと素性テンプレート
by
Kei Uchiumi
いまさら聞けない!CUDA高速化入門
by
Fixstars Corporation
CPU / GPU高速化セミナー!性能モデルの理論と実践:実践編
by
Fixstars Corporation
CUDAのアセンブリ言語基礎のまとめ PTXとSASSの概説
by
Takateru Yamagishi
GPGPU Seminar (GPU Accelerated Libraries, 3 of 3, Thrust)
by
智啓 出川
画像処理ライブラリ OpenCV で 出来ること・出来ないこと
by
Norishige Fukushima
実践で学ぶネットワーク分析
by
Mitsunori Sato
何となく勉強した気分になれるパーサ入門
by
masayoshi takahashi
Crfと素性テンプレート
by
Kei Uchiumi
What's hot
PDF
第1回 配信講義 計算科学技術特論A (2021)
by
RCCSRENKEI
PDF
プログラムを高速化する話Ⅱ 〜GPGPU編〜
by
京大 マイコンクラブ
PDF
GPUをJavaで使う話(Java Casual Talks #1)
by
なおき きしだ
PDF
マルチコアを用いた画像処理
by
Norishige Fukushima
PDF
GPGPU Seminar (GPU Accelerated Libraries, 1 of 3, cuBLAS)
by
智啓 出川
PDF
組み込み関数(intrinsic)によるSIMD入門
by
Norishige Fukushima
PDF
20180723 PFNの研究基盤 / PFN research system infrastructure
by
Preferred Networks
PDF
NTT DATA と PostgreSQL が挑んだ総力戦
by
NTT DATA OSS Professional Services
PDF
導入から 10 年、PHP の trait は滅びるべきなのか その適切な使いどころと弱点、将来について
by
shinjiigarashi
PDF
ARM CPUにおけるSIMDを用いた高速計算入門
by
Fixstars Corporation
PDF
ゴリラテスト モバイルゲームのUIを自動的に検出・操作する モンキーテスト
by
KLab Inc. / Tech
PDF
不遇の標準ライブラリ - valarray
by
Ryosuke839
PPTX
HttpClient詳解、或いは非同期の落とし穴について
by
Yoshifumi Kawai
PDF
正規表現リテラルは本当に必要なのか?
by
kwatch
PPTX
HashMapとは?
by
Trash Briefing ,Ltd
PDF
Objectnessとその周辺技術
by
Takao Yamanaka
PDF
SSII2022 [SS1] ニューラル3D表現の最新動向〜 ニューラルネットでなんでも表せる?? 〜
by
SSII
PDF
Marp Tutorial
by
Rui Watanabe
PDF
直交領域探索
by
okuraofvegetable
PDF
[DL輪読会]近年のエネルギーベースモデルの進展
by
Deep Learning JP
第1回 配信講義 計算科学技術特論A (2021)
by
RCCSRENKEI
プログラムを高速化する話Ⅱ 〜GPGPU編〜
by
京大 マイコンクラブ
GPUをJavaで使う話(Java Casual Talks #1)
by
なおき きしだ
マルチコアを用いた画像処理
by
Norishige Fukushima
GPGPU Seminar (GPU Accelerated Libraries, 1 of 3, cuBLAS)
by
智啓 出川
組み込み関数(intrinsic)によるSIMD入門
by
Norishige Fukushima
20180723 PFNの研究基盤 / PFN research system infrastructure
by
Preferred Networks
NTT DATA と PostgreSQL が挑んだ総力戦
by
NTT DATA OSS Professional Services
導入から 10 年、PHP の trait は滅びるべきなのか その適切な使いどころと弱点、将来について
by
shinjiigarashi
ARM CPUにおけるSIMDを用いた高速計算入門
by
Fixstars Corporation
ゴリラテスト モバイルゲームのUIを自動的に検出・操作する モンキーテスト
by
KLab Inc. / Tech
不遇の標準ライブラリ - valarray
by
Ryosuke839
HttpClient詳解、或いは非同期の落とし穴について
by
Yoshifumi Kawai
正規表現リテラルは本当に必要なのか?
by
kwatch
HashMapとは?
by
Trash Briefing ,Ltd
Objectnessとその周辺技術
by
Takao Yamanaka
SSII2022 [SS1] ニューラル3D表現の最新動向〜 ニューラルネットでなんでも表せる?? 〜
by
SSII
Marp Tutorial
by
Rui Watanabe
直交領域探索
by
okuraofvegetable
[DL輪読会]近年のエネルギーベースモデルの進展
by
Deep Learning JP
Viewers also liked
PPTX
畳み込みLstm
by
tak9029
PDF
【第33回コンピュータビジョン勉強会@関東】OpenVX、 NVIDIA VisionWorks使ってみた
by
Yasuhiro Yoshimura
PPTX
深層学習とTensorFlow入門
by
tak9029
PDF
Hough forestを用いた物体検出
by
MPRG_Chubu_University
PPTX
関東コンピュータビジョン勉強会
by
nonane
PDF
【関東GPGPU勉強会#3】OpenCVの新機能 UMatを先取りしよう
by
Yasuhiro Yoshimura
PDF
機械学習モデルフォーマットの話:さようならPMML、こんにちはPFA
by
Shohei Hido
PDF
TensorFlowプログラミングと分類アルゴリズムの基礎
by
Etsuji Nakai
PPTX
Gpgpu tomoaki-fp16
by
tomoaki0705
PPTX
有名論文から学ぶディープラーニング 2016.03.25
by
Minoru Chikamune
PDF
ディジタル信号処理 課題解説 その8
by
noname409
PDF
Cloud frontの概要と勘所
by
Kei Hirata
PDF
ディジタル信号処理 課題解説 その9
by
noname409
PPTX
20161203 cv 3_d_recon_tracking_eventcamera
by
Kyohei Unno
PPTX
Process Simulation using DWSIM
by
Naren P.R.
PDF
最先端NLP勉強会 “Learning Language Games through Interaction” Sida I. Wang, Percy L...
by
Yuya Unno
PPTX
Scilab: Computing Tool For Engineers
by
Naren P.R.
PDF
アセンブラ漢文
by
kozossakai
PDF
最近やった事とこれからやりたい事 2016年度年末版
by
Netwalker lab kapper
PDF
続・ハロー・ワールド入門(オープンソースカンファレンス2016 Tokyo/Spring ライトニングトーク)
by
kozossakai
畳み込みLstm
by
tak9029
【第33回コンピュータビジョン勉強会@関東】OpenVX、 NVIDIA VisionWorks使ってみた
by
Yasuhiro Yoshimura
深層学習とTensorFlow入門
by
tak9029
Hough forestを用いた物体検出
by
MPRG_Chubu_University
関東コンピュータビジョン勉強会
by
nonane
【関東GPGPU勉強会#3】OpenCVの新機能 UMatを先取りしよう
by
Yasuhiro Yoshimura
機械学習モデルフォーマットの話:さようならPMML、こんにちはPFA
by
Shohei Hido
TensorFlowプログラミングと分類アルゴリズムの基礎
by
Etsuji Nakai
Gpgpu tomoaki-fp16
by
tomoaki0705
有名論文から学ぶディープラーニング 2016.03.25
by
Minoru Chikamune
ディジタル信号処理 課題解説 その8
by
noname409
Cloud frontの概要と勘所
by
Kei Hirata
ディジタル信号処理 課題解説 その9
by
noname409
20161203 cv 3_d_recon_tracking_eventcamera
by
Kyohei Unno
Process Simulation using DWSIM
by
Naren P.R.
最先端NLP勉強会 “Learning Language Games through Interaction” Sida I. Wang, Percy L...
by
Yuya Unno
Scilab: Computing Tool For Engineers
by
Naren P.R.
アセンブラ漢文
by
kozossakai
最近やった事とこれからやりたい事 2016年度年末版
by
Netwalker lab kapper
続・ハロー・ワールド入門(オープンソースカンファレンス2016 Tokyo/Spring ライトニングトーク)
by
kozossakai
Similar to 【関東GPGPU勉強会#4】GTX 1080でComputer Vision アルゴリズムを色々動かしてみる
PDF
Halide による画像処理プログラミング入門
by
Fixstars Corporation
PDF
A100 GPU 搭載! P4d インスタンス 使いこなしのコツ
by
Kuninobu SaSaki
PPTX
画像処理の高性能計算
by
Norishige Fukushima
PDF
【de:code 2020】 AI とデータ サイエンスを加速する NVIDIA の最新 GPU アーキテクチャ
by
日本マイクロソフト株式会社
PDF
2009/12/10 GPUコンピューティングの現状とスーパーコンピューティングの未来
by
Preferred Networks
PDF
【旧版】2009/12/10 GPUコンピューティングの現状とスーパーコンピューティングの未来
by
Preferred Networks
PDF
【A-1】AIを支えるGPUコンピューティングの今
by
Developers Summit
PDF
[db analytics showcase Sapporo 2017] B14: GPU コンピューティング最前線 by エヌビディア 佐々木邦暢
by
Insight Technology, Inc.
KEY
GPGPU deいろんな問題解いてみた
by
Ryo Sakamoto
KEY
NVIDIA Japan Seminar 2012
by
Takuro Iizuka
PDF
GPUディープラーニング最新情報
by
ReNom User Group
PDF
2012-03-08 MSS研究会
by
Kimikazu Kato
PDF
Cuda
by
Shumpei Hozumi
PDF
20170421 tensor flowusergroup
by
ManaMurakami1
PDF
機械学習とこれを支える並列計算: ディープラーニング・スーパーコンピューターの応用について
by
ハイシンク創研 / Laboratory of Hi-Think Corporation
PDF
20170726 py data.tokyo
by
ManaMurakami1
DOC
GPGPUによるパーソナルスーパーコンピュータの可能性
by
Yusaku Watanabe
PDF
AWS Webinar 20201224
by
陽平 山口
KEY
GTC2011 Japan
by
Takuro Iizuka
PPTX
2012 1203-researchers-cafe
by
Toshiya Komoda
Halide による画像処理プログラミング入門
by
Fixstars Corporation
A100 GPU 搭載! P4d インスタンス 使いこなしのコツ
by
Kuninobu SaSaki
画像処理の高性能計算
by
Norishige Fukushima
【de:code 2020】 AI とデータ サイエンスを加速する NVIDIA の最新 GPU アーキテクチャ
by
日本マイクロソフト株式会社
2009/12/10 GPUコンピューティングの現状とスーパーコンピューティングの未来
by
Preferred Networks
【旧版】2009/12/10 GPUコンピューティングの現状とスーパーコンピューティングの未来
by
Preferred Networks
【A-1】AIを支えるGPUコンピューティングの今
by
Developers Summit
[db analytics showcase Sapporo 2017] B14: GPU コンピューティング最前線 by エヌビディア 佐々木邦暢
by
Insight Technology, Inc.
GPGPU deいろんな問題解いてみた
by
Ryo Sakamoto
NVIDIA Japan Seminar 2012
by
Takuro Iizuka
GPUディープラーニング最新情報
by
ReNom User Group
2012-03-08 MSS研究会
by
Kimikazu Kato
Cuda
by
Shumpei Hozumi
20170421 tensor flowusergroup
by
ManaMurakami1
機械学習とこれを支える並列計算: ディープラーニング・スーパーコンピューターの応用について
by
ハイシンク創研 / Laboratory of Hi-Think Corporation
20170726 py data.tokyo
by
ManaMurakami1
GPGPUによるパーソナルスーパーコンピュータの可能性
by
Yusaku Watanabe
AWS Webinar 20201224
by
陽平 山口
GTC2011 Japan
by
Takuro Iizuka
2012 1203-researchers-cafe
by
Toshiya Komoda
Recently uploaded
PDF
基礎から学ぶ PostgreSQL の性能監視 (PostgreSQL Conference Japan 2025 発表資料)
by
NTT DATA Technology & Innovation
PDF
PCCC25(設立25年記念PCクラスタシンポジウム):東京大学情報基盤センター テーマ1/2/3「Society5.0の実現を目指す『計算・データ・学習...
by
PC Cluster Consortium
PDF
安価な ロジック・アナライザを アナライズ(?),Analyze report of some cheap logic analyzers
by
たけおか しょうぞう
PDF
第25回FA設備技術勉強会_自宅で勉強するROS・フィジカルAIアイテム.pdf
by
TomohiroKusu
PDF
visionOS TC「新しいマイホームで過ごすApple Vision Proとの新生活」
by
Sugiyama Yugo
PPTX
DrupalCon Nara 2025の記録 .
by
iPride Co., Ltd.
基礎から学ぶ PostgreSQL の性能監視 (PostgreSQL Conference Japan 2025 発表資料)
by
NTT DATA Technology & Innovation
PCCC25(設立25年記念PCクラスタシンポジウム):東京大学情報基盤センター テーマ1/2/3「Society5.0の実現を目指す『計算・データ・学習...
by
PC Cluster Consortium
安価な ロジック・アナライザを アナライズ(?),Analyze report of some cheap logic analyzers
by
たけおか しょうぞう
第25回FA設備技術勉強会_自宅で勉強するROS・フィジカルAIアイテム.pdf
by
TomohiroKusu
visionOS TC「新しいマイホームで過ごすApple Vision Proとの新生活」
by
Sugiyama Yugo
DrupalCon Nara 2025の記録 .
by
iPride Co., Ltd.
【関東GPGPU勉強会#4】GTX 1080でComputer Vision アルゴリズムを色々動かしてみる
1.
GTX 1080でComputer Vision アルゴリズムを色々動かしてみる 関東GPGPU勉強会#4 2016/8/21 @dandelion1124
2.
自己紹介(1/2) Twitter ID:@dandelion1124 • 学生時代はコンピュータビジョン、VRの研究に従事 •
大学院の研究室でOpenCVのTipsサイトを作っていたら OpenCV関連書籍(OpenCVプログラミングブック)を書くことに • 現在は都内勤務エンジニア Web: http://atinfinity.github.io Wiki: https://github.com/atinfinity/lab/wiki 連載記事: http://www.buildinsider.net/small/opencv/
3.
自己紹介(2/2) • メインで参加している勉強会 – 関東コンピュータビジョン勉強会
#cvsaisentan http://sites.google.com/site/cvsaisentan/
4.
本日のアジェンダ • OpenCVとは • OpenCVのデータ構造 •
GpuMatとCUDAカーネルの連携 • CUDAカーネル実装 – フィルタ処理 – テンプレートマッチング • 速度計測いろいろ – OpenCV
5.
OpenCVとは Intelが開発したOpen SourceのComputer Vision ライブラリ。現在はItseezIntelが開発を行っている。 http://opencv.org/ •
公式サポートOS – Windows/Linux/Mac OS/Android/iOS • 公式サポート言語 – C/C++/Python/Java ※有志による非公式ラッパーの一覧を以下のサイトにまとめています。 https://github.com/atinfinity/lab/wiki/OpenCV-binding%E3%81%BE%E3%81%A8%E3%82%81 先日ItseezがIntelに買収される という発表がありました
6.
OpenCVのデータ構造 OpenCVで画像を格納するために使うデータ構造は おおまかに以下の4つ。 • Mat 画像データの入れ物(CPU版) •
UMat 画像データの入れ物(CPU/OpenCL版) • GpuMat 画像データの入れ物(CUDA版) UMatについては前回勉強会の発表資料を参照ください。 http://www.slideshare.net/YasuhiroYoshimura/gpgpu-dandelion1124-201301130 ※上記資料は2013年11月時点のものなので最新版ではAPI仕様が少し変わっています。
7.
GpuMatとCUDAカーネルの連携 GpuMatとCUDAカーネルを連携する場合は、 cudevモジュールのGlobPtrSz、PtrStepSzを活用すると 便利です。 • GlobPtrSz:cols(幅)、rows (高さ)
、step等が参照可 • PtrStepSz:cols (幅)、rows (高さ)、step、ptr等が参照可 – Ptrメソッドを使うとポインタのアドレス計算を簡略化できる – 以降のコードではこちらを使います 参考:http://proc-cpuinfo.fixstars.com/2016/08/gpumat.html
8.
サンプルコード(PtrStepSz) // PtrStepSz型の変数を生成 cv::cudev::PtrStepSz<uchar> pSrc
= cv::cudev::PtrStepSz<uchar>(src.rows, src.cols * src.channels(), src.ptr<uchar>(), src.step); const dim3 block(64, 2); const dim3 grid(cv::cudev::divUp(dst.cols, block.x), cv::cudev::divUp(dst.rows, block.y)); // CUDAカーネルを呼び出す kernel<<<grid, block>>>(pSrc); // カーネル引数としてPtrStepSz型の変数を渡す CV_CUDEV_SAFE_CALL(cudaGetLastError()); CV_CUDEV_SAFE_CALL(cudaDeviceSynchronize()); カーネル呼び出し部
9.
サンプルコード(PtrStepSz) // カーネル引数としてPtrStepSz型の変数を受け取る __global__ void
kernel(cv::cudev::PtrStepSz<uchar> src) { int x = blockDim.x * blockIdx.x + threadIdx.x; int y = blockDim.y * blockIdx.y + threadIdx.y; if(x < src.cols && y < src.rows) { uchar val = src.ptr(y)[x]; // 座標(x, y)の画素値を参照する } } CUDAカーネル
10.
【追記】GpuMatとCUDAカーネルの連携 GpuMatとCUDAカーネルを連携する場合は、 cudevモジュールのGlobPtrSz、PtrStepSzを活用すると 便利です。 発表時に「CUDAカーネルの引数としてGpuMatクラスの インスタンスを直接渡せる」というご指摘を受けたため、 確認したところ、正しく動作することがわかりました。 実装する際にはGpuMatクラスのインスタンスを渡した方が わかりやすそうです。
11.
【追記】サンプルコード(GpuMat) cv::Mat src =
cv::imread("lena.jpg", cv::IMREAD_GRAYSCALE); cv::cuda::GpuMat d_src(src); const dim3 block(64, 2); const dim3 grid(cv::cudev::divUp(dst.cols, block.x), cv::cudev::divUp(dst.rows, block.y)); // CUDAカーネルを呼び出す kernel<<<grid, block>>>(d_src); // カーネル引数としてGpuMatクラスのインスタンスを渡す CV_CUDEV_SAFE_CALL(cudaGetLastError()); CV_CUDEV_SAFE_CALL(cudaDeviceSynchronize()); カーネル呼び出し部
12.
【追記】サンプルコード(GpuMat) // カーネル引数としてGpuMatクラスのインスタンスを受け取る __global__ void
kernel(cv::cuda::GpuMat src) { int x = blockDim.x * blockIdx.x + threadIdx.x; int y = blockDim.y * blockIdx.y + threadIdx.y; if(x < src.cols && y < src.rows) { uchar val = src.ptr(y)[x]; // 座標(x, y)の画素値を参照する } } CUDAカーネル
13.
CUDAカーネル実装 よーし、CUDAカーネル書くぞー! →まずはCUDA8のドキュメントを読もう →Pascal Tuning Guideはまだない? ※CUDA
8 RCのドキュメント
14.
ご清聴ありがとうございました
15.
CUDAカーネル実装 よーし、CUDAカーネル書くぞー! →まずはCUDA8のドキュメントを読もう →Pascal Tuning Guideはまだない? →今回は手探りでやってみましょう ※CUDA
8 RCのドキュメント
16.
CUDAカーネル実装 • 計測環境 – OS:Ubuntu
16.04 LTS(64bit) – CUDA:CUDA Toolkit v8.0 – GCC:5.4.0 – CPU:Intel Xeon CPU E5-2623 v3 @ 3.00GHz – メモリ:128GB – GPU:GeForce GTX 1080 • Pascalアーキテクチャ
17.
CUDAカーネル実装 • 計測環境(比較用) – OS:Ubuntu
16.04 LTS(64bit) – CUDA:CUDA Toolkit v8.0 – GCC:5.4.0 – CPU:Intel Xeon CPU E5-2623 v3 @ 3.00GHz – メモリ:128GB – GPU:GeForce GTX TITAN X • Maxwellアーキテクチャ
18.
CUDAカーネル実装 • 計測環境(比較用) – OS:Windows
10 Pro(64bit) – CUDA:CUDA Toolkit v7.5 – Visual Studio:Visual Studio 2013 Update5 – CPU:Intel Core i7-3930K @ 3.20GHz – メモリ:32GB – GPU:GeForce GTX 680 • Keplerアーキテクチャ
19.
CUDAカーネル実装 GeForce GTX 1080 GeForce GTX Titan
X GeForce GTX 680 アーキテクチャ Pascal Maxwell Kepler CUDAコア数 2560基 3072基 1536基 定格クロック 1607MHz 1000MHz 1006MHz ブーストクロック 1733MHz 1075MHz 1058MHz メモリバス帯域幅 320GB/s 336.5GB/s 192.2GB/s メモリ容量 8GB 12GB 2GB 動作クロックが大きく向上 メモリバス帯域幅はGeForce Titan Xとほぼ同等 CUDAコア、メモリ容量がGTX 1080より多い
20.
フィルタ処理 • 着目座標および周辺の画素値にカーネル係数で重み付けし た値を計算する処理 • 以下の例だと・・・ (1/9)*11
+ (1/9)*14 + (1/9)*11 + (1/9)*13 + (1/9)*10 + (1/9)*13 + (1/9)*11 + (1/9)*14 + (1/9)*11 = 12 カーネル(3x3) 11 13 11 14 13 14 11 10 11 入力画像 1/9 1/9 1/9 1/9 1/9 1/9 1/91/91/9 注目座標 12 出力画像 積和演算が多い!! この例だと積:9回、和:9回
21.
フィルタ処理(CPU実装) ソースコード:https://github.com/atinfinity/imageFilteringGpu for(int y =
border_size; y < (dst.rows - border_size); y++){ uchar* pdst = dst.ptr<uchar>(y); for(int x = border_size; x < (dst.cols - border_size); x++){ double sum = 0.0; for(int yy = 0; yy < kernel.rows; yy++){ for(int xx = 0; xx < kernel.cols; xx++){ sum += (kernel.ptr<float>(yy)[xx] * src.ptr<uchar>(y+yy-border_size)[x+xx-border_size]); } } pdst[x] = sum; } } 計算結果をストア カーネル係数で重み付けして加算
22.
フィルタ処理 • Naive実装 – CPU実装の類似度計算部分をそのままCUDAに持ってくる •
__ldg関数利用 – __ldg関数を使ってRead-Onlyキャッシュ経由でデータ読 み込み • テクスチャメモリ利用 – 画像データをテクスチャメモリに格納し、カーネルで参照 ソースコード:https://github.com/atinfinity/imageFilteringGpu
23.
フィルタ処理(Naive実装) ソースコード:https://github.com/atinfinity/imageFilteringGpu if((y >= border_size)
&& y < (dst.rows-border_size)){ if((x >= border_size) && (x < (dst.cols-border_size))){ double sum = 0.0; for(int yy = 0; yy < kernel.rows; yy++){ for(int xx = 0; xx < kernel.cols; xx++){ sum += (kernel.ptr(yy)[xx] * src.ptr(y+yy-border_size)[x+xx-border_size]); } } dst.ptr(y)[x] = sum; } } 範囲チェック カーネル係数で重み付けして加算 計算結果をストア
24.
フィルタ処理(__ldg関数利用) ソースコード:https://github.com/atinfinity/imageFilteringGpu if((y >= border_size)
&& y < (dst.rows-border_size)){ if((x >= border_size) && (x < (dst.cols-border_size))){ double sum = 0.0; for(int yy = 0; yy < kernel.rows; yy++){ const uchar* psrc = src.ptr(y+yy-border_size) + (x-border_size); const float* pkernel = kernel.ptr(yy); for(int xx = 0; xx < kernel.cols; xx++){ sum += (__ldg(&pkernel[xx]) * __ldg(&psrc[xx])); } } dst.ptr(y)[x] = sum; } } __ldg関数を利用してRead-Onlyキャッシュ経由で読み込み
25.
フィルタ処理(テクスチャメモリ利用) ソースコード:https://github.com/atinfinity/imageFilteringGpu // bind texture cv::cuda::device::bindTexture<uchar>(&srcTex,
pSrc); const dim3 block(64, 2); const dim3 grid(cv::cudev::divUp(dst.cols, block.x), cv::cudev::divUp(dst.rows, block.y)); imageFilteringGpu_tex<<<grid, block>>>(pSrc, pDst, pKernel, border_size); CV_CUDEV_SAFE_CALL(cudaGetLastError()); CV_CUDEV_SAFE_CALL(cudaDeviceSynchronize()); // unbind texture CV_CUDEV_SAFE_CALL(cudaUnbindTexture(srcTex)); カーネル呼び出し部 OpenCVに便利関数があるので活用! なぜかunbind用の便利関数が 見当たらなかったので直接呼ぶ・・・
26.
フィルタ処理(テクスチャメモリ利用) ソースコード:https://github.com/atinfinity/imageFilteringGpu if((y >= border_size)
&& (y < (dst.rows-border_size))){ if((x >= border_size) && (x < (dst.cols-border_size))){ double sum = 0.0; for(int yy = 0; yy < kernel.rows; yy++){ for(int xx = 0; xx < kernel.cols; xx++){ sum += (kernel.ptr(yy)[xx] * tex2D(srcTex, x + xx - border_size, y + yy - border_size)); } } dst.ptr(y)[x] = sum; } } Tex2D関数を使ってテクスチャメモリを参照 CUDAカーネル
27.
フィルタ処理 入力画像はw=800、h=640のグレースケール画像 単位はms
5回計測して平均をとる GTX 1080 (Pascal) GTX TITAN X (Maxwell) GTX680 (Kepler) CPU実装(Naive) 57.521 44.158 39.255 OpenCV(Mat) 4.956 4.980 5.212 CUDA実装(Naive) 0.426 0.606 1.138 CUDA実装 (__ldg関数使用) 0.417 0.560 - CUDA実装 (テクスチャメモリ使用) 0.531 0.618 1.168 CC3.0では__ldgが使えない・・・
28.
テンプレートマッチング • 画像中から特定のパターンを見付ける処理 • 類似度の指標はいくつかある –
SSD:差の2乗の総和 – SAD:差の絶対値の総和 etc… • 今回はSSDという指標について実装します 参考:http://imagingsolution.blog107.fc2.com/blog-entry-186.html
29.
テンプレートマッチング(CPU実装) ソースコード:https://github.com/atinfinity/matchTemplateGpu for(int y =
0; y < result.rows; y++){ float* presult = result.ptr<float>(y); for(int x = 0; x < result.cols; x++){ long sum = 0; for(int yy = 0; yy < templ.rows; yy++){ const uchar* pimg = img.ptr<uchar>(y + yy); const uchar* ptempl = templ.ptr<uchar>(yy); for(int xx = 0; xx < templ.cols; xx++){ int diff = pimg[x + xx] - ptempl[xx]; sum += (diff*diff); } } presult[x] = sum; } } 画素値の差を計算 差の二乗和を加算
30.
テンプレートマッチング 1. Naive実装 CPU実装の類似度計算部分をそのままCUDAに持ってくる 2.
shared memory利用 テンプレート画像は頻繁に参照するため、shared memoryに格納 テンプレートサイズは任意なので動的にshared memoryを確保 3. 2. + __ldg利用 __ldg関数を使ってRead-Onlyキャッシュ経由でデータ読み込み ソースコード:https://github.com/atinfinity/matchTemplateGpu
31.
テンプレートマッチング(Naive実装) ソースコード:https://github.com/atinfinity/matchTemplateGpu if((x < result.cols)
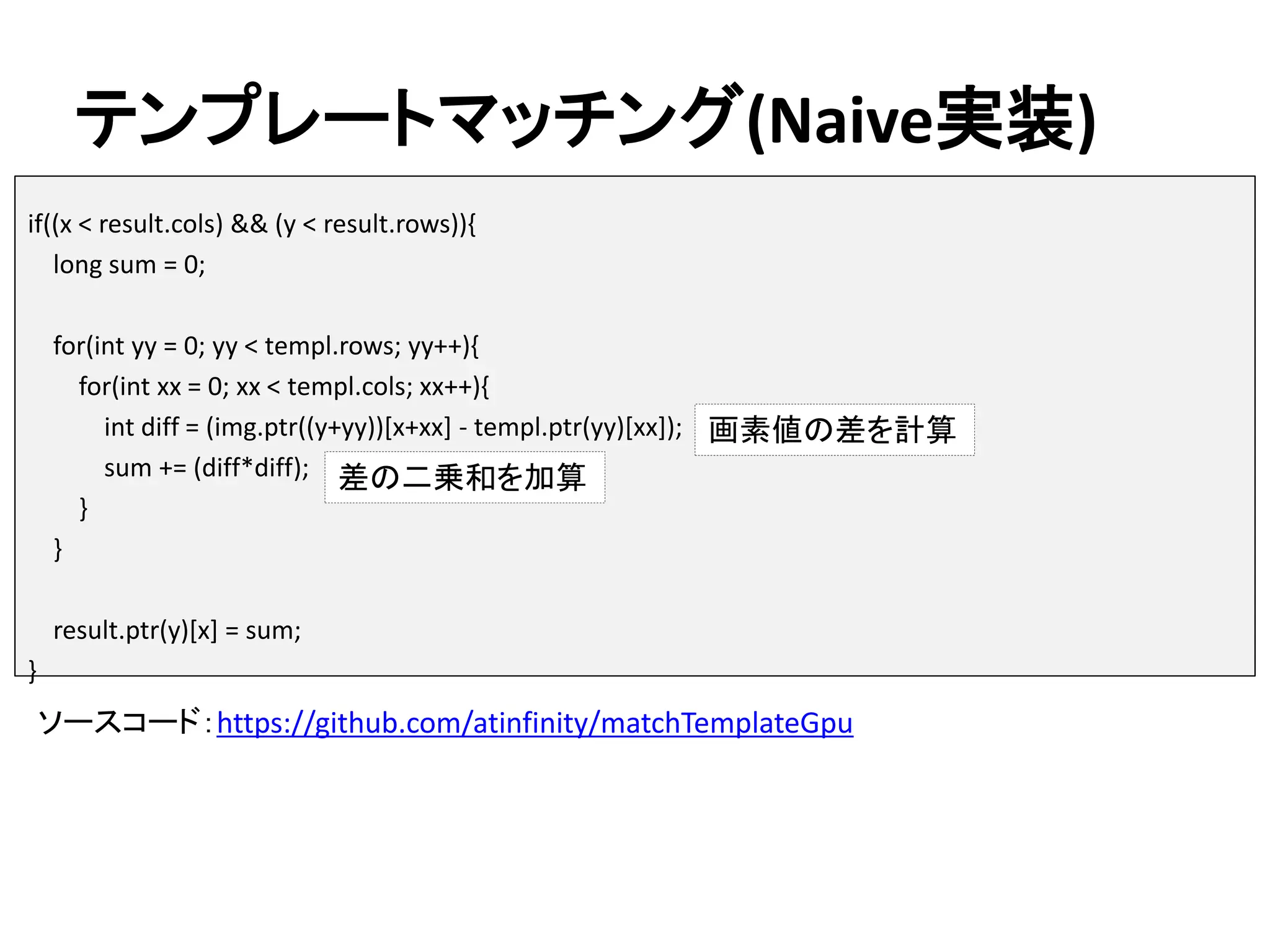
&& (y < result.rows)){ long sum = 0; for(int yy = 0; yy < templ.rows; yy++){ for(int xx = 0; xx < templ.cols; xx++){ int diff = (img.ptr((y+yy))[x+xx] - templ.ptr(yy)[xx]); sum += (diff*diff); } } result.ptr(y)[x] = sum; } 差の二乗和を加算 画素値の差を計算
32.
テンプレートマッチング(32x32) 入力画像はw=1920、h=1080のグレースケール画像 単位はms
5回計測して平均をとる GTX 1080 (Pascal) GTX TITAN X (Maxwell) GTX680 (Kepler) CPU実装(Naive) 1696.070 1728.700 1107.840 OpenCV(Mat) 36.876 36.782 38.723 CUDA実装(Naive) 13.845 19.483 46.181 CUDA実装 (shared memory) 7.851 11.834 49.417 CUDA実装 (shared memory + __ldg) 6.931 9.641 - CC3.0では__ldgが 使えない・・・
33.
テンプレートマッチング(64x64) 入力画像はw=1920、h=1080のグレースケール画像 単位はms
5回計測して平均をとる GTX 1080 (Pascal) GTX TITAN X (Maxwell) GTX680 (Kepler) CPU実装(Naive) 5527.08 5519.98 OpenCV(Mat) 65.84 65.32 CUDA実装(Naive) 36.64 46.87 CUDA実装 (shared memory) 27.50 38.87 CUDA実装 (shared memory + __ldg) 25.15 33.02 -
34.
速度計測いろいろ(OpenCV) • cudafilters – GaussianBlur –
BoxFilter • cudafeatures2d – ORB – FAST • cudaobjdetect – HOG
35.
速度計測いろいろ(OpenCV) 入力画像はw=800、h=640のグレースケール画像 単位はms
5回計測して平均をとる GTX 1080 (Pascal) GTX TITAN X (Maxwell) GTX680 (Kepler) GaussianBlur 0.065 0.237 0.757 BoxFilter 0.265 0.564 1.671 ORB 4.295 6.688 11.665 FAST 0.443 0.474 1.252 HOG 9.884 13.099 40.300
36.
やり残したこと • テンプレートマッチング(CUDA版)のチューニング – 演算部分の最適化 –
【追記】long型を使用している箇所を見直す – アルゴリズムそのものの見直し • CUDA8から追加された機能を試す – cudaMemPrefetchAsyncなるAPIが増えているのに気付いたけど使い方 がよくわからず・・・ • 【追記】Unified Memoryのprefetchに関するAPIのようです。 • OpenCVベンチマーク – 詳細なプロファイリングおよび分析 • NPPベンチマーク – CUDA8のNPPはPascal世代にも最適化されている?
37.
まとめ • GpuMatとCUDAカーネルの連携は簡単 – cudevモジュールのGlobPtrSz、PtrStepSzが便利 –
【追記】CUDAカーネルにGpuMatクラスのインスタンスを直接渡せる • GTX 1080では動作クロックが大きく向上 – 演算ネックとなる問題に対しては恩恵が得られている • OpenCVのcudaモジュールも(少なくとも今回検証した関数につい ては)GTX 1080上で高速に動作 – ただし、OpenCVのcudaモジュールが最新アーキテクチャに対して十分な 最適化がなされているかは要検証 • Pascal Tuning Guide欲しい!!
38.
おわり
Download








![サンプルコード(PtrStepSz)
// カーネル引数としてPtrStepSz型の変数を受け取る
__global__ void kernel(cv::cudev::PtrStepSz<uchar> src)
{
int x = blockDim.x * blockIdx.x + threadIdx.x;
int y = blockDim.y * blockIdx.y + threadIdx.y;
if(x < src.cols && y < src.rows) {
uchar val = src.ptr(y)[x]; // 座標(x, y)の画素値を参照する
}
}
CUDAカーネル](https://image.slidesharecdn.com/gpgpudandelion112420160820-160821042915/75/GPGPU-4-GTX-1080-Computer-Vision-9-2048.jpg)


![【追記】サンプルコード(GpuMat)
// カーネル引数としてGpuMatクラスのインスタンスを受け取る
__global__ void kernel(cv::cuda::GpuMat src)
{
int x = blockDim.x * blockIdx.x + threadIdx.x;
int y = blockDim.y * blockIdx.y + threadIdx.y;
if(x < src.cols && y < src.rows) {
uchar val = src.ptr(y)[x]; // 座標(x, y)の画素値を参照する
}
}
CUDAカーネル](https://image.slidesharecdn.com/gpgpudandelion112420160820-160821042915/75/GPGPU-4-GTX-1080-Computer-Vision-12-2048.jpg)








![フィルタ処理(CPU実装)
ソースコード:https://github.com/atinfinity/imageFilteringGpu
for(int y = border_size; y < (dst.rows - border_size); y++){
uchar* pdst = dst.ptr<uchar>(y);
for(int x = border_size; x < (dst.cols - border_size); x++){
double sum = 0.0;
for(int yy = 0; yy < kernel.rows; yy++){
for(int xx = 0; xx < kernel.cols; xx++){
sum +=
(kernel.ptr<float>(yy)[xx] * src.ptr<uchar>(y+yy-border_size)[x+xx-border_size]);
}
}
pdst[x] = sum;
}
}
計算結果をストア
カーネル係数で重み付けして加算](https://image.slidesharecdn.com/gpgpudandelion112420160820-160821042915/75/GPGPU-4-GTX-1080-Computer-Vision-21-2048.jpg)

![フィルタ処理(Naive実装)
ソースコード:https://github.com/atinfinity/imageFilteringGpu
if((y >= border_size) && y < (dst.rows-border_size)){
if((x >= border_size) && (x < (dst.cols-border_size))){
double sum = 0.0;
for(int yy = 0; yy < kernel.rows; yy++){
for(int xx = 0; xx < kernel.cols; xx++){
sum += (kernel.ptr(yy)[xx] * src.ptr(y+yy-border_size)[x+xx-border_size]);
}
}
dst.ptr(y)[x] = sum;
}
}
範囲チェック
カーネル係数で重み付けして加算
計算結果をストア](https://image.slidesharecdn.com/gpgpudandelion112420160820-160821042915/75/GPGPU-4-GTX-1080-Computer-Vision-23-2048.jpg)
![フィルタ処理(__ldg関数利用)
ソースコード:https://github.com/atinfinity/imageFilteringGpu
if((y >= border_size) && y < (dst.rows-border_size)){
if((x >= border_size) && (x < (dst.cols-border_size))){
double sum = 0.0;
for(int yy = 0; yy < kernel.rows; yy++){
const uchar* psrc = src.ptr(y+yy-border_size) + (x-border_size);
const float* pkernel = kernel.ptr(yy);
for(int xx = 0; xx < kernel.cols; xx++){
sum += (__ldg(&pkernel[xx]) * __ldg(&psrc[xx]));
}
}
dst.ptr(y)[x] = sum;
}
}
__ldg関数を利用してRead-Onlyキャッシュ経由で読み込み](https://image.slidesharecdn.com/gpgpudandelion112420160820-160821042915/75/GPGPU-4-GTX-1080-Computer-Vision-24-2048.jpg)

![フィルタ処理(テクスチャメモリ利用)
ソースコード:https://github.com/atinfinity/imageFilteringGpu
if((y >= border_size) && (y < (dst.rows-border_size))){
if((x >= border_size) && (x < (dst.cols-border_size))){
double sum = 0.0;
for(int yy = 0; yy < kernel.rows; yy++){
for(int xx = 0; xx < kernel.cols; xx++){
sum += (kernel.ptr(yy)[xx] * tex2D(srcTex, x + xx - border_size, y + yy - border_size));
}
}
dst.ptr(y)[x] = sum;
}
}
Tex2D関数を使ってテクスチャメモリを参照
CUDAカーネル](https://image.slidesharecdn.com/gpgpudandelion112420160820-160821042915/75/GPGPU-4-GTX-1080-Computer-Vision-26-2048.jpg)

![テンプレートマッチング(CPU実装)
ソースコード:https://github.com/atinfinity/matchTemplateGpu
for(int y = 0; y < result.rows; y++){
float* presult = result.ptr<float>(y);
for(int x = 0; x < result.cols; x++){
long sum = 0;
for(int yy = 0; yy < templ.rows; yy++){
const uchar* pimg = img.ptr<uchar>(y + yy);
const uchar* ptempl = templ.ptr<uchar>(yy);
for(int xx = 0; xx < templ.cols; xx++){
int diff = pimg[x + xx] - ptempl[xx];
sum += (diff*diff);
}
}
presult[x] = sum;
}
}
画素値の差を計算
差の二乗和を加算](https://image.slidesharecdn.com/gpgpudandelion112420160820-160821042915/75/GPGPU-4-GTX-1080-Computer-Vision-29-2048.jpg)

![テンプレートマッチング(Naive実装)
ソースコード:https://github.com/atinfinity/matchTemplateGpu
if((x < result.cols) && (y < result.rows)){
long sum = 0;
for(int yy = 0; yy < templ.rows; yy++){
for(int xx = 0; xx < templ.cols; xx++){
int diff = (img.ptr((y+yy))[x+xx] - templ.ptr(yy)[xx]);
sum += (diff*diff);
}
}
result.ptr(y)[x] = sum;
}
差の二乗和を加算
画素値の差を計算](https://image.slidesharecdn.com/gpgpudandelion112420160820-160821042915/75/GPGPU-4-GTX-1080-Computer-Vision-31-2048.jpg)
































![SSII2022 [SS1] ニューラル3D表現の最新動向〜 ニューラルネットでなんでも表せる?? 〜](https://cdn.slidesharecdn.com/ss_thumbnails/ss1ssii2022hkatoneural3drepresentationhiroharukato-220607054619-fadc6480-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DL輪読会]近年のエネルギーベースモデルの進展](https://cdn.slidesharecdn.com/ss_thumbnails/energybasedmodel-200124020855-thumbnail.jpg?width=640&height=640&fit=bounds)


























![[db analytics showcase Sapporo 2017] B14: GPU コンピューティング最前線 by エヌビディア 佐々木邦暢](https://cdn.slidesharecdn.com/ss_thumbnails/20170630dbassprnvidia-170707074715-thumbnail.jpg?width=640&height=640&fit=bounds)

















