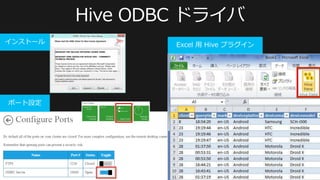
Windows Developer Daysで使ったHadoop on Windows (Server|Azure)紹介資料です。「設計・実装・活用法」というタイトルとは裏腹にただの概要紹介になってしまったので、もう少しましなものを作りたいと思っています・・・