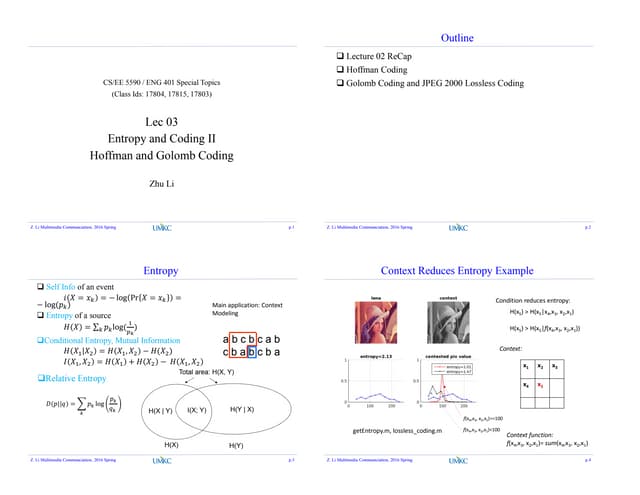
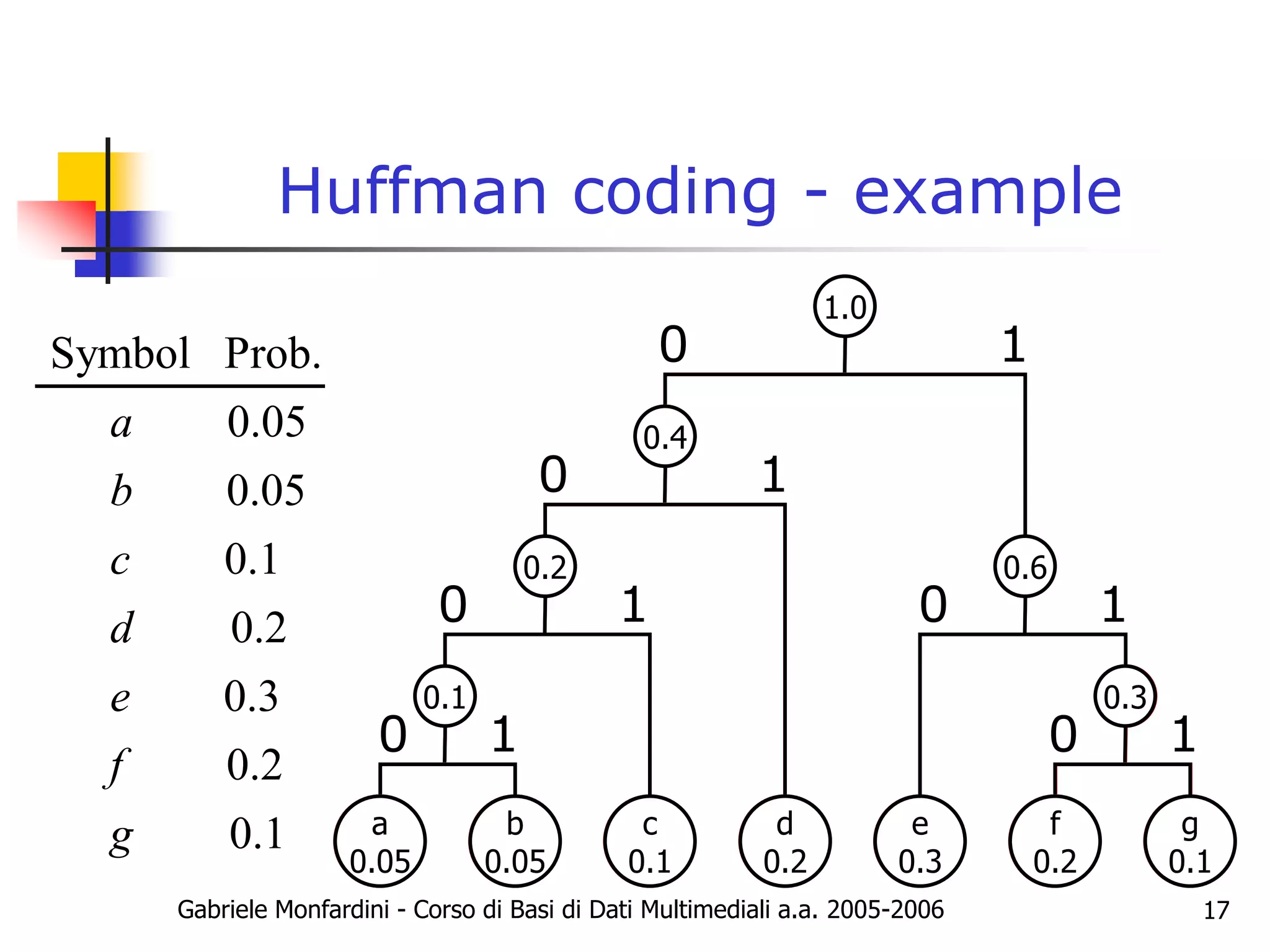
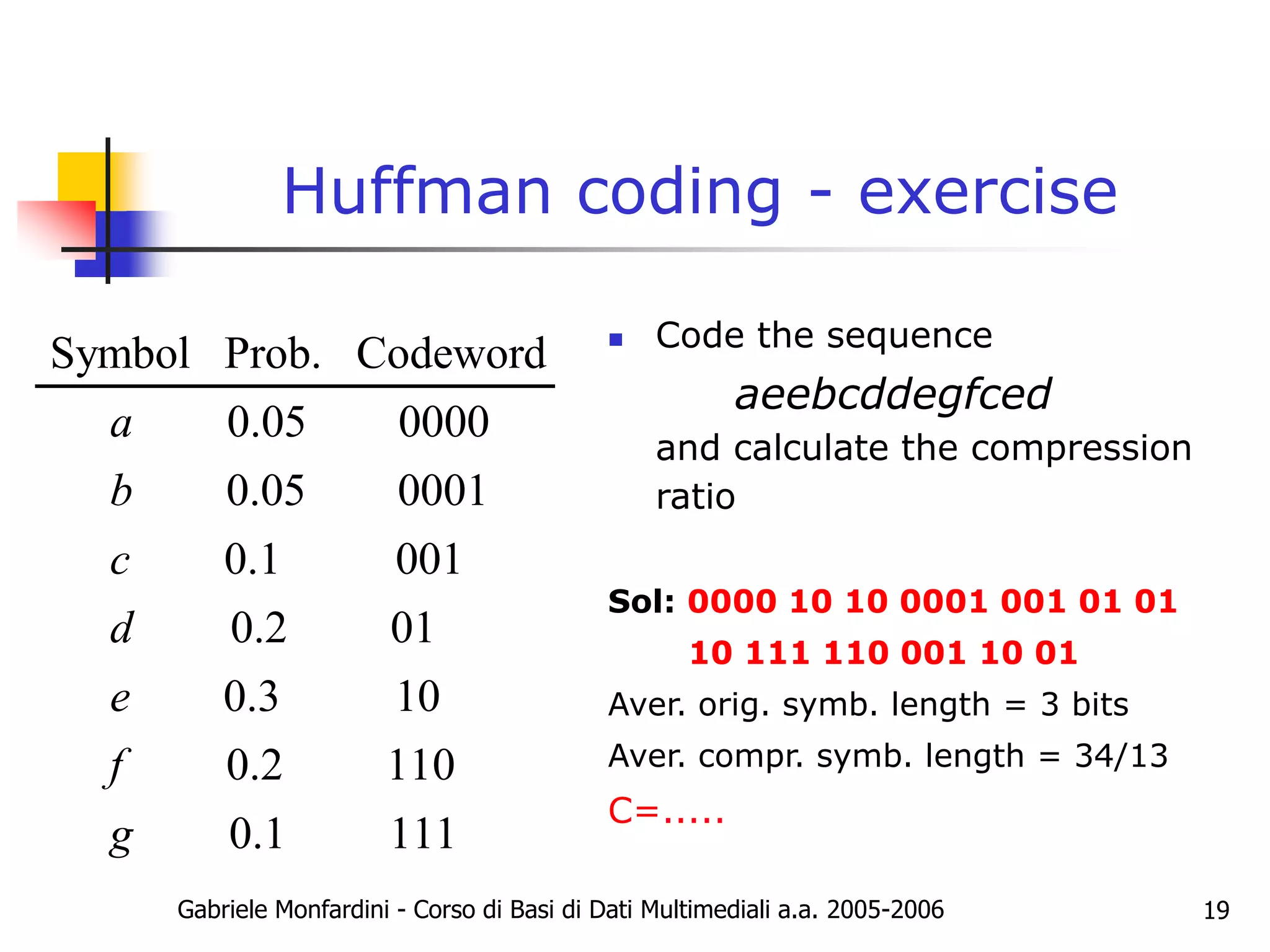
The document discusses Huffman coding and optimal codes. It explains that Huffman coding is an algorithm that constructs optimal prefix codes through a tree building process. The algorithm groups symbols by probability and assigns binary codewords based on the tree branches. This results in codewords with an average length that approaches the entropy limit, making Huffman codes optimal. The document provides examples of building Huffman trees and encoding/decoding data with the generated codes. It also discusses properties of optimal codes in general and notes that Huffman coding performs slightly better than Shannon-Fano coding.































![34
canonical Huffman coding - IV
Encoding. Suppose there are n disctinct symbols, that for symbol
i we have calculated huffman codelength and
i
l i
i l maxlength
for 1 to { [ ] 0; }
for 1 to { [ ] [ ] 1; }
[ ] 0;
for 1 downto 1 {
[ ] ( [ 1] [ 1])/ 2 ; }
for 1 to
i i
k maxlength numl k
i n numl l numl l
firstcode maxlength
k maxlength
firstcode k firstcode k numl k
k maxlength
{ [ ]= [ ]; }
for 1 to {
[ ] [ ];
, [ ]- [ ] ;
[ ] [ ] 1; }
i
i i i
i i
nextcode k firstcode k
i n
codeword i nextcode l
symbol l nextcode l firstcode l i
nextcode l nextcode l
numl[k] = number of
codewords with length k
firstcode[k] =
integer for first code of
length k
nextcode[k] =
integer for the next
codeword of length k to
be assigned
symbol[-,-] used for
decoding
codeword[i] the
rightmost bits of this
integer are the code for
symbol i
i
l](https://image.slidesharecdn.com/huffmancoding-230529115650-be4a9891/75/Huffman-coding-ppt-34-2048.jpg)
![35
canonical Huffman - example
1. Evaluate array numl
Symb. length
2
5
5
3
2
5
5
2
i
i l
a
b
c
d
e
f
g
h
: [0 3 1 0 4]
numl
2. Evaluate array firstcode
: [2 1 1 2 0]
firstcode
3. Construct array codeword and symbol
for 1 to {
[ ]= [ ]; }
for 1 to {
[ ] [ ];
, [ ]- [ ] ;
[ ] [ ] 1; }
i
i i i
i i
k maxlength
nextcode k firstcode k
i n
codeword i nextcode l
symbol l nextcode l firstcode l i
nextcode l nextcode l
- - - -
a e h -
d - - -
- - - -
b c f g
symbol
0 1 2 3
1
2
3
4
5
code bits
word
1 01
0 00000
1 00001
1 001
2 10
2 00010
3 00011
3 11
for 1 downto 1 {
[ ] ( [ 1]
[ 1]) / 2 ; }
k maxlength
firstcode k firstcode k
numl k
](https://image.slidesharecdn.com/huffmancoding-230529115650-be4a9891/75/Huffman-coding-ppt-35-2048.jpg)
![Gabriele Monfardini - Corso di Basi di Dati Multimediali a.a. 2005-2006 36
canonical Huffman coding - V
Decoding. We have the arrays firstcode and symbols
();
1;
while [ ] {
2* ();
1; }
Return , [ ] ;
v nextinputbit
k
v firstcode k
v v nextinputbit
k k
symbol k v firstcode k
nextinputbit() function that
returns next input bit
firstcode[k] = integer for first
code of length k
symbol[k,n] returns the
symbol number n with
codelength k](https://image.slidesharecdn.com/huffmancoding-230529115650-be4a9891/75/Huffman-coding-ppt-36-2048.jpg)
![37
canonical Huffman - example
();
1;
while [ ] {
2* ();
1; }
Return , [ ] ;
v nextinputbit
k
v firstcode k
v v nextinputbit
k k
symbol k v firstcode k
- - - -
a e h -
d - - -
- - - -
b c f g
symbol
0 1 2 3
1
2
3
4
5
: [2 1 1 2 0]
firstcode
00 0
0 0
0 000 00
1
1 1
1 1
1
Decoded: dhebad
00 0
0 0
0 000 00
1
1 1
1 1
1
symbol[3,0] = d
symbol[2,2] = h
symbol[2,1] = e
symbol[5,0] = b
symbol[2,0] = a
symbol[3,0] = d
symbol[3,0] = d
symbol[2,2] = h
symbol[2,1] = e
symbol[5,0] = b
symbol[2,0] = a
symbol[3,0] = d](https://image.slidesharecdn.com/huffmancoding-230529115650-be4a9891/75/Huffman-coding-ppt-37-2048.jpg)