Download to read offline


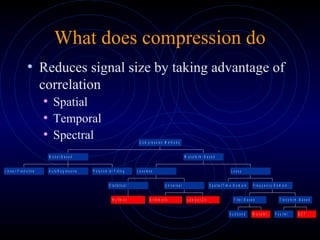














This document discusses various methods of data compression. It begins by stating the goals of understanding how media such as images, audio and video are compressed to reduce file sizes and increase transmission efficiency. It then describes different types of correlations exploited in compression, such as spatial, temporal and spectral. The remainder of the document details specific compression techniques including Huffman coding, Golomb-Rice coding, and lossless JPEG. It discusses considerations for compression method selection such as output quality, encoding/decoding delay, and whether lossy or lossless compression is required.








































































