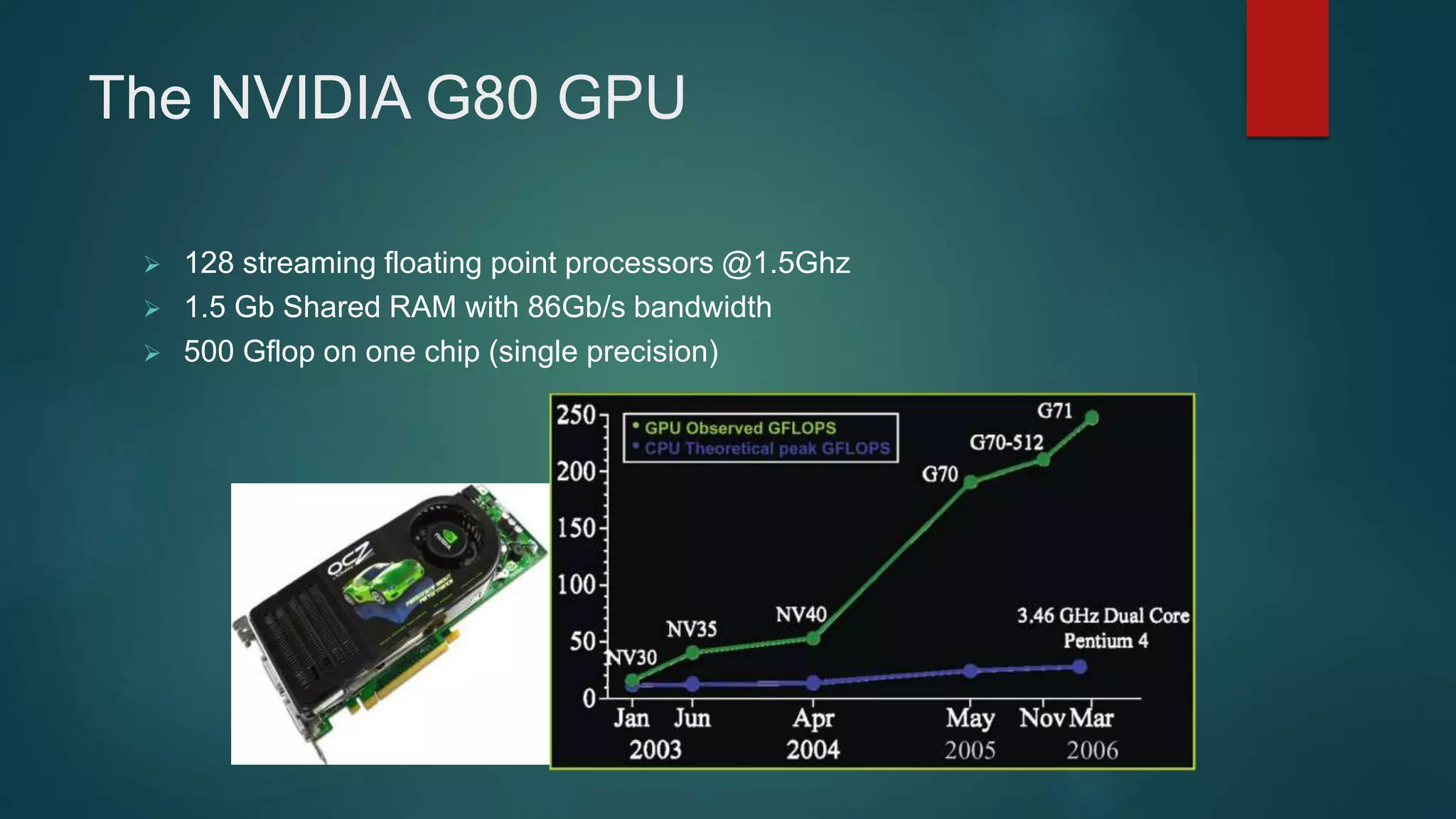
This document discusses GPU architecture and functioning. It defines a GPU as a processor optimized for graphics, video and visual computing. GPUs are highly parallel and multithreaded. The document outlines the evolution of GPUs from specialized graphics cards to massively parallel processors capable of general purpose computing. It describes the GPU pipeline including host interface, vertex processing, triangle setup, fragment processing and memory interface. It also discusses programming models like CUDA and differences between CPUs and GPUs.