Downloaded 20 times



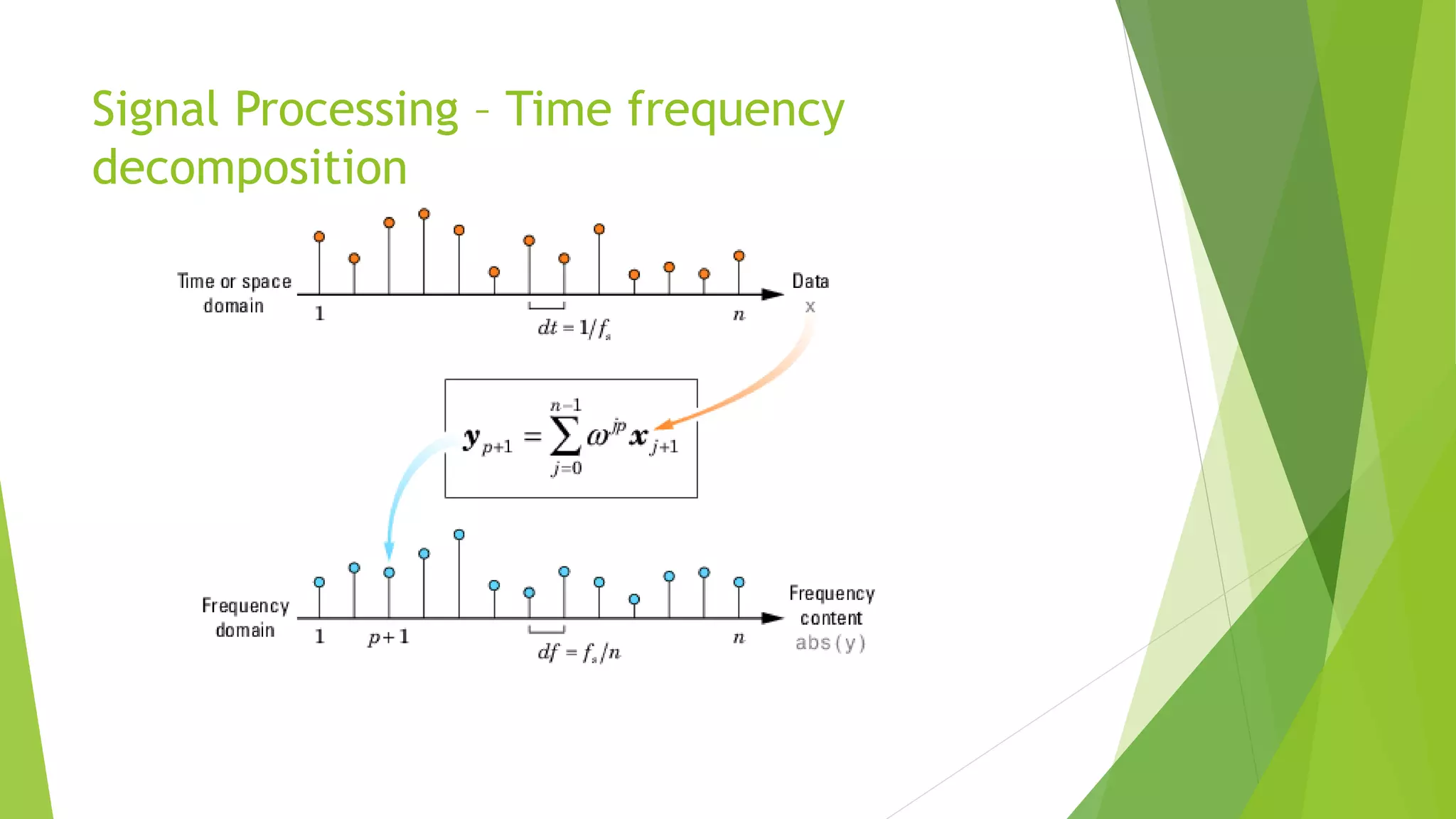





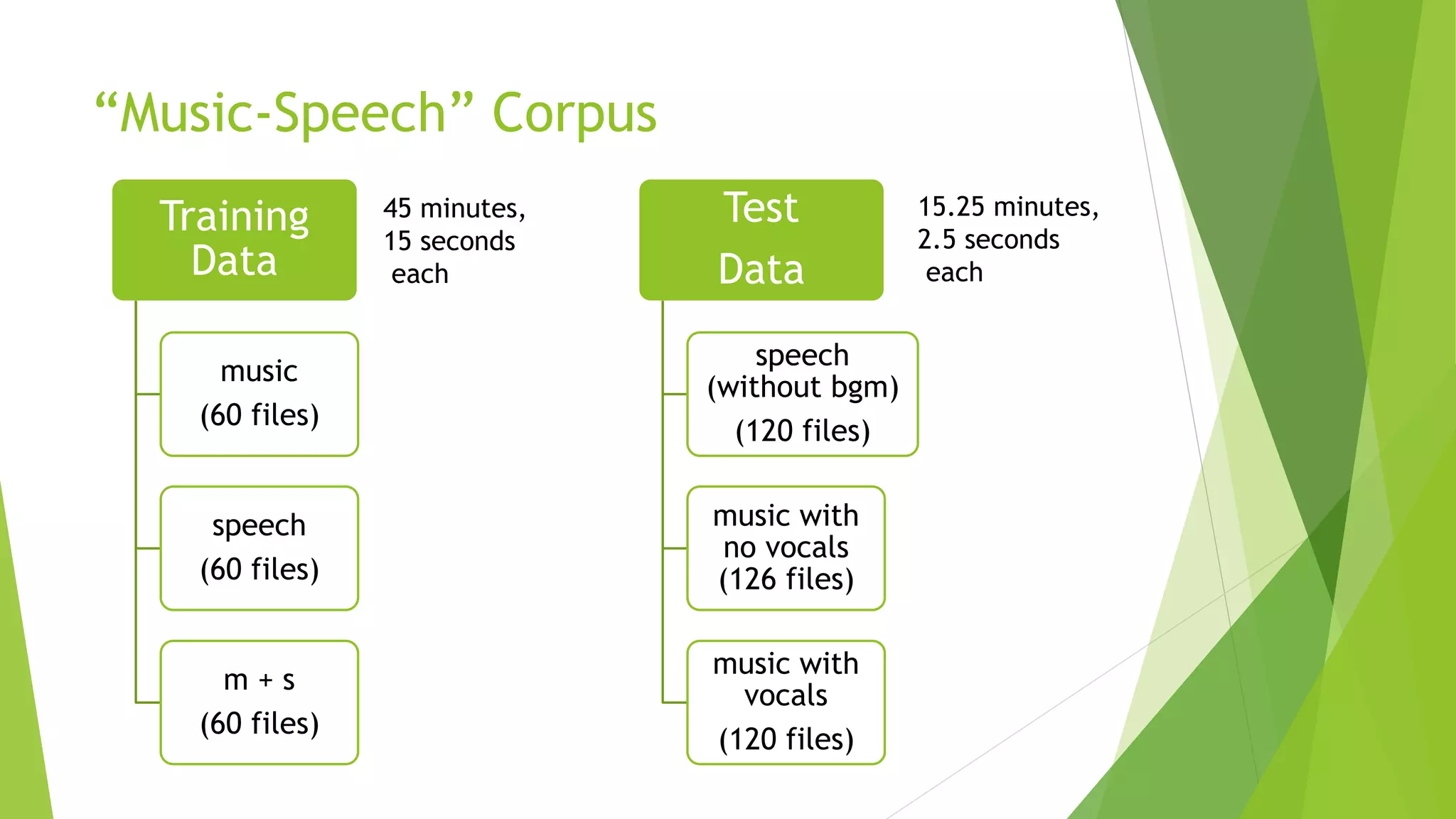
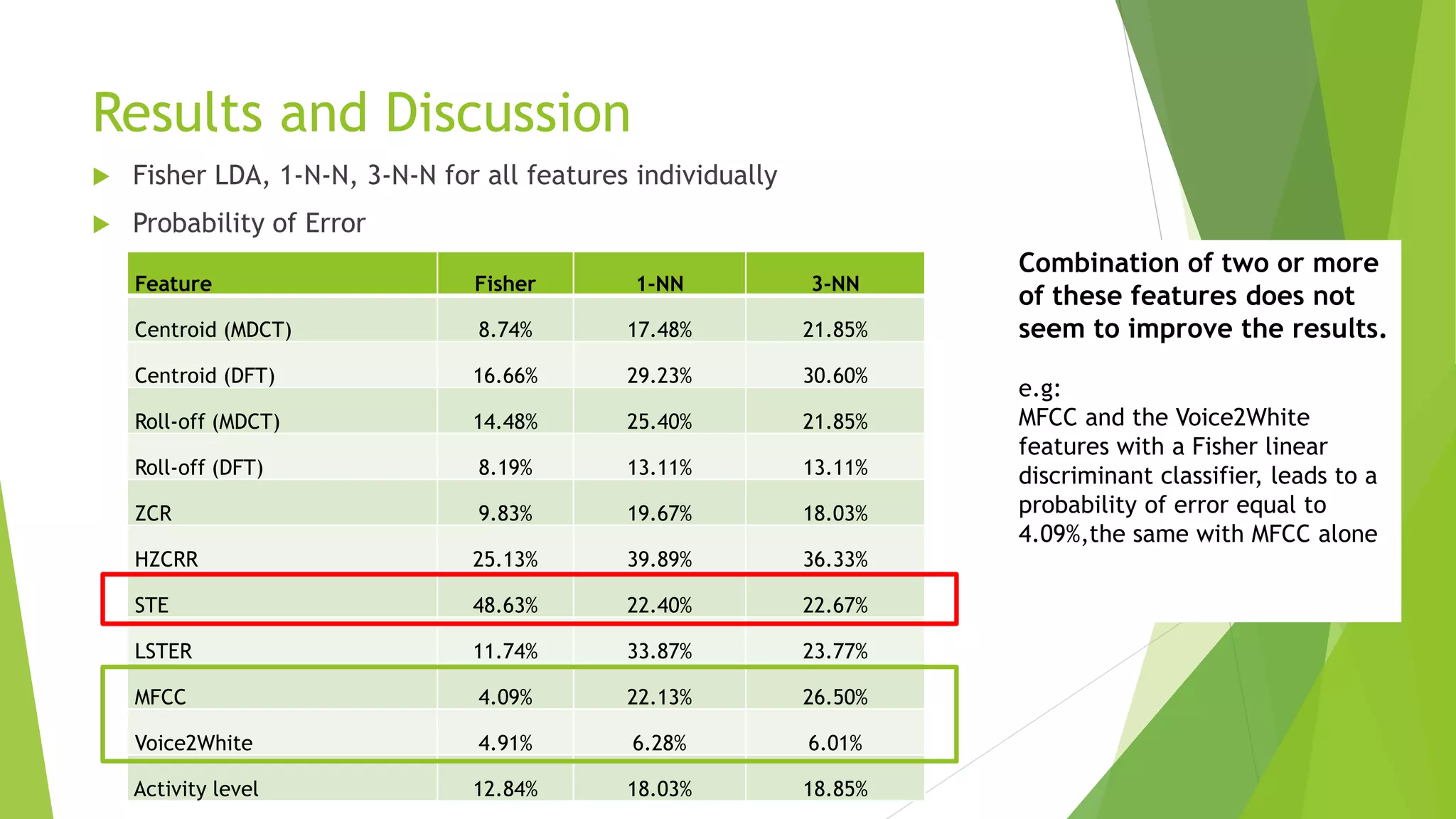
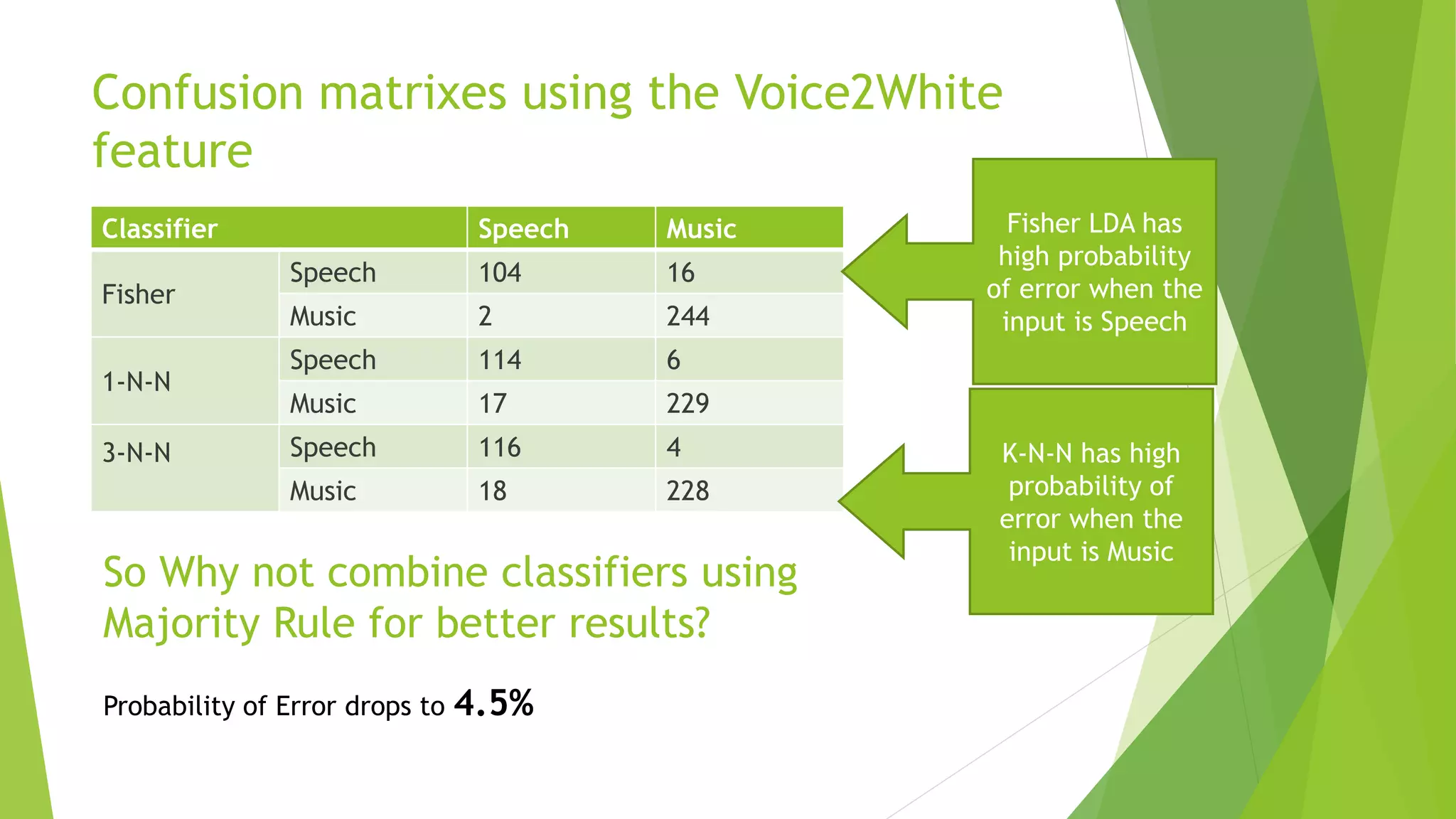



This document describes research applying Fisher Linear Discriminant Analysis (LDA) and K-Nearest Neighbors (K-NN) algorithms to classify speech and music audio clips. It finds that Fisher LDA using single features like mel-frequency cepstral coefficients achieves classification error rates below 5%, outperforming K-NN. While combining multiple features does not improve LDA results, combining the outputs of LDA and K-NN classifiers using majority voting further lowers the error rate to 4.5%, demonstrating the benefit of classifier ensembles for this task.





































































![Vibe Coding vs. Spec-Driven Development [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/vibecodingvsspecdrivendevelopment-251209105622-43f455e7-thumbnail.jpg?width=640&height=640&fit=bounds)
















