Downloaded 358 times








![Example: Word Count
library(SparkR)
lines
<-‐
textFile(sc,
“hdfs://my_text_file”)
words
<-‐
flatMap(lines,
function(line)
{
strsplit(line,
"
")[[1]]
})
wordCount
<-‐
lapply(words,
function(word)
{
list(word,
1L)
})
counts
<-‐
reduceByKey(wordCount,
"+",
2L)
output
<-‐
collect(counts)](https://image.slidesharecdn.com/07venkataramansun-150624021503-lva1-app6892/85/SparkR-The-Past-the-Present-and-the-Future-Shivaram-Venkataraman-and-Rui-Sun-UC-Berkeley-AMPLAB-and-Intel-13-320.jpg)


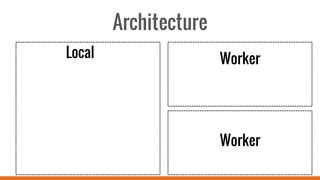
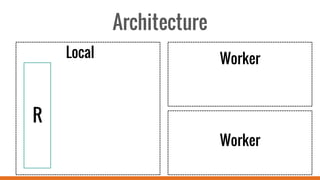
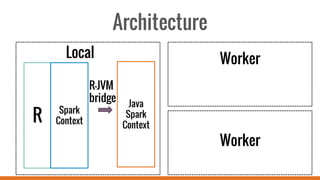
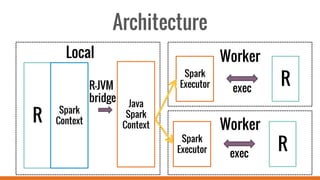
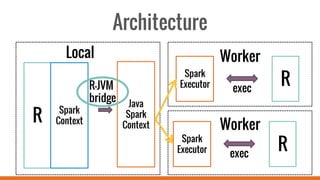

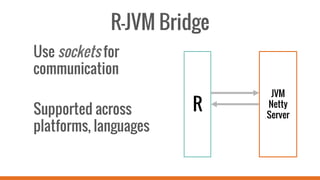

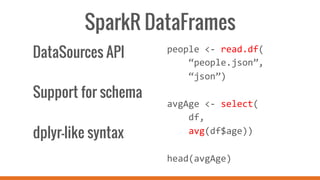
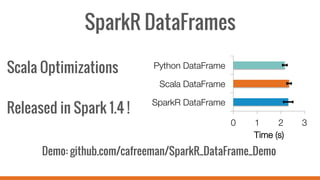










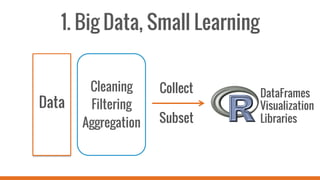
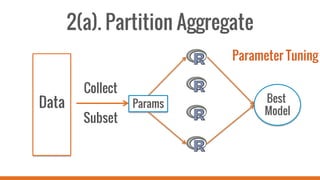
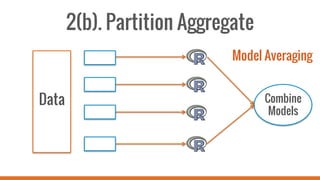
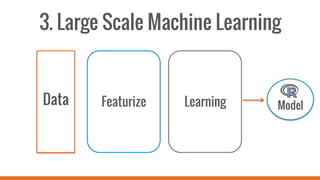
SparkR allows users to perform large-scale data analysis from R. It provides a unified approach for working with big data using DataFrames. The current release of SparkR includes DataFrame support released in Spark 1.4 for improved performance. Future developments will expand SparkR's capabilities for large-scale machine learning, simple parallel programming APIs, and tighter integration with existing R packages. The open source project has an growing community of over 20 contributors working to advance SparkR.























































































