Downloaded 190 times

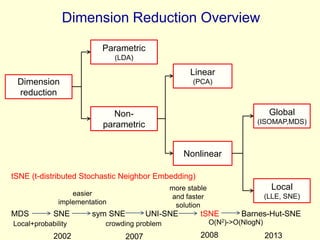







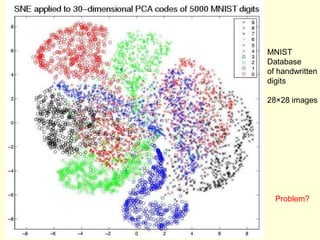
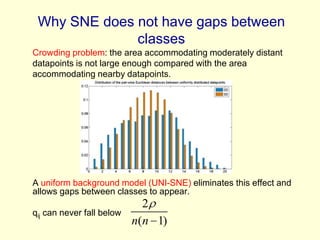
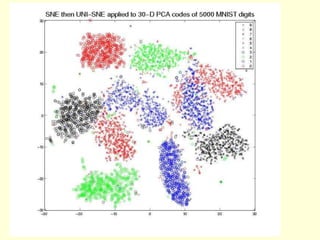

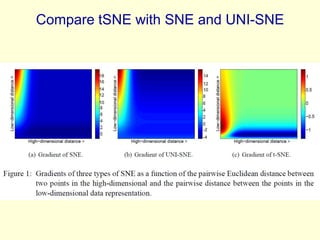


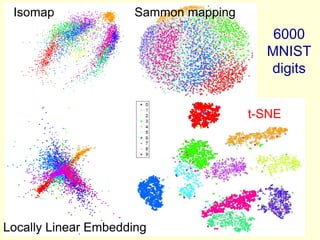




This document discusses t-Distributed Stochastic Neighbor Embedding (t-SNE), a technique for visualizing high-dimensional data. It begins by overviewing dimension reduction techniques before focusing on t-SNE. t-SNE is an improvement on Stochastic Neighbor Embedding (SNE) that converts similarities between data points to joint probabilities and minimizes the divergence between a high-dimensional and low-dimensional distribution. The document explains how t-SNE addresses issues like the "crowding problem" to better separate clusters in low dimensions. Optimization methods for t-SNE are also covered.


























































































![5G Explained! A High Level Overview [Introduction]](https://cdn.slidesharecdn.com/ss_thumbnails/5gexplainedahighleveloverview-260119165306-cc137a3e-thumbnail.jpg?width=640&height=640&fit=bounds)
















