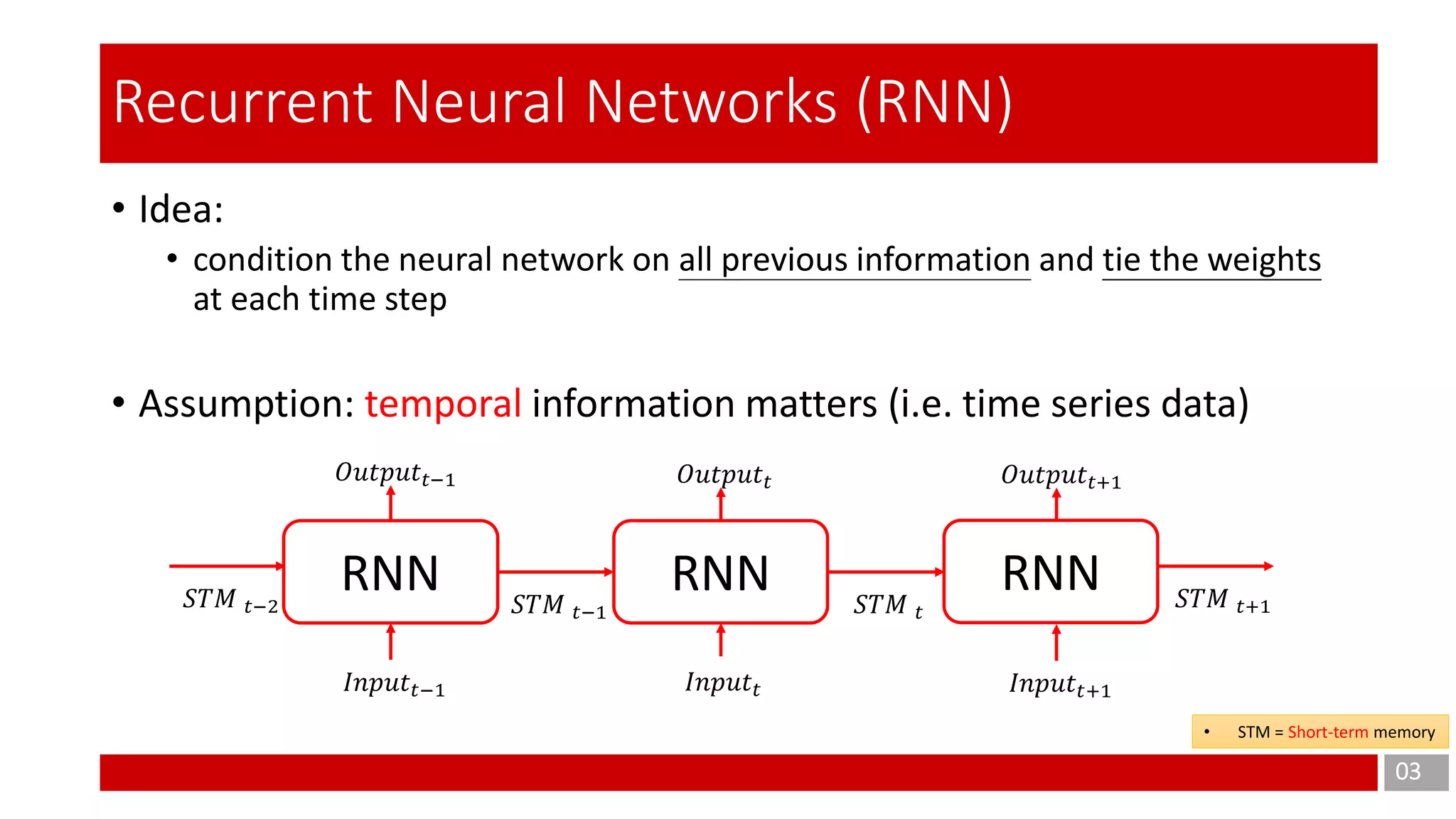
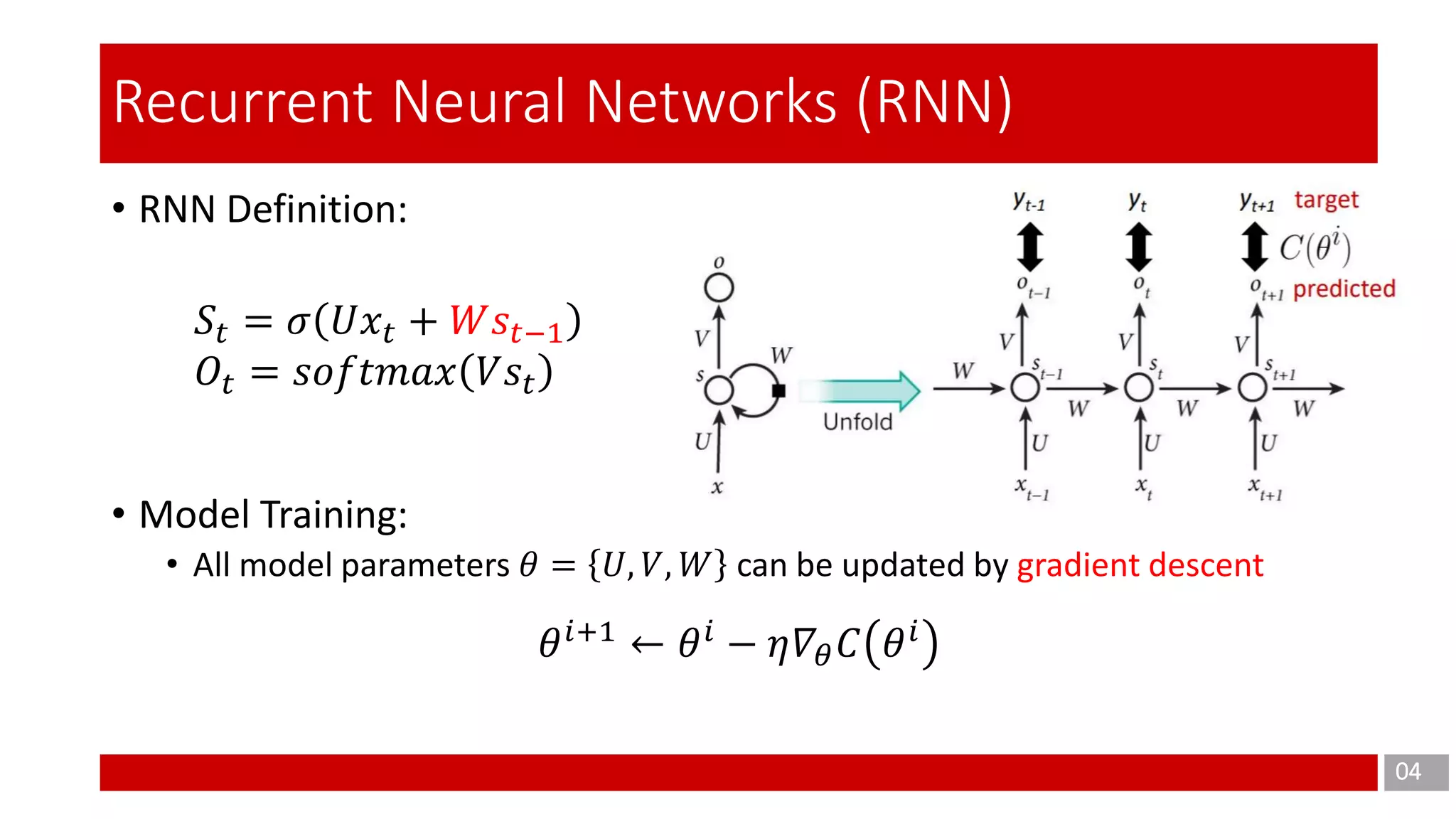
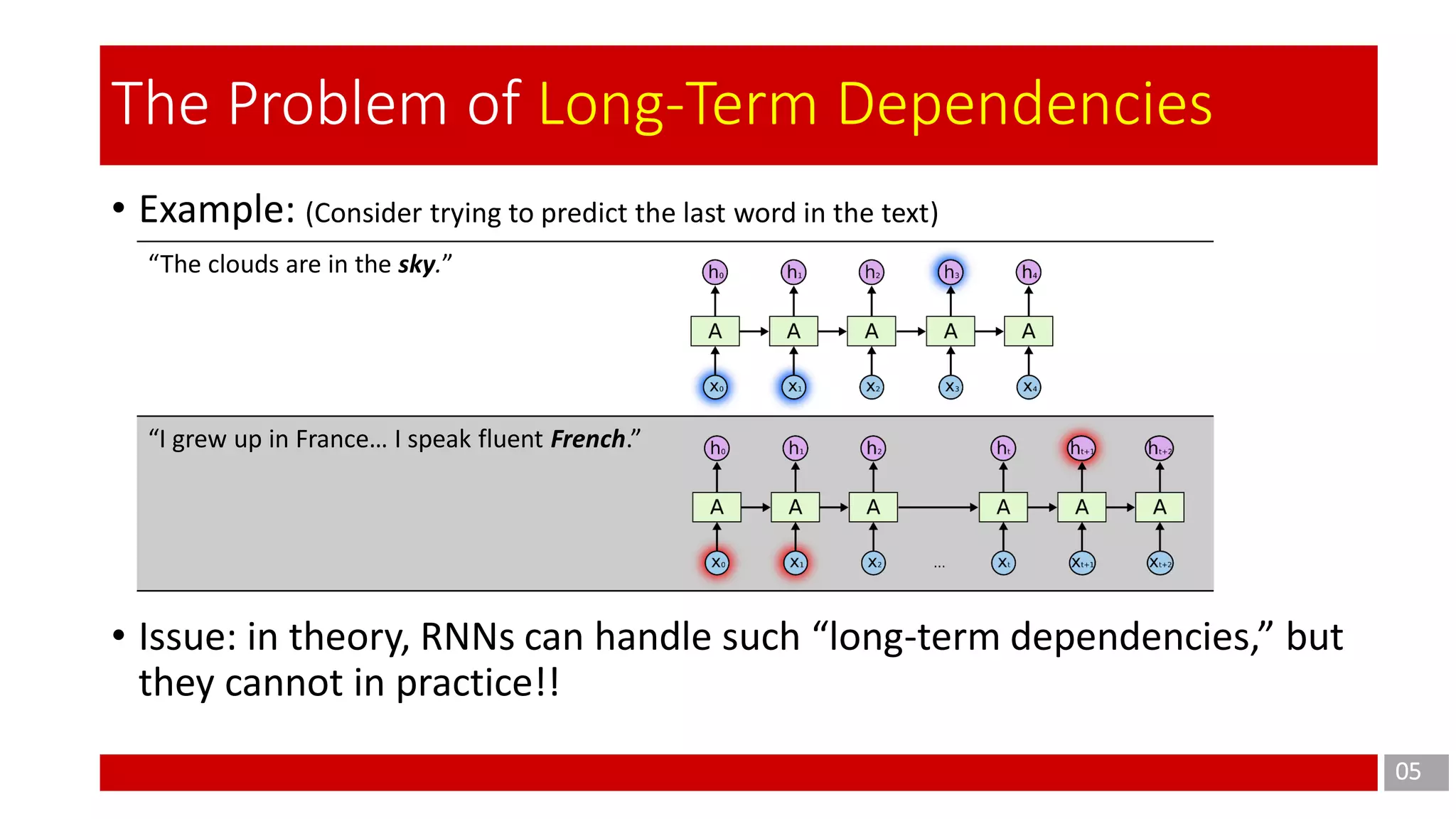
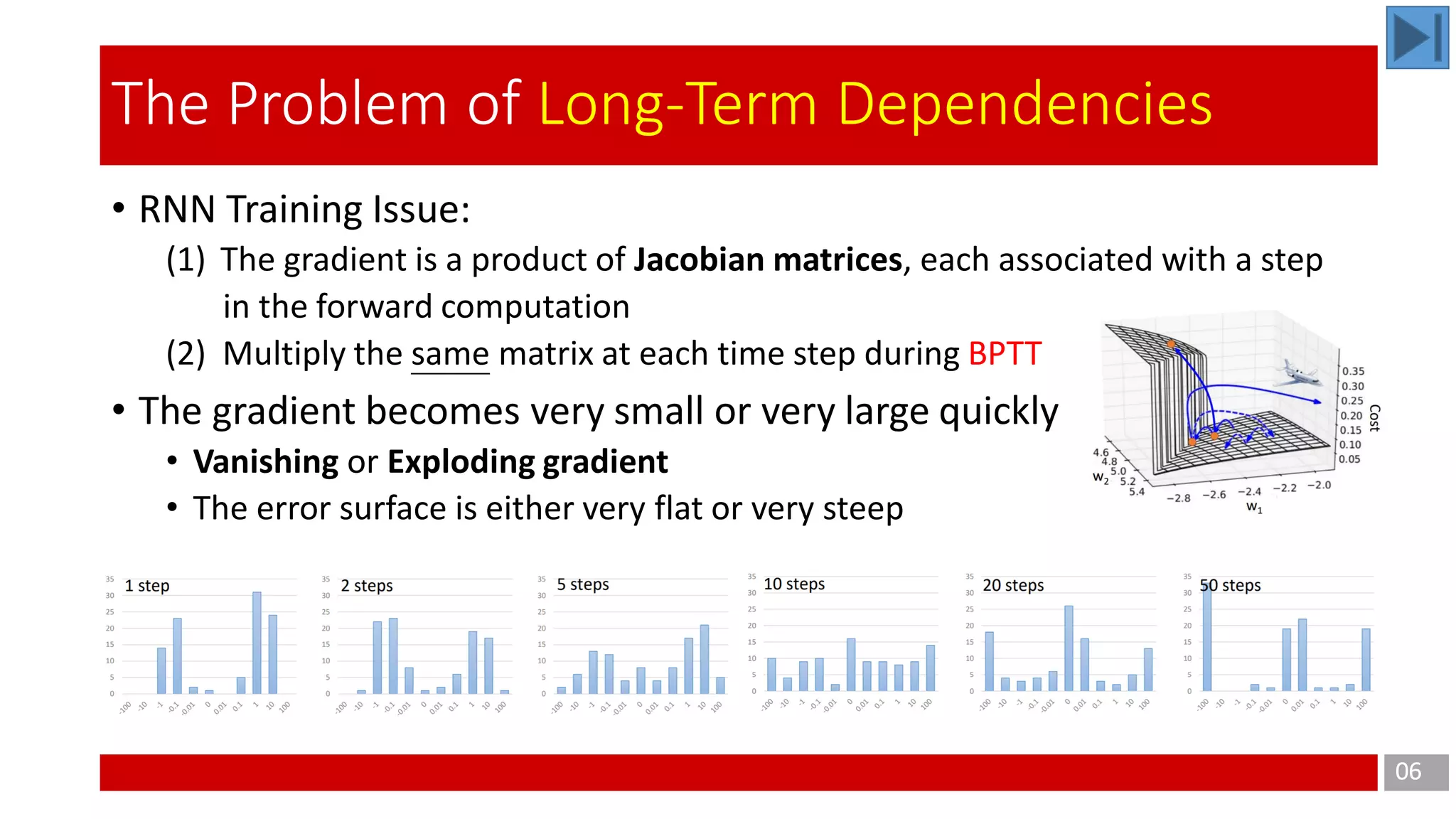
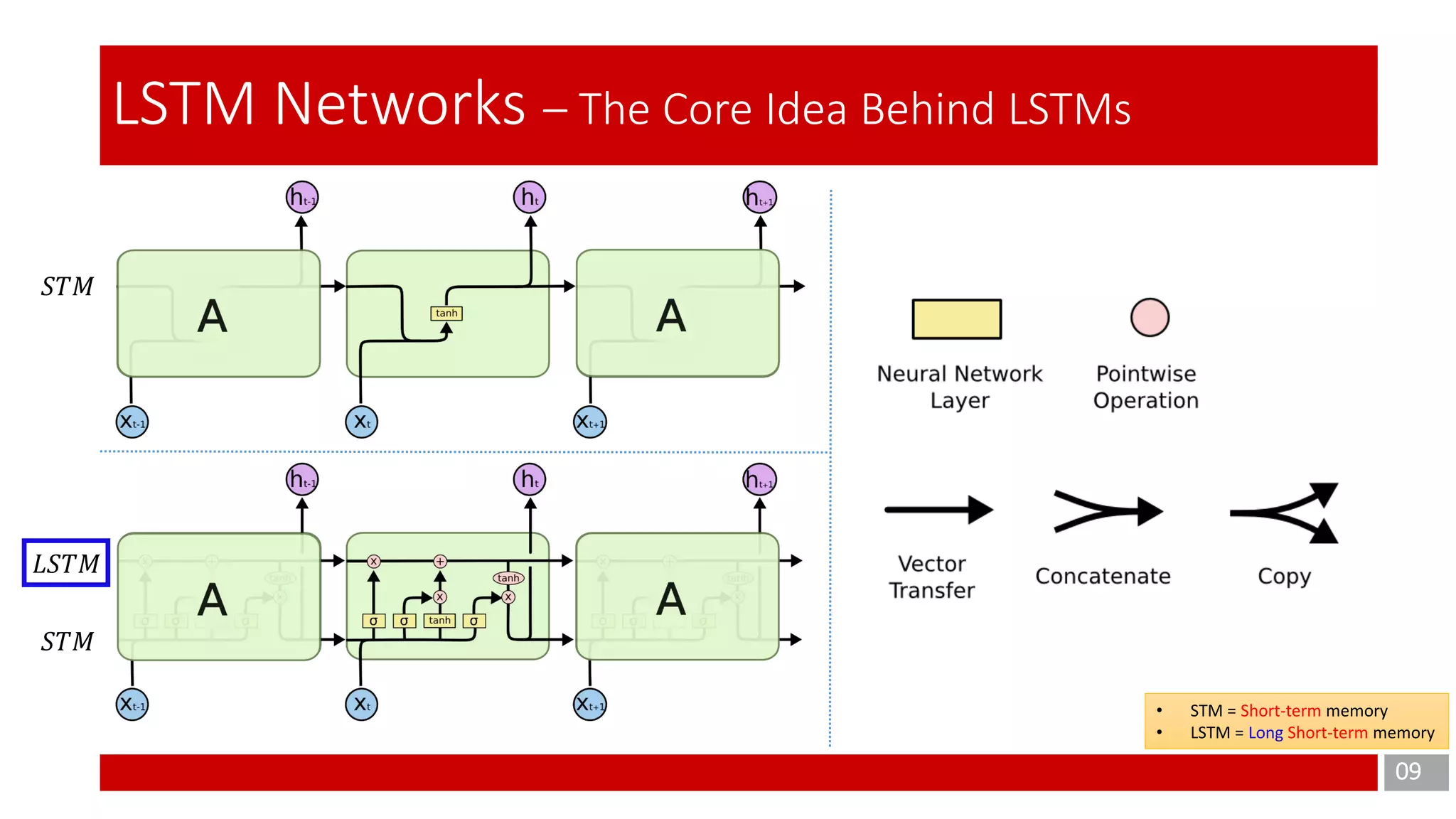
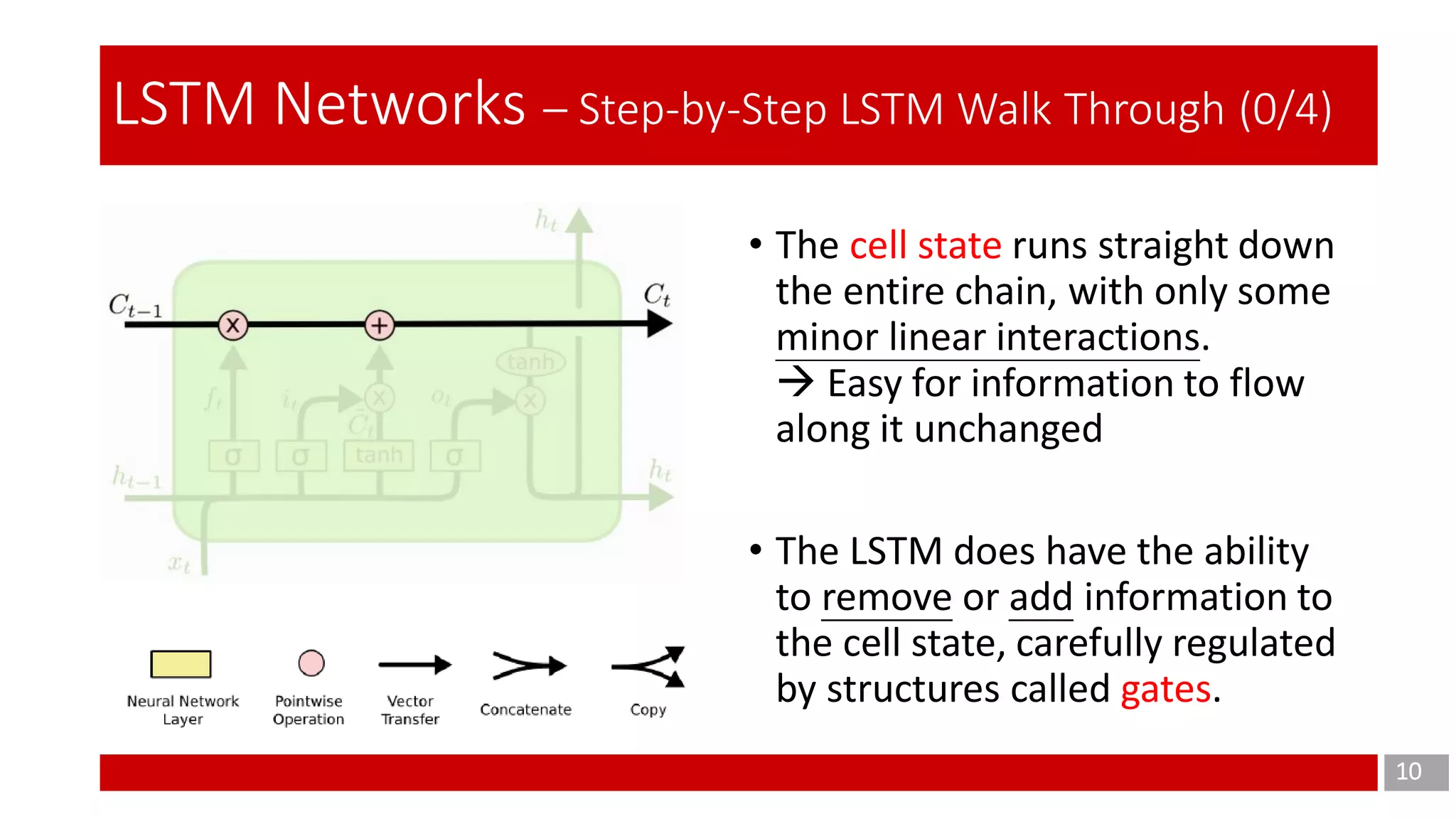
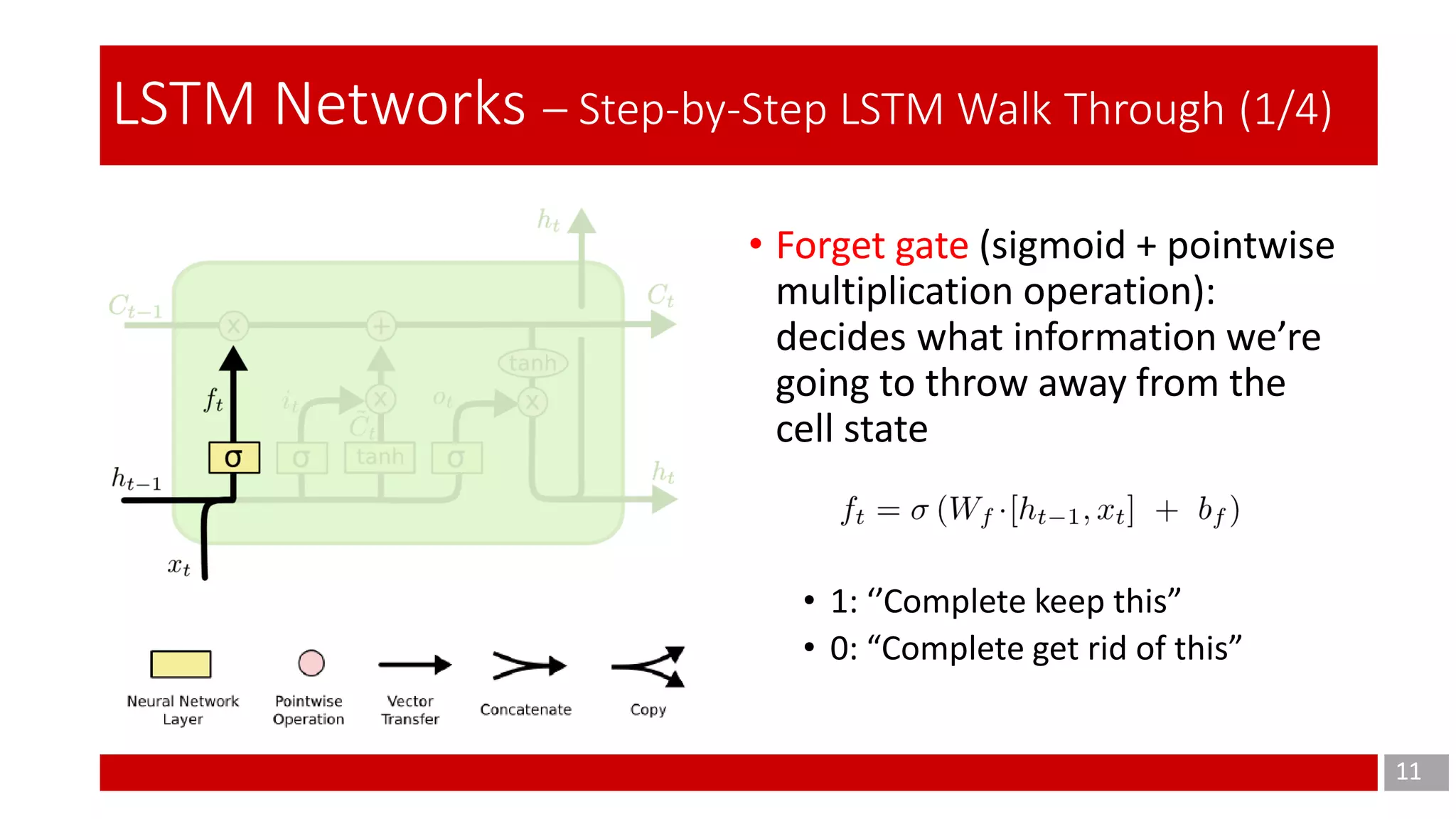
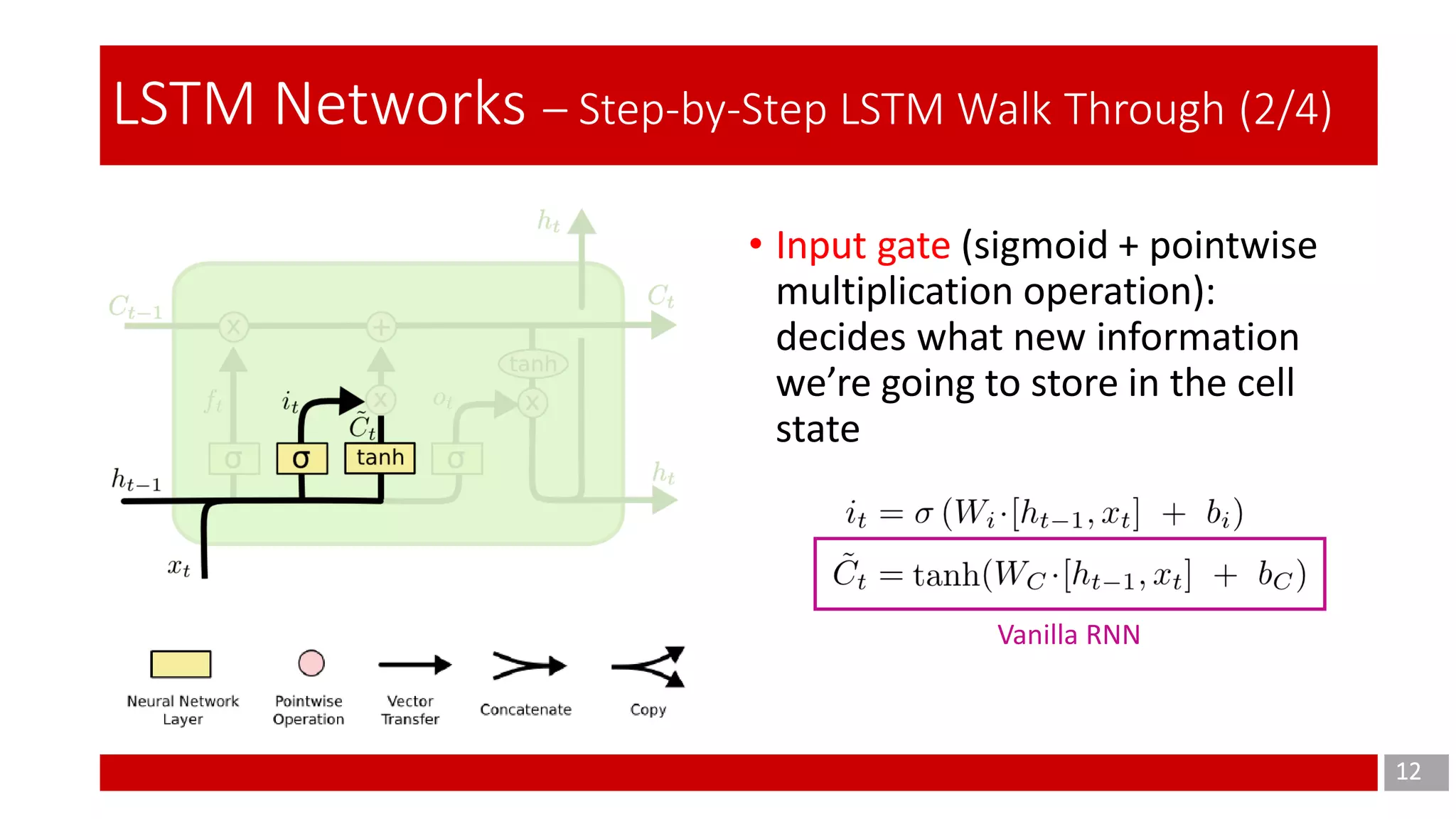
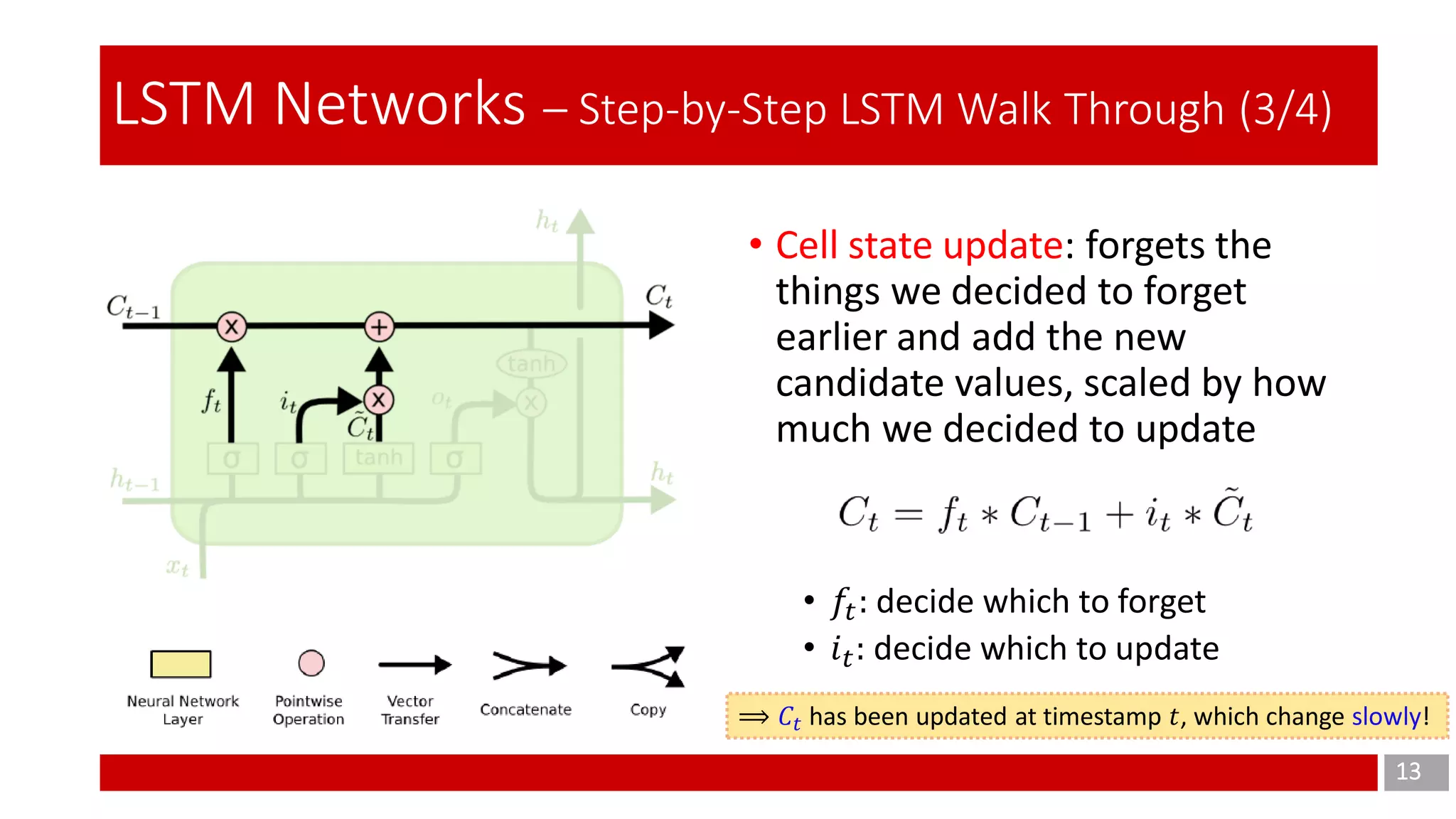
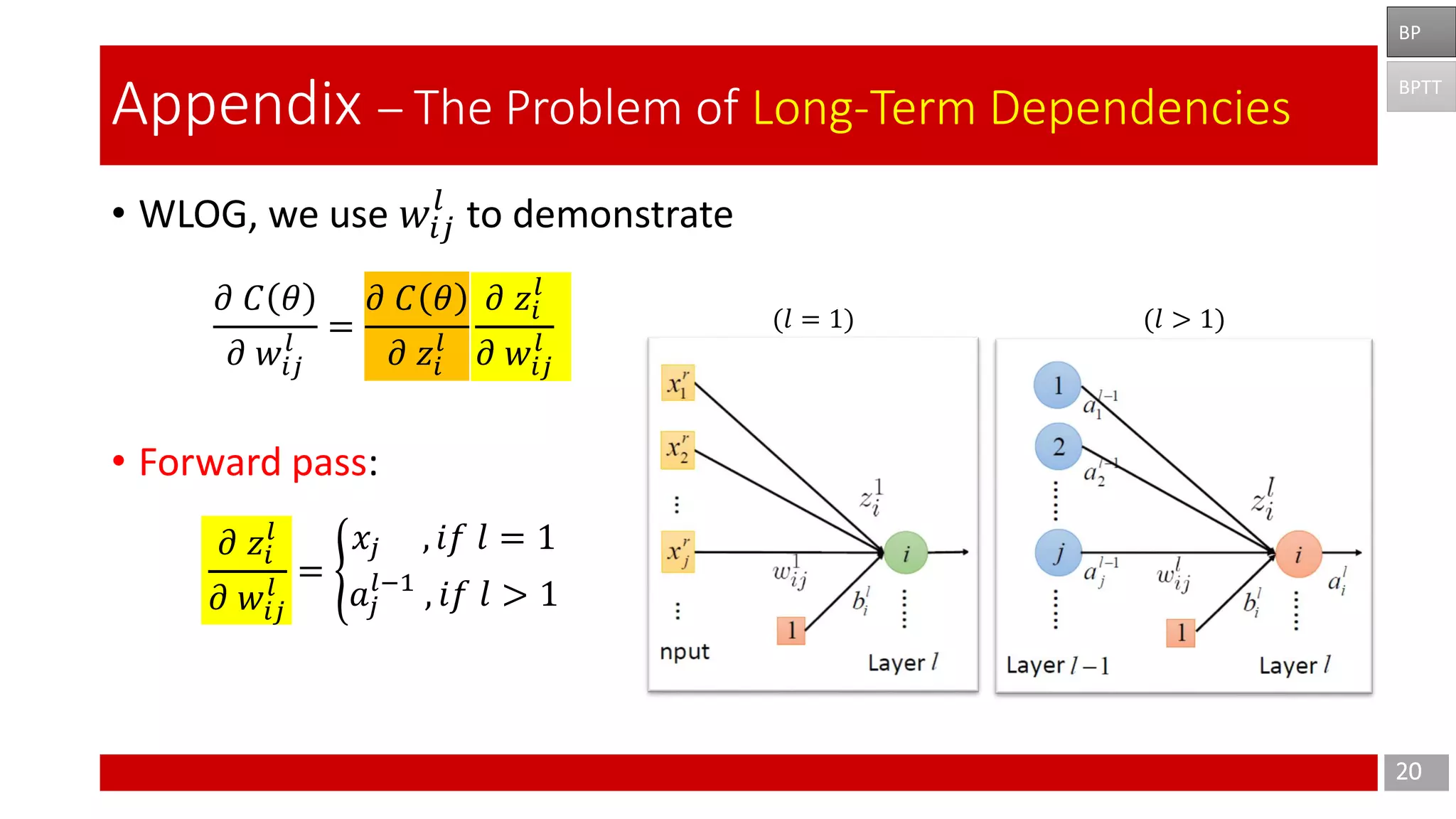
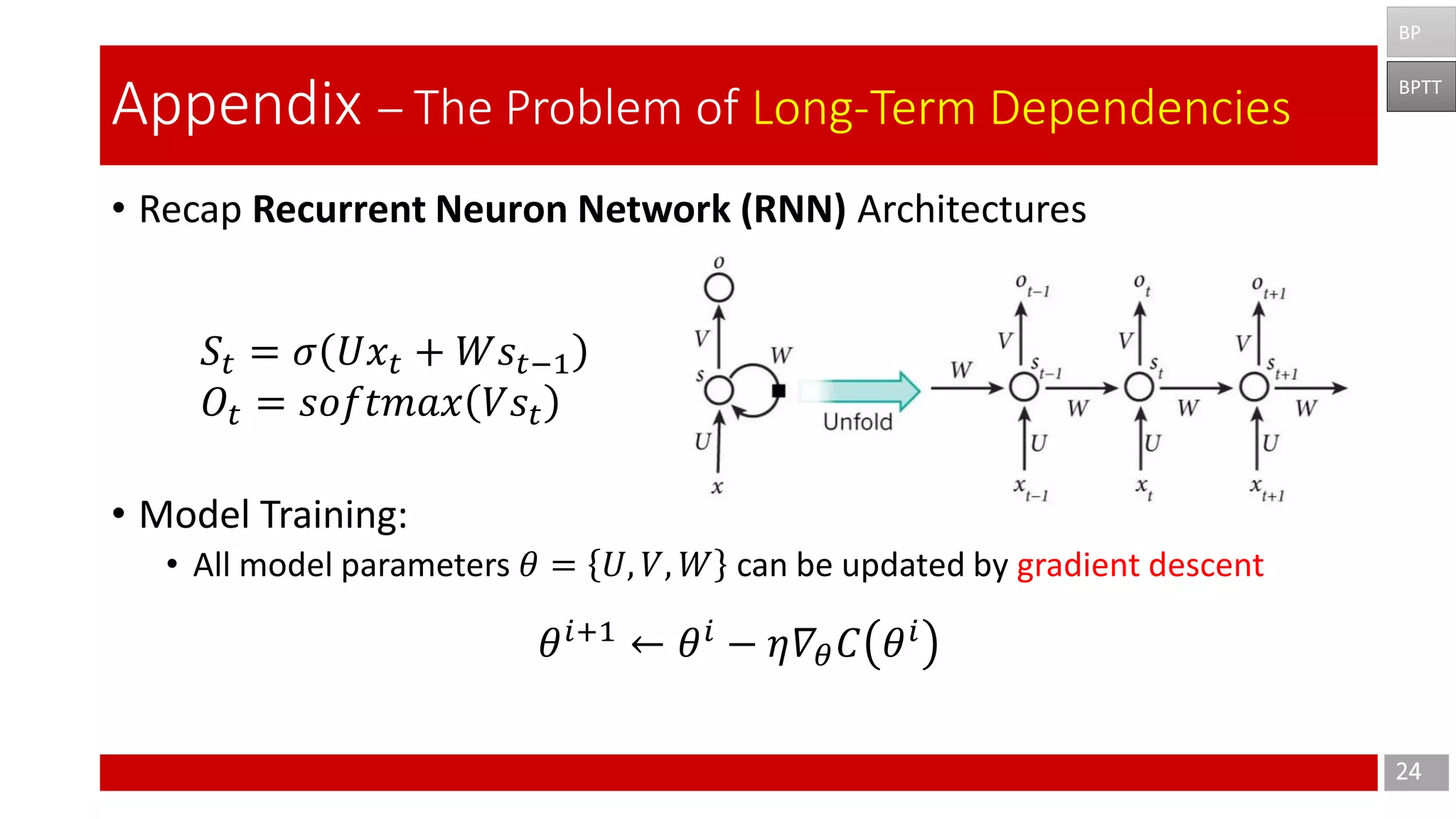
The document discusses Long Short-Term Memory (LSTM) networks, which are designed to address the shortcomings of Recurrent Neural Networks (RNNs) in learning long-term dependencies due to issues like vanishing and exploding gradients. It explains the architecture and function of LSTMs, including the use of gating mechanisms to control the flow of information, and outlines various LSTM variants such as Gated Recurrent Units (GRUs). Additionally, it touches on training methods and offers conclusions and references for further reading.