Downloaded 29 times







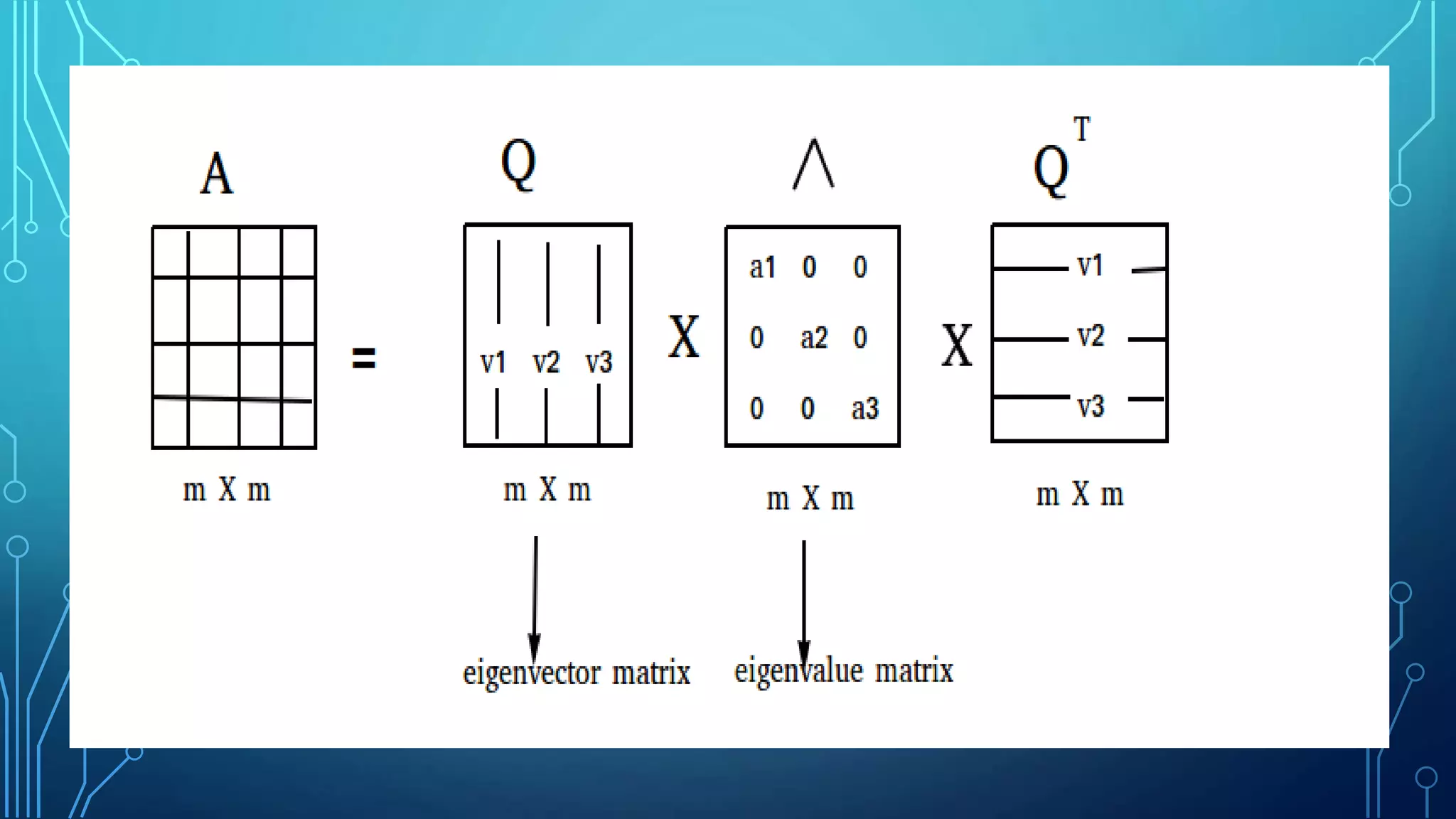

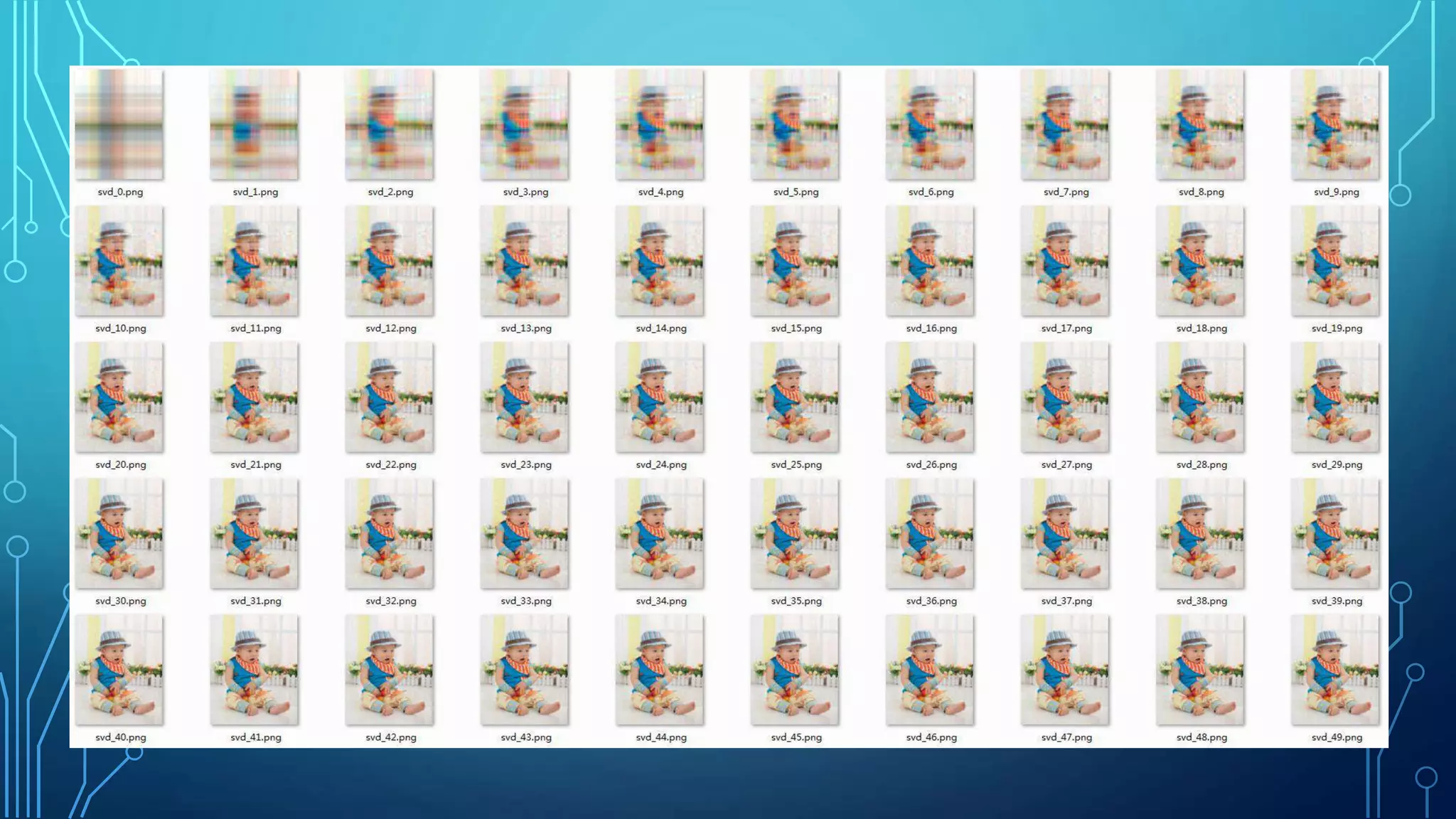
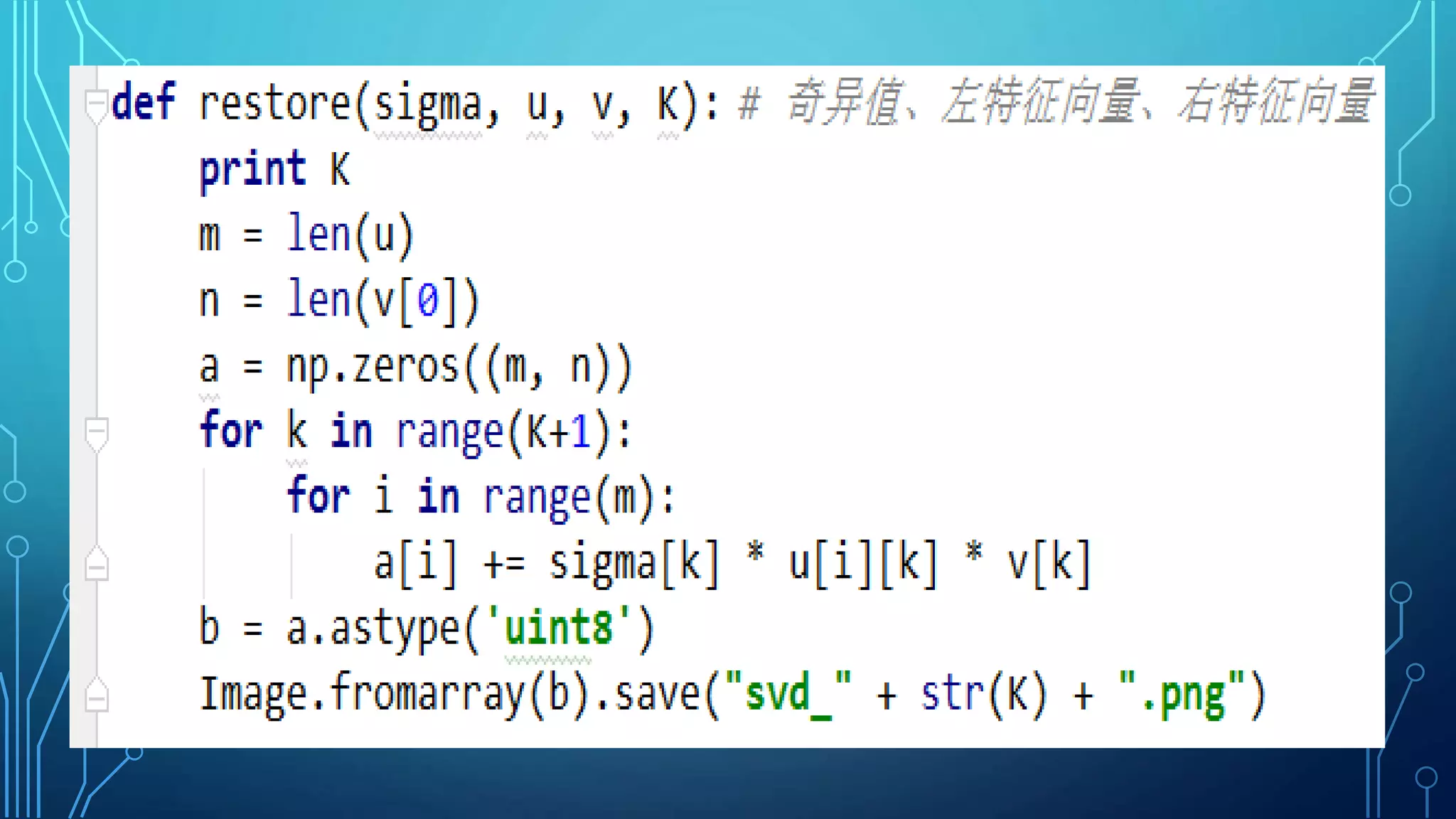




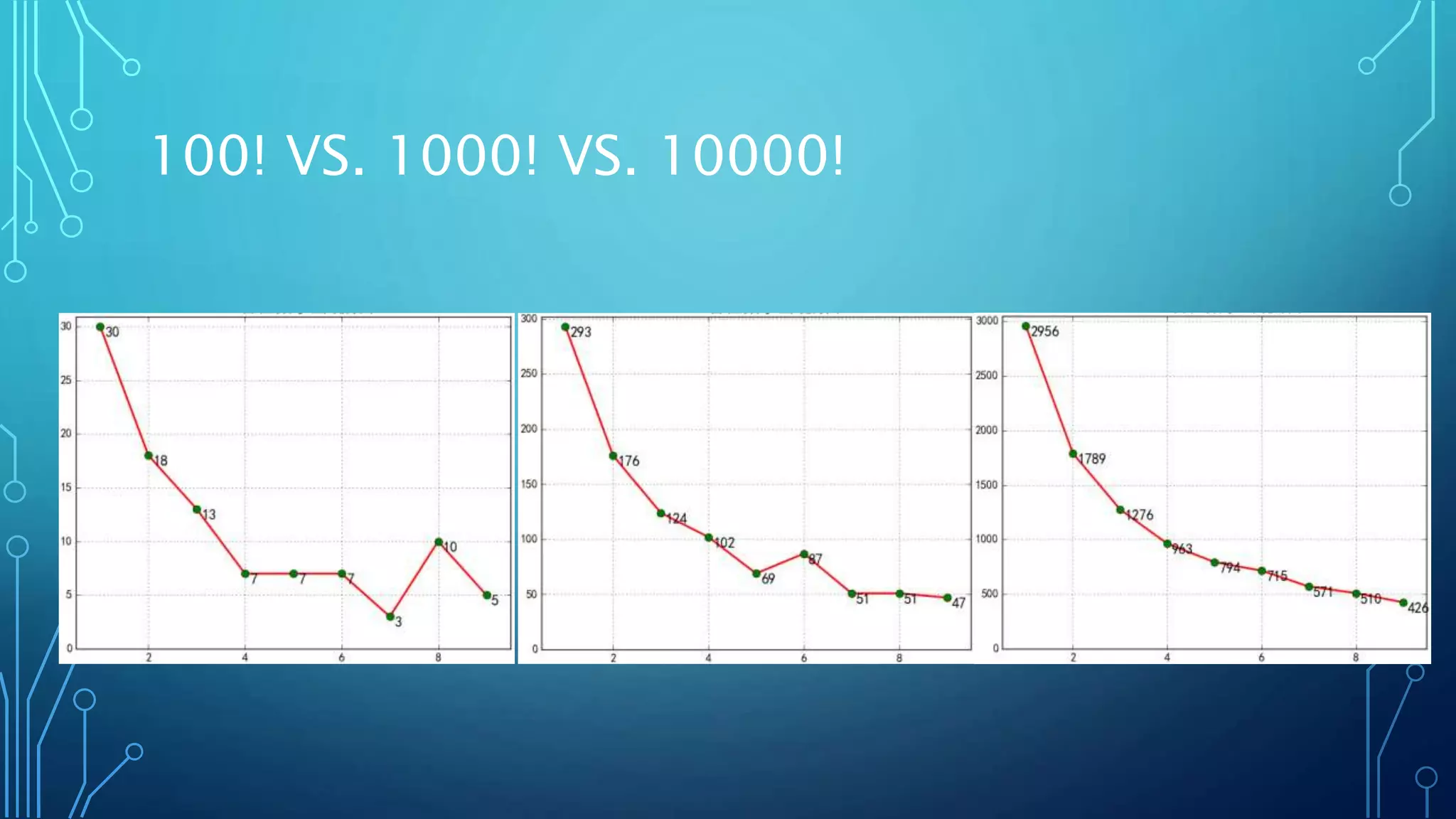




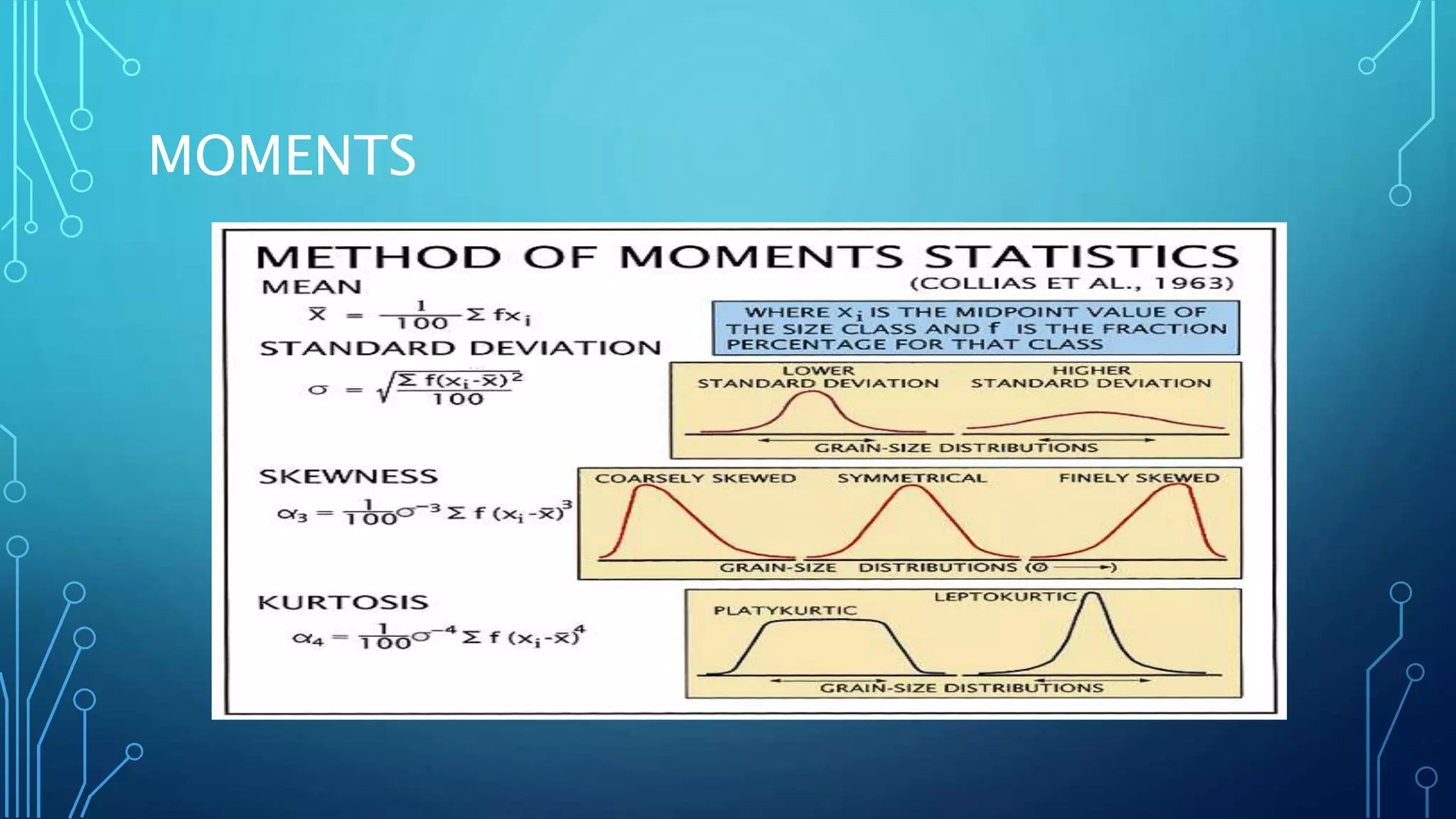
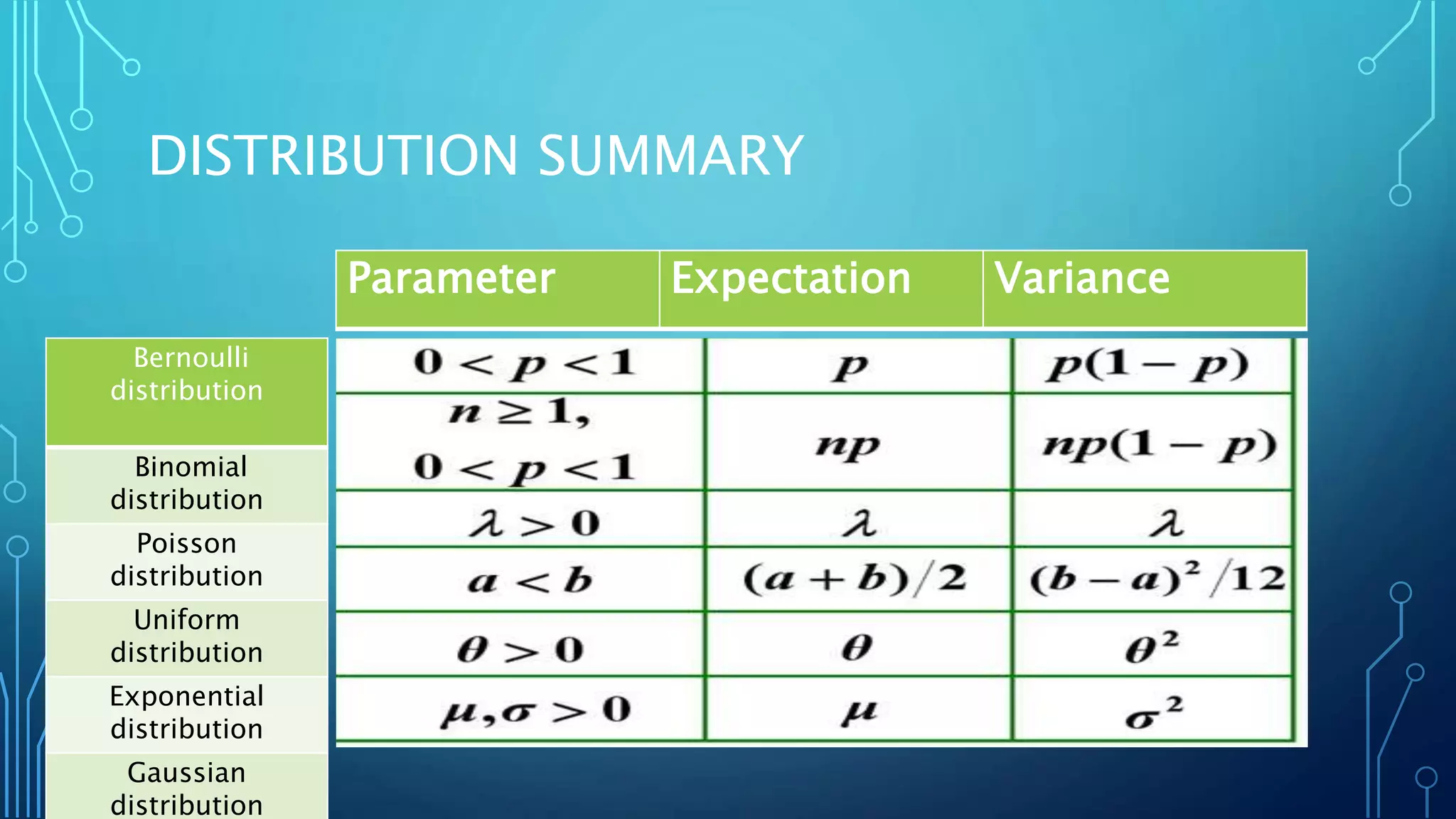




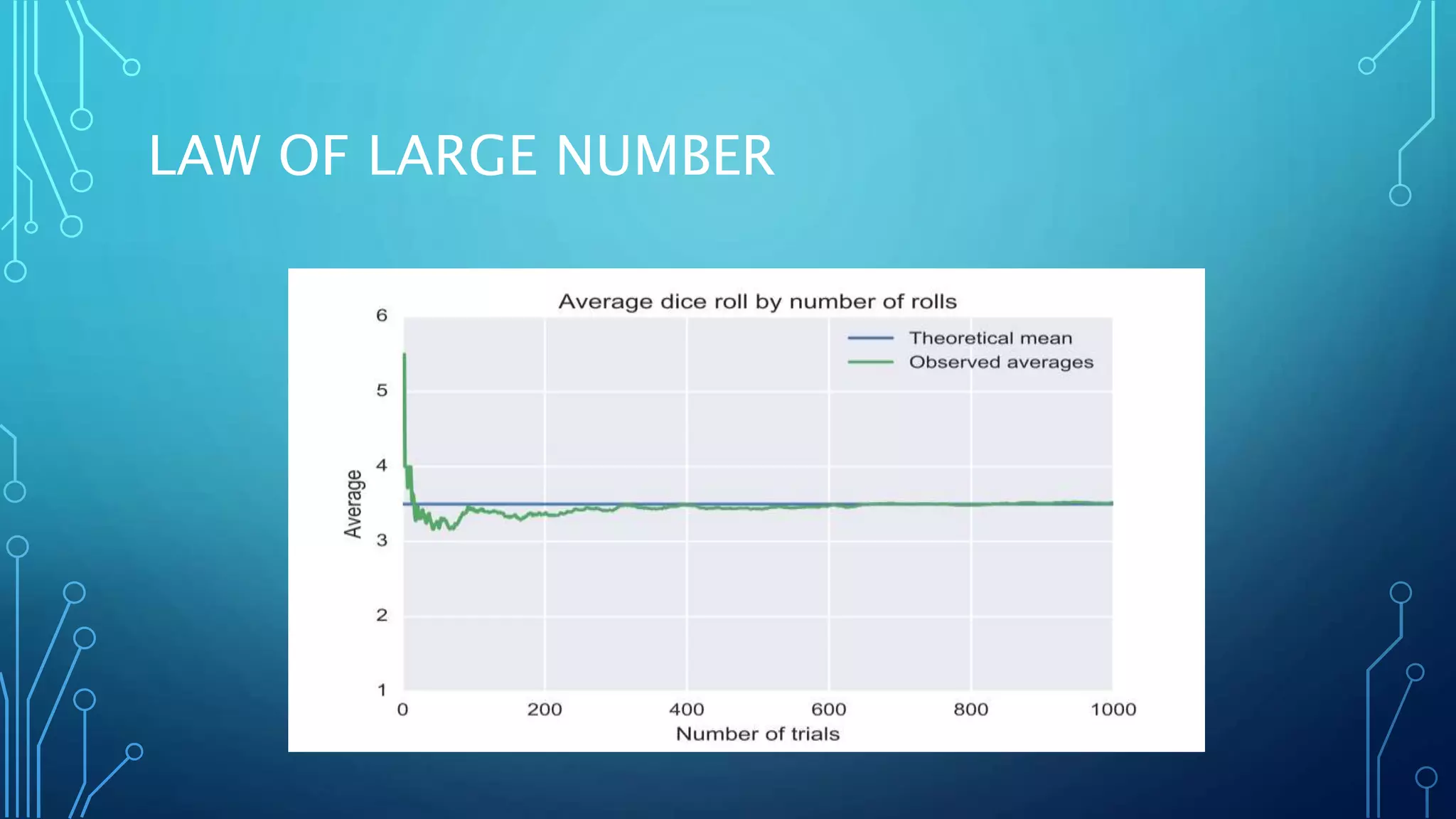
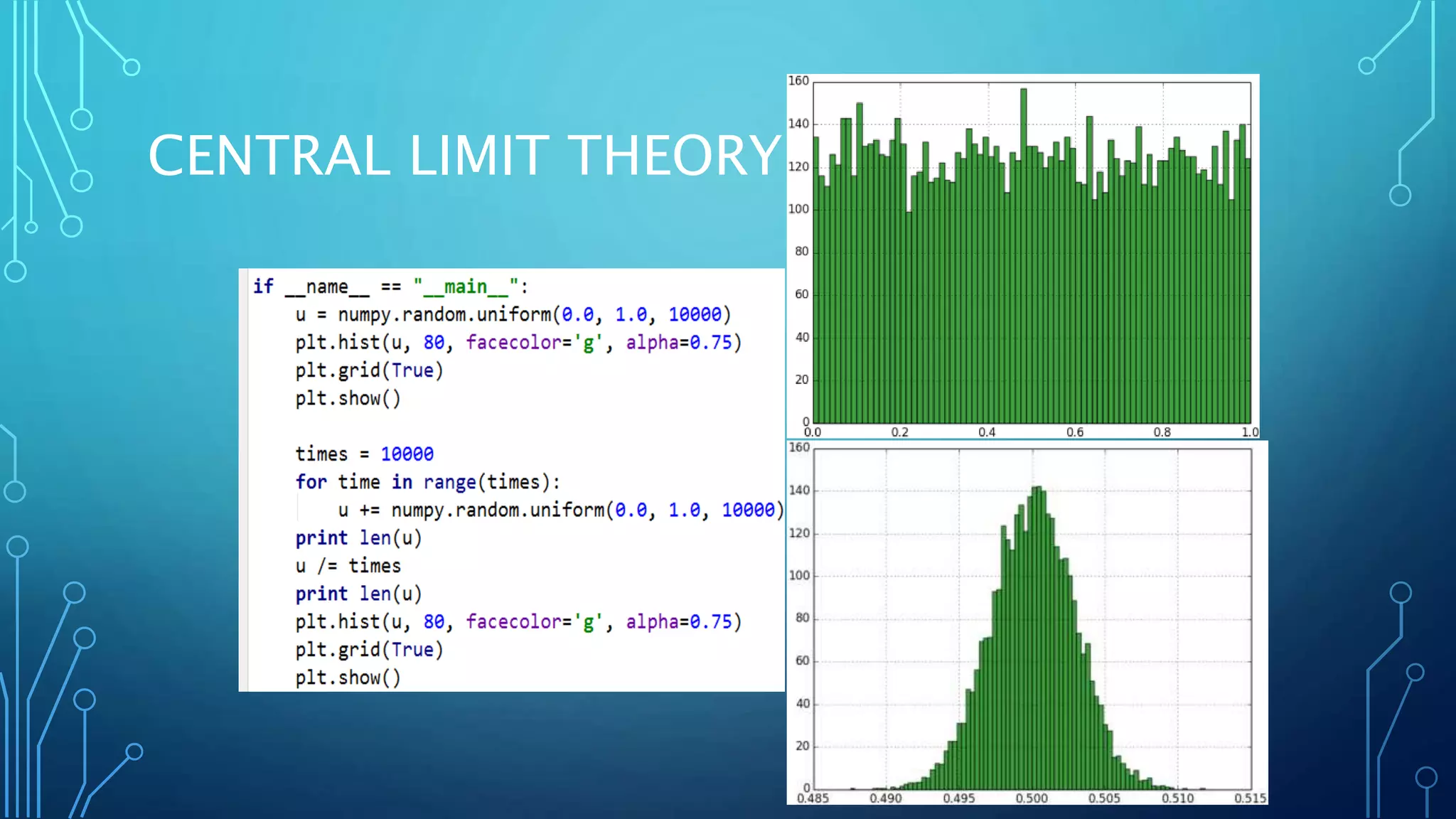





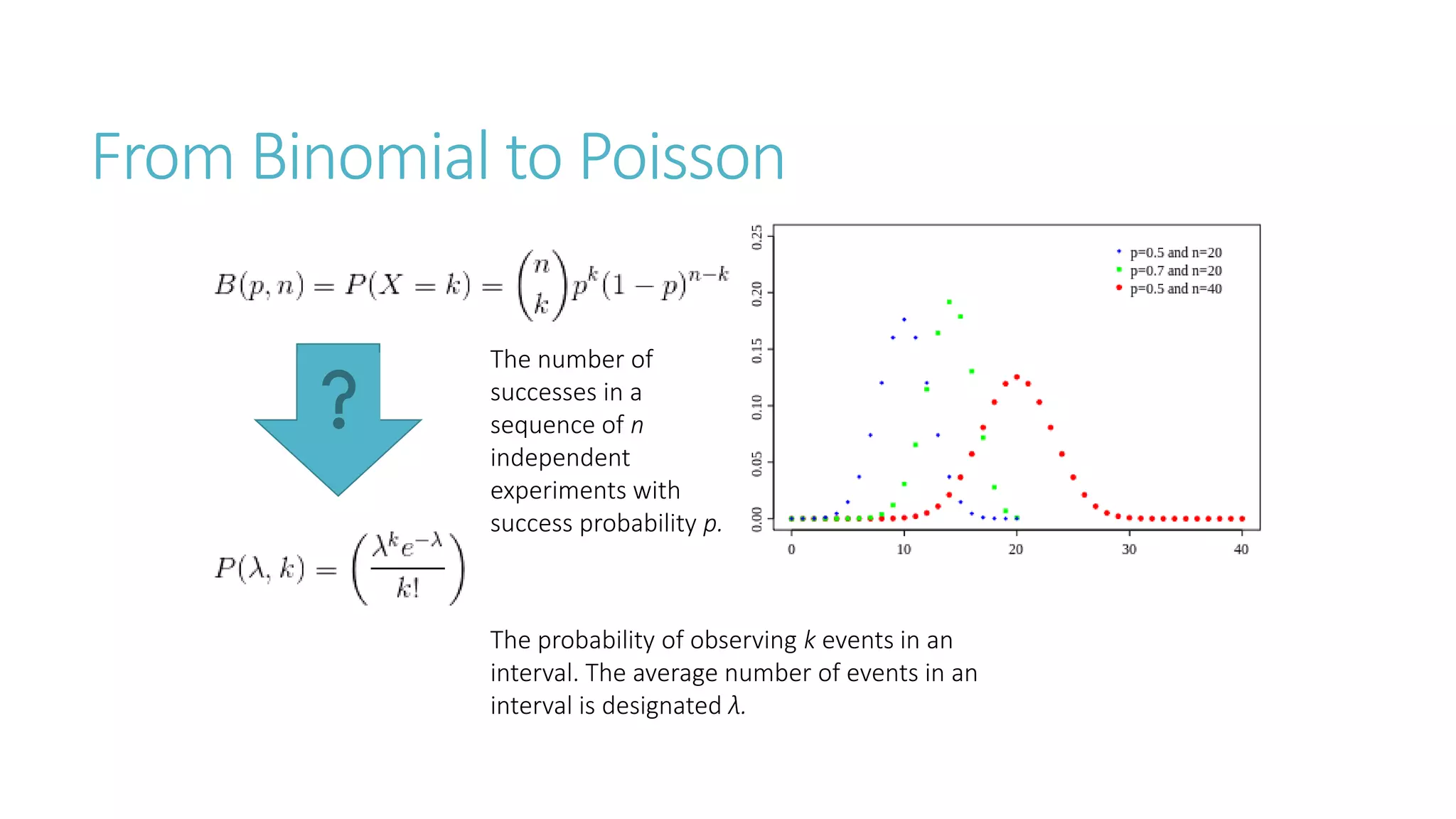


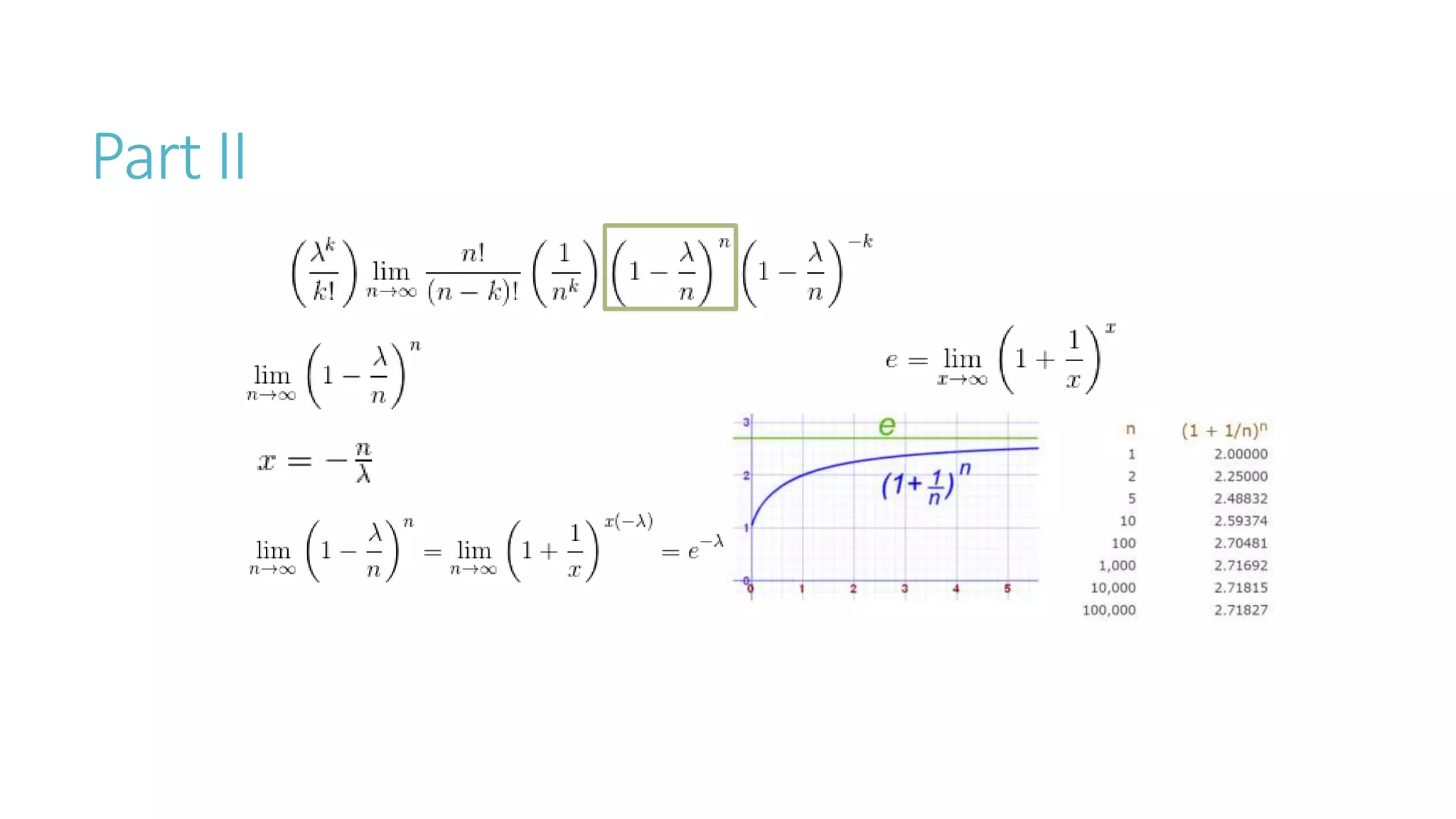
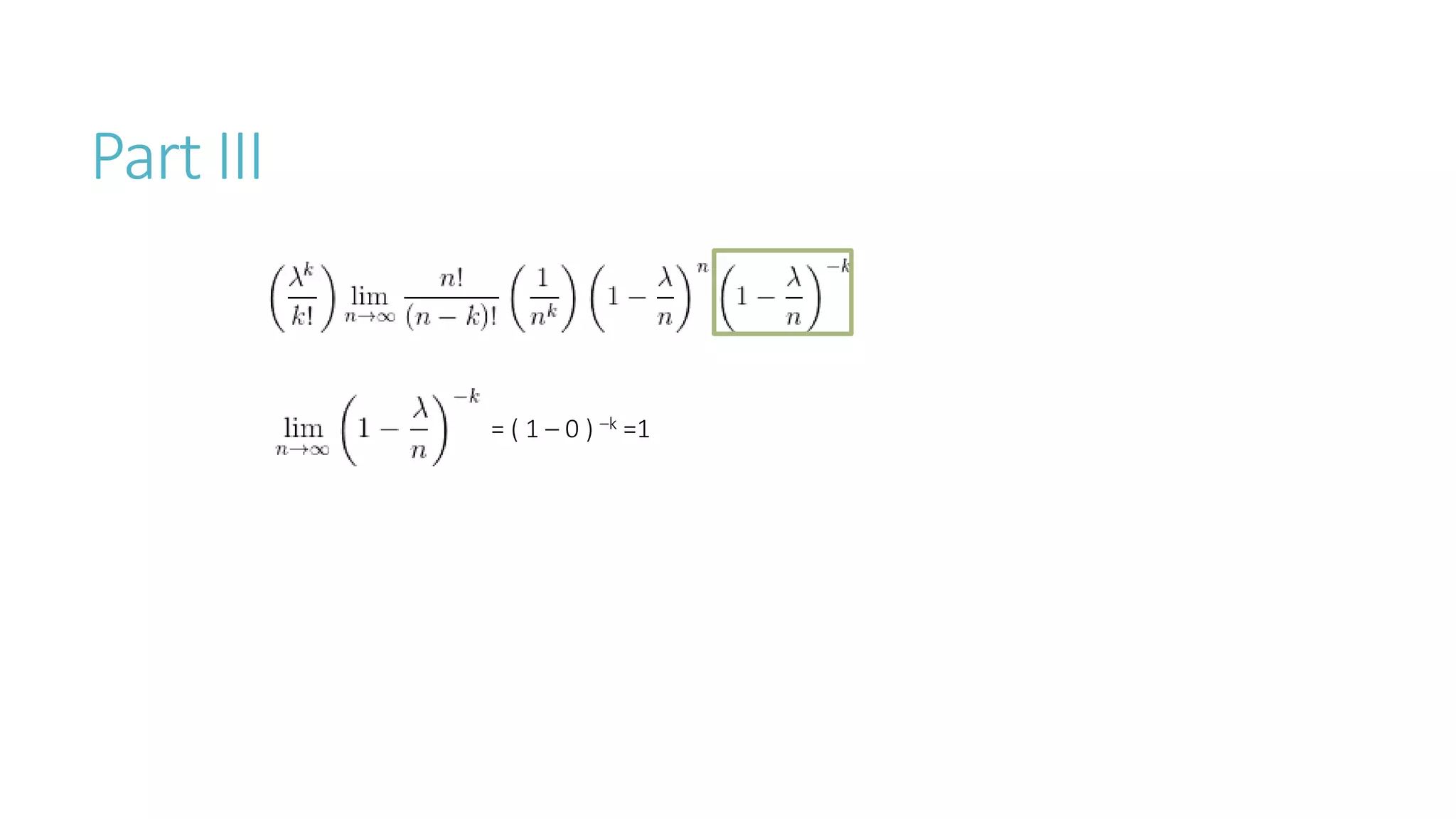
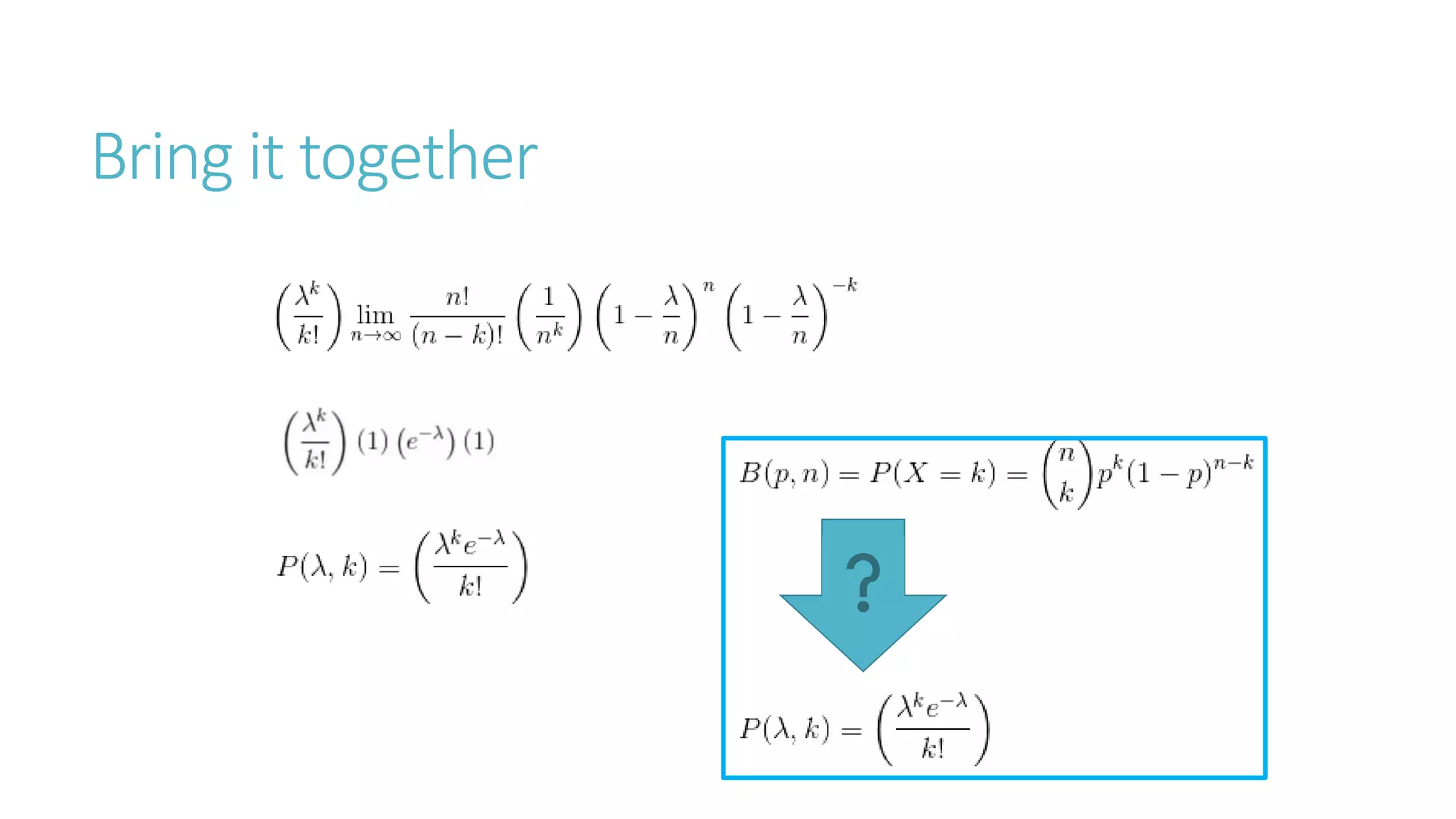


Linear algebra and probability concepts are summarized in 3 sentences: Scalars, vectors, matrices, and tensors are introduced as the basic components of linear algebra. Common linear algebra operations like transpose, addition, and multiplication are described. Probability concepts such as random variables, probability distributions, moments, and the central limit theorem are covered to lay the foundation for understanding deep learning techniques.























































































