Download as PDF, PPTX



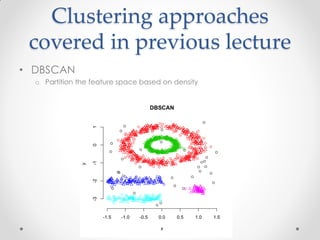



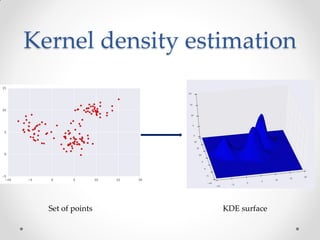

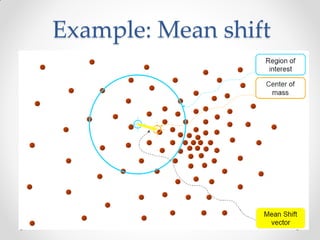
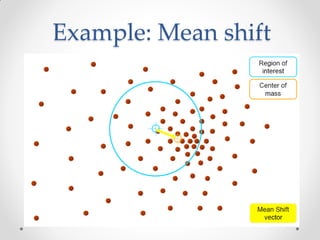
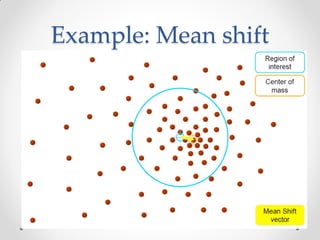
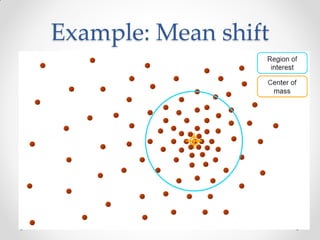
















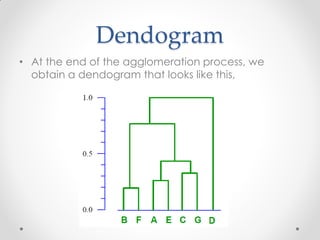
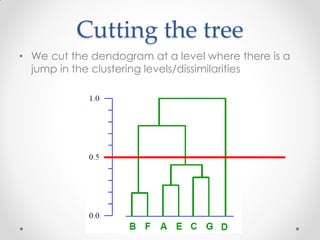

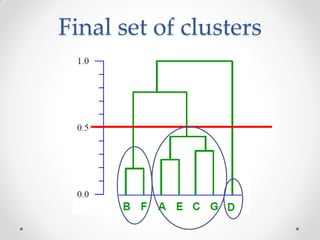






Mean shift clustering finds clusters by locating peaks in the probability density function of the data. It iteratively moves data points to the mean of nearby points until convergence. Hierarchical clustering builds clusters gradually by either merging or splitting clusters at each step. There are two types: divisive which splits clusters, and agglomerative which merges clusters. Agglomerative clustering starts with each point as a cluster and iteratively merges the closest pair of clusters until all are merged based on a chosen linkage method like complete or average linkage. The choice of distance metric and linkage method impacts the resulting clusters.

























































































![[DSC Europe 25] Dubravko Culibrk - Deep Learning for Mammography.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/yiscimuktacgqoiu4dkp-deep-learning-for-mammography-260119121559-aad59182-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DSC Europe 25] Bojan Banjac - AI is always right when it comes to the matter...](https://cdn.slidesharecdn.com/ss_thumbnails/syoxtqierpydwxm5srcb-4-bojan-banjac-ai-is-always-right-when-it-comes-to-the-matters-of-taste-260119101519-694ee7d7-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DSC Europe 25] Paula Garcia Esteban -Building the Future: The Role of Data S...](https://cdn.slidesharecdn.com/ss_thumbnails/9ld1r1bsqpwve8qfvphy-paula-garcia-esteban-building-the-future-260122103838-4171f5cb-thumbnail.jpg?width=640&height=640&fit=bounds)











