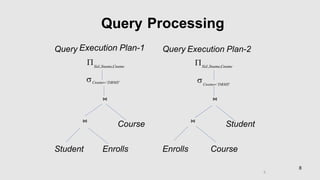
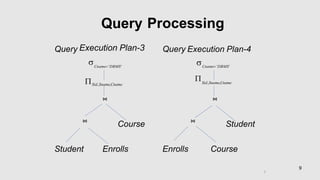
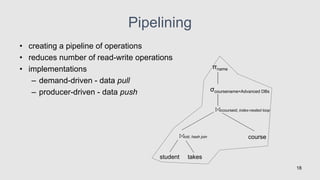
Chapter 5 discusses query processing and optimization, outlining the steps involved in parsing, translating, and evaluating SQL queries to efficient relational algebra expressions. It emphasizes the importance of query optimization to select the lowest cost evaluation plan based on statistical information from the database. The chapter also covers various algorithms for operations, cost estimation for querying, and equivalence rules for transforming relational expressions.

















































































![Attack surfaces and attack tress[inform]](https://cdn.slidesharecdn.com/ss_thumbnails/lecture03-260108015941-a4dee53b-thumbnail.jpg?width=640&height=640&fit=bounds)








