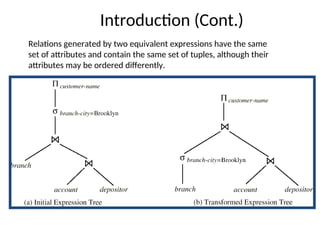
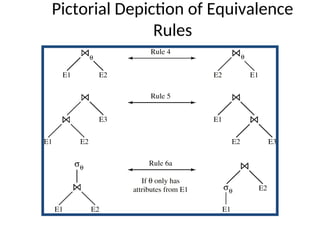
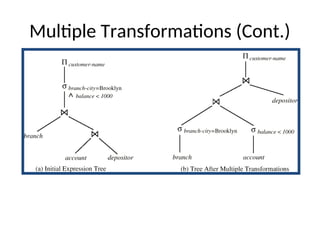
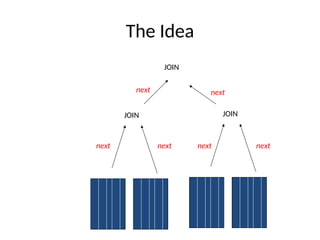
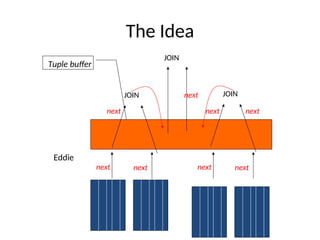
The document discusses advanced techniques for distributed query processing, focusing on query optimization and various evaluation strategies. It outlines the importance of cost estimation, transformation rules, and memoization for generating efficient query evaluation plans. Additionally, it introduces adaptive query processing models, such as eddies, which dynamically adjust execution based on real-time conditions and system behavior.