Downloaded 43 times






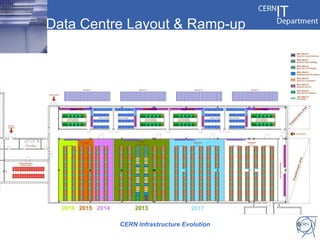


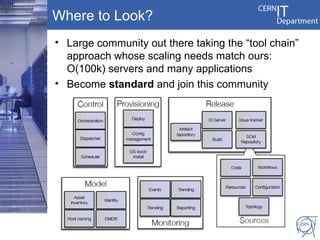


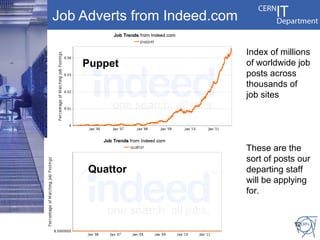

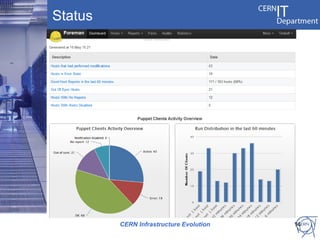



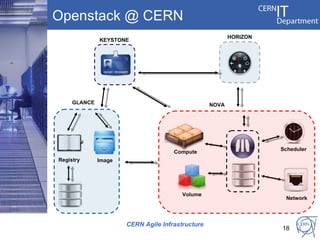


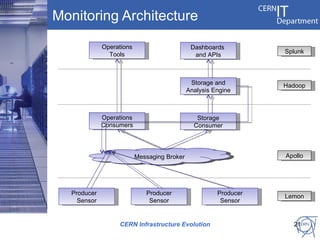
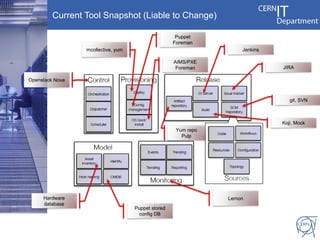





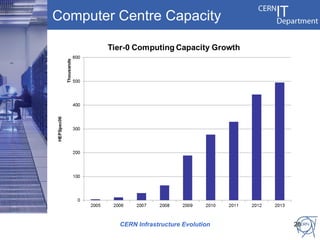

CERN's IT infrastructure is reaching its limits and needs to expand to support increasing computing capacity demands while maintaining a fixed staff size. CERN is addressing this by expanding its data center capacity through a new remote facility in Budapest, Hungary, and by adopting new open source configuration, monitoring and infrastructure tools to improve efficiency. Key projects include deploying OpenStack for infrastructure as a service, Puppet for configuration management, and integrating monitoring across tools. The transition will take place between 2012-2014 alongside LHC upgrades.




























































































