Downloaded 40 times









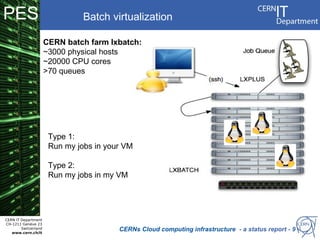
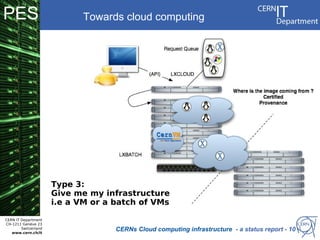
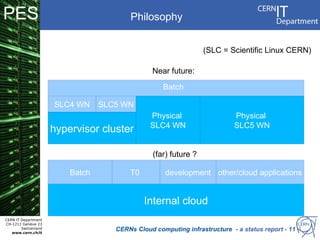





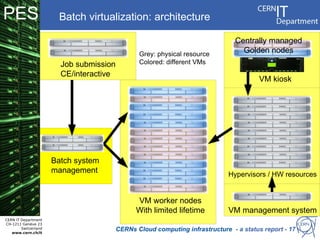

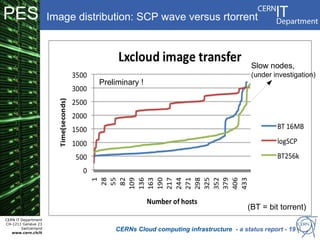

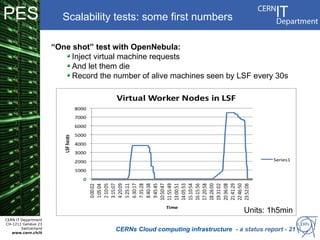

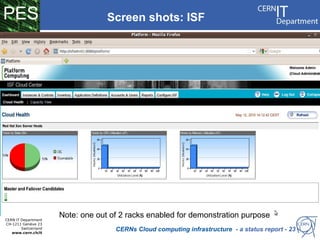
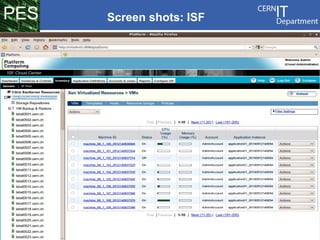



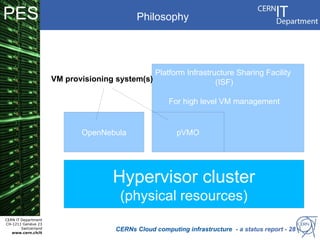



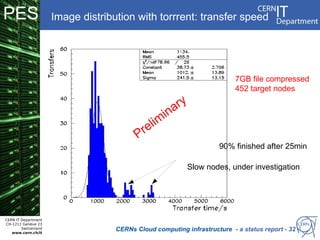
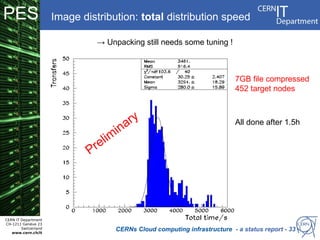

CERN operates the largest particle physics laboratory in the world. It generates huge amounts of data from experiments like the Large Hadron Collider that require vast computing resources to analyze. CERN is moving to virtualize its batch computing infrastructure to better utilize resources and enable new computing models like cloud computing. The presentation provides an overview of CERN's computing infrastructure and status of its efforts to virtualize its batch resources using virtual machines with limited lifetimes that are deployed dynamically on a hypervisor cluster.
































































































