Download to read offline































![Copyright © 2011 LOGTEL
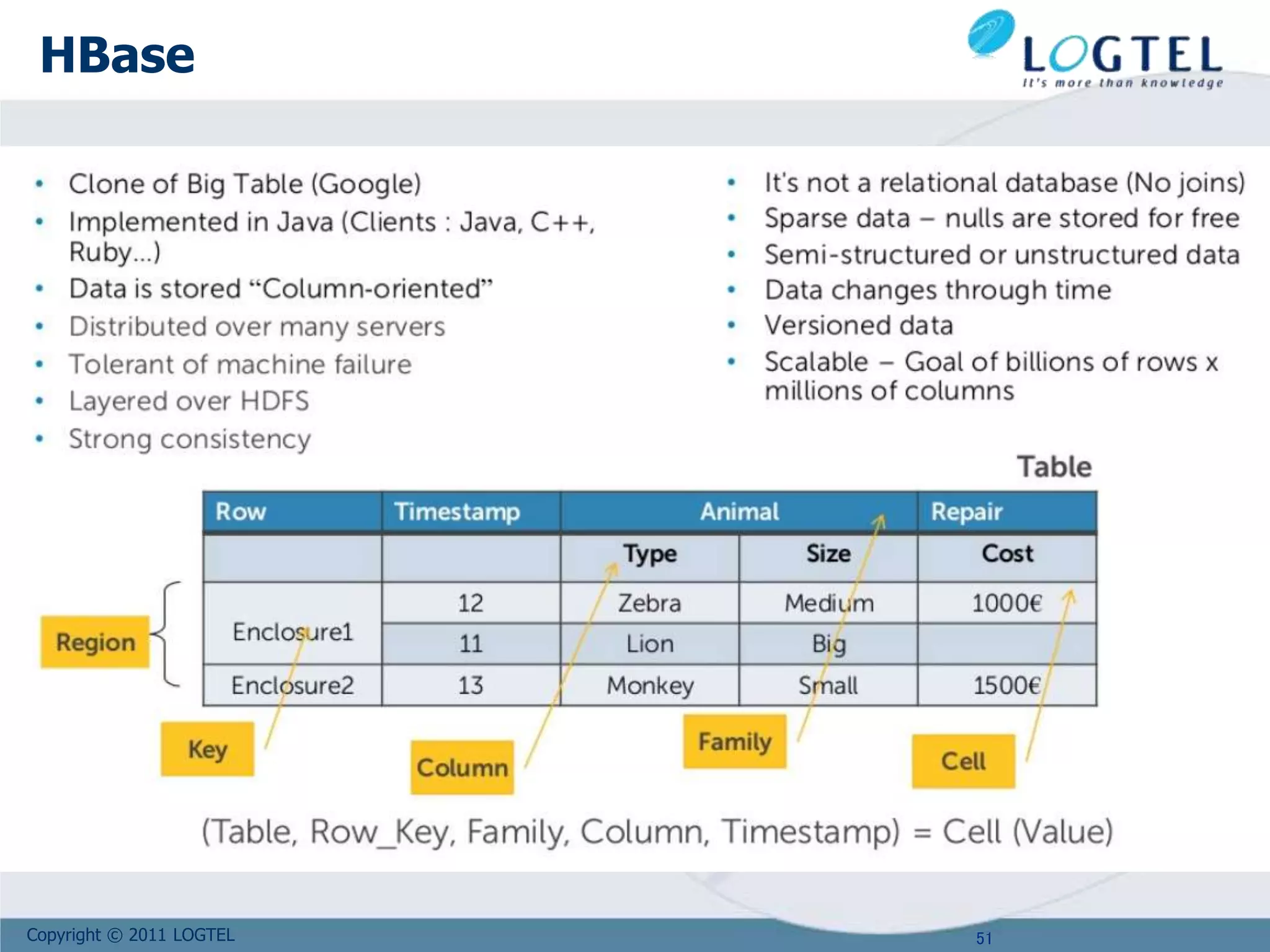
Google
Tables are sorted by Row
Table schema only define its column families .
Each family consists of any number of columns
Each column consists of any number of versions
Columns only exist when inserted, NULLs are free.
Columns within a family are sorted and stored together
Everything except table names are byte[]
(Row, Family: Column, Timestamp) Value
Row key
Column Family
value
TimeStamp](https://image.slidesharecdn.com/bigdata2107-210720144243/75/Big-Data-2107-for-Ribbon-52-2048.jpg)




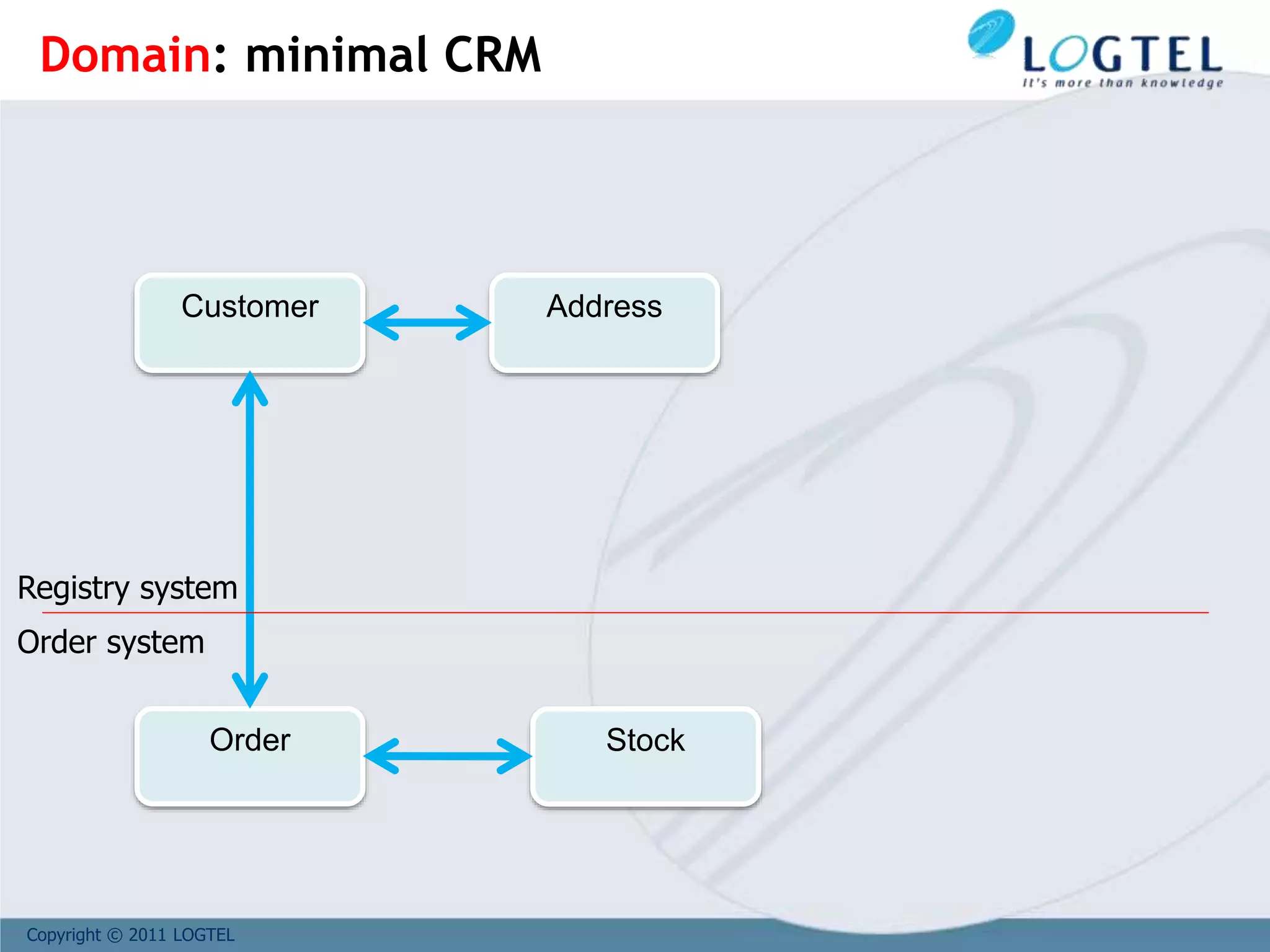



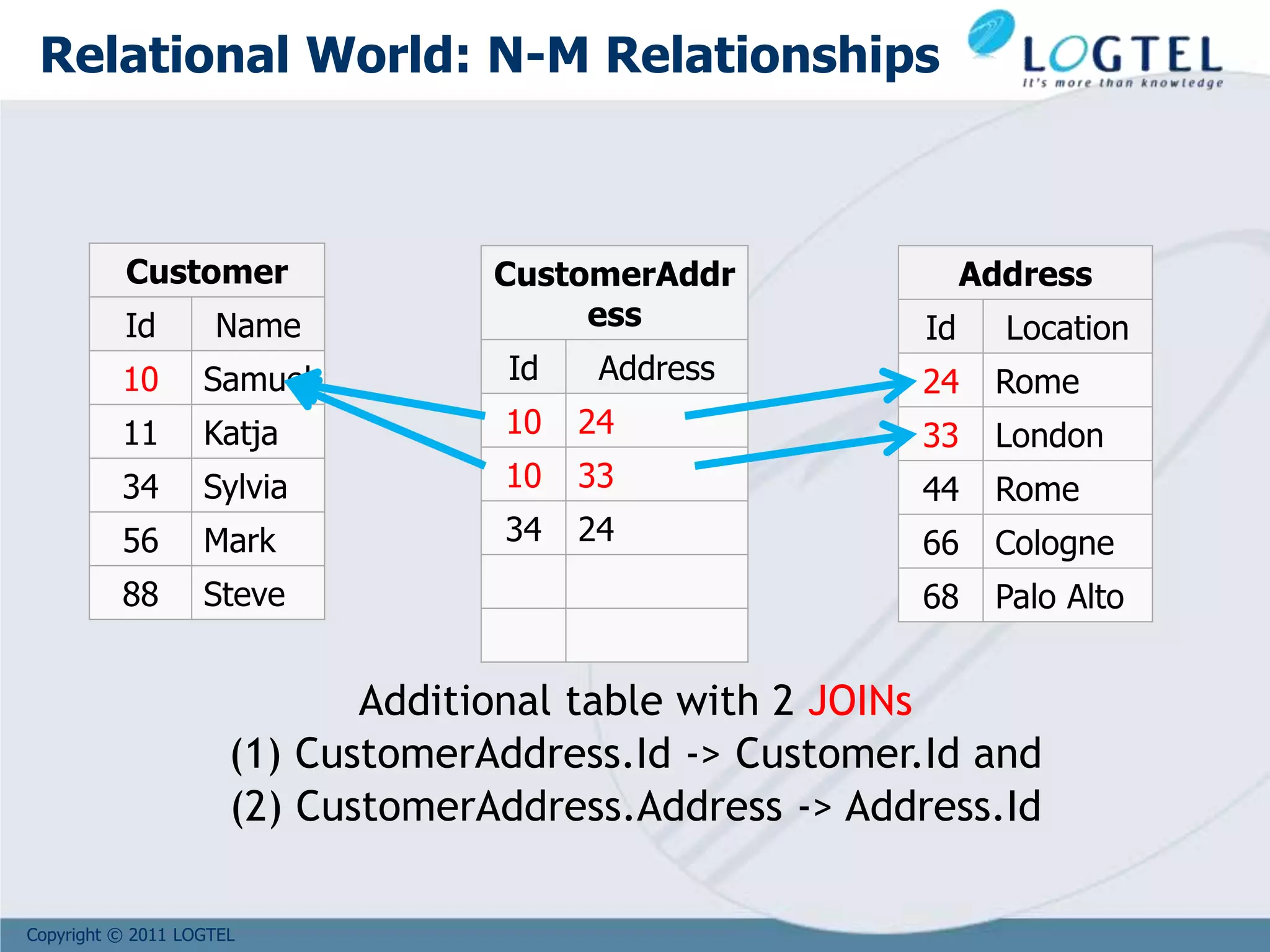




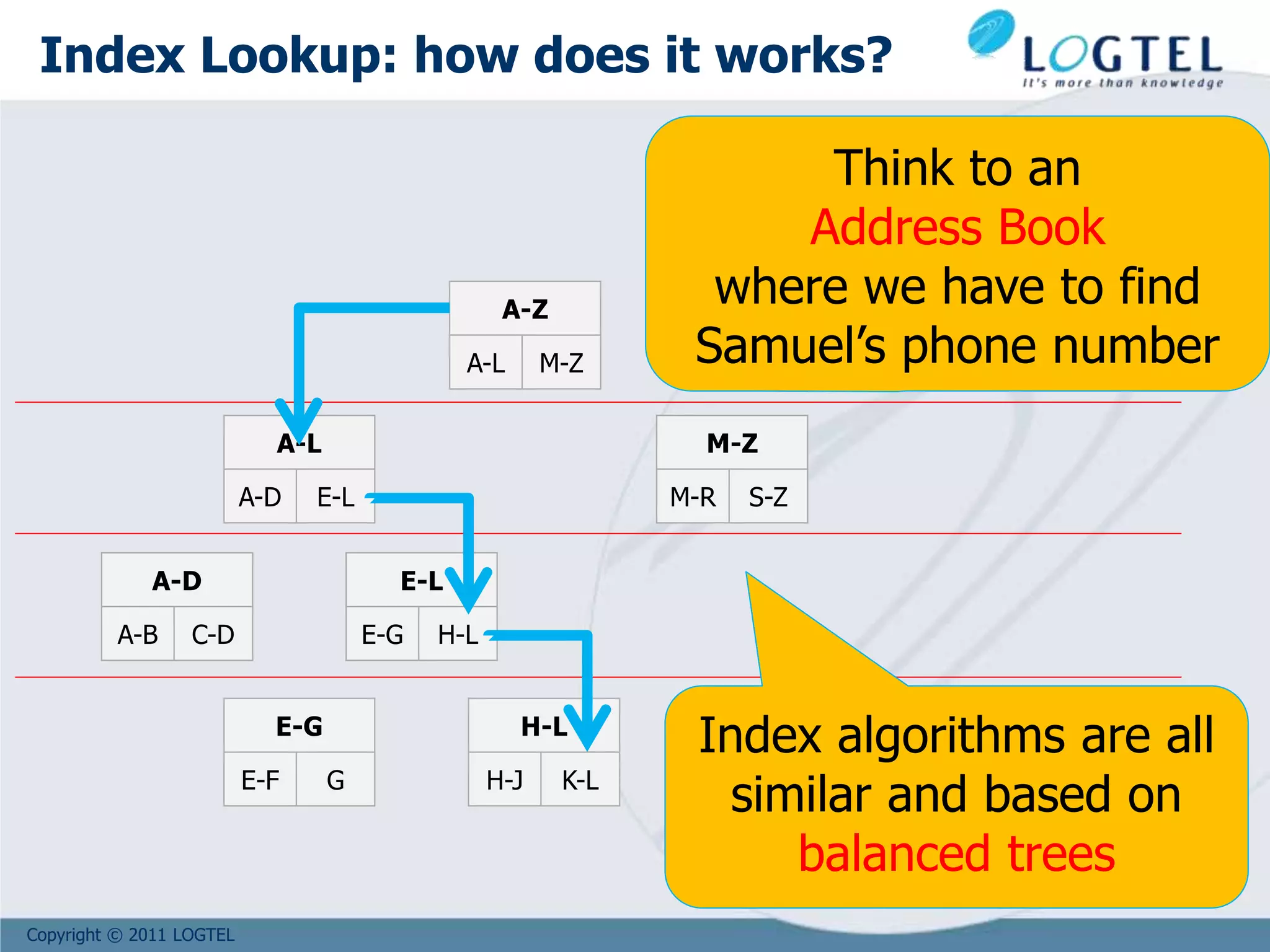
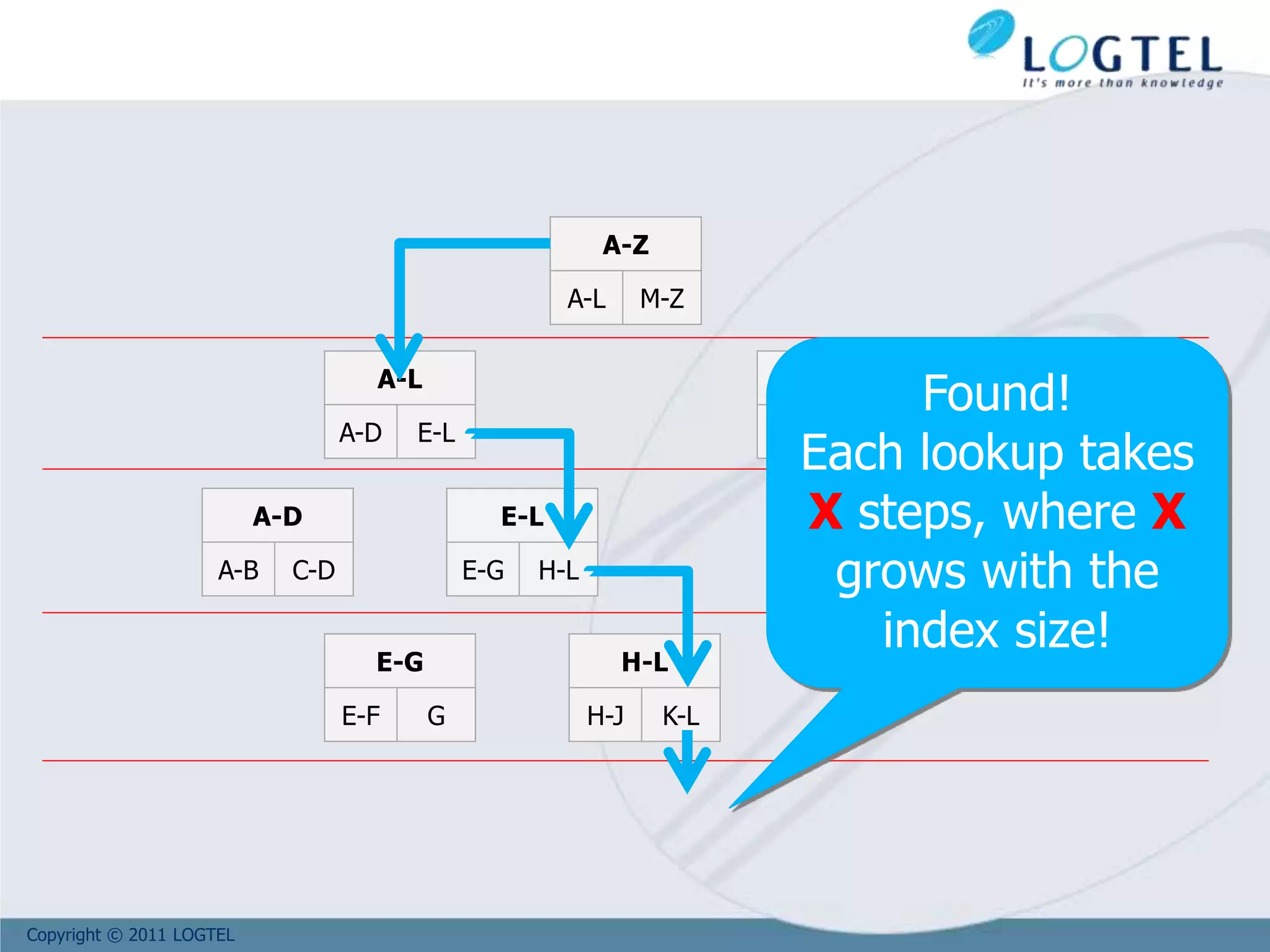

![Copyright © 2011 LOGTEL
Sam
Lives
out : [#14:54]
label : ‘Customer’
name : ‘Sam’
out: [#13:35]
in: [#13:100]
Label : ‘Lives’
RID =
#13:35
RID =
#14:54
RID =
#13:100
in: [#14:54]
label = ‘Address’
name = ‘Rome’
The Record ID (RID)
is a Physical position
Rome
OrientDB: traverse a relationship](https://image.slidesharecdn.com/bigdata2107-210720144243/75/Big-Data-2107-for-Ribbon-73-2048.jpg)




![Copyright © 2011 LOGTEL
orientdb> select in[label=‘Lives’].out from V where
label = ‘Address’ and name = ‘Rome’
---+--------+--------------------+--------------------+--------------------+
#| REC ID |label |out |in |
---+--------+--------------------+--------------------+--------------------+
0| 13:35|Sam |[#14:54] | |
---+--------+--------------------+--------------------+--------------------+
1 item(s) found. Query executed in 0.007 sec(s).
orientdb> select * from V where label = ‘Address’ AND
in[label=‘Lives’].size() > 0
---+--------+--------------------+--------------------+--------------------+
#| REC ID |label |out |in |
---+--------+--------------------+--------------------+--------------------+
0| 13:100| Rome | |[#14:54] |
---+--------+--------------------+--------------------+--------------------+
1 item(s) found. Query executed in 0.007 sec(s).
Query the graph in SQL](https://image.slidesharecdn.com/bigdata2107-210720144243/75/Big-Data-2107-for-Ribbon-78-2048.jpg)
![Copyright © 2011 LOGTEL
OGraphDatabase graph = new
OGraphDatabase("local:/tmp/db/graph”);
// GET ALL THE THE CUSTOMER FROM ROME, ITALY
List<ODocument> result = graph.command( new OCommandSQL (
“select in[label=‘Lives’].out from V where label = ‘Address’
and name = ?”)
).execute( “Rome”);
for( ODocument v : result ) {
System.out.println(“Result: “ + v.field(“label”) );
}
-----------------------------------------------------------------------------------
----Result: Sam
Query the graph in Java](https://image.slidesharecdn.com/bigdata2107-210720144243/75/Big-Data-2107-for-Ribbon-79-2048.jpg)

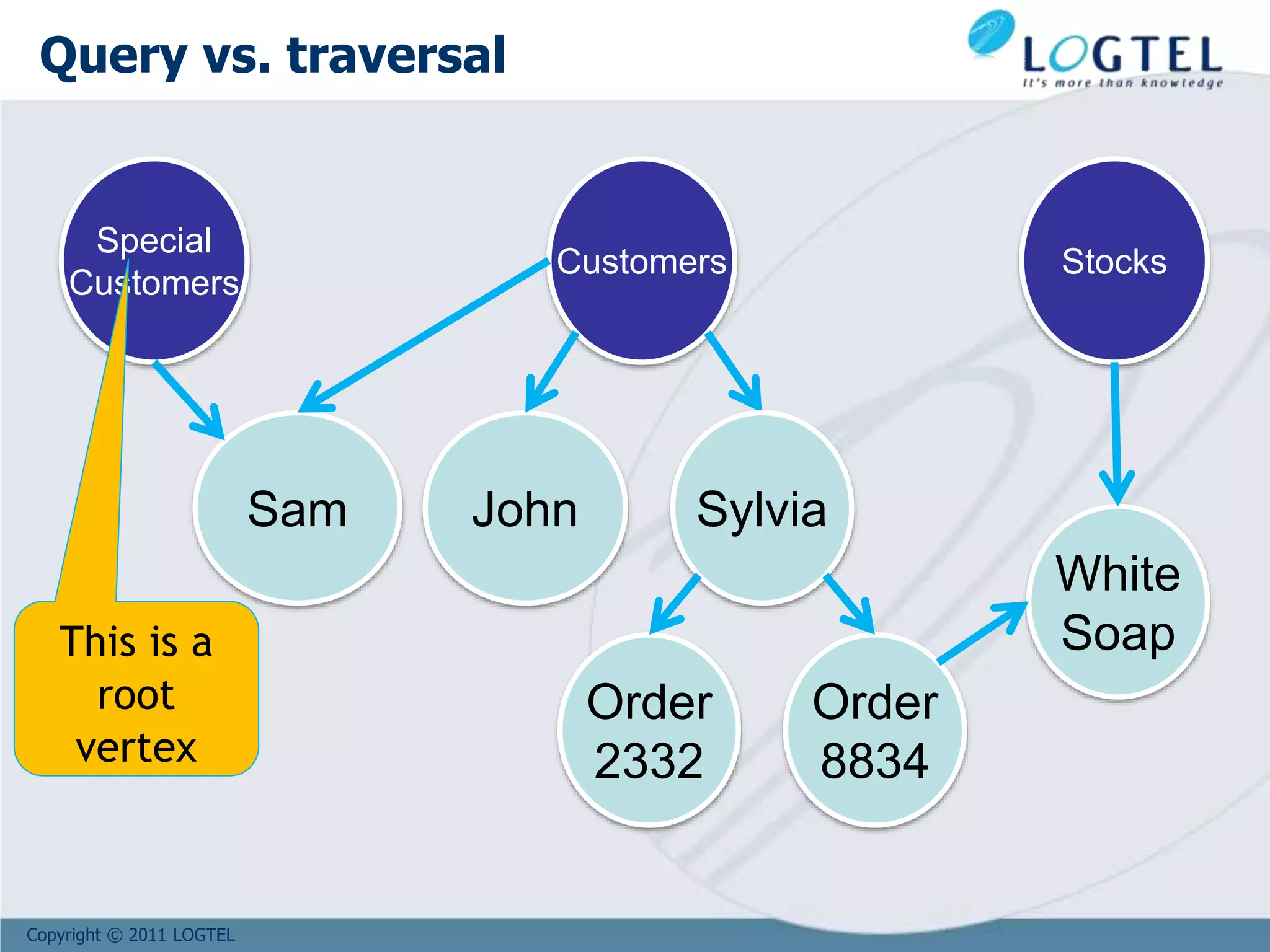
![Copyright © 2011 LOGTEL
Supposing that the root node #30:0 links all the
Customer vertices
Get all the customers:
orientdb> select out.in from #30:0
Get all the customers who bought at least one ‘White Soap’
product:
orientdb> select * from ( select out.in from #30:0) where
out.in.out[label=‘Bought’].in.name = ‘White Soap’
Customers
#30:0
Query the graph in SQL](https://image.slidesharecdn.com/bigdata2107-210720144243/75/Big-Data-2107-for-Ribbon-82-2048.jpg)




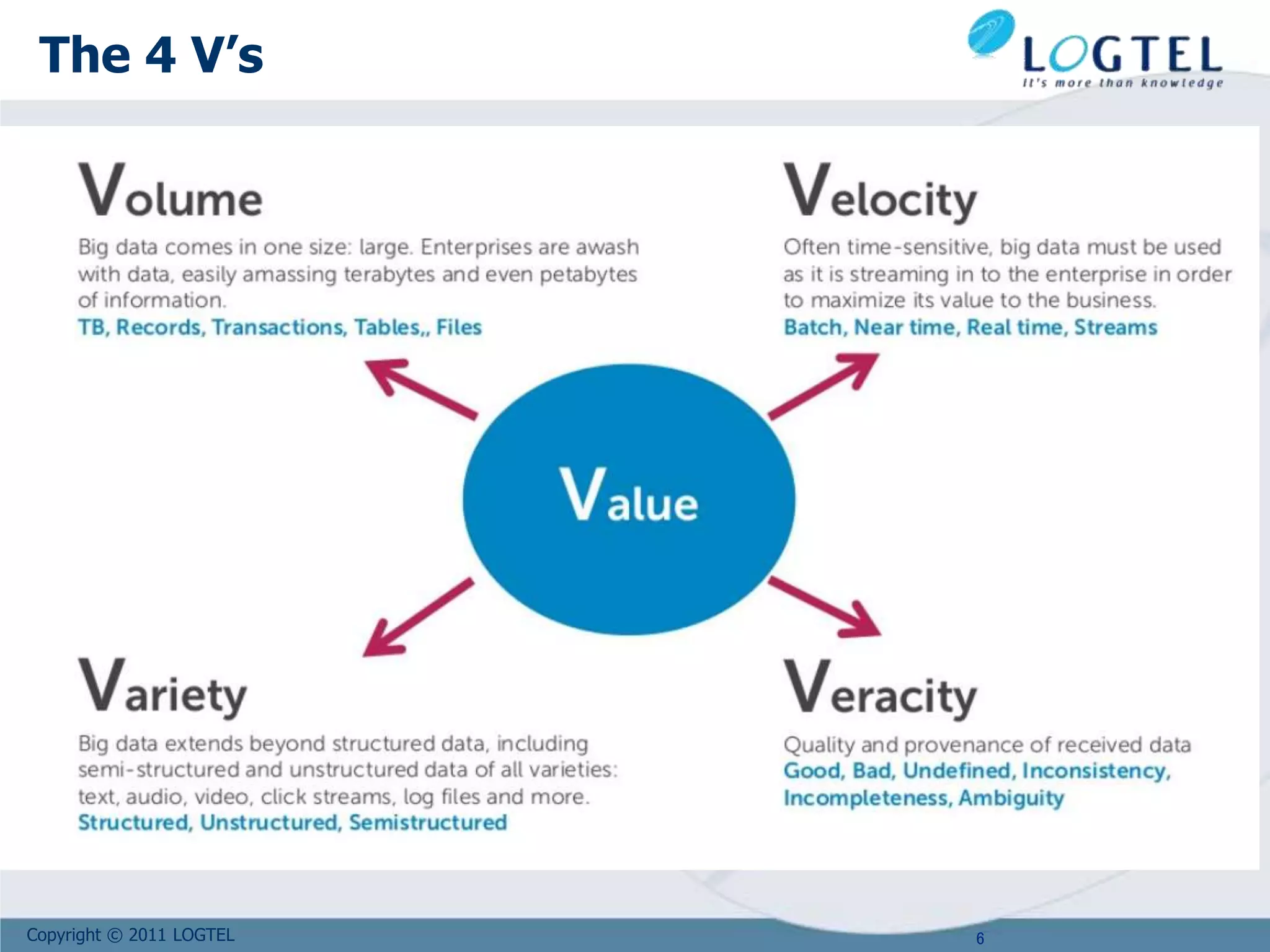
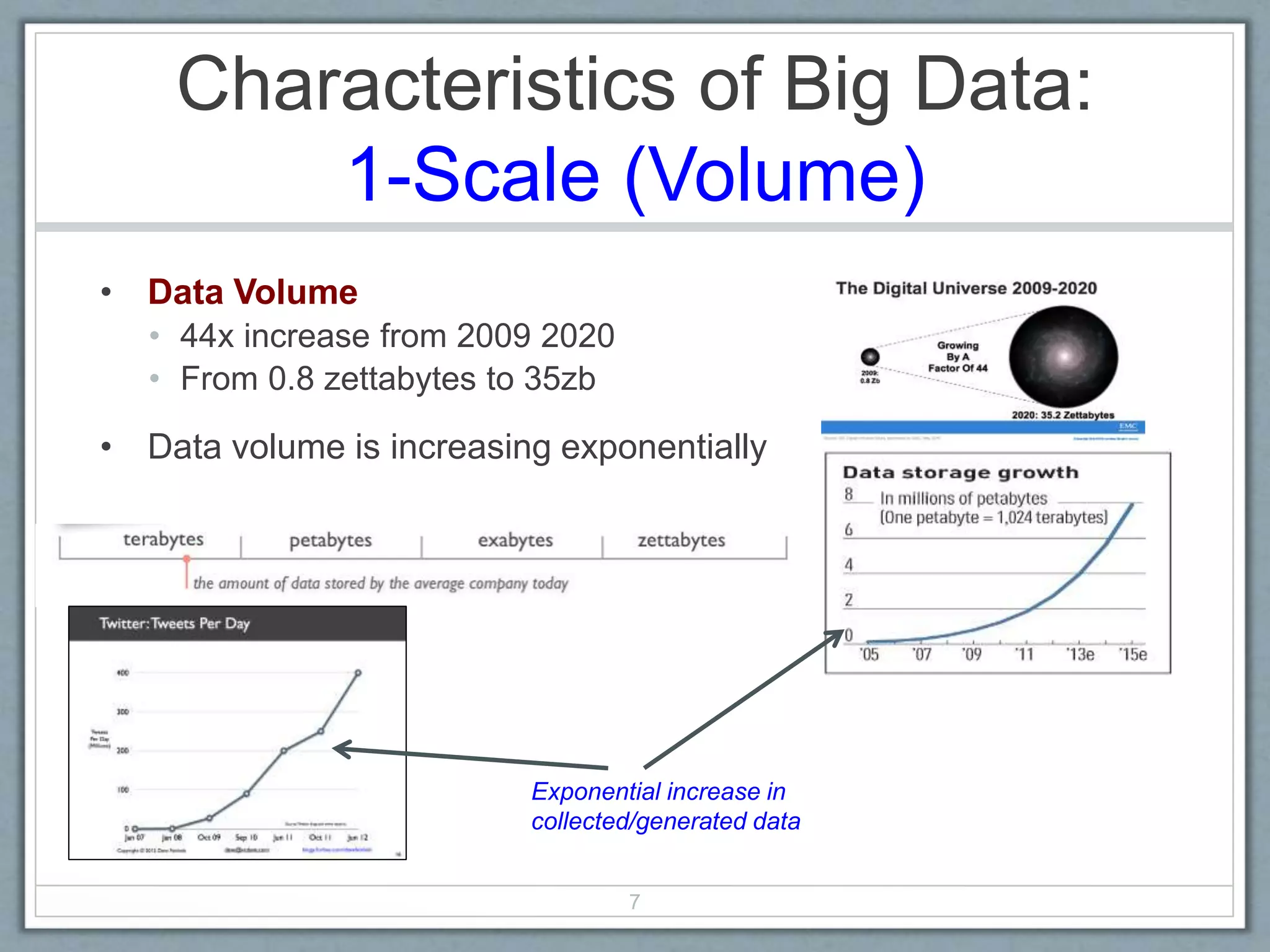
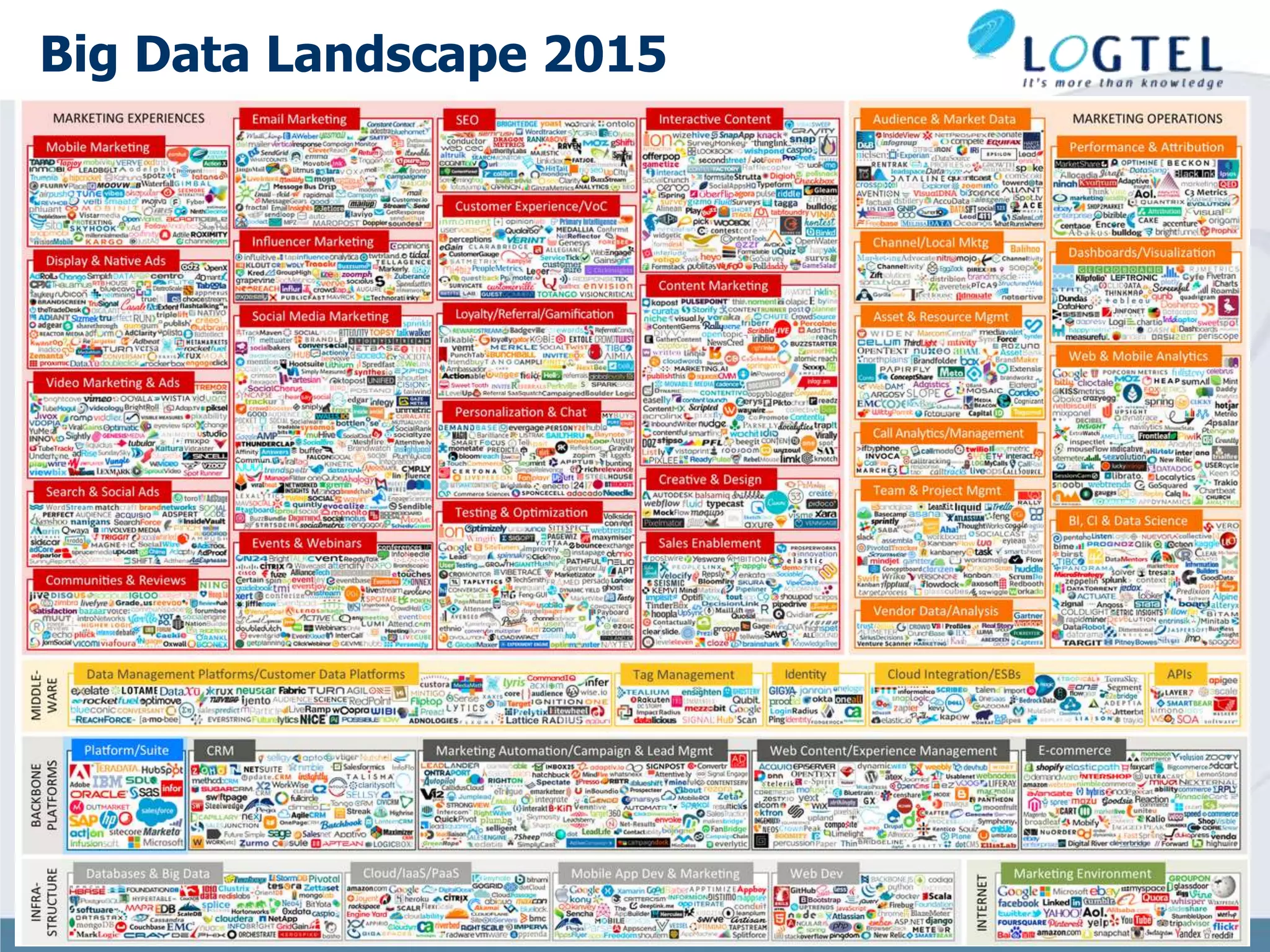
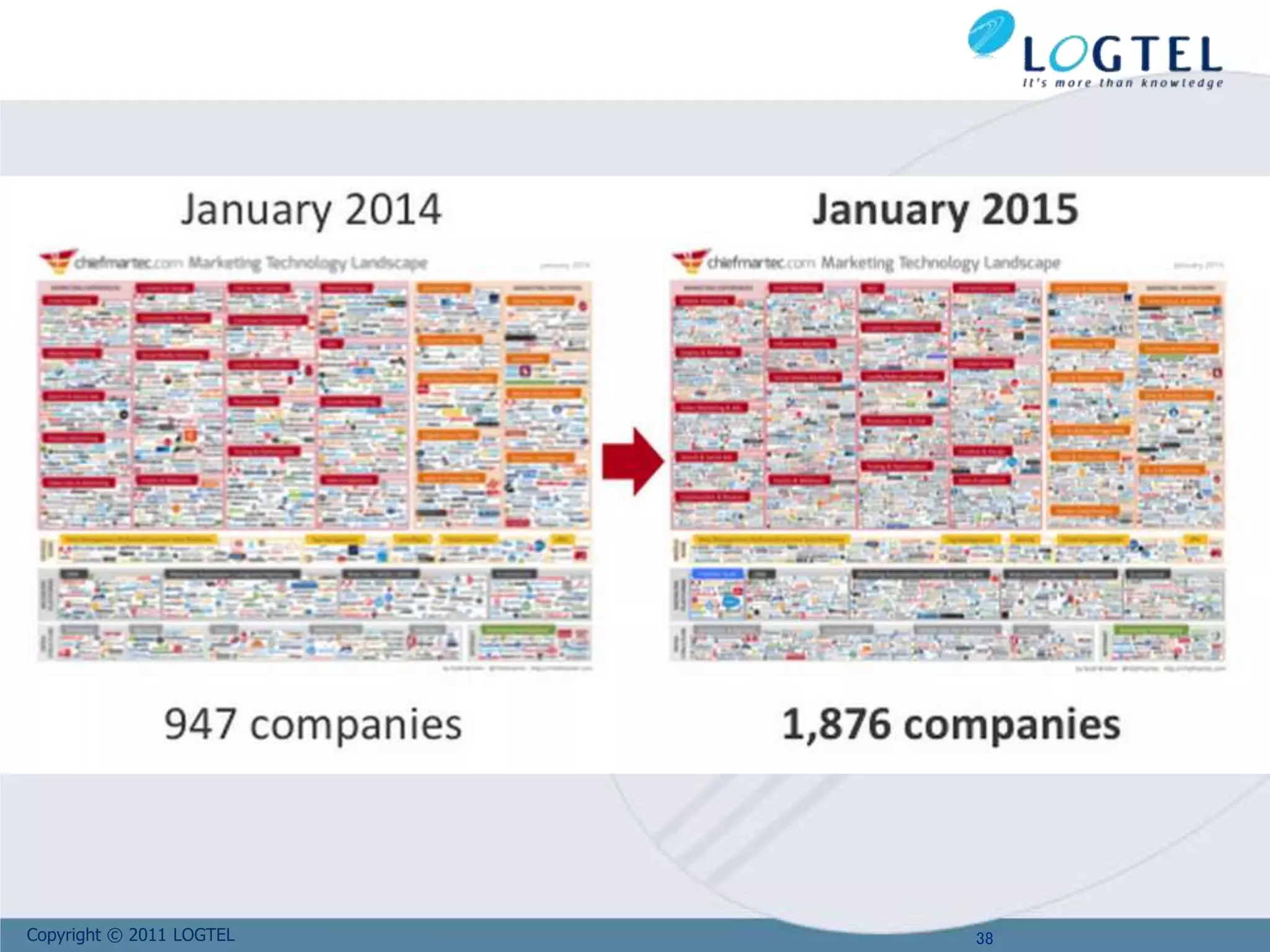
The document provides an extensive overview of big data, defining it through its characteristics, known as the 4 V's: volume, variety, velocity, and complexity. It discusses the evolution of data generation and consumption, the implications of the CAP theorem on system design, and the applications and technologies related to big data, including NoSQL databases. Additionally, it highlights challenges associated with traditional database models and the importance of scalable architectures to manage large datasets effectively.

















![[OpenStack Day in Korea 2015] Keynote 2 - Leveraging OpenStack to Realize the...](https://cdn.slidesharecdn.com/ss_thumbnails/02-150213033017-conversion-gate01-thumbnail.jpg?width=640&height=640&fit=bounds)










































![[DSC Europe 25] Behzad Hosseini - AI Agents in the Wild: Deploying Models tha...](https://cdn.slidesharecdn.com/ss_thumbnails/3qtejajvsjqrzwfept2c-10-251212103250-7f2b1068-thumbnail.jpg?width=640&height=640&fit=bounds)





![[DSC Europe 25] Uros Pesic - The Reality of AI in Marketing.pdf](https://cdn.slidesharecdn.com/ss_thumbnails/rtkodnmtycovsllvzsyn-9-251215095918-b0c6bfe3-thumbnail.jpg?width=640&height=640&fit=bounds)



![[DSC Europe 25] Branko Urosevic -Rethinking Financial Talent: Integrating Cod...](https://cdn.slidesharecdn.com/ss_thumbnails/8jjrus8ttko6qj64f58f-3-251212103250-642c6374-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Kaja Kandare - LLM as a judge.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/arxyccaxsdsd1ba99wjw-7-251212104007-2b4e3f64-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Bassam Maharmeh - Artificial Intelligence: Opportunities and ...](https://cdn.slidesharecdn.com/ss_thumbnails/thhfmr2fqpawzj7hsjpg-5-251211083048-2c23204f-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DSC Europe 25] Debmalya Biswas - Agentification: the art of transforming man...](https://cdn.slidesharecdn.com/ss_thumbnails/r5azlggvtqiaiiusrqdr-4-251212103249-5a12c89b-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DSC Europe 25] Hans Kleinsman - The Compliance Gearbox: How Tax Tech Mediate...](https://cdn.slidesharecdn.com/ss_thumbnails/dxdytie1toel0hr90bjs-2-251212103250-174fdbe7-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DSC Europe 25] Katherine Forrest - AI NOW: Understanding the Velocity of Cha...](https://cdn.slidesharecdn.com/ss_thumbnails/wvvbruqfrci0sfq9xwgb-4-251212104007-e5ad1987-thumbnail.jpg?width=640&height=640&fit=bounds)