Download to read offline

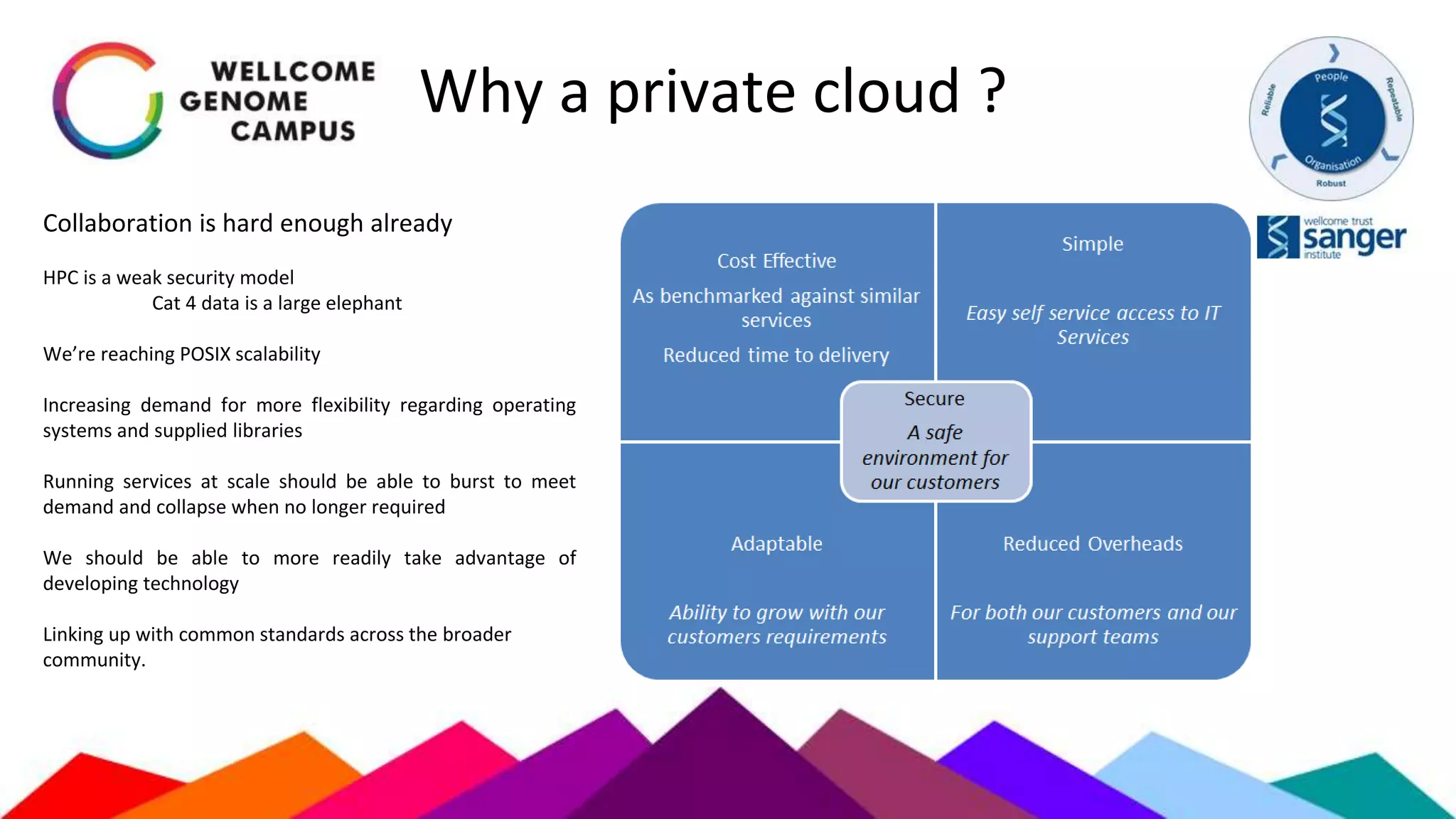




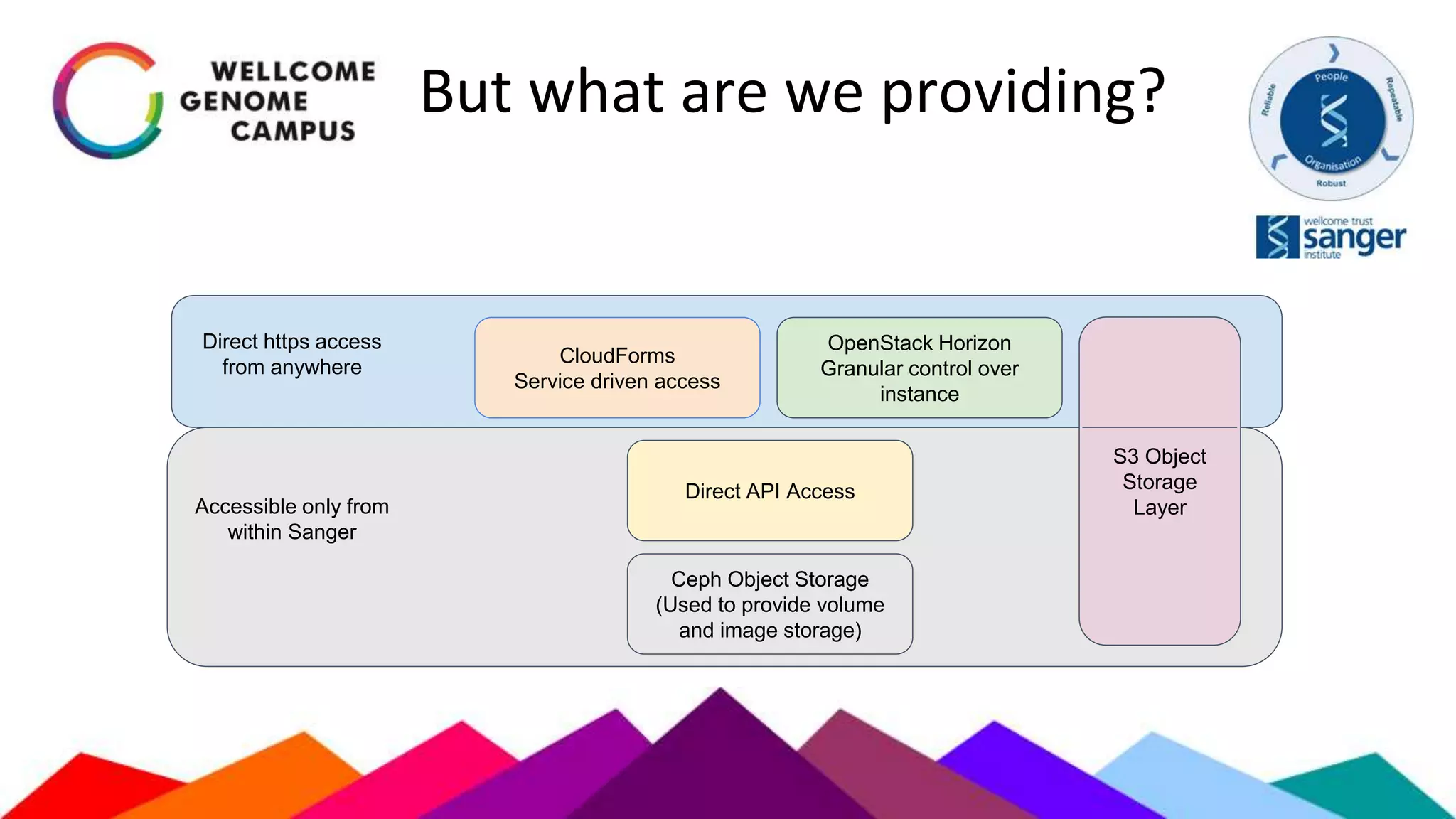
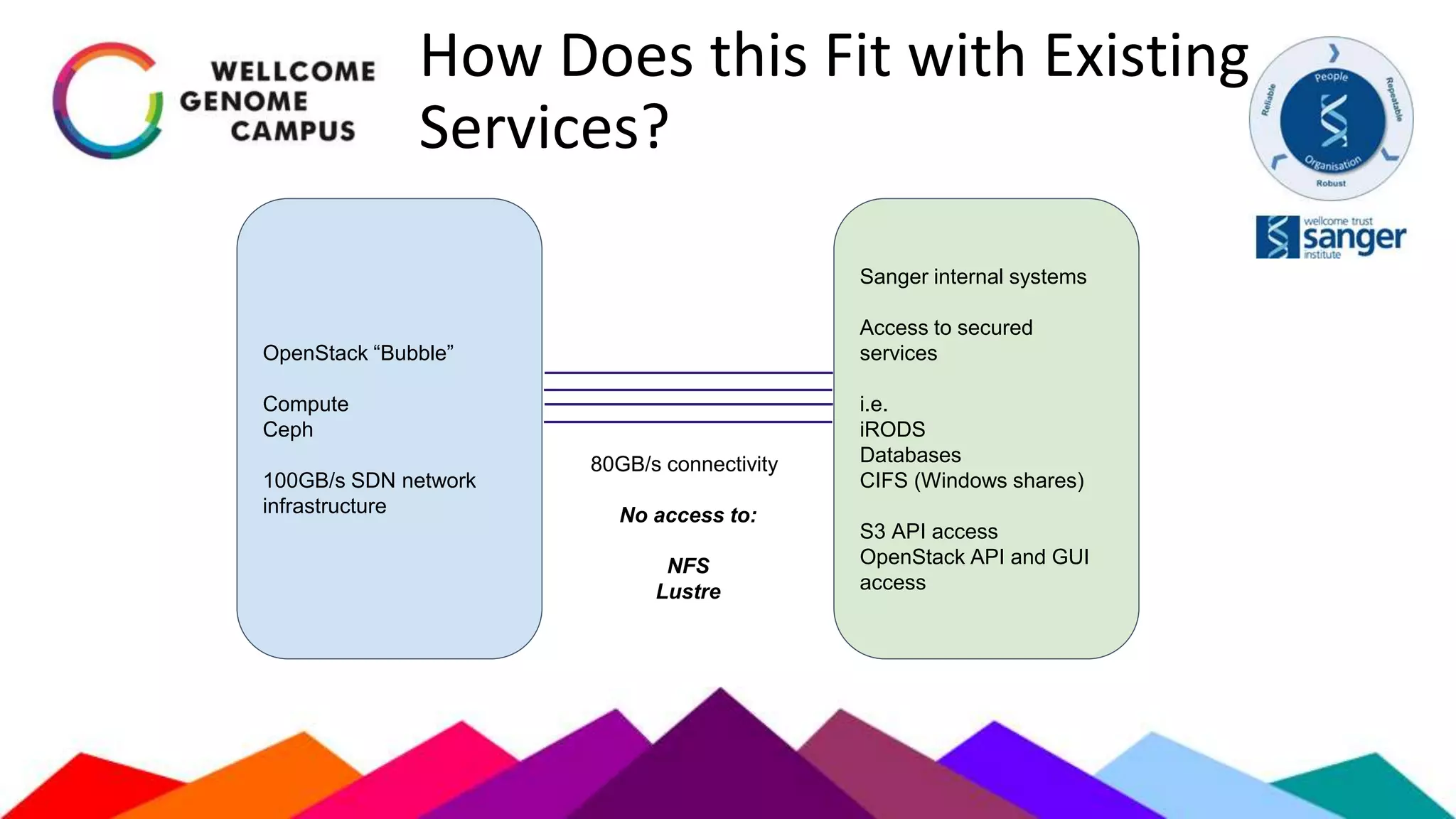
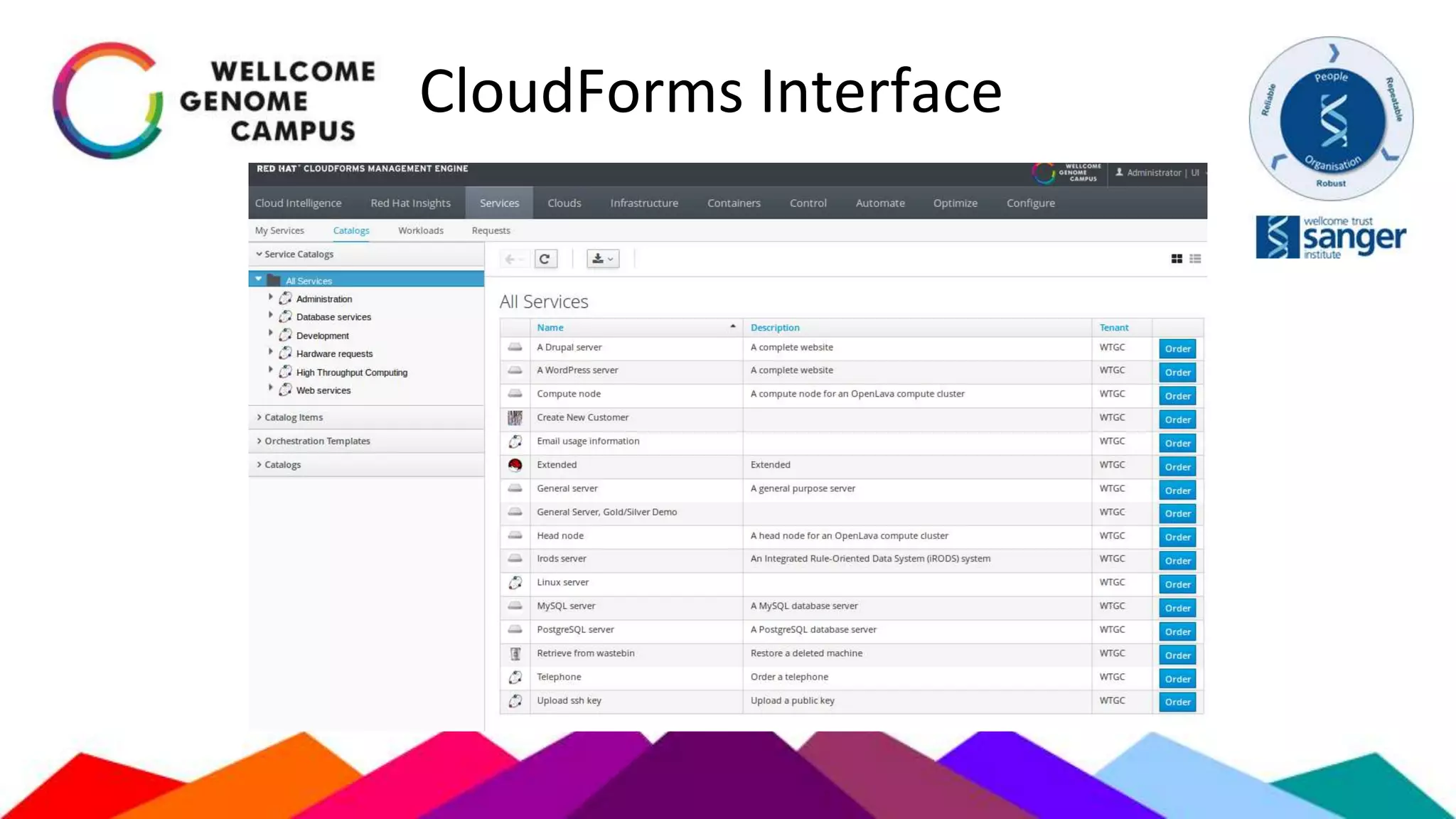
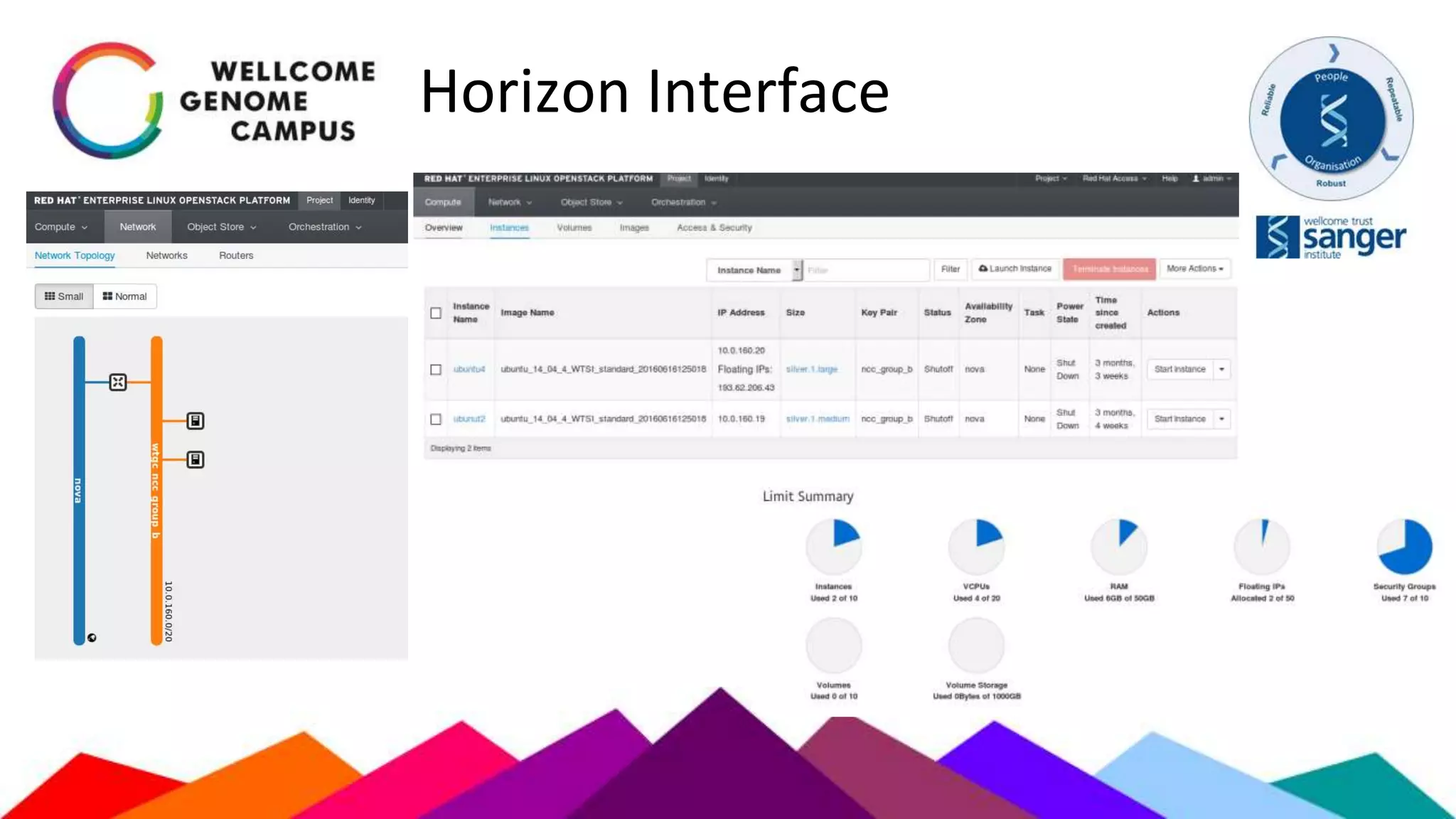






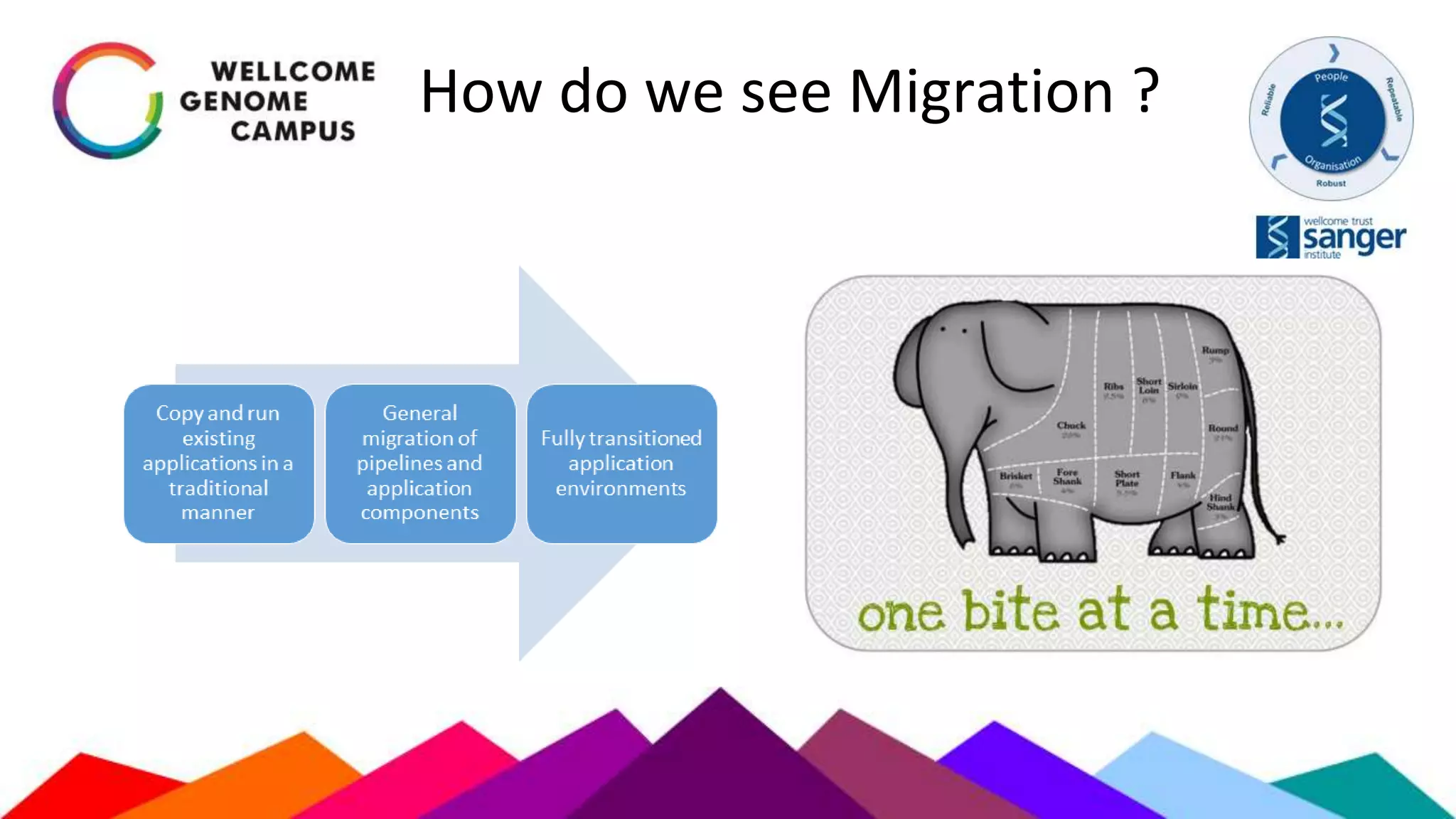
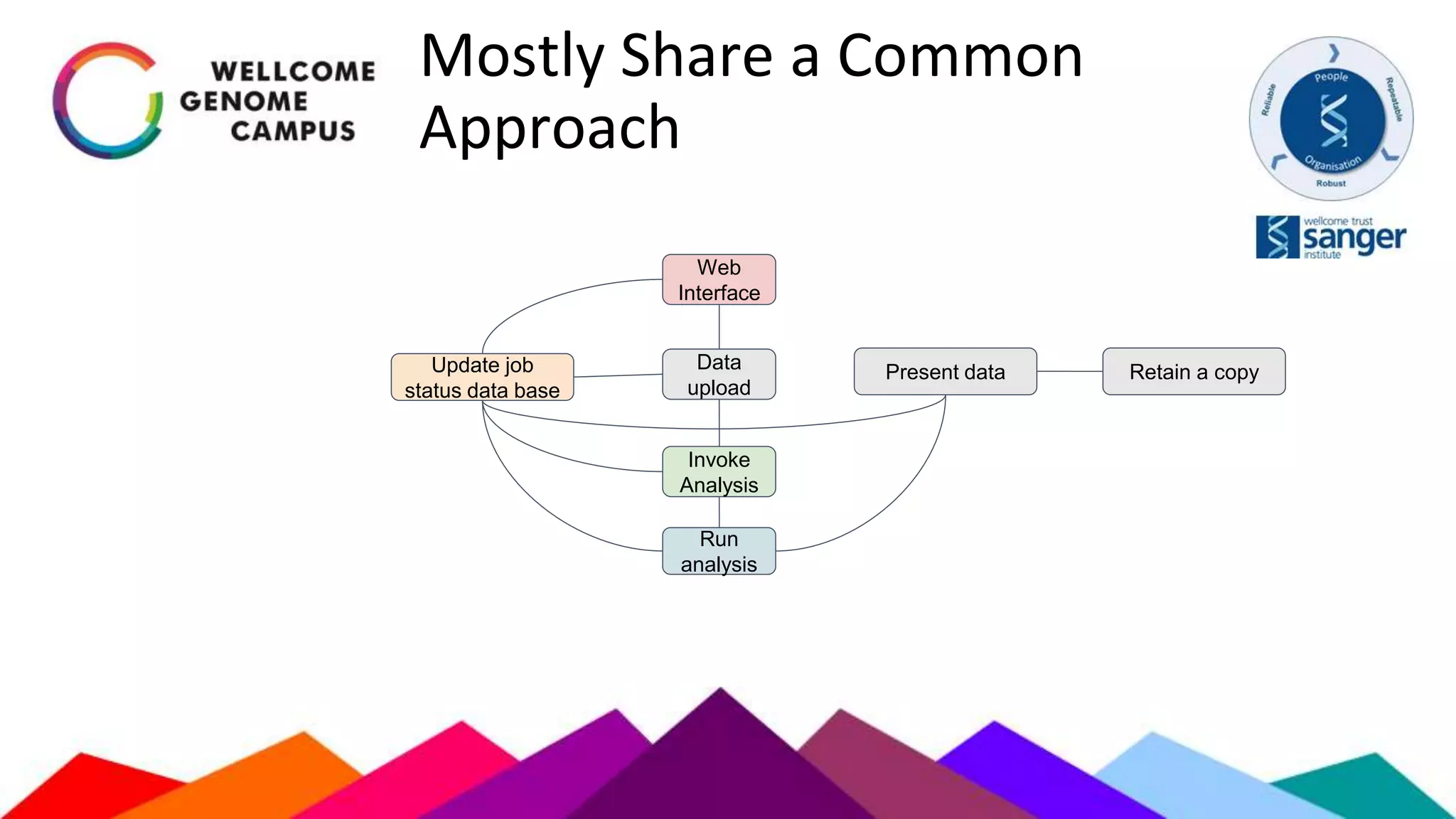














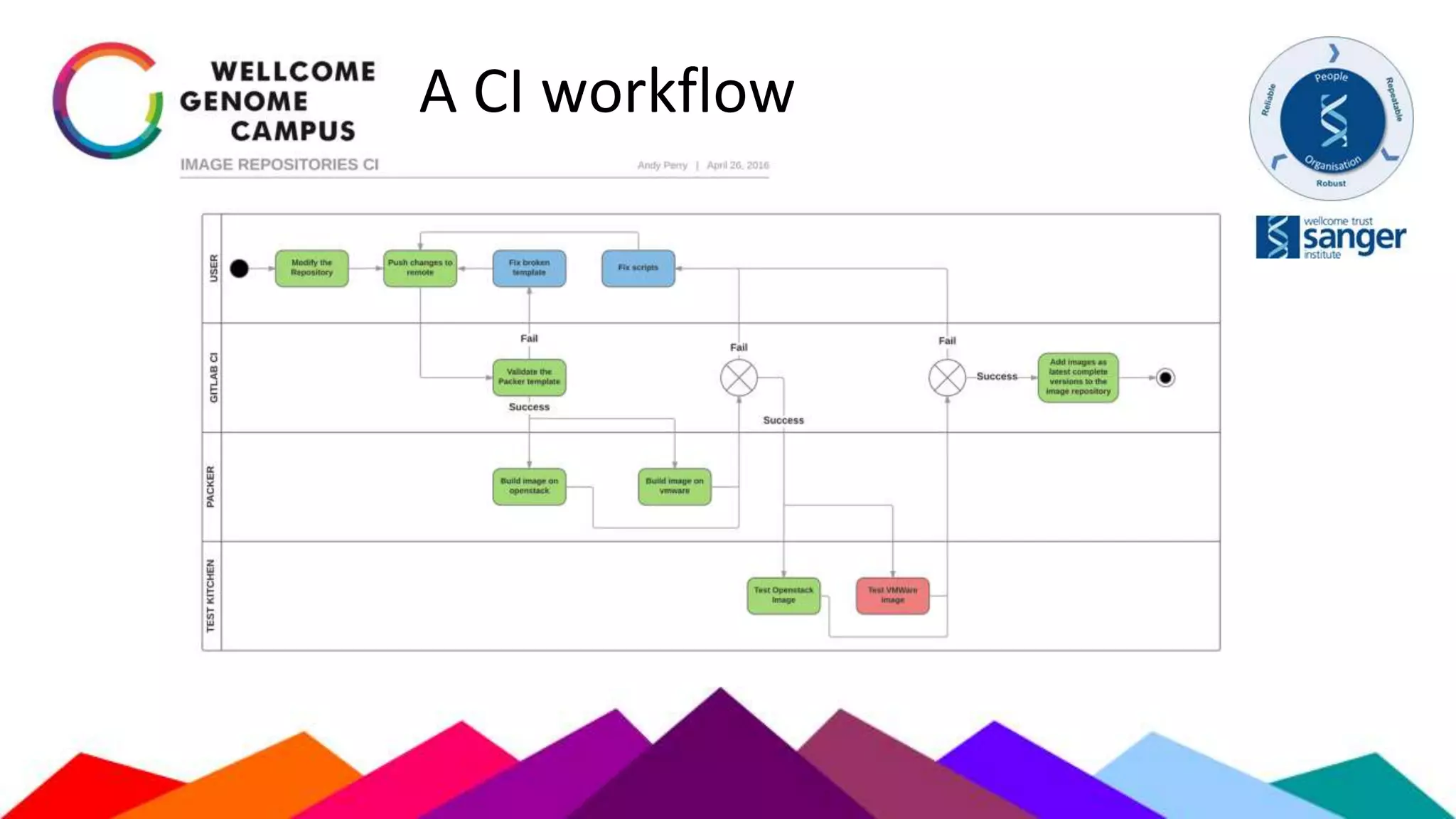










The document outlines Sanger's development and deployment of a flexible compute platform utilizing OpenStack, detailing its architecture, components, and the transition from existing systems. It emphasizes the benefits of a private cloud for resource management, scalability, and application development, while also discussing the planned enhancements and migration strategies. The initiative aims to enable dynamic workflows, improve collaboration, and provide a robust infrastructure for computational needs in genomics research.




















































































