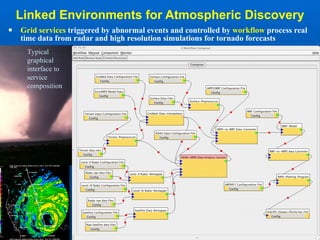
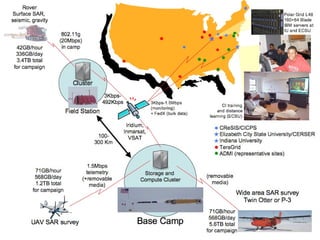
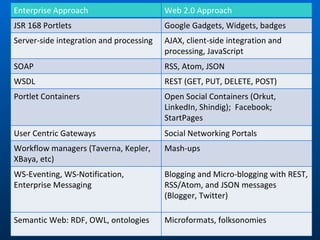
1) Cyberinfrastructure refers to the combination of computing systems, data storage systems, advanced instruments and data repositories, visualization environments, and people that enable knowledge discovery through integrated multi-scale simulations and analyses.
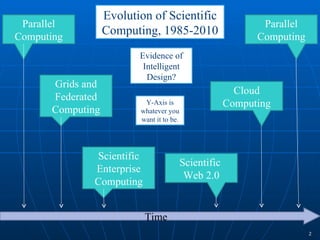
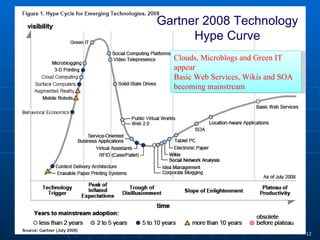
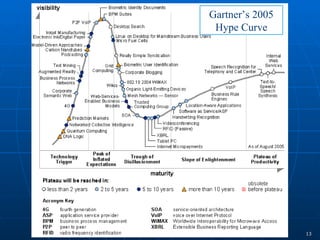
2) Cloud computing, multicore processors, and Web 2.0 tools are changing the landscape of cyberinfrastructure by providing new approaches to distributed computing and data sharing that emphasize usability, collaboration, and accessibility.
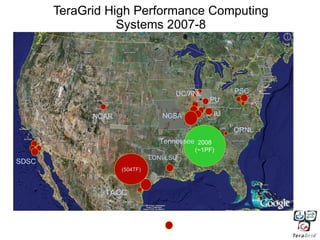
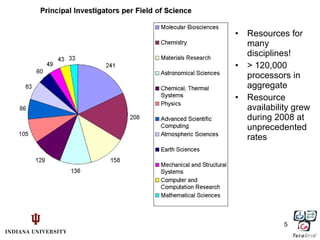
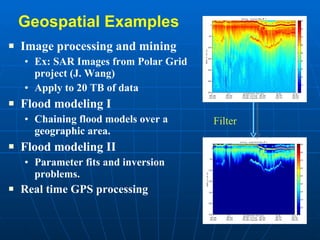
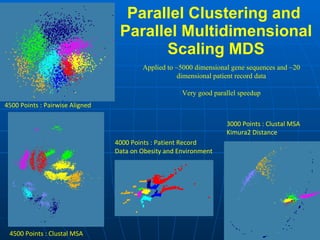
3) Scientific applications are increasingly data-intensive, requiring high-performance computing resources to analyze large datasets from sources like gene sequencers, telescopes, sensors, and web crawlers.
![Overview of Cyberinfrastructure and the Breadth of Its Application Geoffrey Fox Computer Science, Informatics, Physics Chair Informatics Department Director Community Grids Laboratory and Digital Science Center Indiana University Bloomington IN 47404 (Presenter: Marlon Pierce ) [email_address] http://www.infomall.org [email_address]](https://image.slidesharecdn.com/howarduniversityjune22-090622074945-phpapp02/85/Cyberinfrastructure-and-Applications-Overview-Howard-University-June22-1-320.jpg)
![Overview of Cyberinfrastructure and the Breadth of Its Application Geoffrey Fox Computer Science, Informatics, Physics Chair Informatics Department Director Community Grids Laboratory and Digital Science Center Indiana University Bloomington IN 47404 (Presenter: Marlon Pierce ) [email_address] http://www.infomall.org [email_address]](https://image.slidesharecdn.com/howarduniversityjune22-090622074945-phpapp02/75/Cyberinfrastructure-and-Applications-Overview-Howard-University-June22-1-2048.jpg)