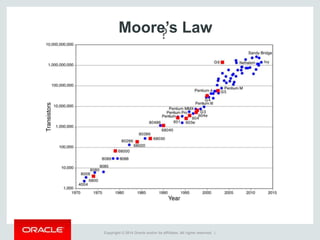
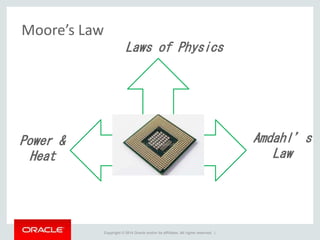
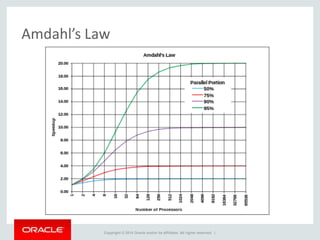
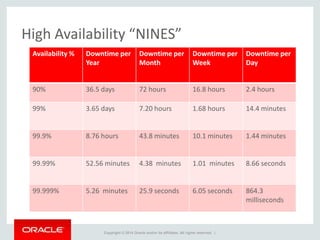
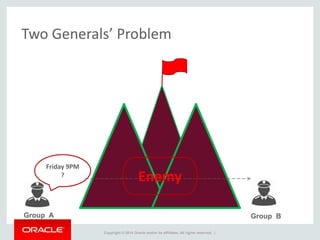
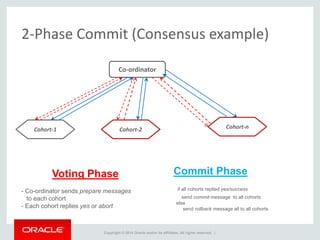
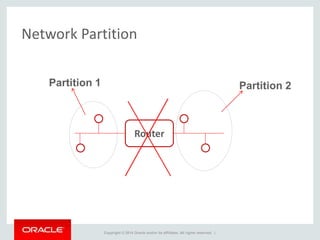
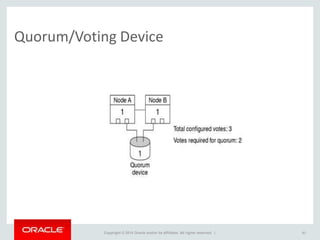
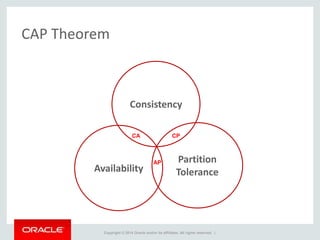
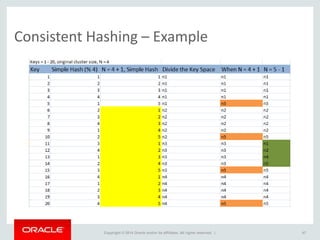
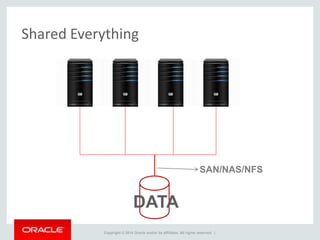
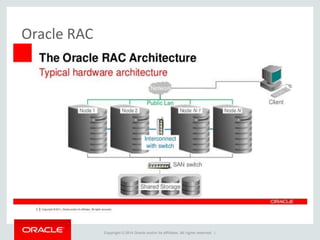
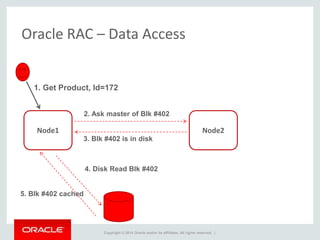
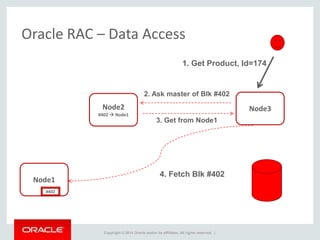
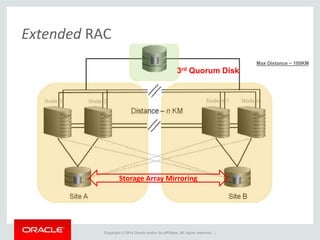
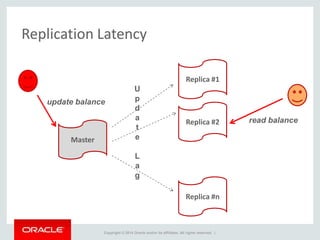
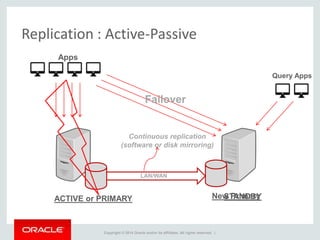
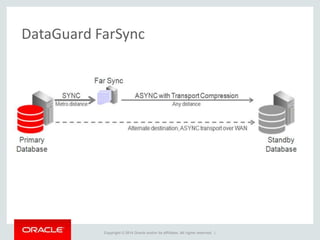
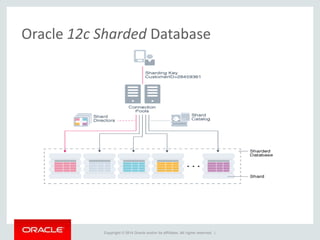
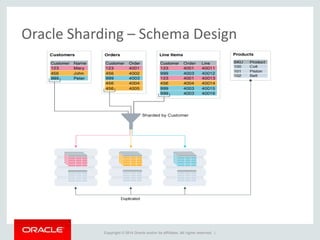
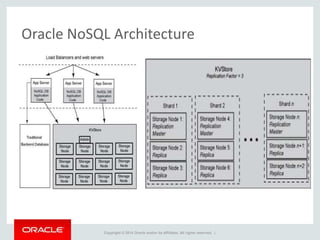
The document provides an overview of distributed databases, focusing on their principles, implementation, and challenges. Key concepts include scalability, high availability, consensus, replication, and various architectures like Oracle RAC and NoSQL. It discusses the CAP theorem, fallacies of distributed computing, and the necessity of robust design against failures in distributed systems.