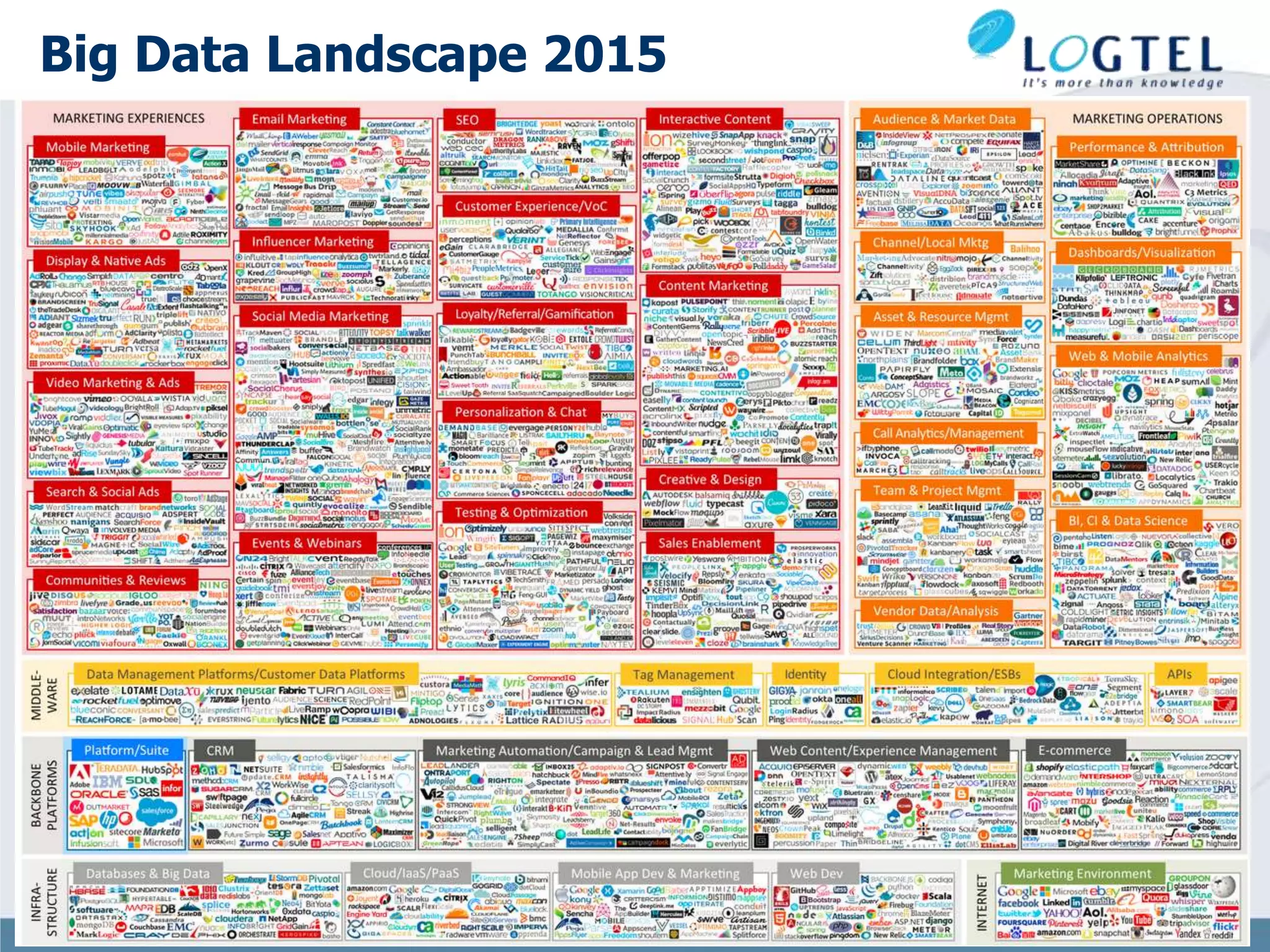
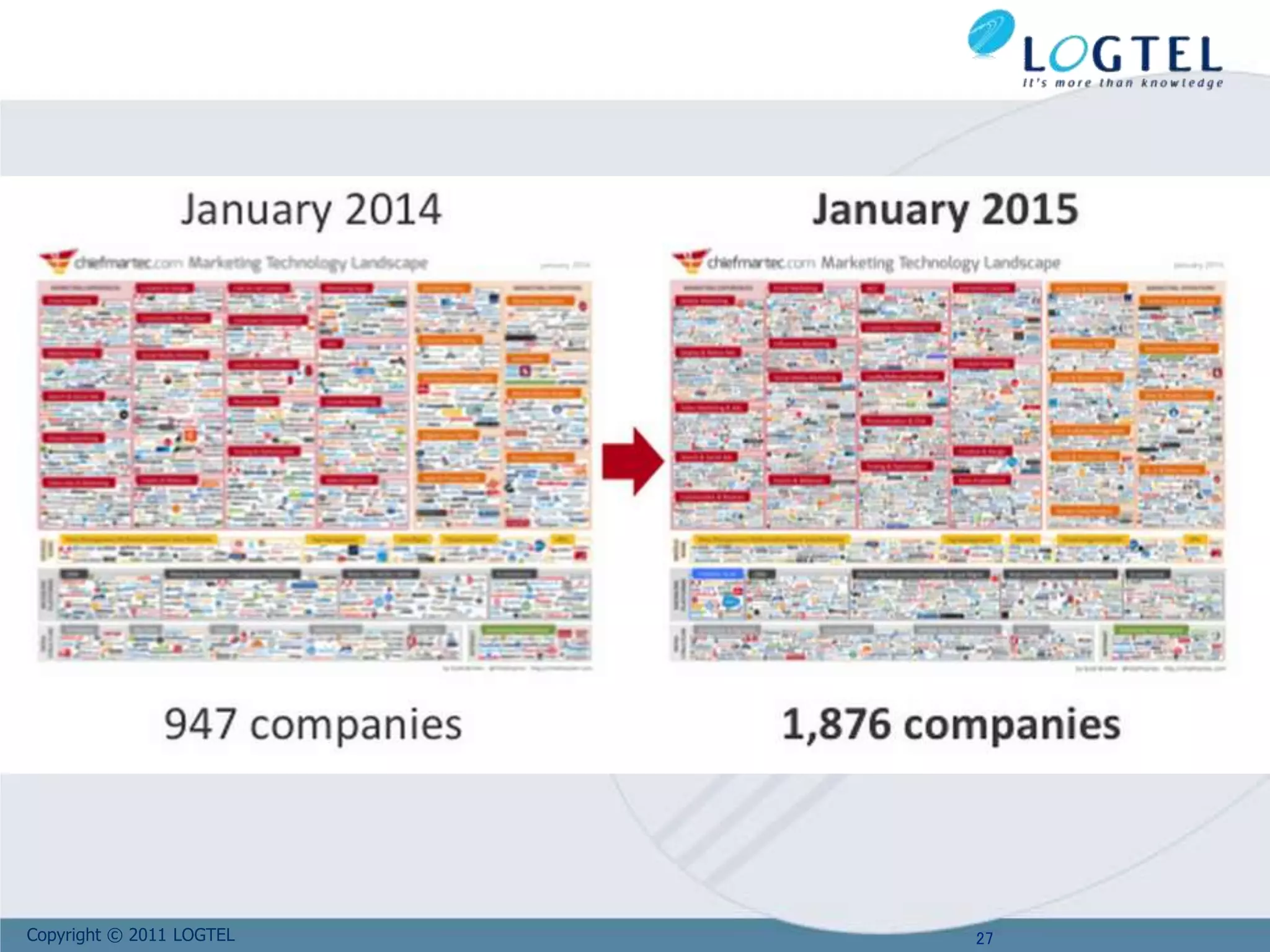
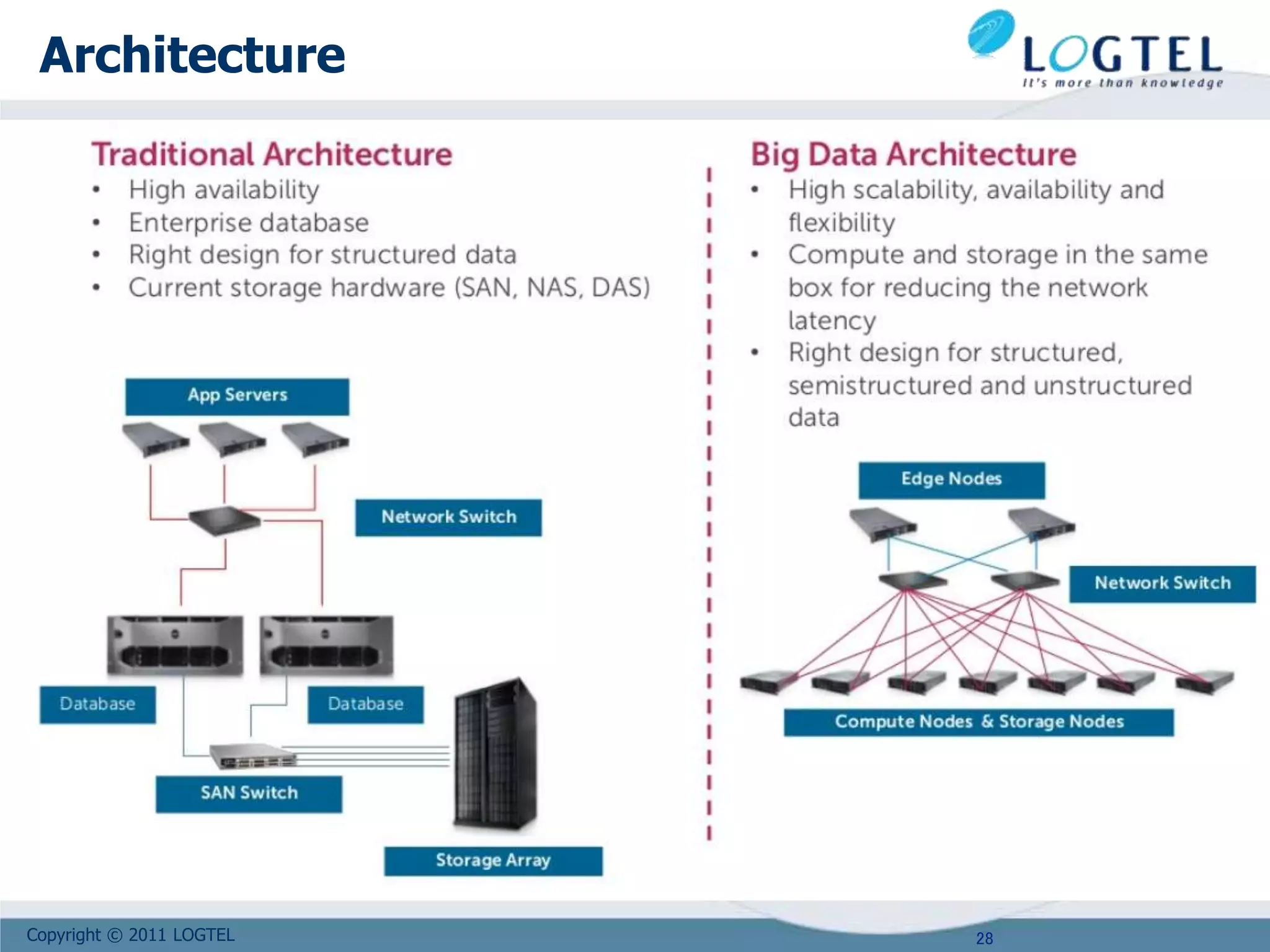
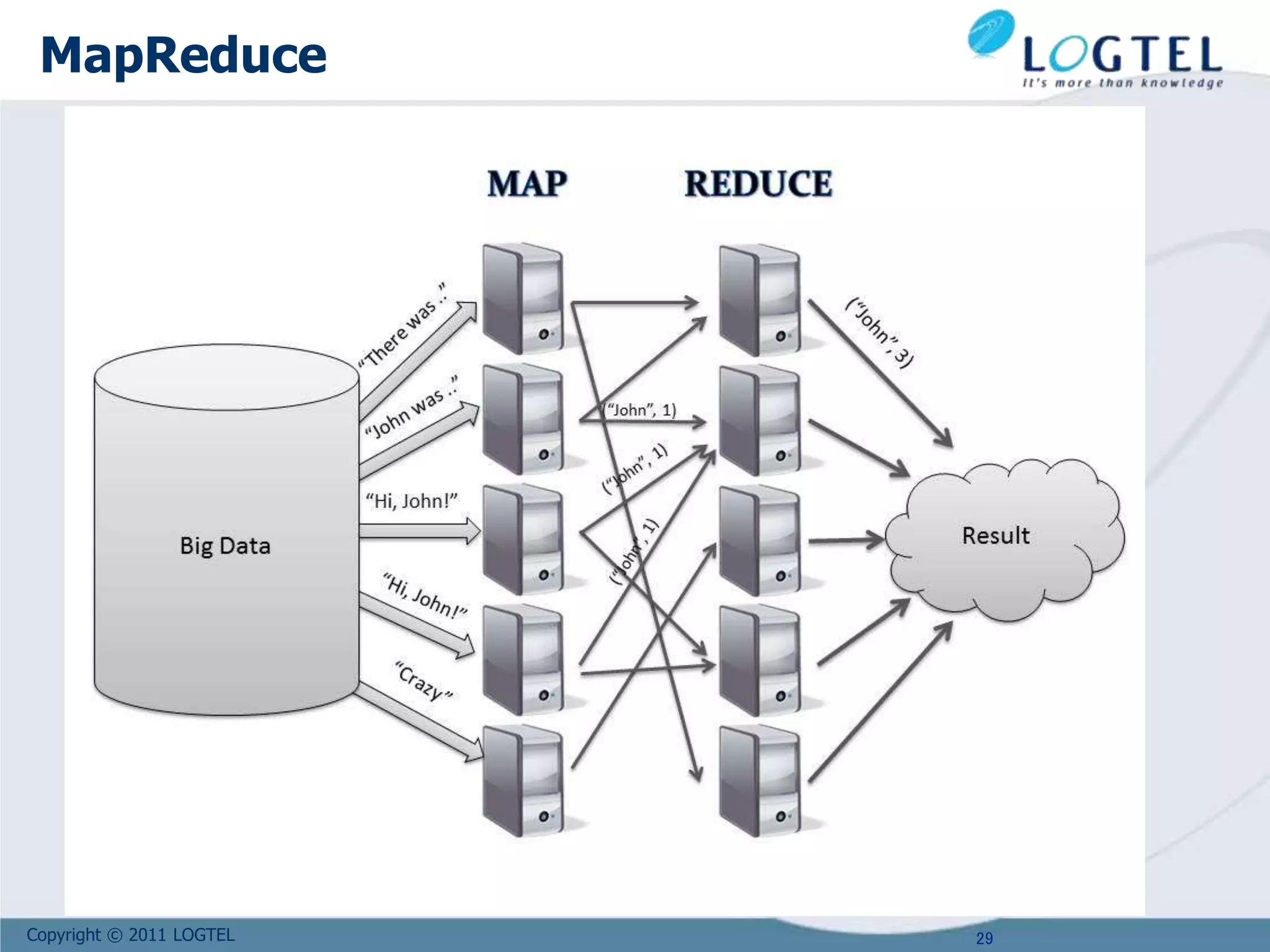
Downloaded 30 times



























![Copyright © 2011 LOGTEL
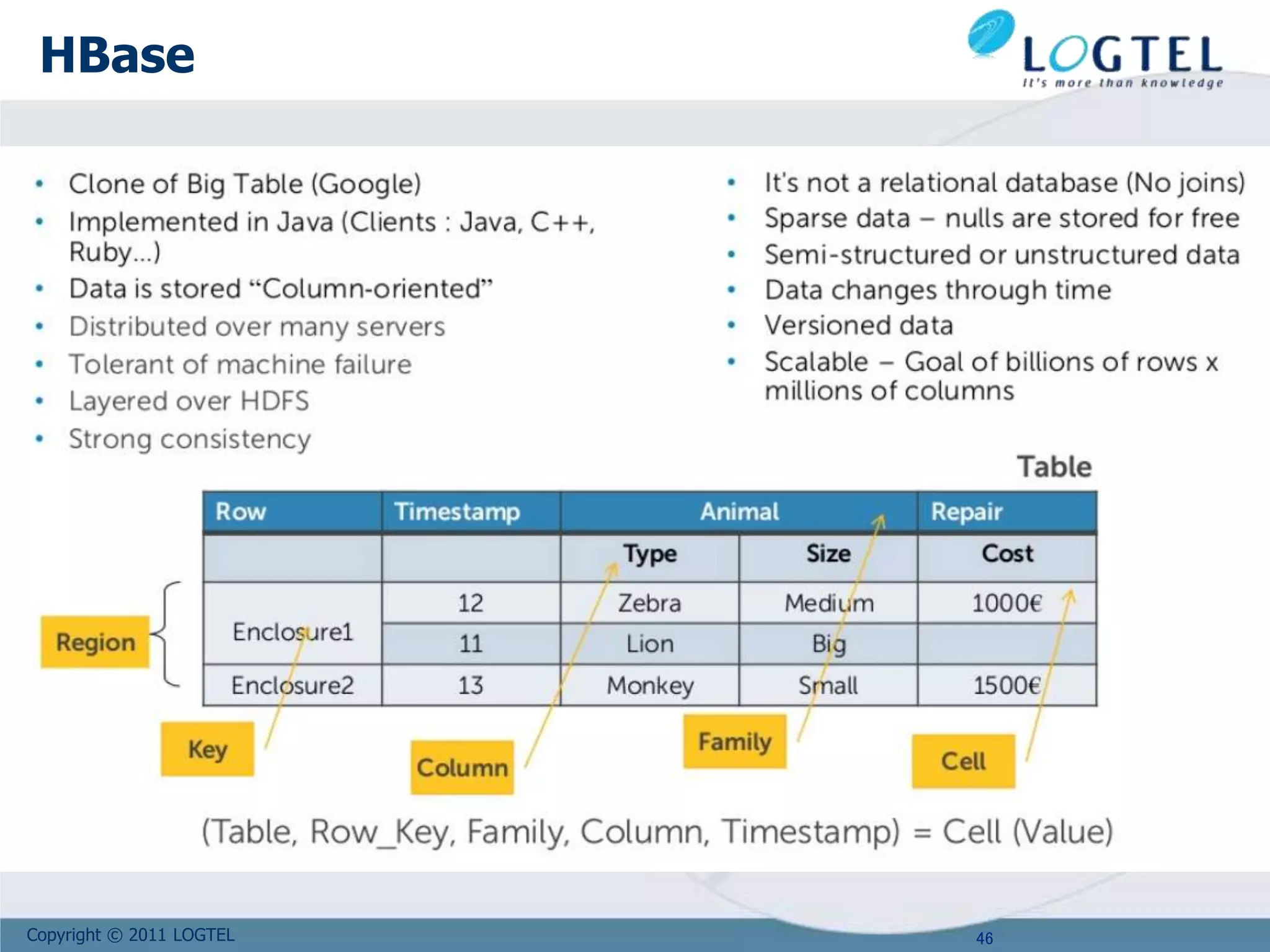
Google
Tables are sorted by Row
Table schema only define its column families .
Each family consists of any number of columns
Each column consists of any number of versions
Columns only exist when inserted, NULLs are free.
Columns within a family are sorted and stored together
Everything except table names are byte[]
(Row, Family: Column, Timestamp) Value
Row key
Column Family
valueTimeStamp](https://image.slidesharecdn.com/bigd4a1015-171017115009/75/Big-Data-NoSQL-1017-47-2048.jpg)





![Copyright © 2011 LOGTEL
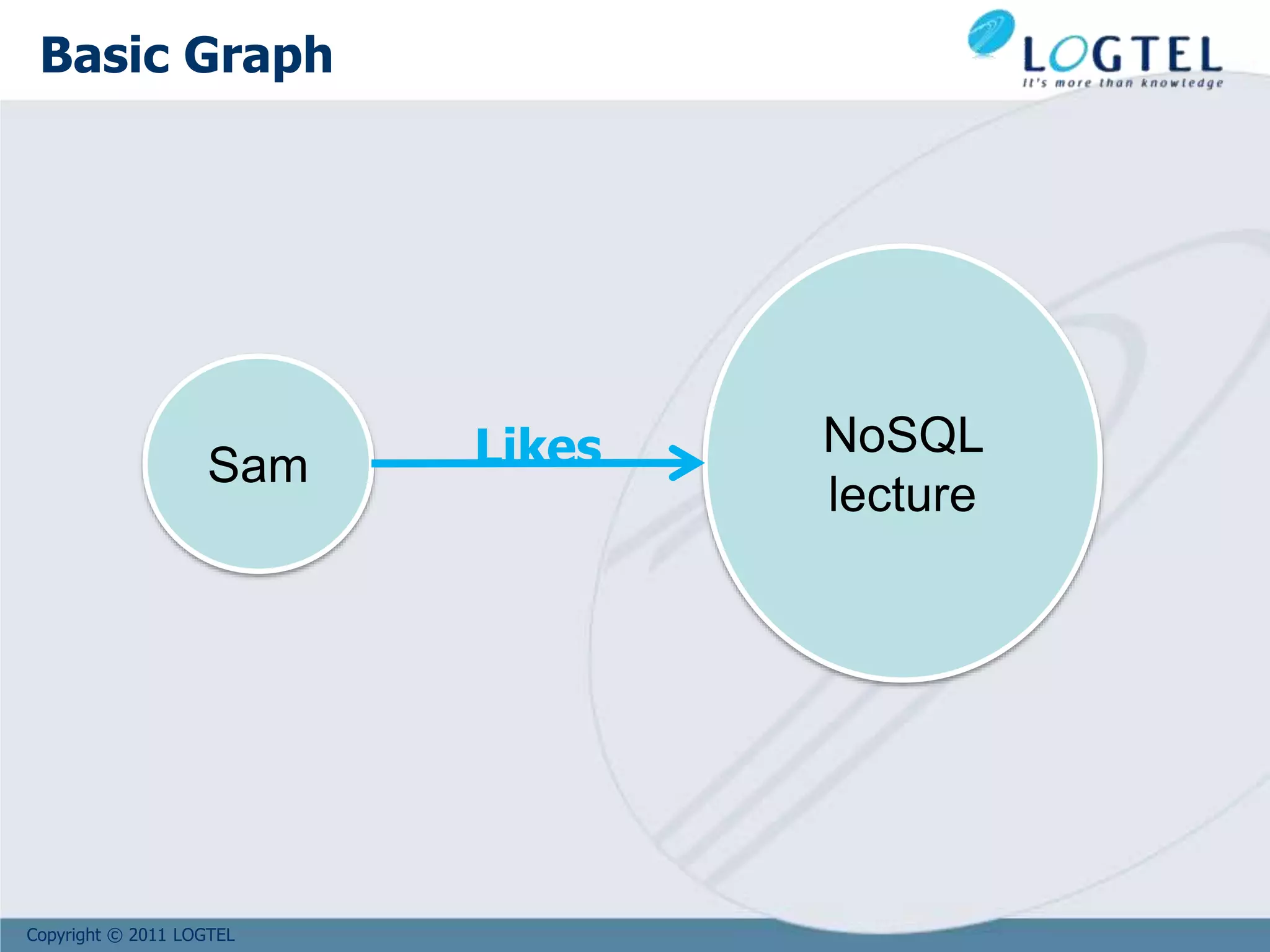
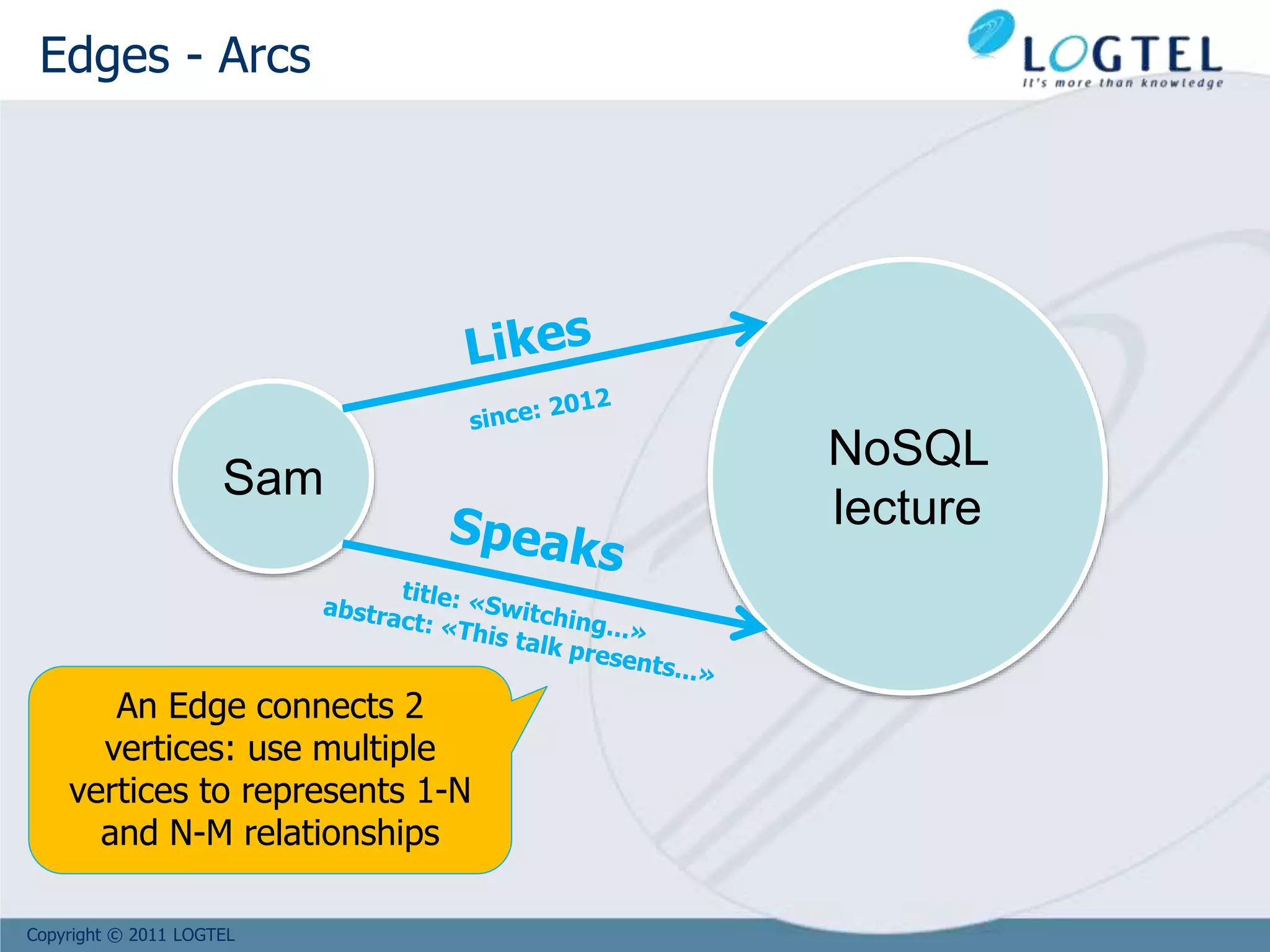
Sam
name: Samuel
surname: Dratwa
company: SADOT
NoSQL
Lecture
editions: [Comverse, Tel-Aviv]
Likes
since: 2012
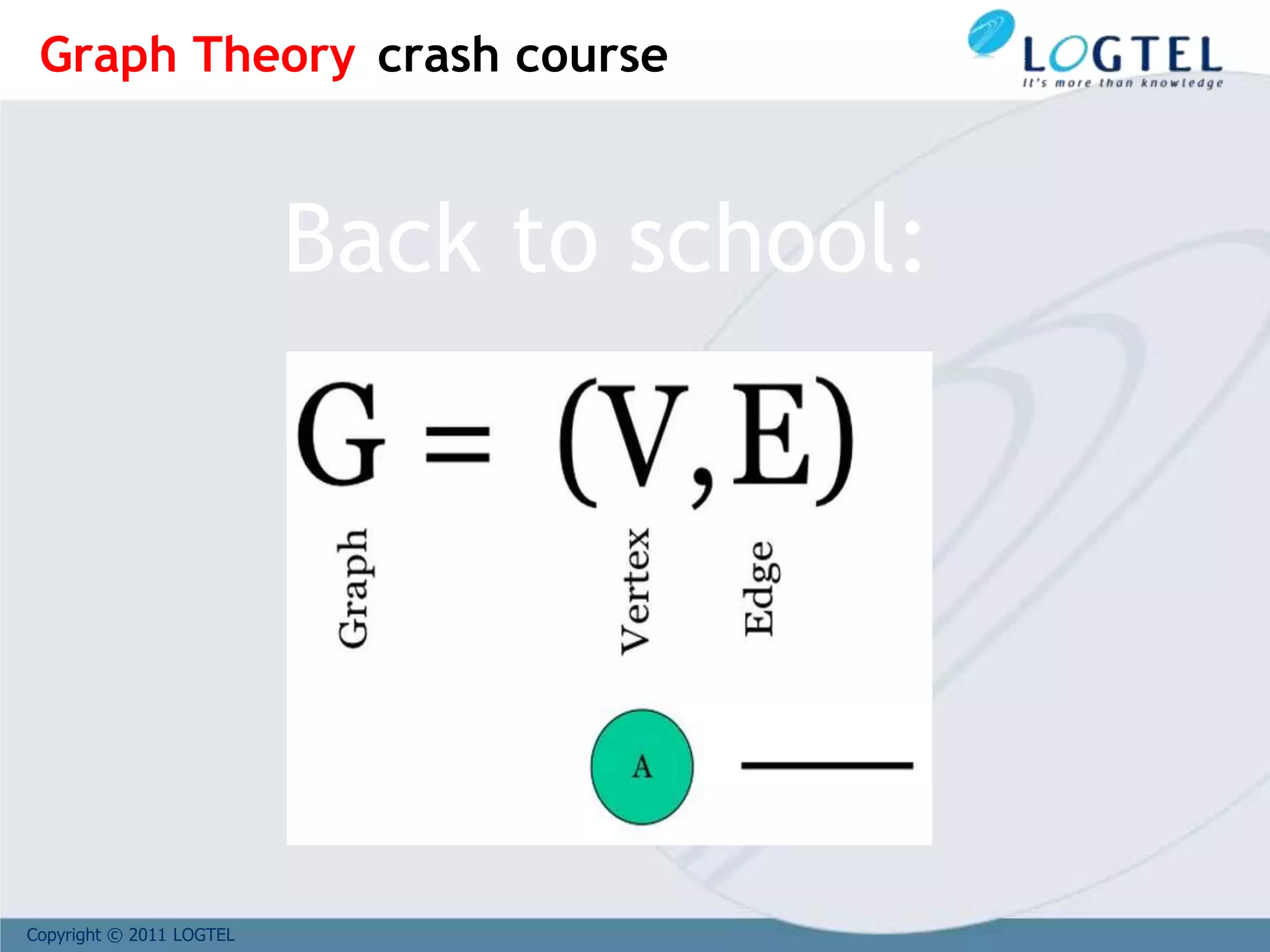
Vertices and Edges
can have
properties
Vertices and Edges
can have
properties
Vertices and Edges
can have
properties
Vertices are
directed
* https://github.com/tinkerpop/blueprints/wiki/Property-Graph-Model
Property Graph Model*](https://image.slidesharecdn.com/bigd4a1015-171017115009/75/Big-Data-NoSQL-1017-58-2048.jpg)








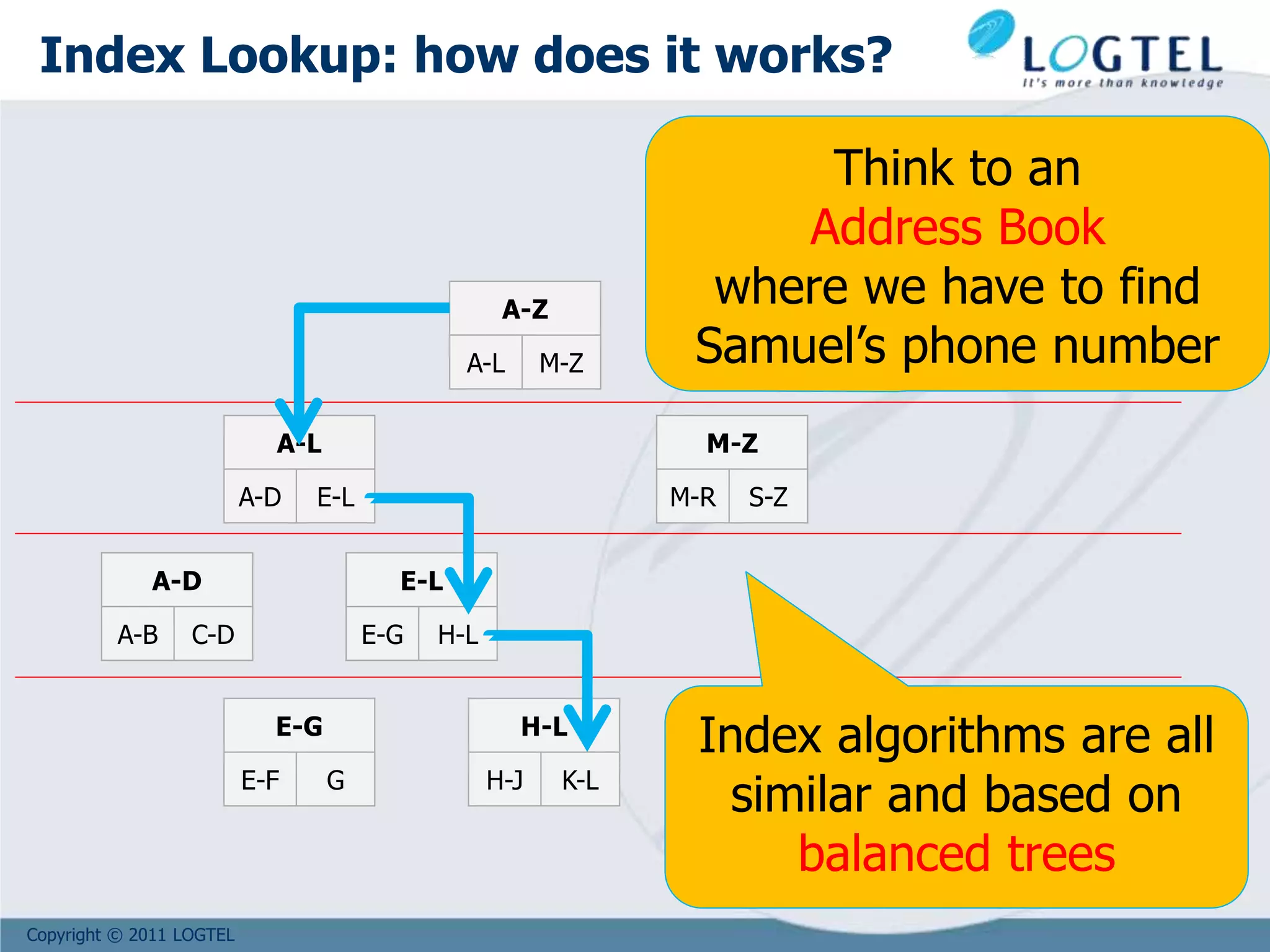
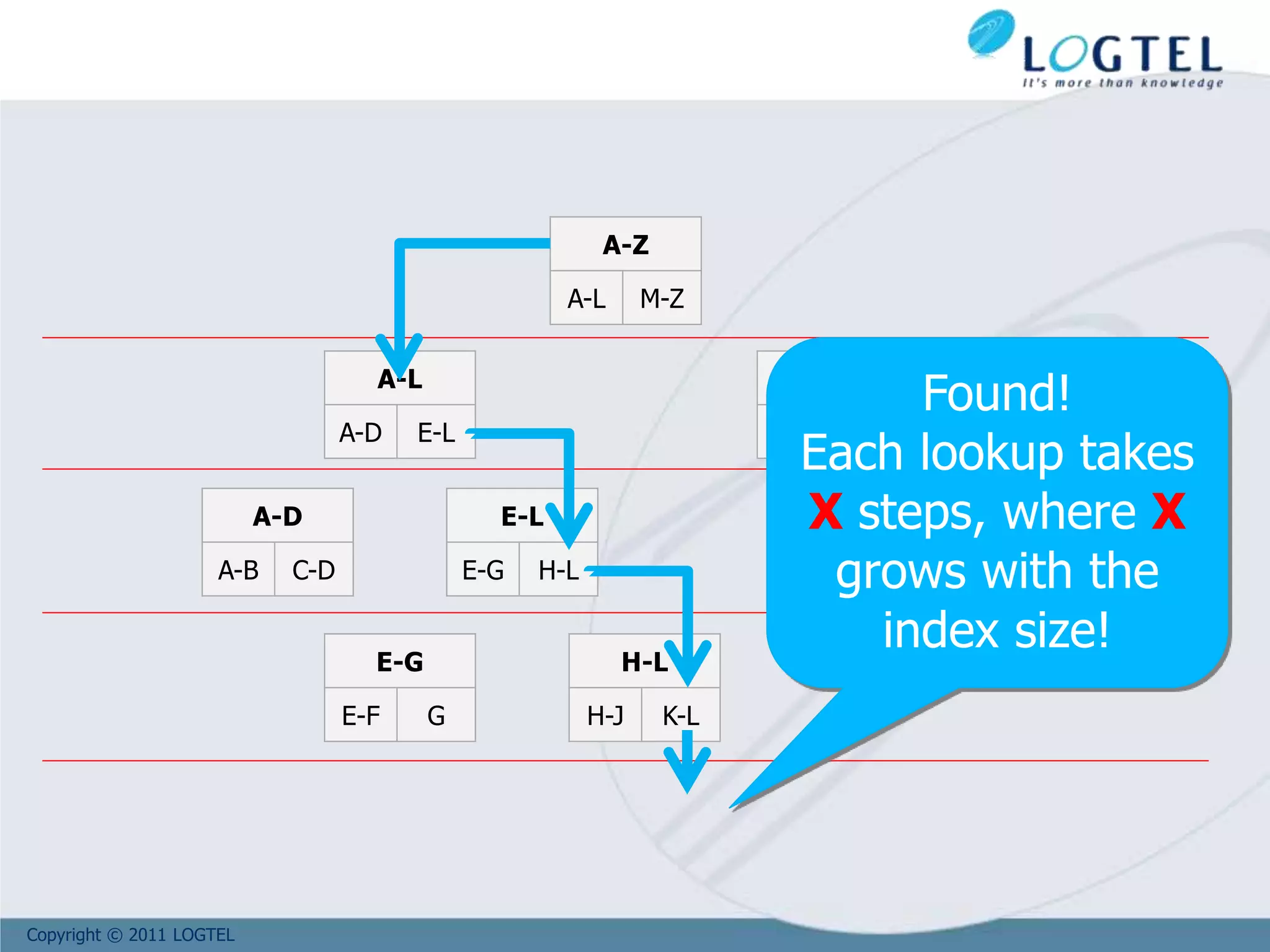




![Copyright © 2011 LOGTEL
Sam
Lives
out : [#14:54]
label : ‘Customer’
name : ‘Sam’
out: [#13:35]
in: [#13:100]
Label : ‘Lives’
RID =
#13:35
RID =
#14:54
RID =
#13:100
in: [#14:54]
label = ‘Address’
name = ‘Rome’
The Record ID (RID)
is a Physical position
Rome
OrientDB: traverse a relationship](https://image.slidesharecdn.com/bigd4a1015-171017115009/75/Big-Data-NoSQL-1017-77-2048.jpg)




![Copyright © 2011 LOGTEL
orientdb> select in[label=‘Lives’].out from V where
label = ‘Address’ and name = ‘Rome’
---+--------+--------------------+--------------------+--------------------+
#| REC ID |label |out |in |
---+--------+--------------------+--------------------+--------------------+
0| 13:35|Sam |[#14:54] | |
---+--------+--------------------+--------------------+--------------------+
1 item(s) found. Query executed in 0.007 sec(s).
orientdb> select * from V where label = ‘Address’ AND
in[label=‘Lives’].size() > 0
---+--------+--------------------+--------------------+--------------------+
#| REC ID |label |out |in |
---+--------+--------------------+--------------------+--------------------+
0| 13:100| Rome | |[#14:54] |
---+--------+--------------------+--------------------+--------------------+
1 item(s) found. Query executed in 0.007 sec(s).
Query the graph in SQL](https://image.slidesharecdn.com/bigd4a1015-171017115009/75/Big-Data-NoSQL-1017-82-2048.jpg)
![Copyright © 2011 LOGTEL
OGraphDatabase graph = new
OGraphDatabase("local:/tmp/db/graph”);
// GET ALL THE THE CUSTOMER FROM ROME, ITALY
List<ODocument> result = graph.command( new OCommandSQL (
“select in[label=‘Lives’].out from V where label = ‘Address’
and name = ?”)
).execute( “Rome”);
for( ODocument v : result ) {
System.out.println(“Result: “ + v.field(“label”) );
}
-----------------------------------------------------------------------------------
----Result: Sam
Query the graph in Java](https://image.slidesharecdn.com/bigd4a1015-171017115009/75/Big-Data-NoSQL-1017-83-2048.jpg)

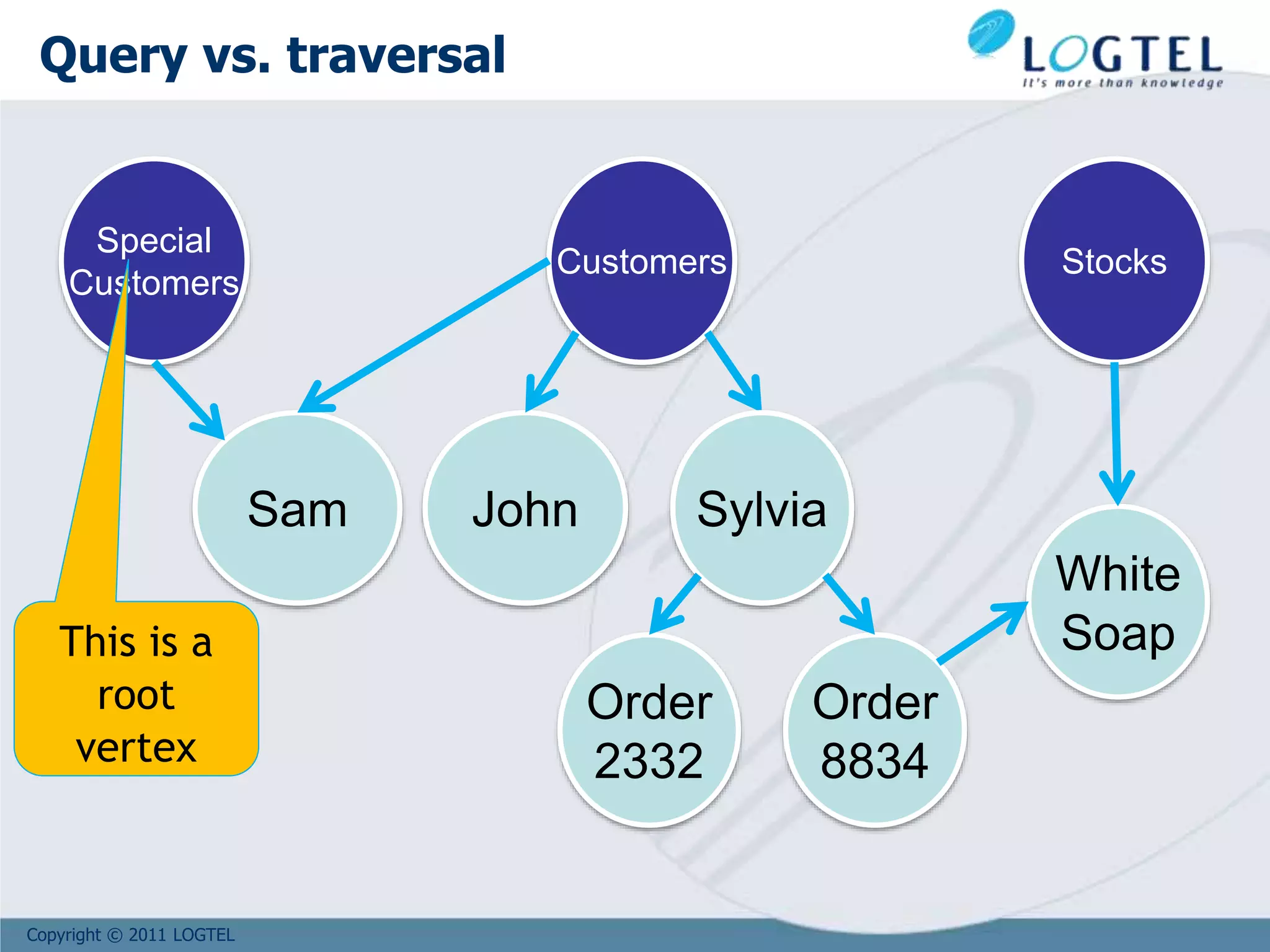
![Copyright © 2011 LOGTEL
Supposing that the root node #30:0 links all the
Customer vertices
Get all the customers:
orientdb> select out.in from #30:0
Get all the customers who bought at least one ‘White Soap’
product:
orientdb> select * from ( select out.in from #30:0) where
out.in.out[label=‘Bought’].in.name = ‘White Soap’
Customers
#30:0
Query the graph in SQL](https://image.slidesharecdn.com/bigd4a1015-171017115009/75/Big-Data-NoSQL-1017-86-2048.jpg)
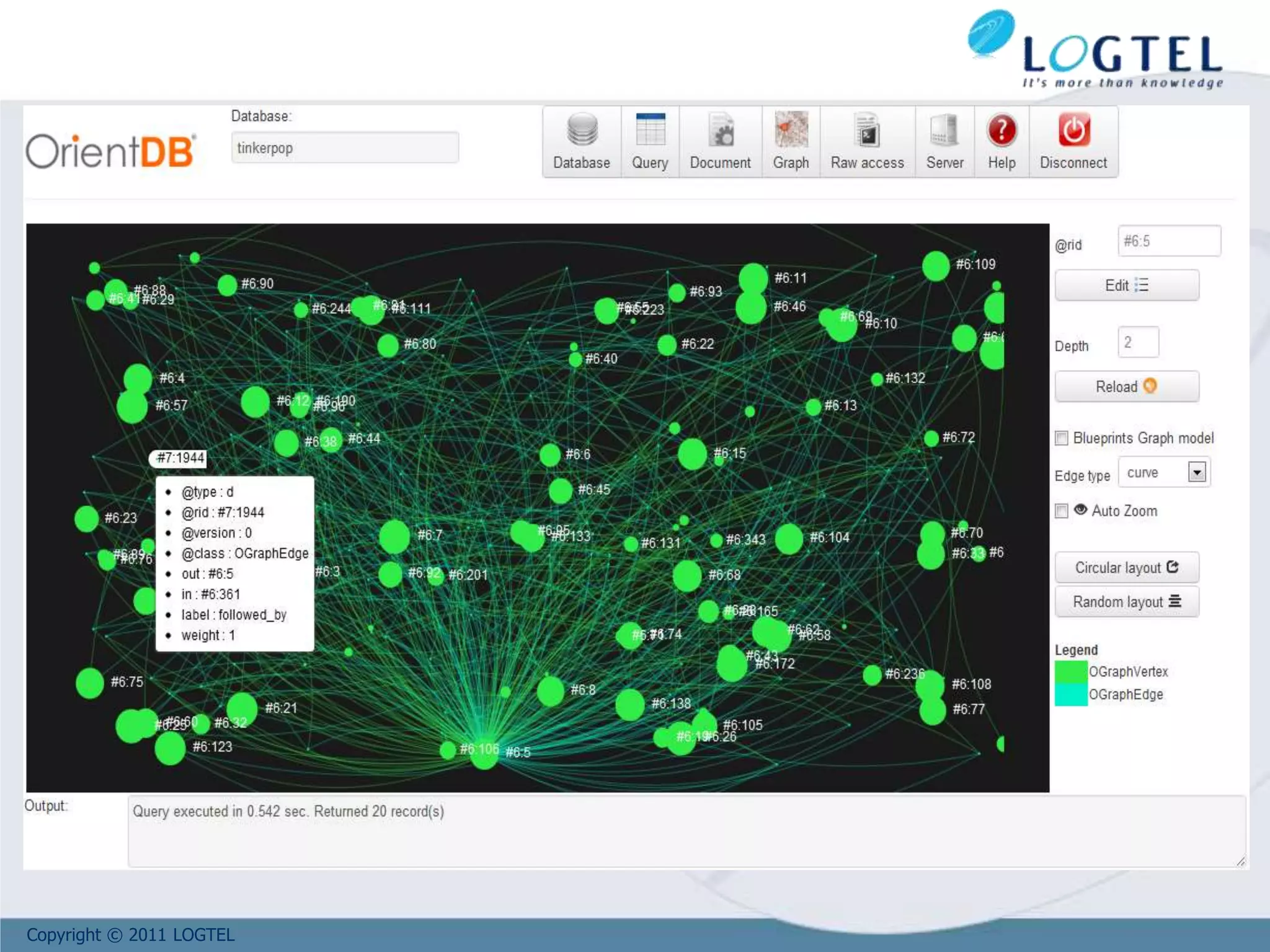













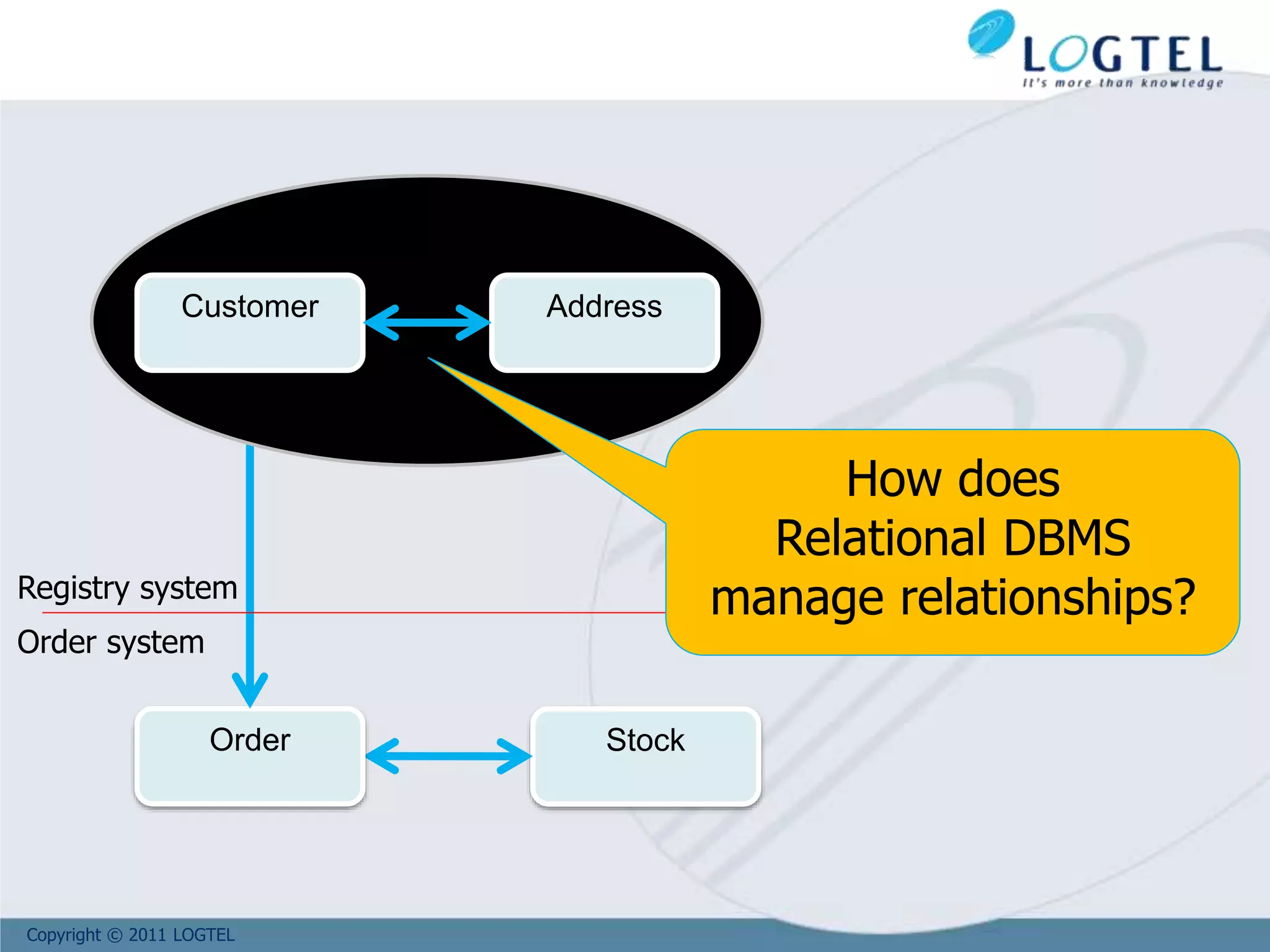
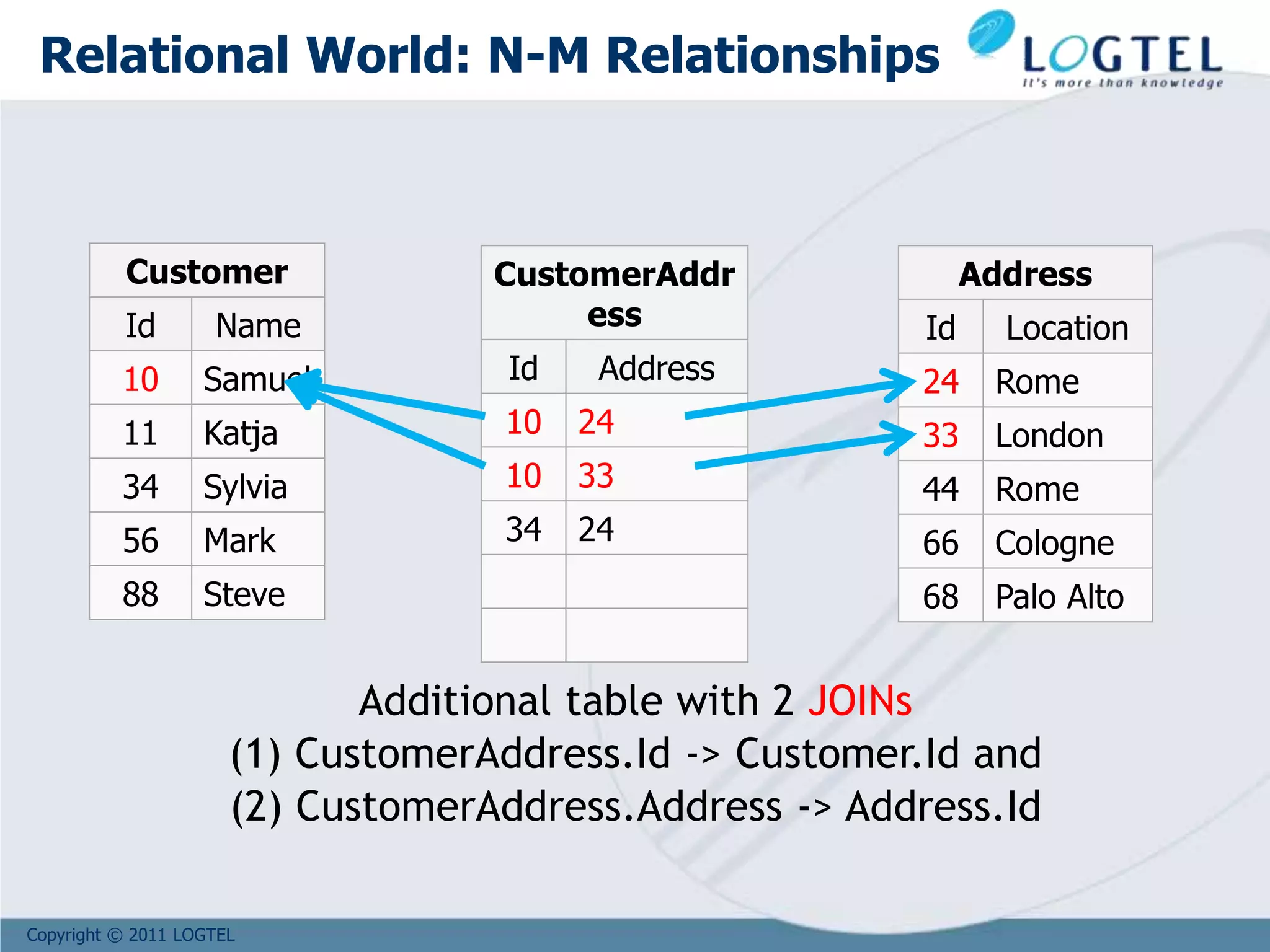
The document provides an overview of NoSQL and big data technologies. It begins with defining big data and the challenges it poses that require new techniques compared to traditional databases. It then discusses the CAP theorem and how NoSQL databases sacrifice consistency or availability to achieve scalability. The document outlines several NoSQL data models and examples like key-value, columnar, document and graph databases. It also discusses distributed systems like BigTable, HBase and PNUTS. Finally, it provides an example of how graph databases can model relationships compared to the need for joins in relational databases.




























































![[DSC Europe 25] Dusan Nesic - Securing Tomorrow’s Infrastructure: Why Cyber-P...](https://cdn.slidesharecdn.com/ss_thumbnails/qikbszfftyowjm2q6duw-1-251211083848-8f2ead6b-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Milan Zdravkovic - The road less traveled in District Heating...](https://cdn.slidesharecdn.com/ss_thumbnails/nfaboniqwsz4ucyctnmy-2-milan-zdravkovic-dsc2025-the-road-less-traveled-in-district-heating-operation-251208151905-f56388a5-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DSC Europe 25] Aleksandra Dragicevic - AI-Boosted Research in Healthcare: Fr...](https://cdn.slidesharecdn.com/ss_thumbnails/iqwngszurf2r7pi1lnnj-4-aleksandra-dragicevic-ad-dsc-europe-conference-20-251208151905-37c3238a-thumbnail.jpg?width=640&height=640&fit=bounds)



![[DSC Europe 25] Milan Sekuloski - Data, Defence, and Development: Cybersecuri...](https://cdn.slidesharecdn.com/ss_thumbnails/dfrkwwx4qly6atqpbl4z-4-251209104645-c3d4b0ca-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DSC Europe 25] Sara Polak - The Archaeology of Innovation: AI as the Next Cr...](https://cdn.slidesharecdn.com/ss_thumbnails/7ecbscdnt8mlcuqbd2ln-2-sara-polak-ai-creative-industries-251208152533-aa1fcf54-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Kaja Kandare - LLM as a judge.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/arxyccaxsdsd1ba99wjw-7-251212104007-2b4e3f64-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DSC Europe 25] Jon Dajci - Bridging TradFi and DeFi: Building the Future of ...](https://cdn.slidesharecdn.com/ss_thumbnails/fqmhfvlbqhkihjvqvhmu-7-251211083849-6af7e325-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DSC Europe 25] Dragana Ilic - AI for Big Data in Astronomy.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/8palya86qaatvjhva1ms-2-dragana-ilic-ai-ilic-251208151906-652b819c-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DSC Europe 25] Marko Krstic - Understanding the AI Threat Landscape - Risks,...](https://cdn.slidesharecdn.com/ss_thumbnails/tiyim1ins5jvbrvzpzla-2-251209104645-c69d3553-thumbnail.jpg?width=640&height=640&fit=bounds)