Downloaded 25 times




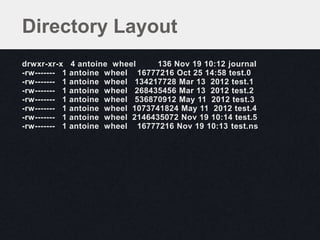



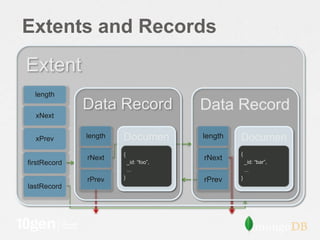










![Journal Format
JHeader • Section contains single group
JSectHeader [LSN commit
3] • Applied all-or-nothing
DurOp
DurOp Set database context
Op_DbContext
for subsequent
DurOp length operations
JSectFooter offset
fileNo
JSectHeader [LSN
data[length]
7]
length
DurOp Write
offset
DurOp fileNo Operation
data[length]
DurOp length
JSectFooter offset
fileNo
… data[length]](https://image.slidesharecdn.com/2-28understandingstorage-130301165145-phpapp02/85/Webinar-Understanding-Storage-for-Performance-and-Data-Safety-26-320.jpg)








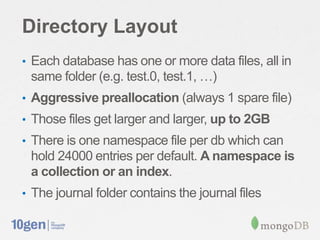
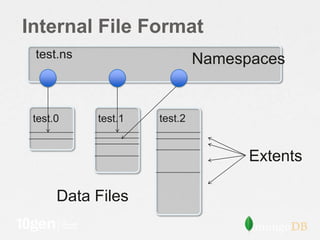
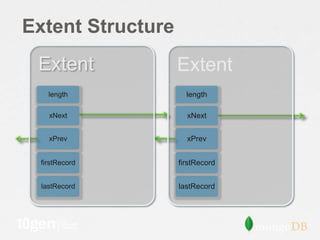
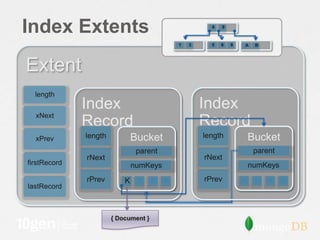
The document discusses strategies for optimizing storage performance and data safety, focusing on data file organization and options for tuning storage systems. It outlines the importance of memory mapping, journaling for data durability, and managing fragmentation. Additionally, it provides insights into database statistics and configuration recommendations to enhance efficiency and minimize the risk of data loss.

































































![MongoDB .local San Francisco 2020: Powering the new age data demands [Infosys]](https://cdn.slidesharecdn.com/ss_thumbnails/315pminfosysfinalsfoversionvocalpart1-200120221508-thumbnail.jpg?width=640&height=640&fit=bounds)































