Download as PDF, PPTX














![HBase - Data Model Operations
○
○
HTable class offers 4 techniques: get, put, delete and scan.
The first 3 have a single or batch mode available
//Scan example
public static final byte[] CF1 = "empData1".getBytes();
public static final byte[] ATTR1 = "empId".getBytes();
HTable htable = new HTable(blah... // create an instance of HTable
Scan scan = new Scan();
scan.addColumn(CF1, ATTR1);
scan.setStartRow(Bytes.toBytes("200"));
scan.setStopRow(Bytes.toBytes("500"));
ResultScanner rs = htable.getScanner(scan);
try {
for (Result r = rs.next(); r != null; r = rs.next()) {
// do something with it...
} finally {
rs.close();
}](https://image.slidesharecdn.com/storageforbigdata-140207132641-phpapp01/75/Storage-Systems-for-big-data-HDFS-HBase-and-intro-to-KV-Store-Redis-33-2048.jpg)





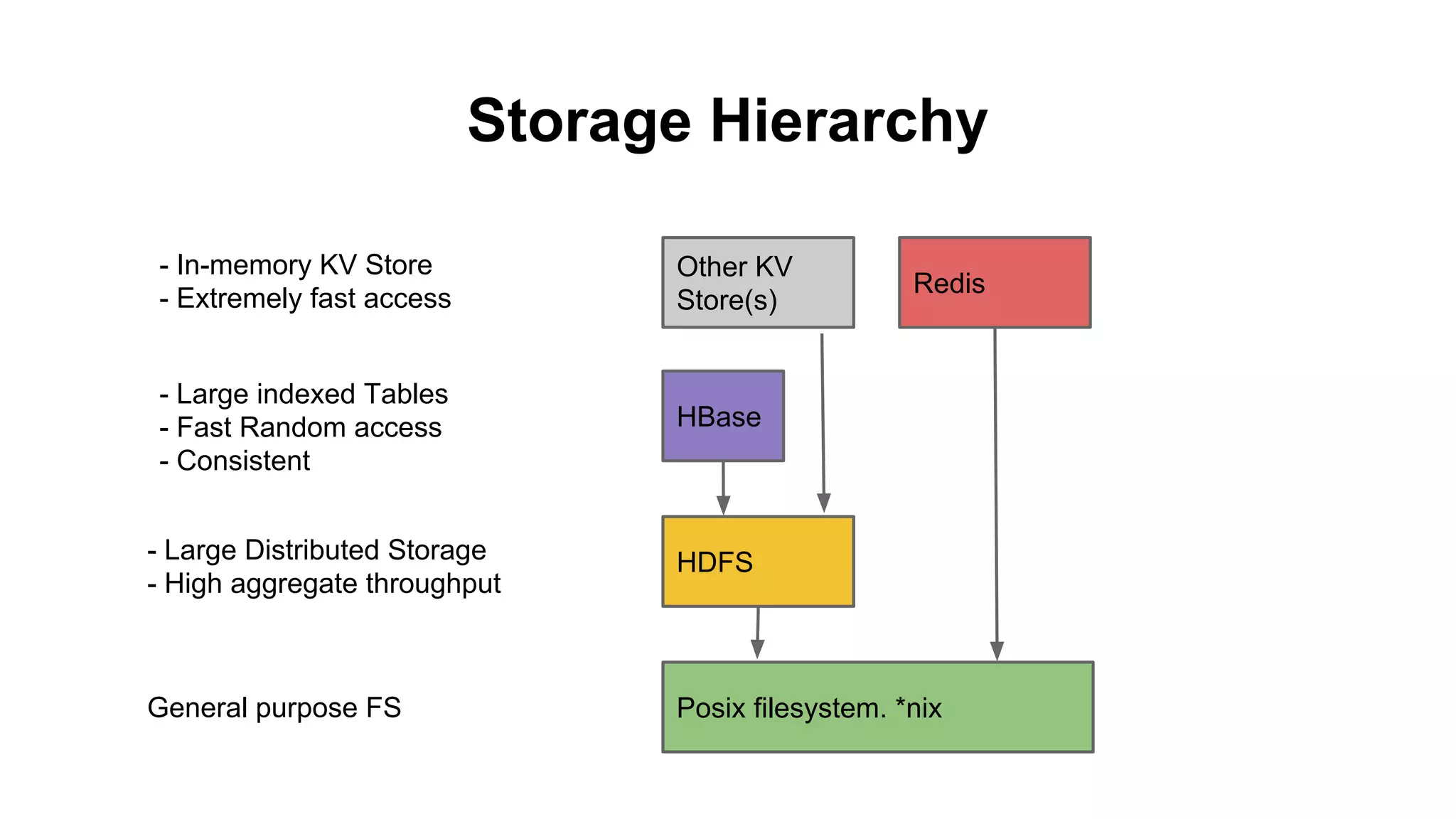
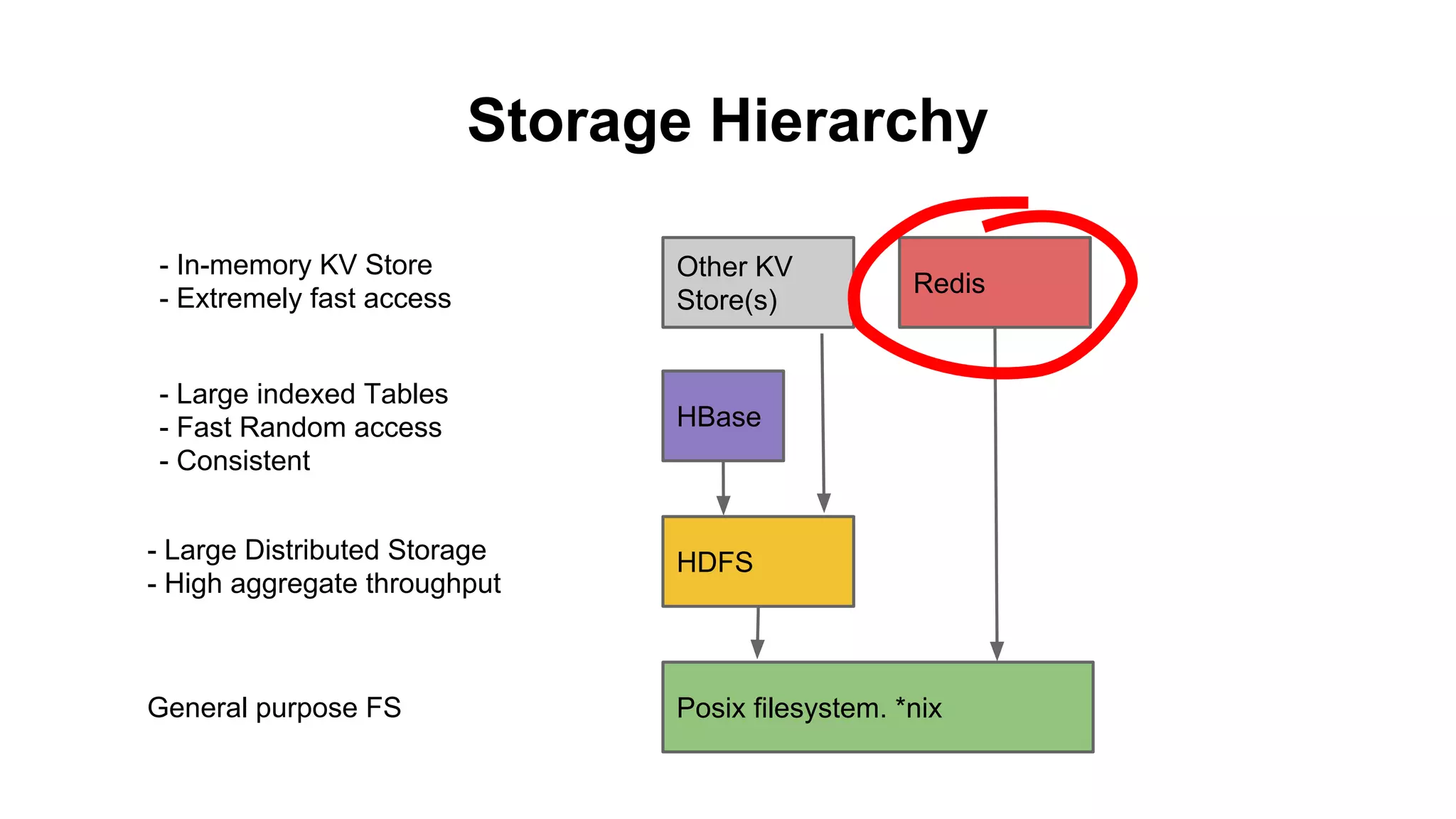

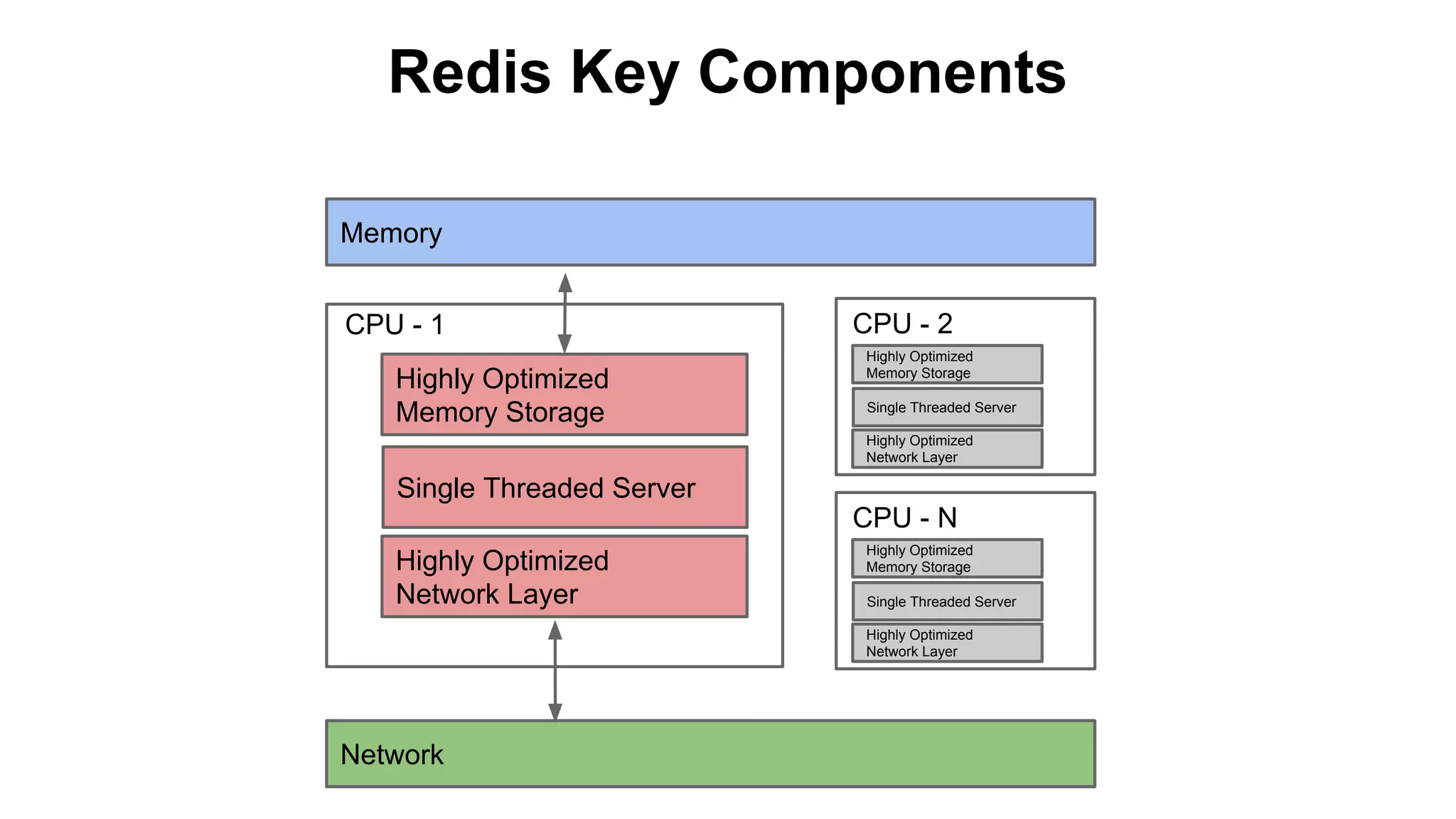
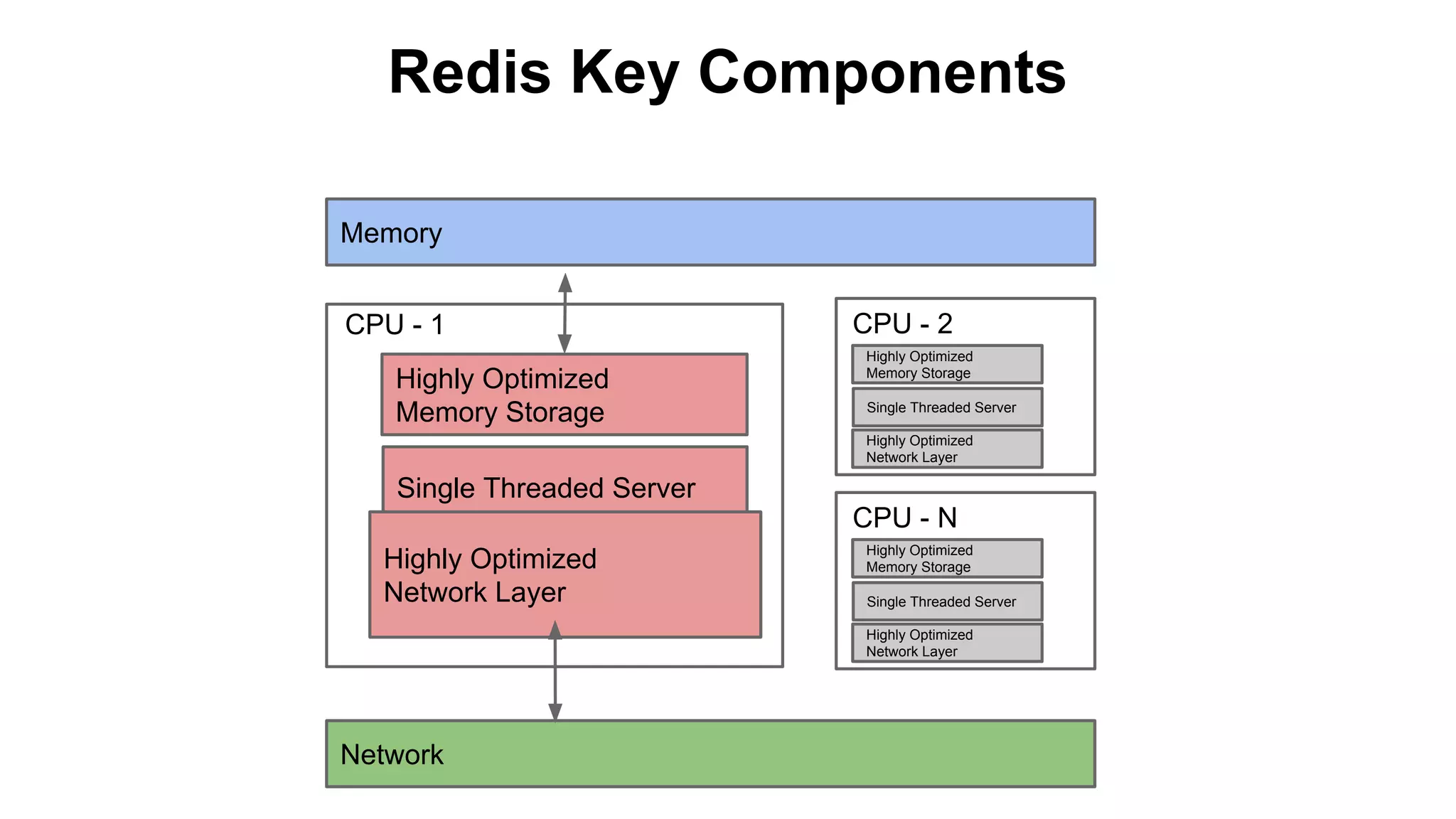
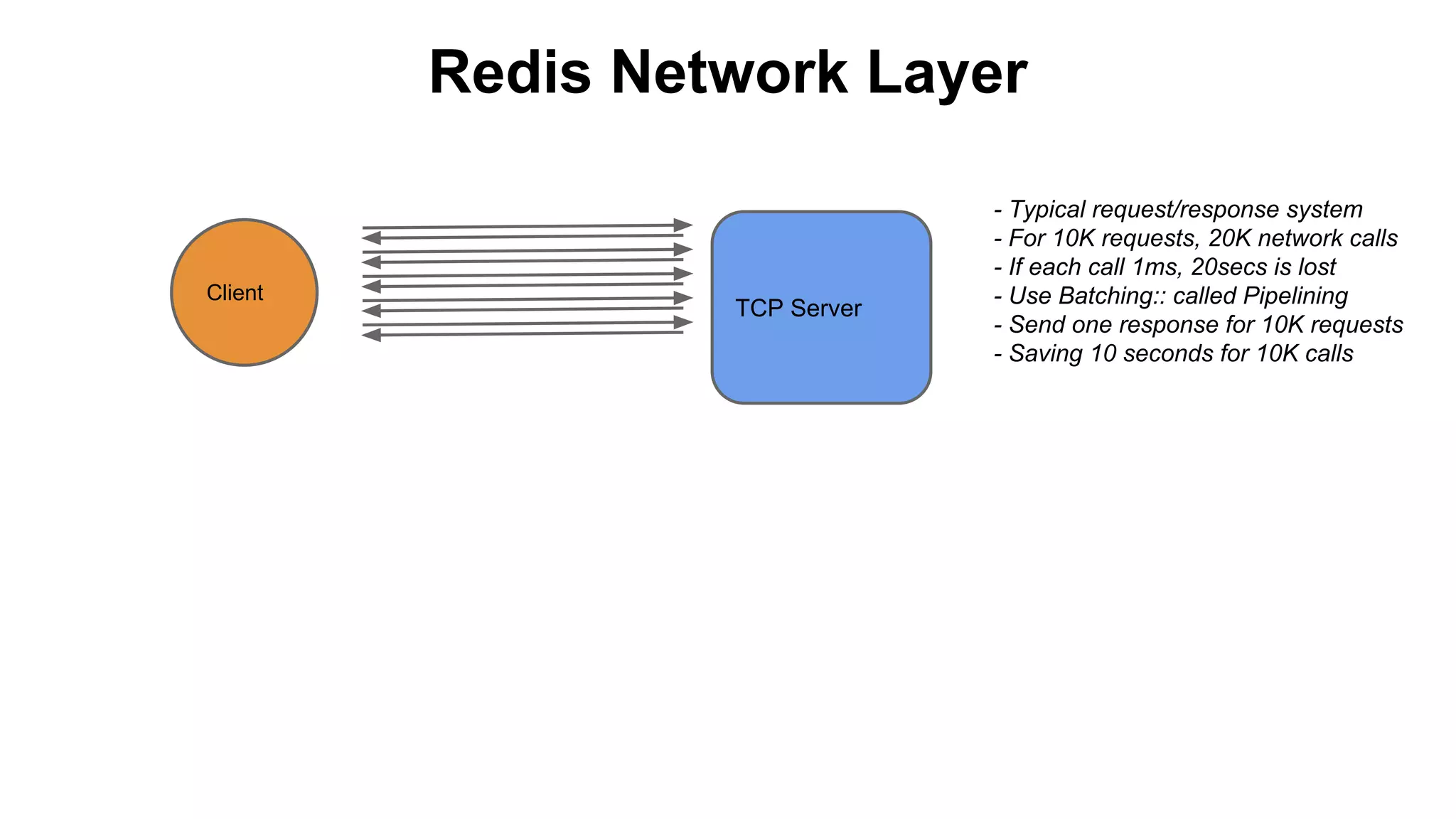
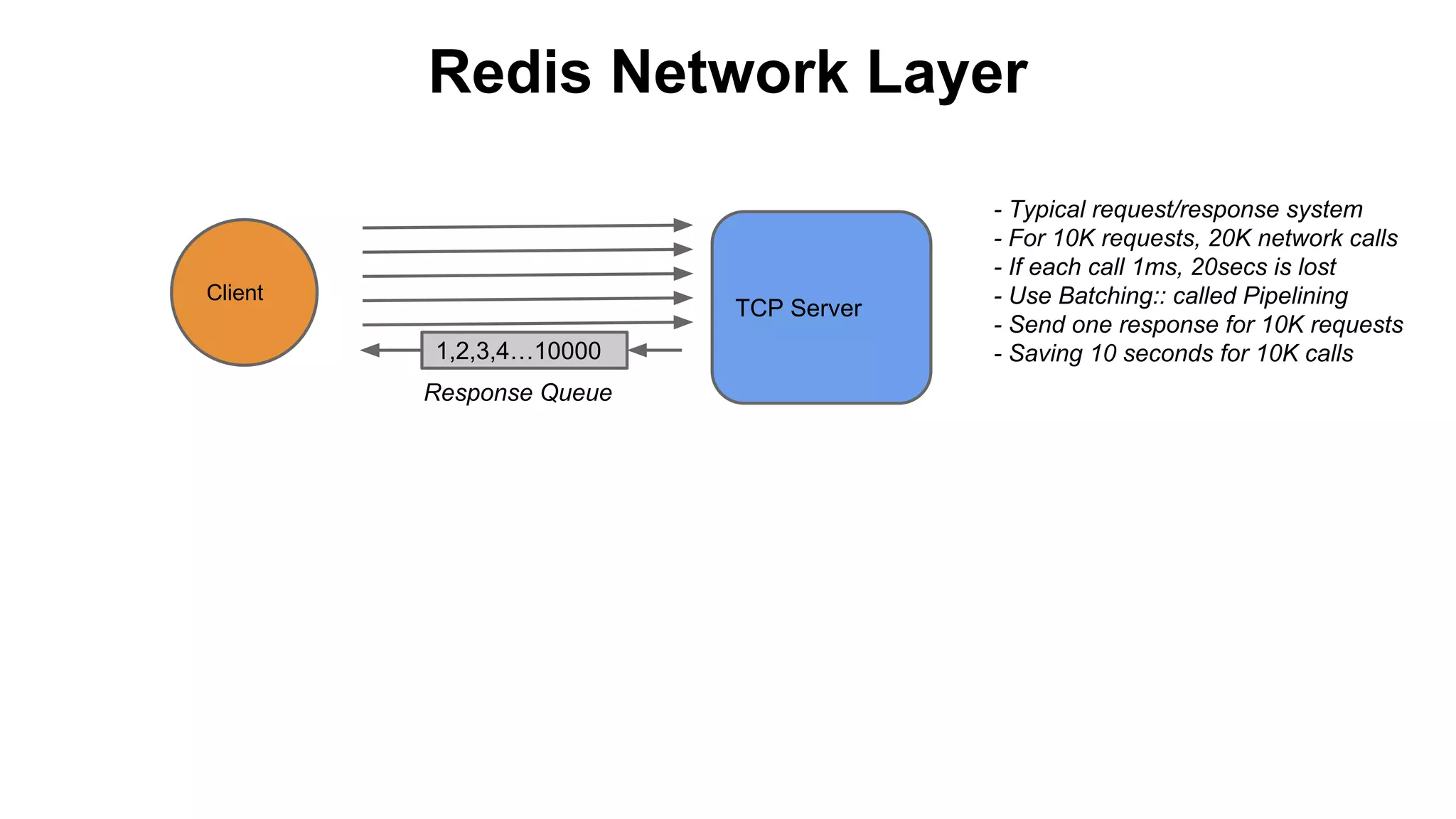
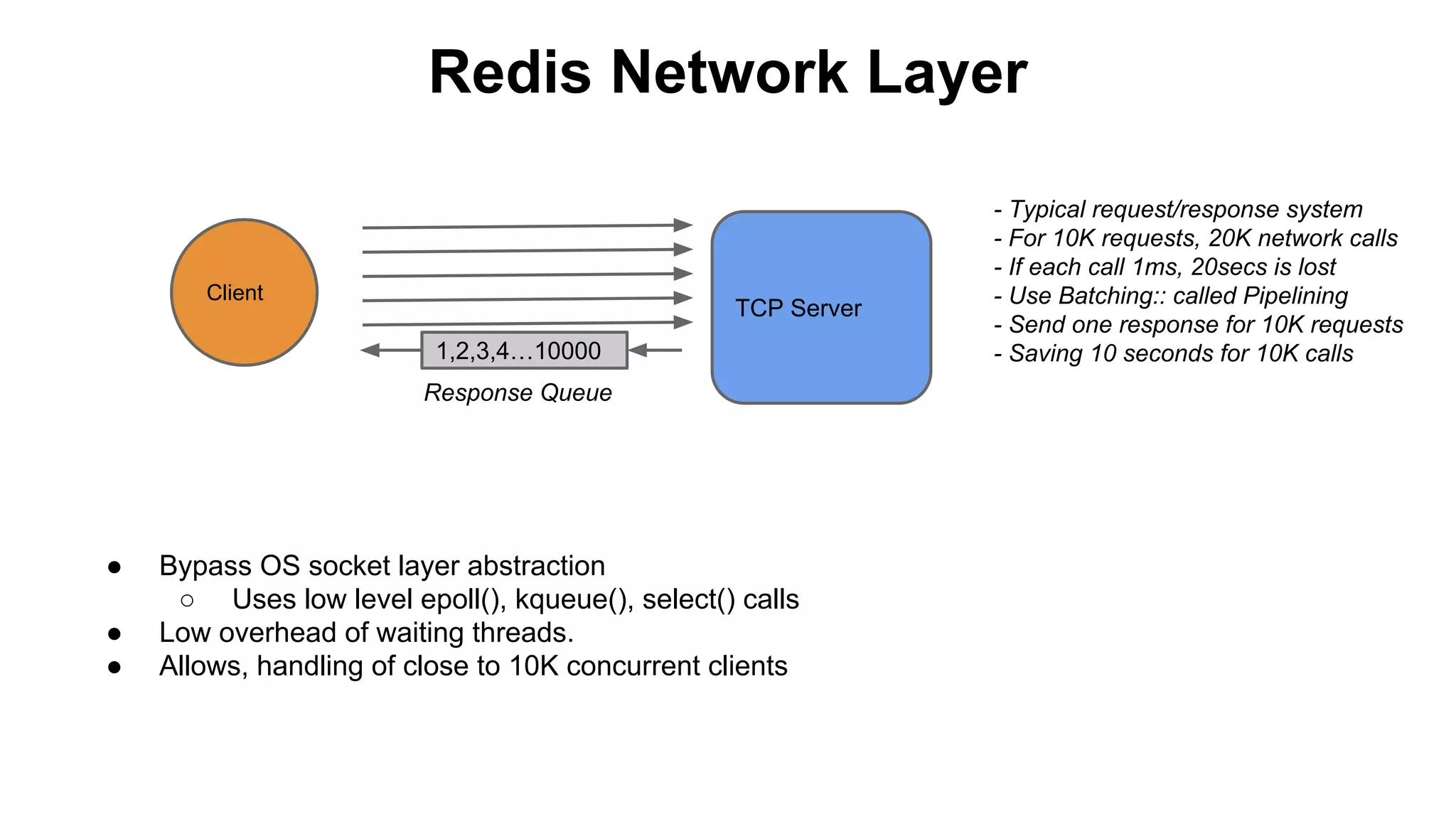

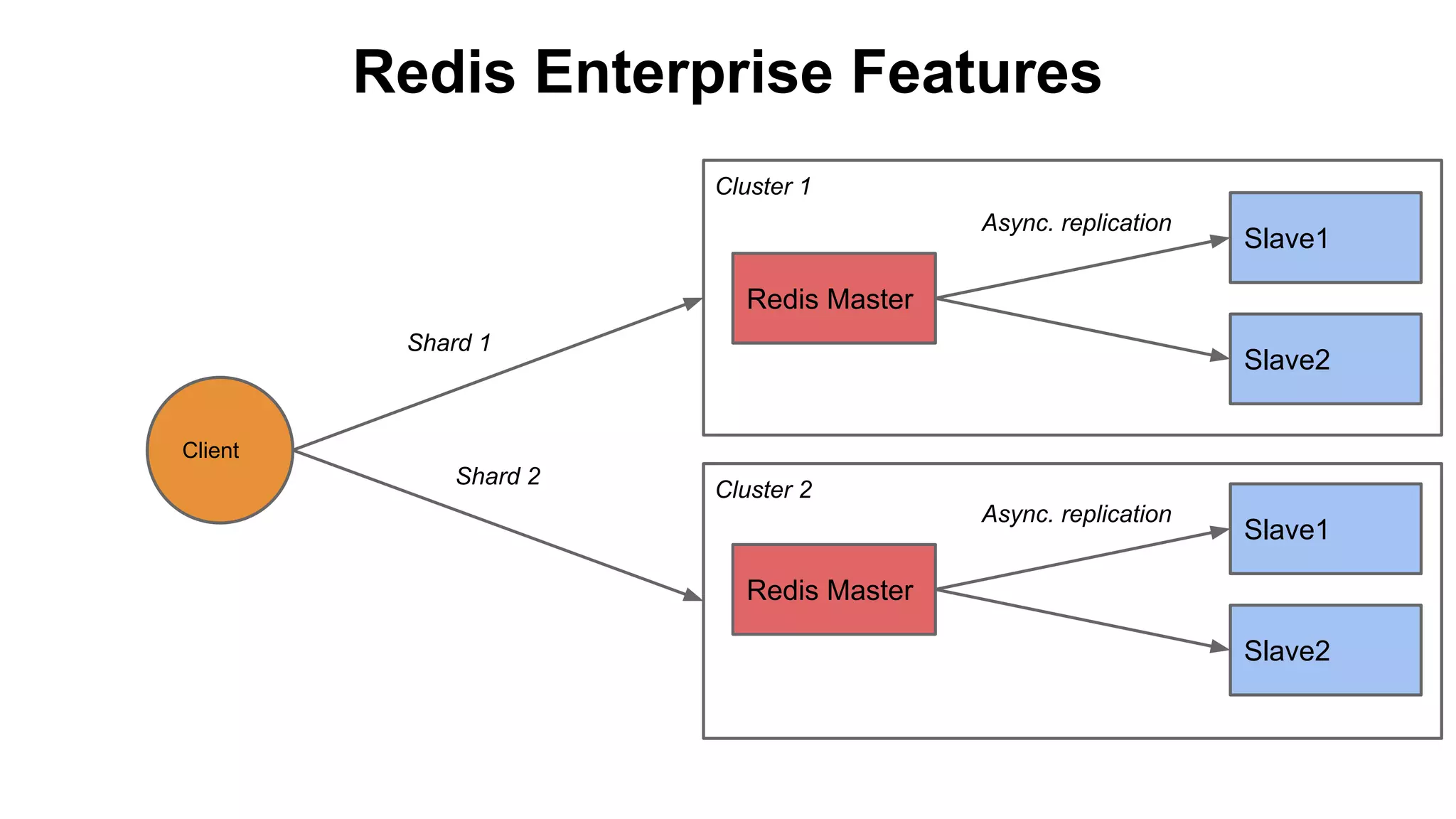

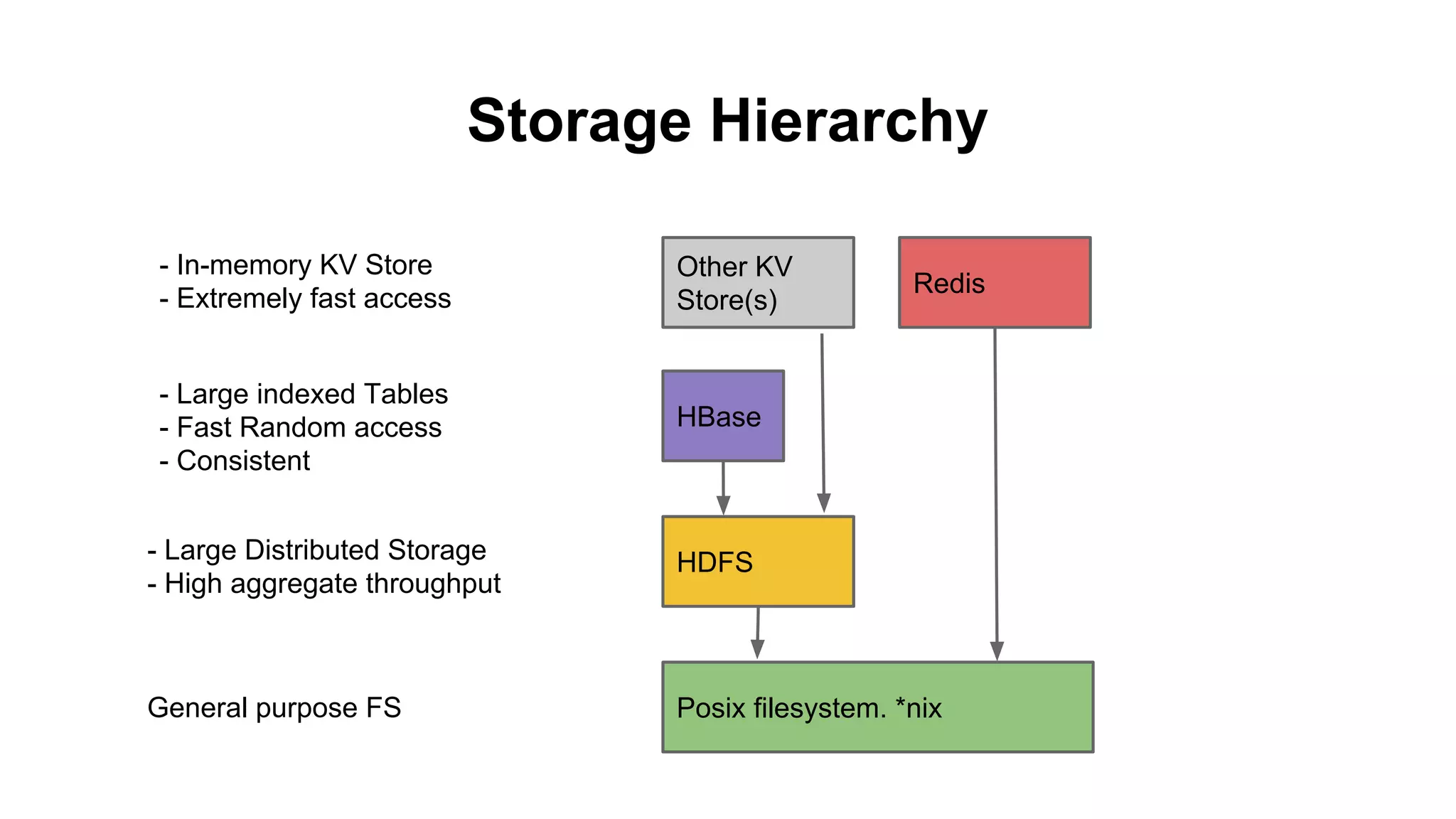



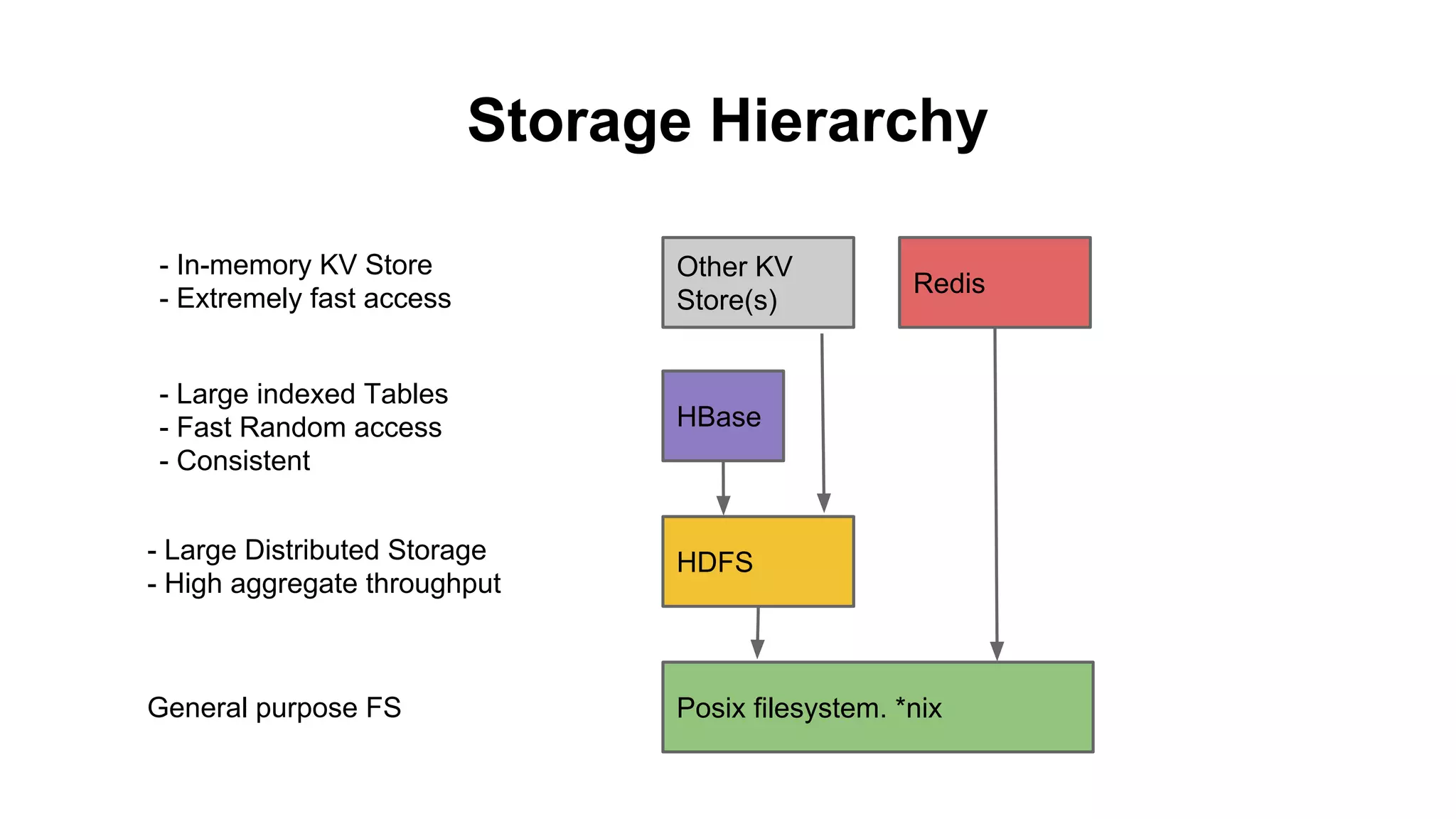
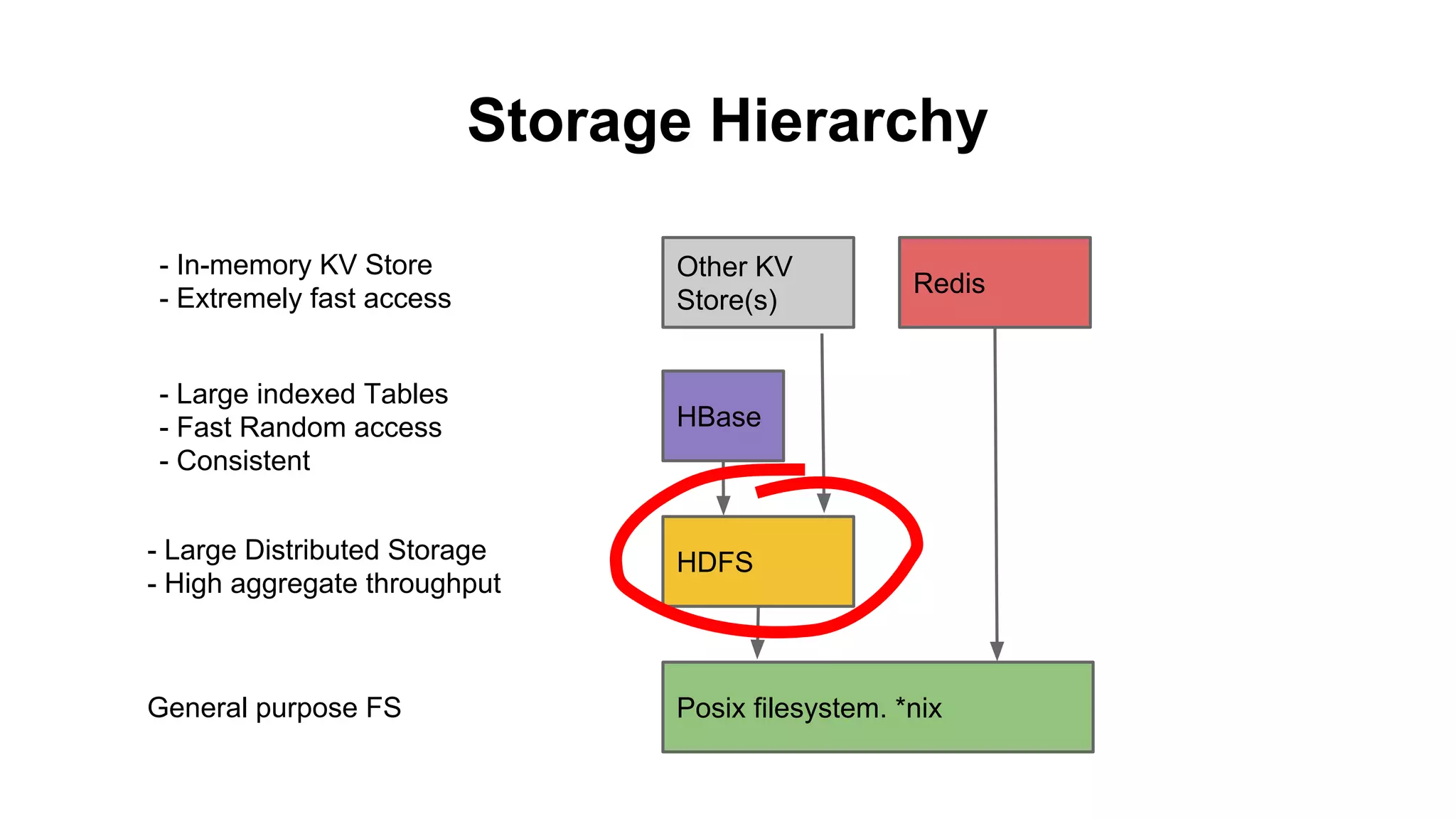
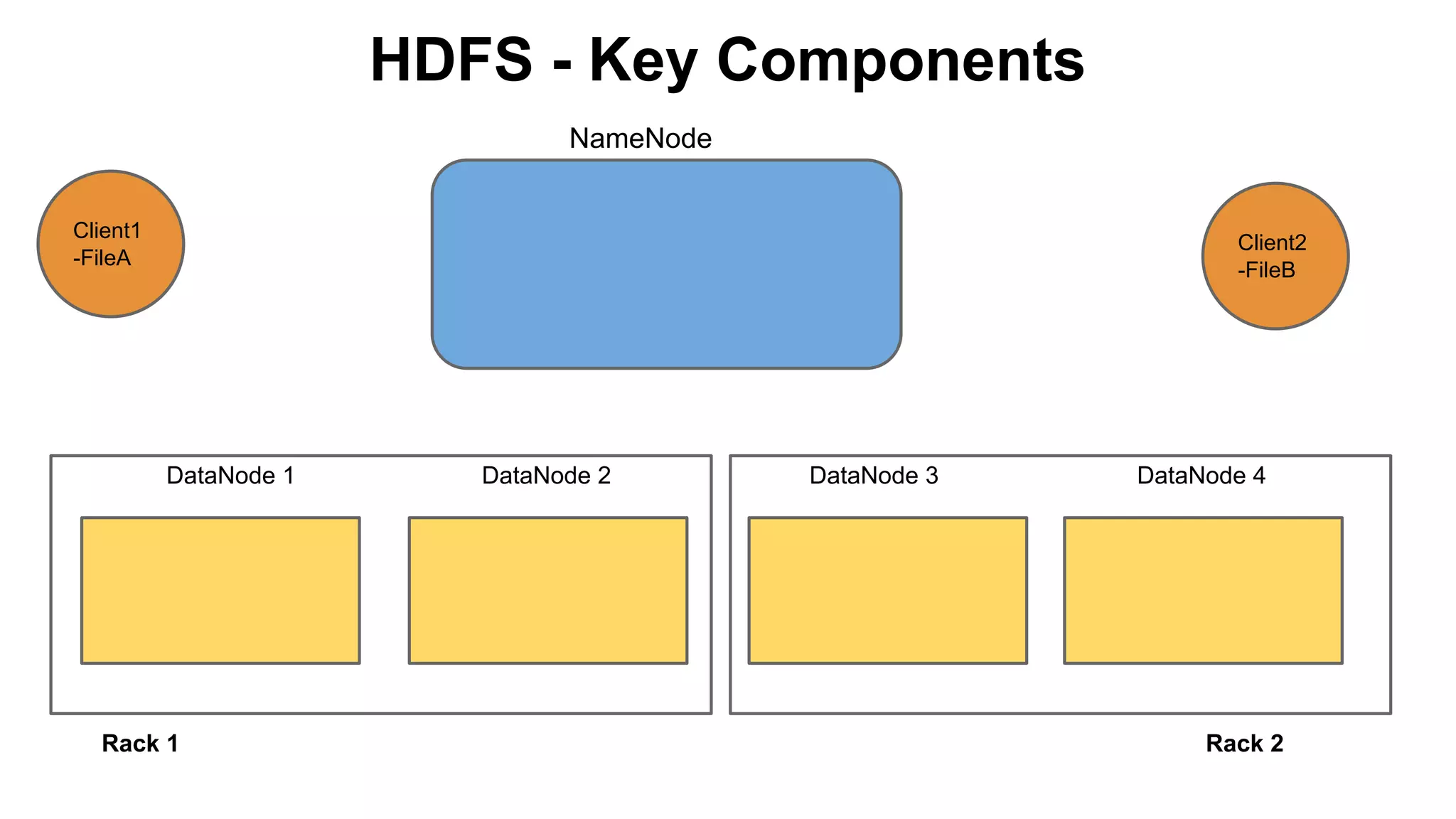
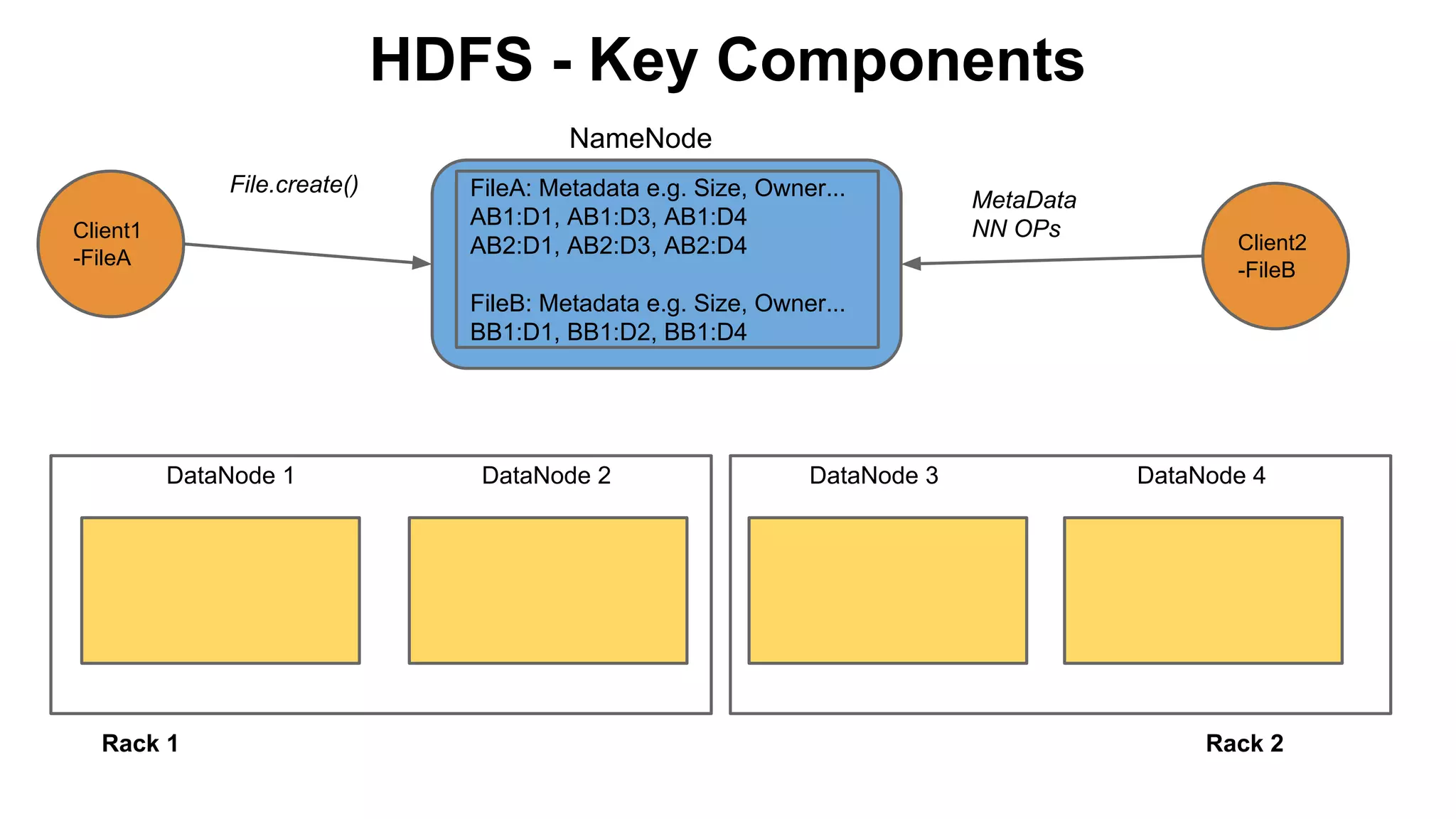
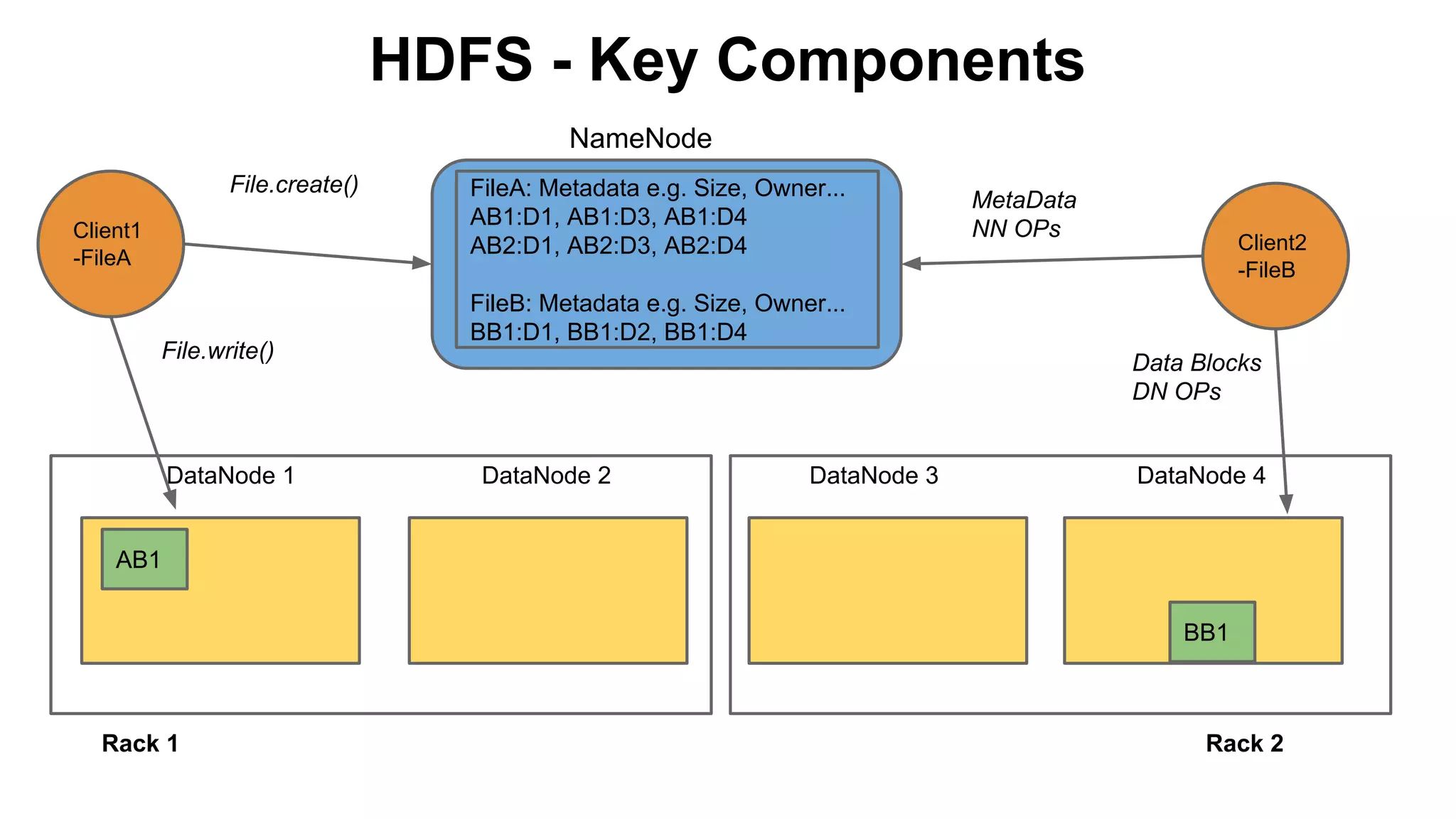
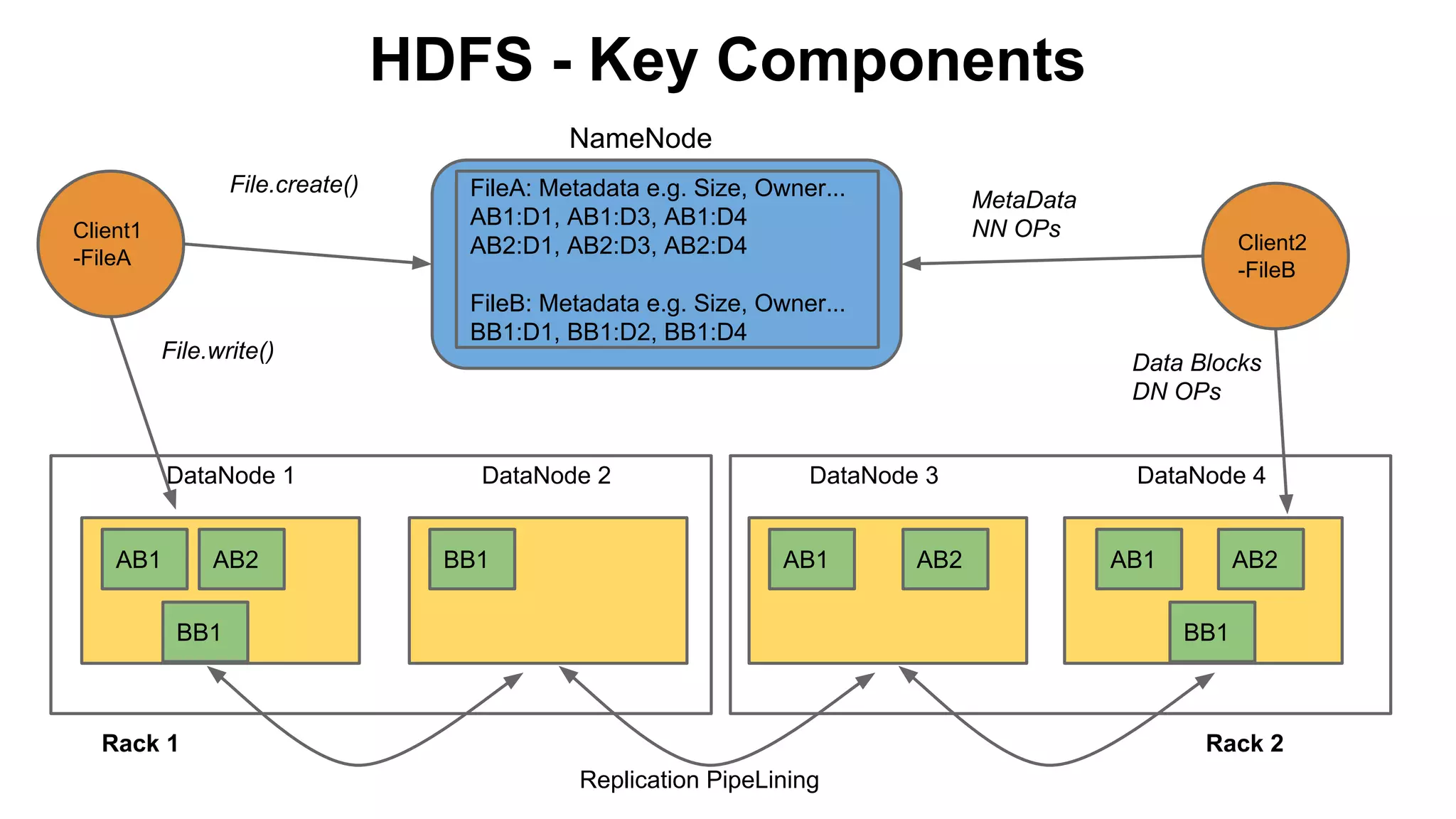
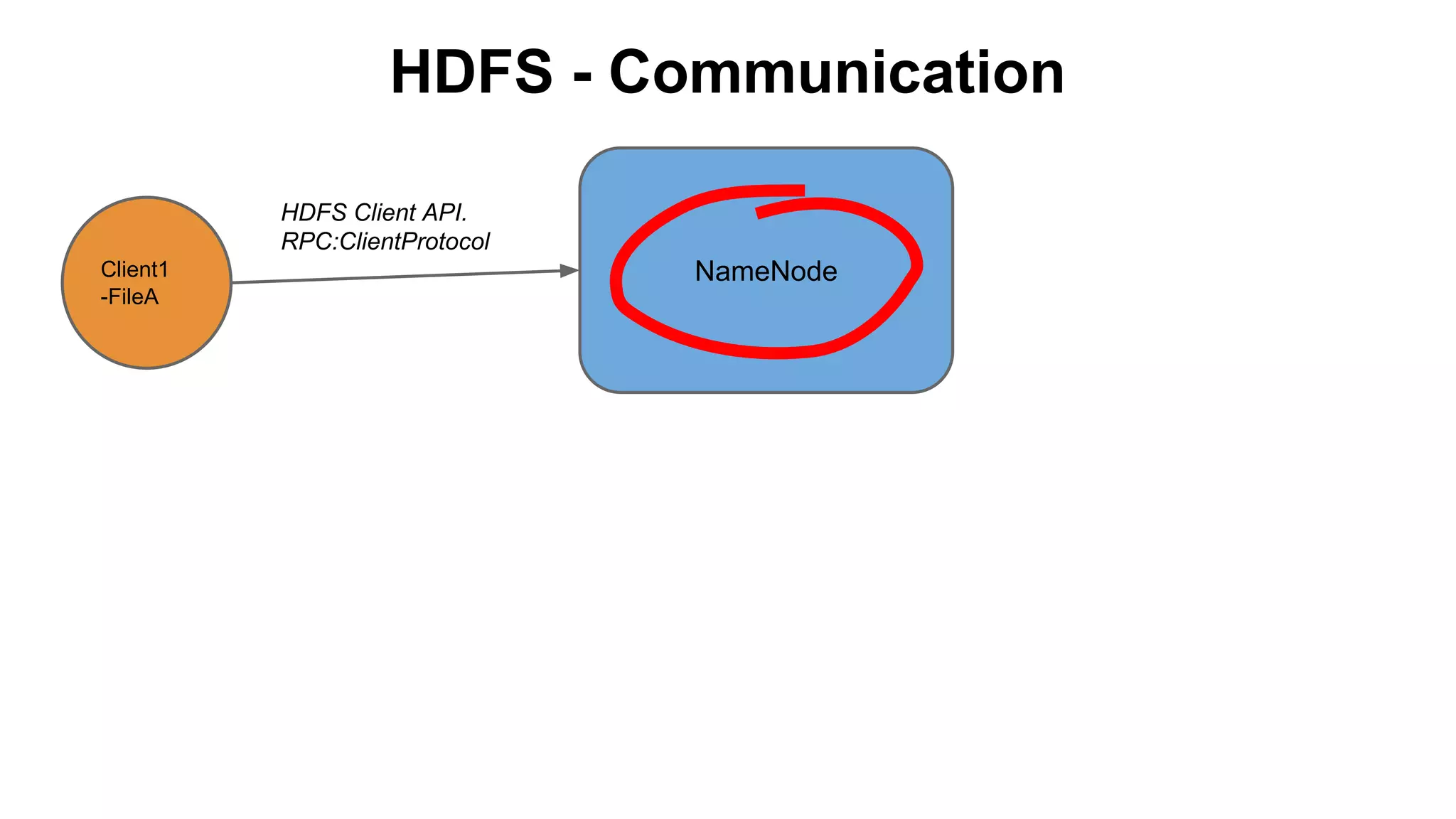
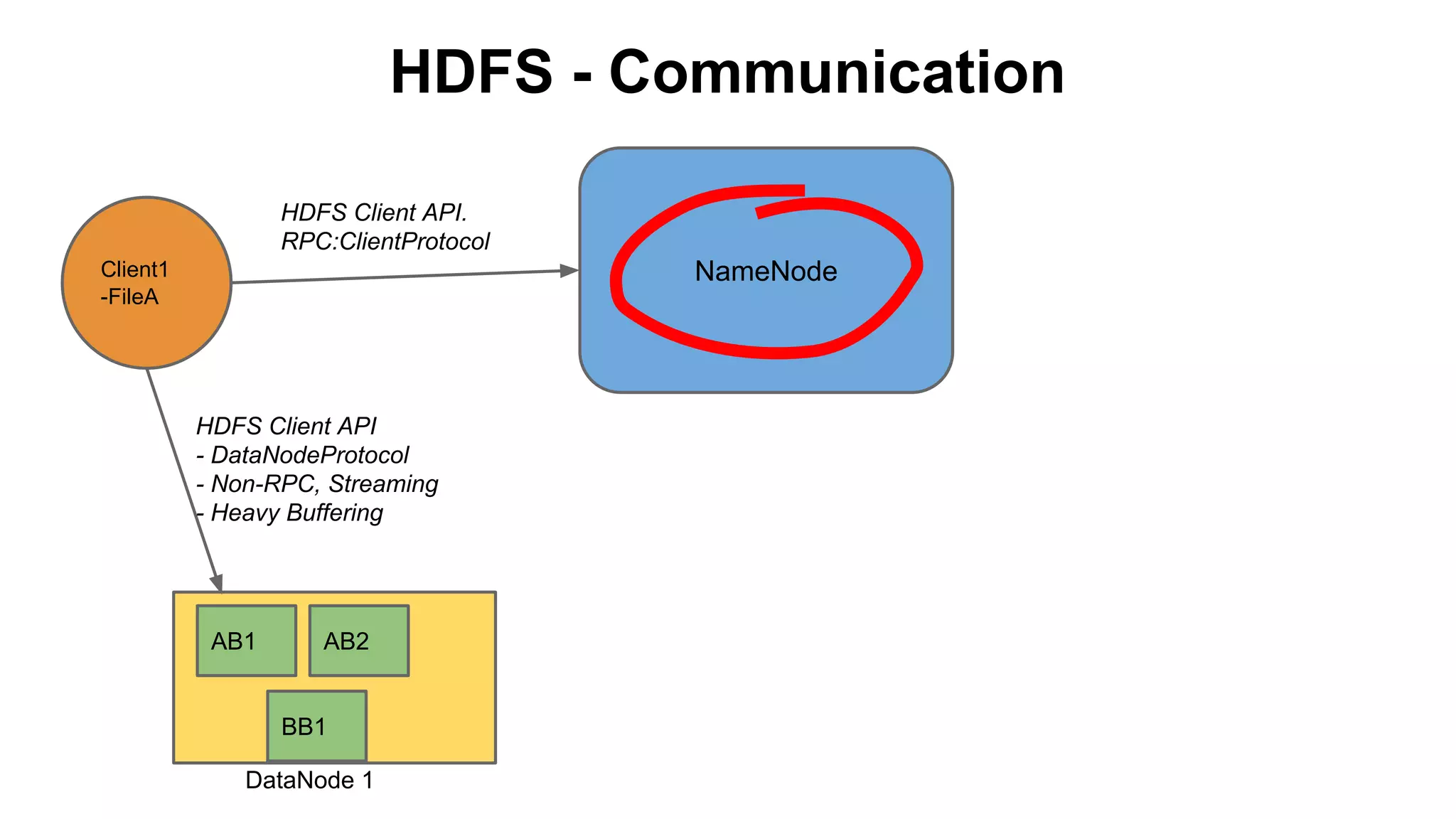
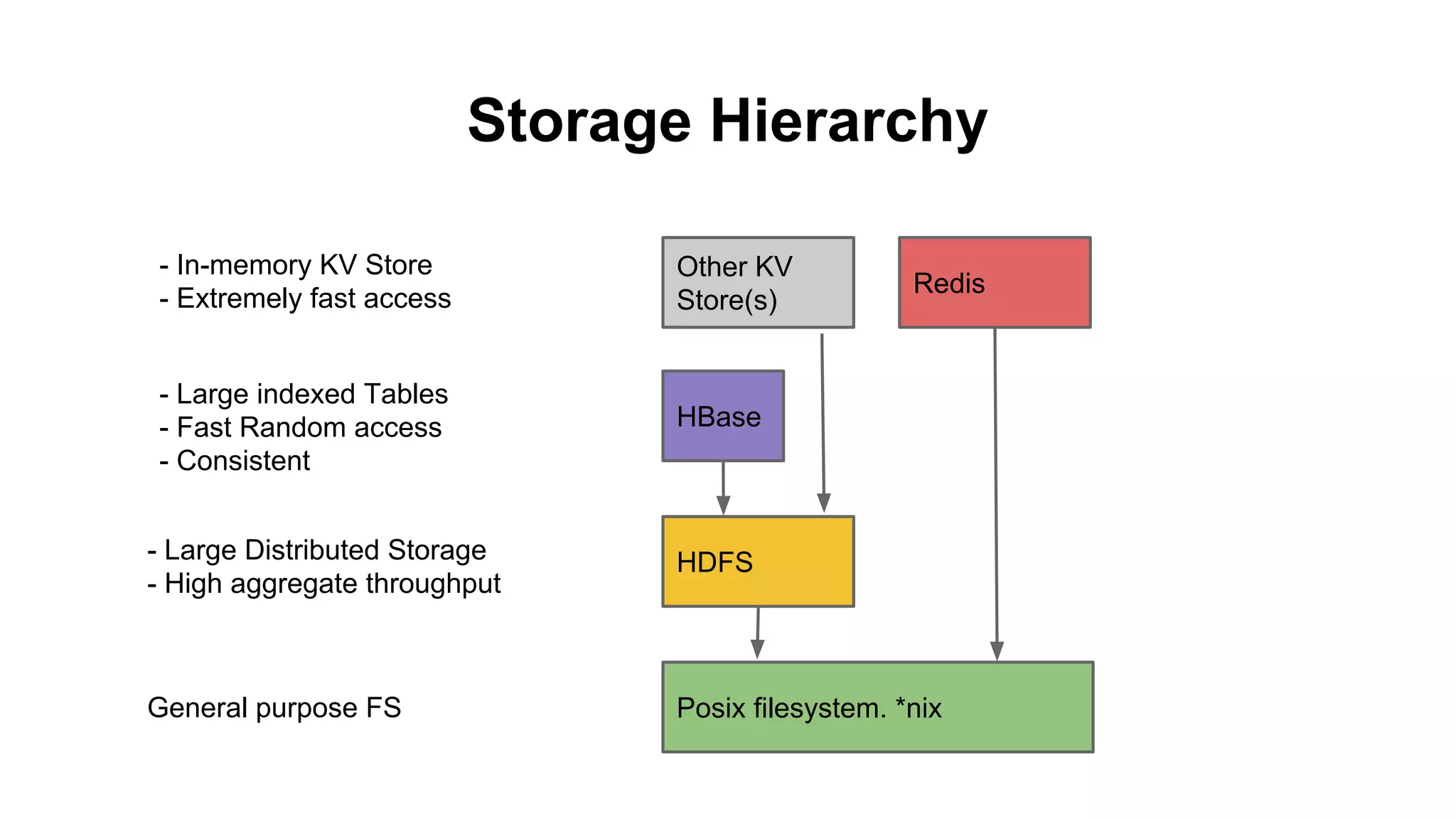
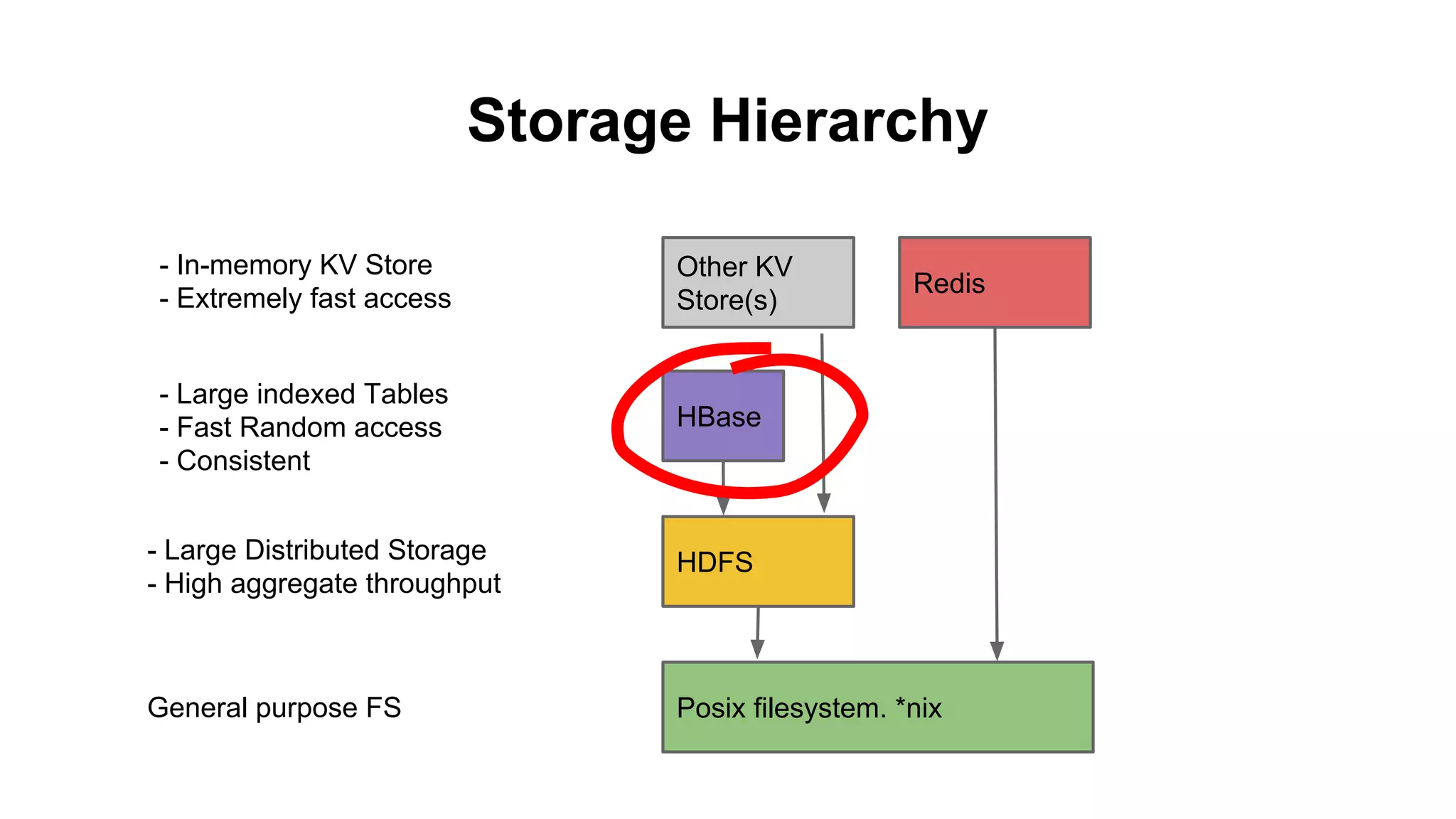
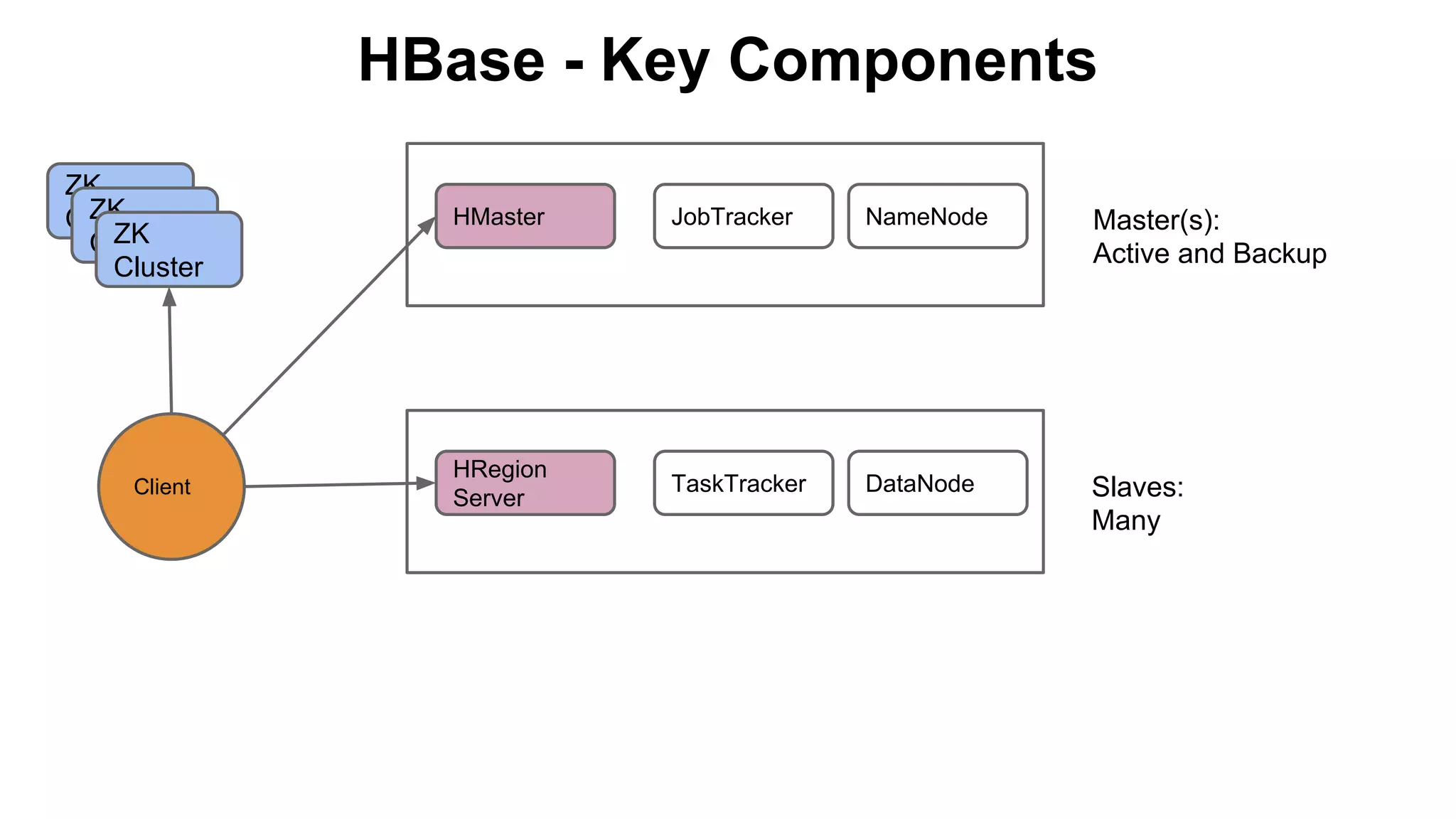
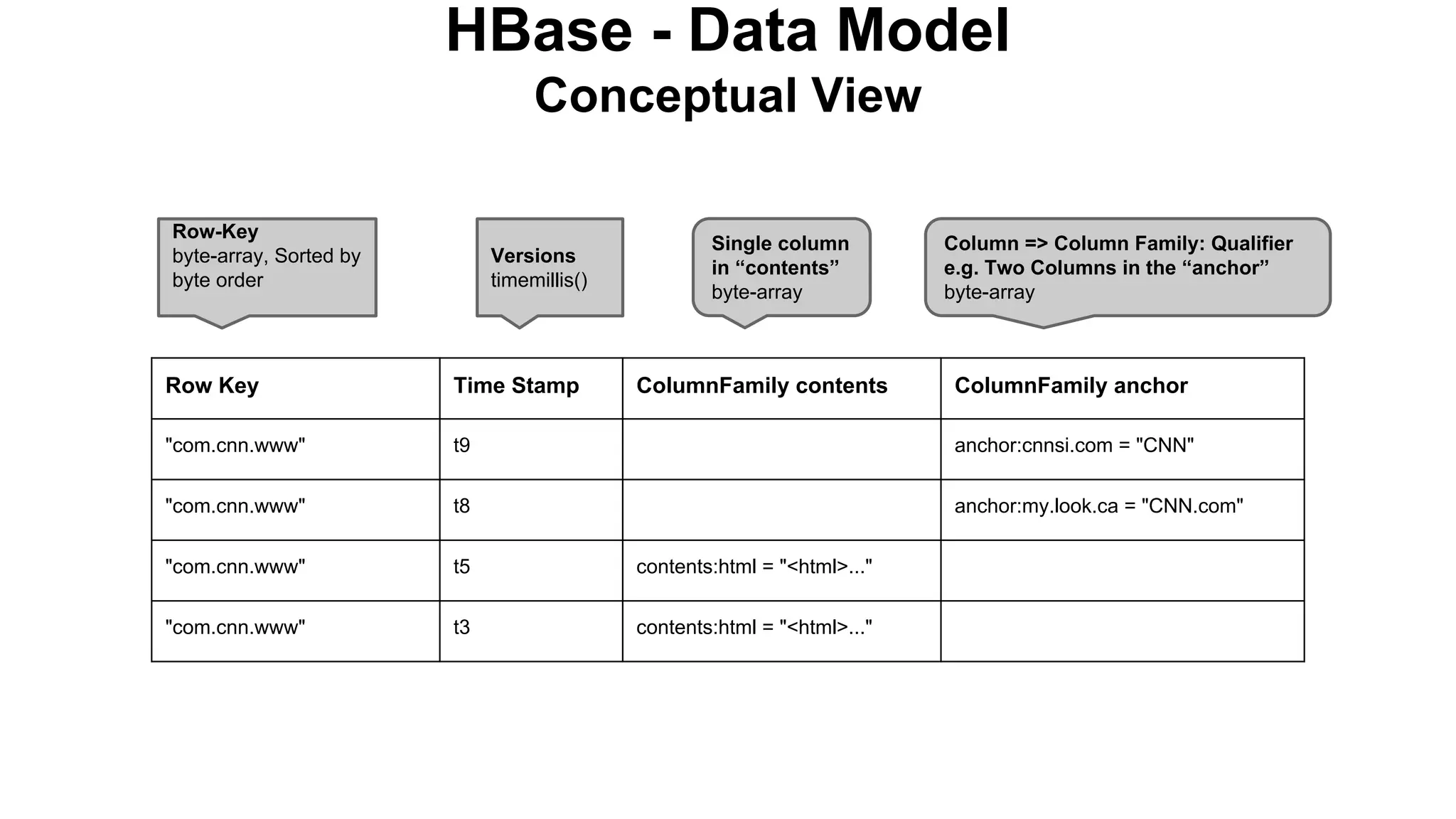
The document discusses various storage systems for big data, particularly focusing on Hadoop's HDFS and HBase, as well as Redis. It outlines key features, architecture, and operational concepts, highlighting the strengths and limitations of each storage solution. Additionally, it touches on the HDFS components, data model of HBase, and advanced topics related to performance and management.
















































































![Coded Agents – with UiPath SDK + LangGraph [Virtual Hands-on Workshop]](https://cdn.slidesharecdn.com/ss_thumbnails/codedagentsdeck-251215155422-5497c599-thumbnail.jpg?width=640&height=640&fit=bounds)






