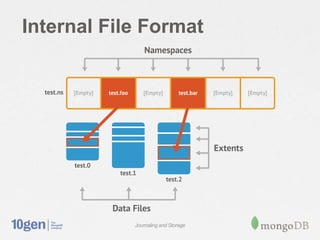
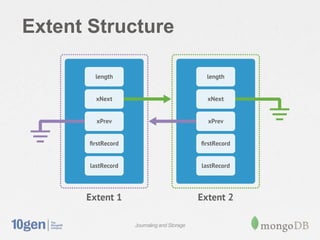
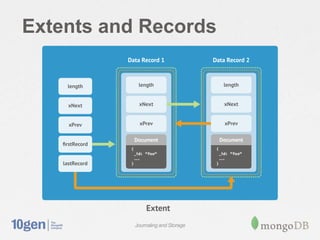
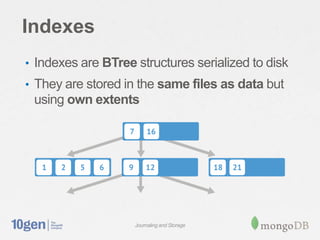
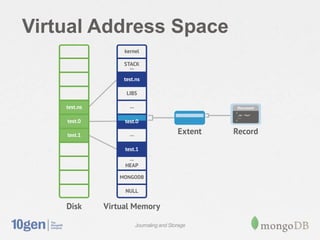
MongoDB stores data in files on disk that are broken into variable-sized extents containing documents. These extents, as well as separate index structures, are memory mapped by the operating system for efficient read/write. A write-ahead journal is used to provide durability and prevent data corruption after crashes by logging operations before writing to the data files. The journal increases write performance by 5-30% but can be optimized using a separate drive. Data fragmentation over time can be addressed using the compact command or adjusting the schema.