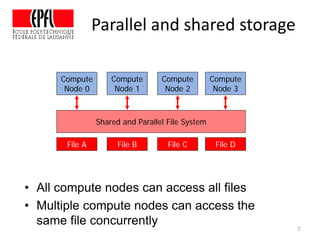
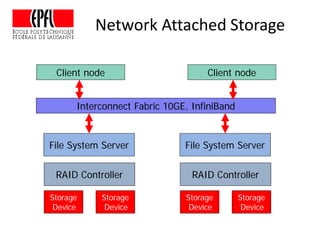
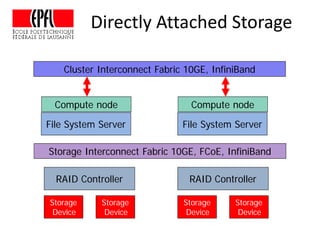
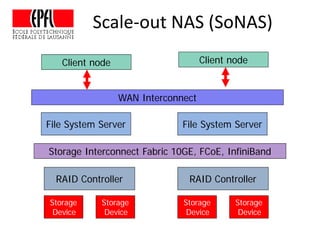
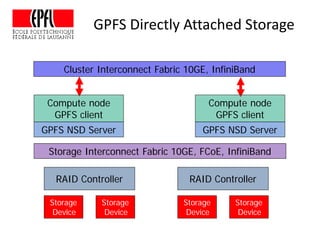
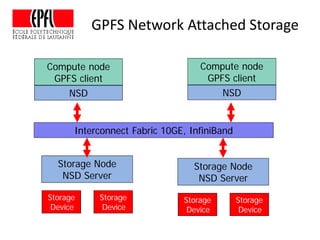
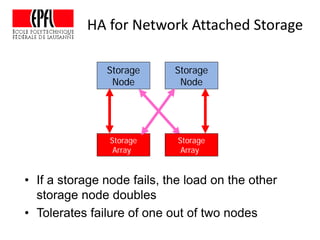
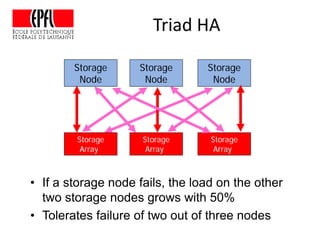
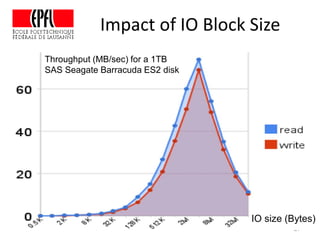
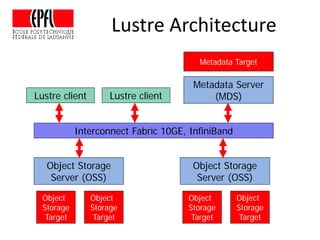
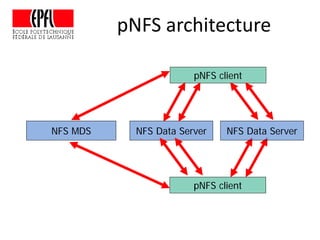
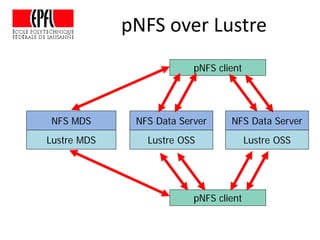
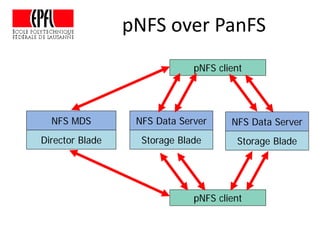
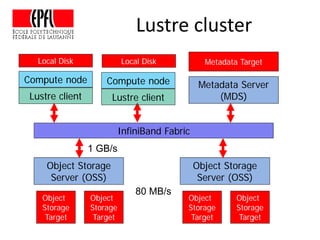
This document discusses storage infrastructure for high-performance computing. It begins by introducing data-intensive science and the need for parallel storage systems. It then discusses several parallel file systems used in HPC like GPFS, Lustre, and PanFS. Key concepts covered include data striping, scale-out NAS, parallel file systems, and IO acceleration techniques. The document also discusses challenges of data growth, bottlenecks in scaling storage, and architectures of various parallel file systems.