Downloaded 139 times


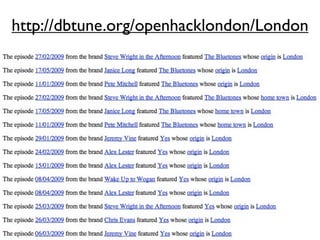

















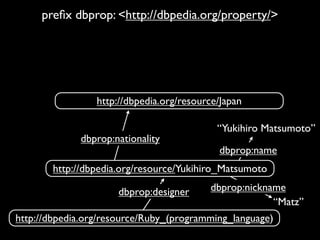





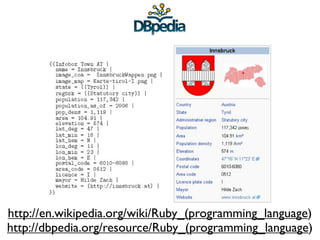








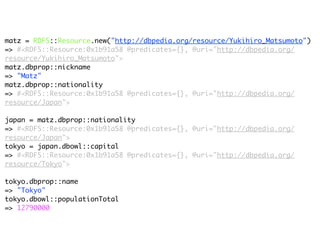
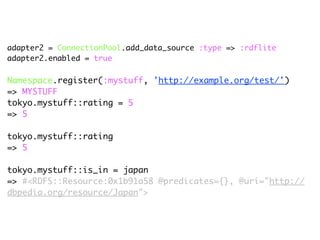







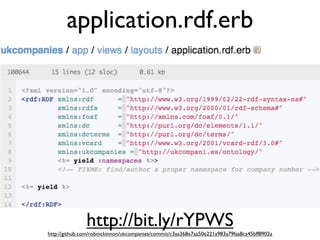



The document discusses Linked Data and RDF, describing how data from different sources on the web can be connected using URIs, HTTP, and structured data formats like RDF. It provides examples of retrieving and representing data from DBpedia in RDF format using Ruby tools and libraries. It also discusses publishing RDF from a Rails application by adding MIME types and generating RDF representations.


![Realtime Analytics With Elasticsearch [New Media Inspiration 2013]](https://cdn.slidesharecdn.com/ss_thumbnails/realtimeanalyticselasticsearch-karelminarik-nmi2013-130119084635-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)

















































