


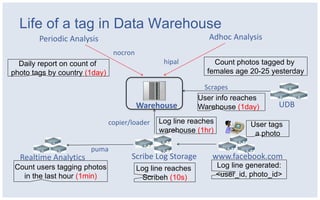
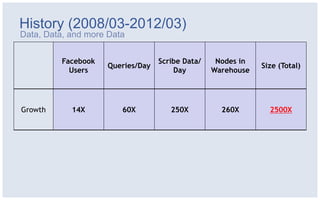










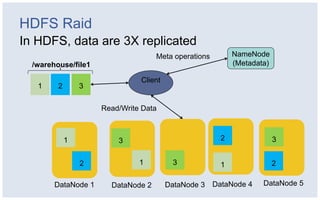
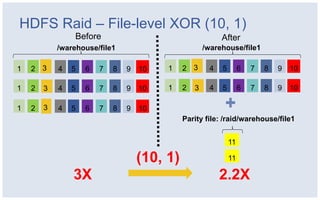

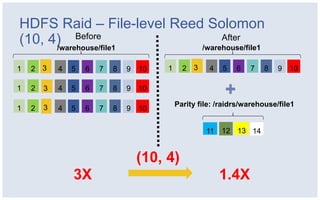
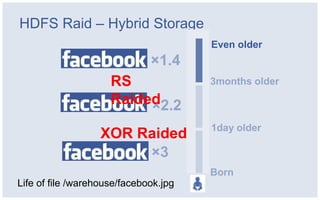

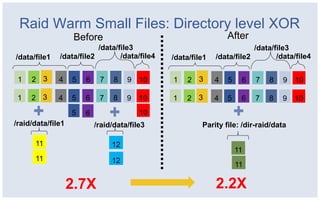
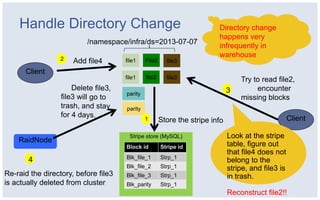






The document discusses Facebook's strategies for managing big data storage challenges, including smart retention of data, sorting and compressing data to enhance storage efficiency, and implementing HDFS RAID for better data redundancy. It details the methodology for empirical retention to optimize table usage, the importance of sorting before compression, and the use of hybrid storage solutions. Additionally, lessons learned from these approaches highlight significant space savings and operational considerations within their data infrastructure.






















































































