Download as PDF, PPTX
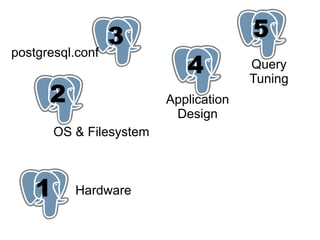
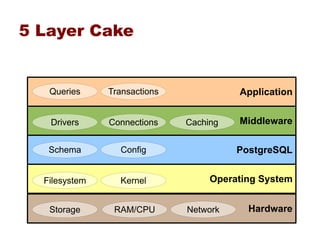
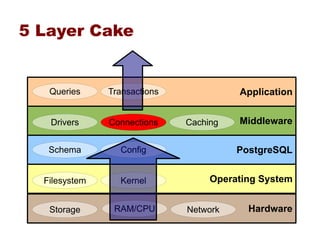
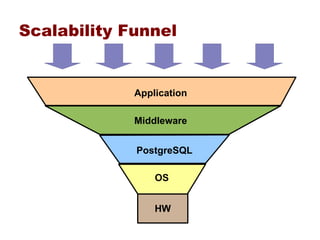









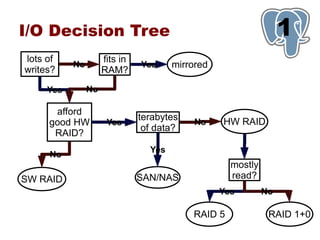




























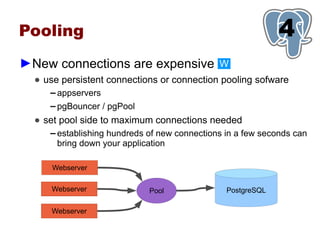


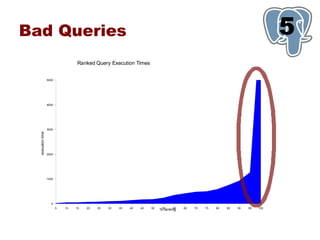
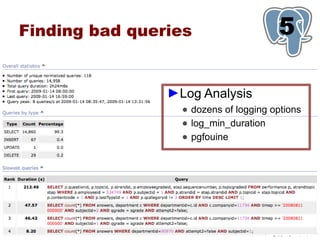

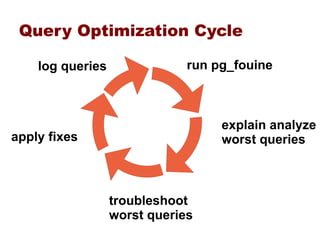
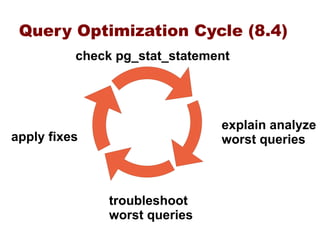
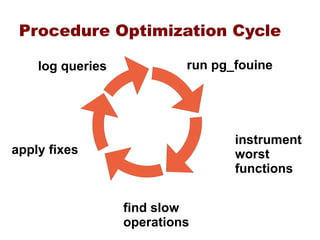
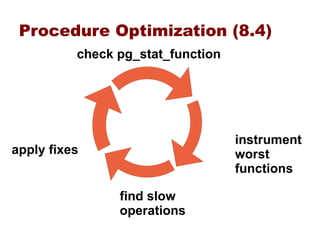


This document provides an overview of five steps to improve PostgreSQL performance: 1) hardware optimization, 2) operating system and filesystem tuning, 3) configuration of postgresql.conf parameters, 4) application design considerations, and 5) query tuning. The document discusses various techniques for each step such as selecting appropriate hardware components, spreading database files across multiple disks or arrays, adjusting memory and disk configuration parameters, designing schemas and queries efficiently, and leveraging caching strategies.









































































