Download as PDF, PPTX

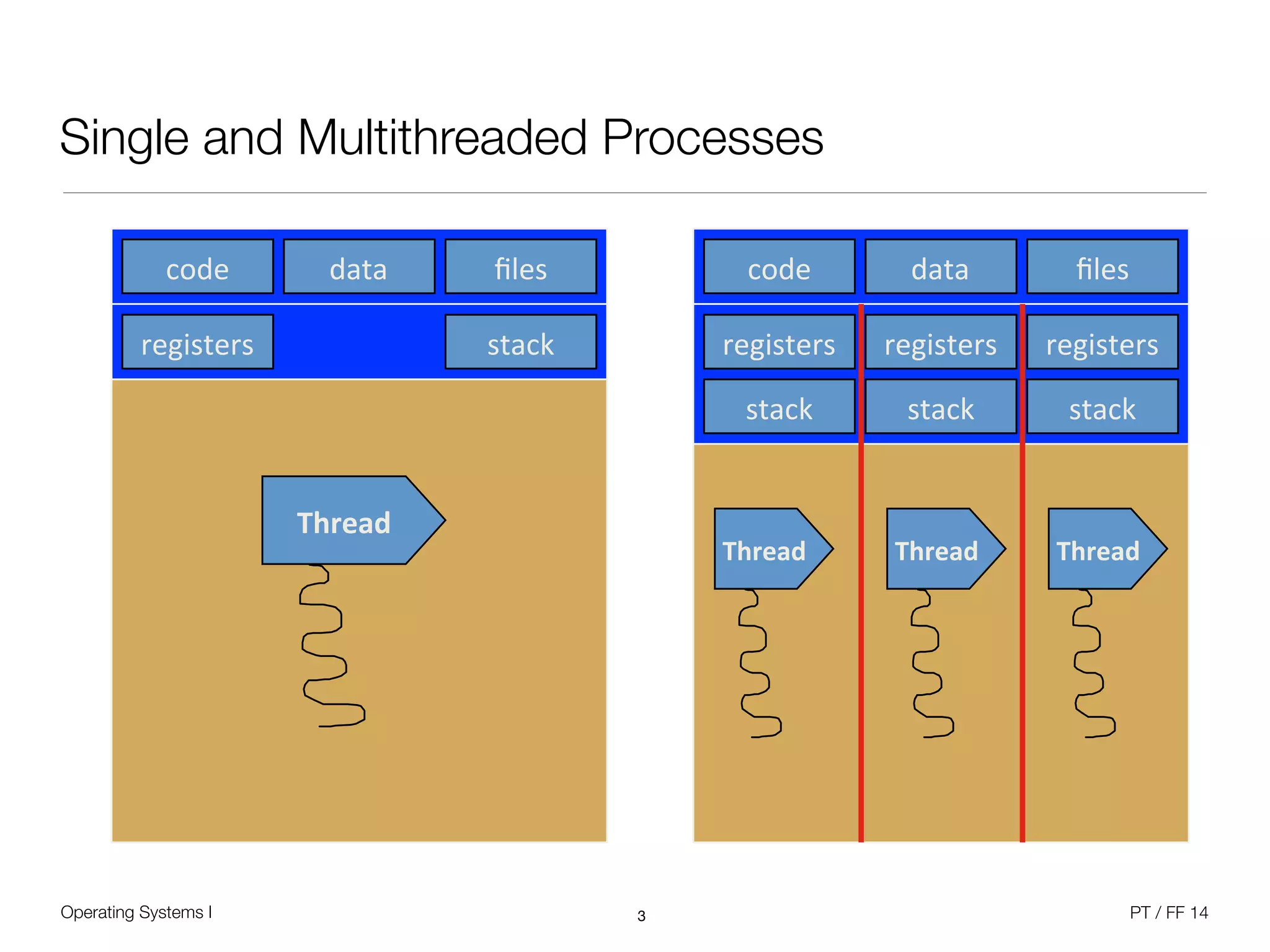


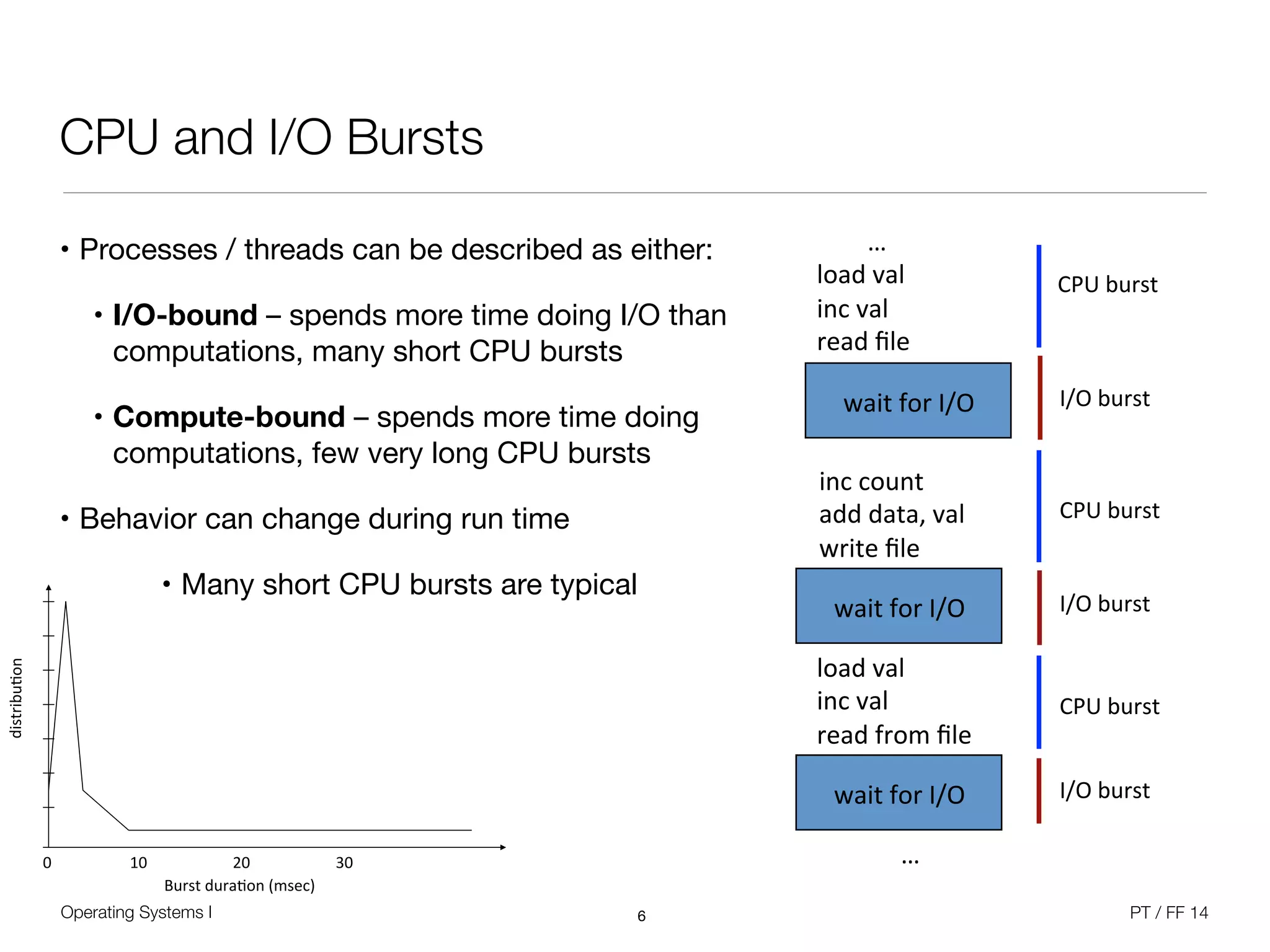

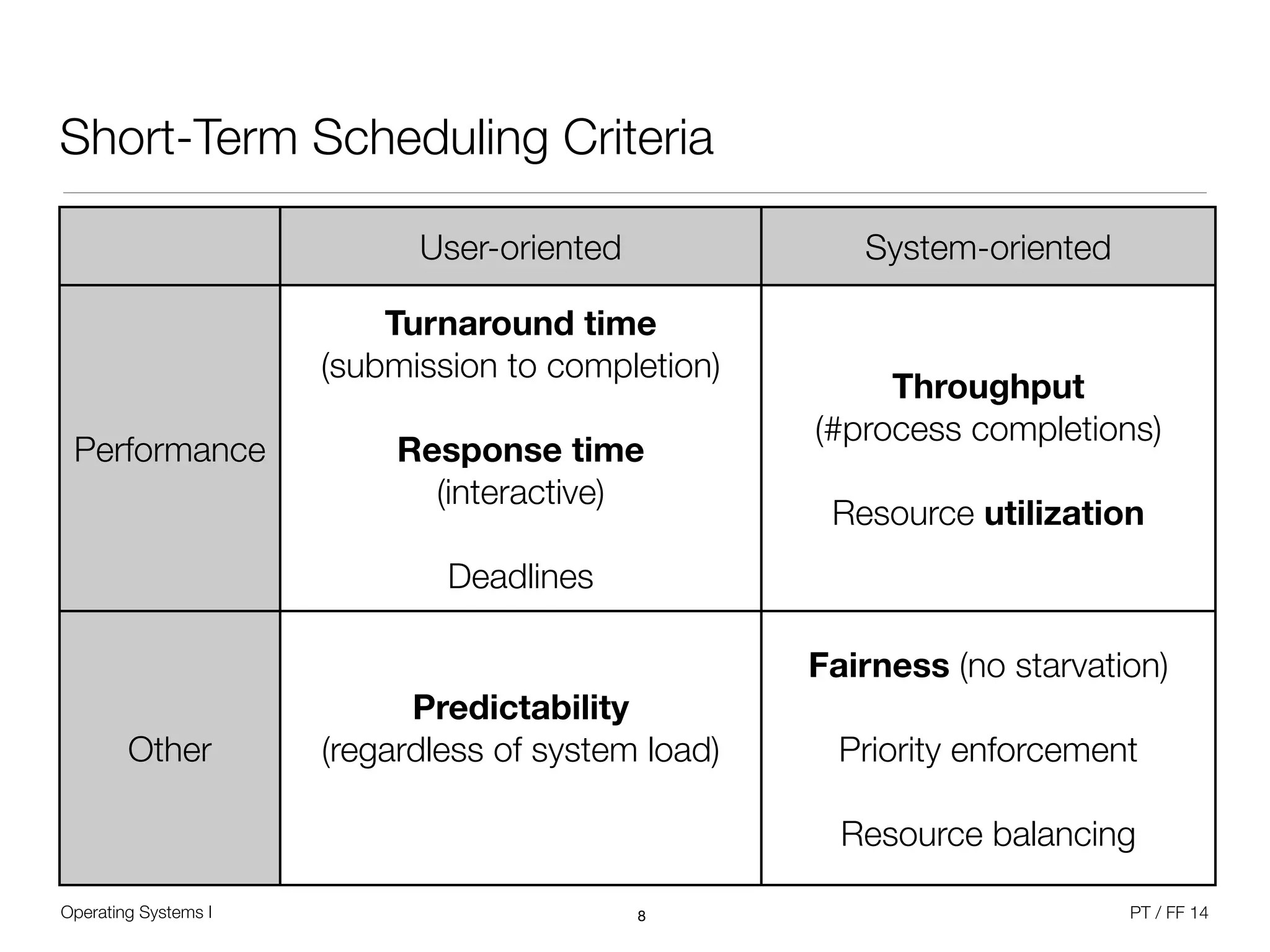



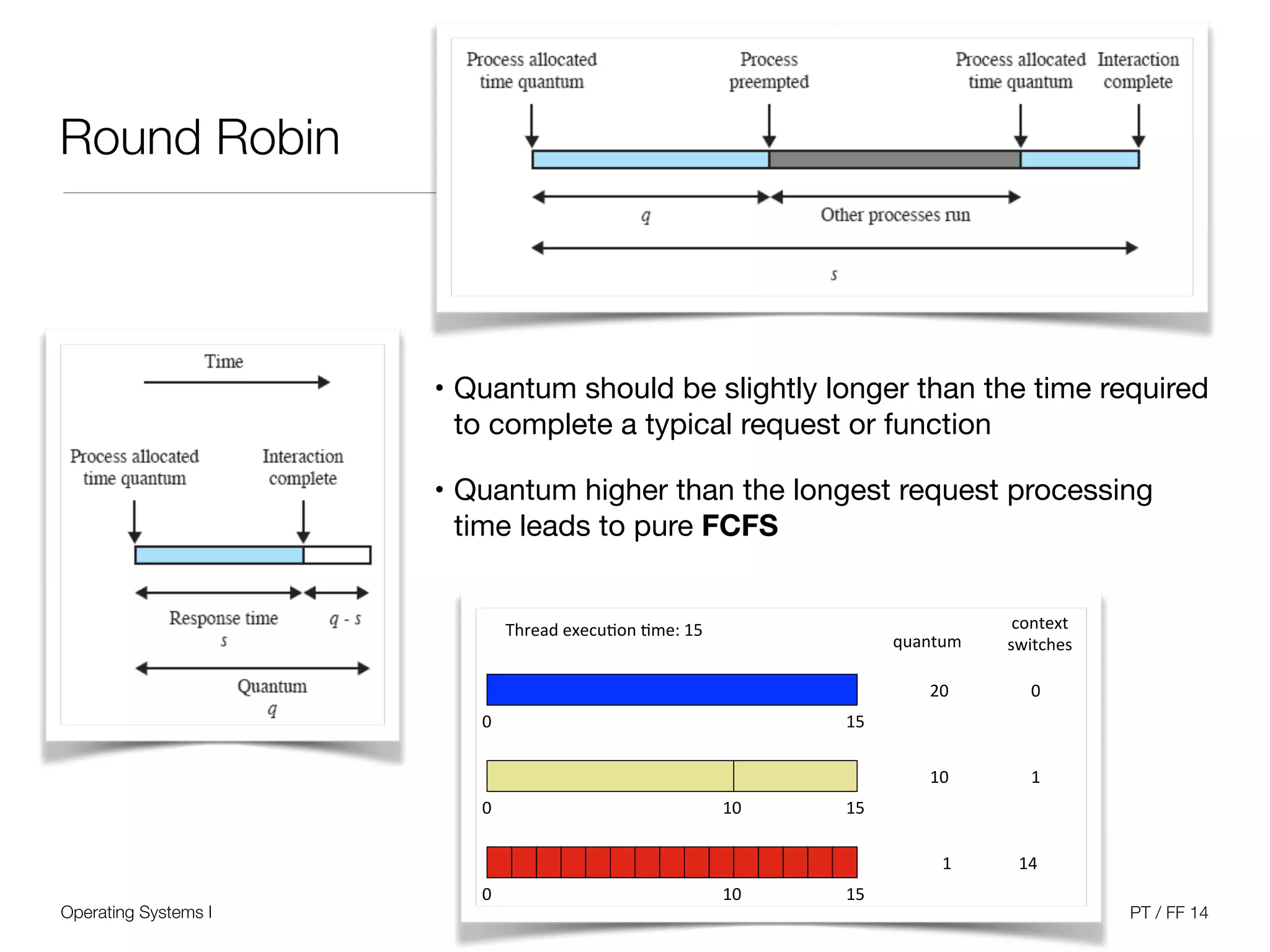
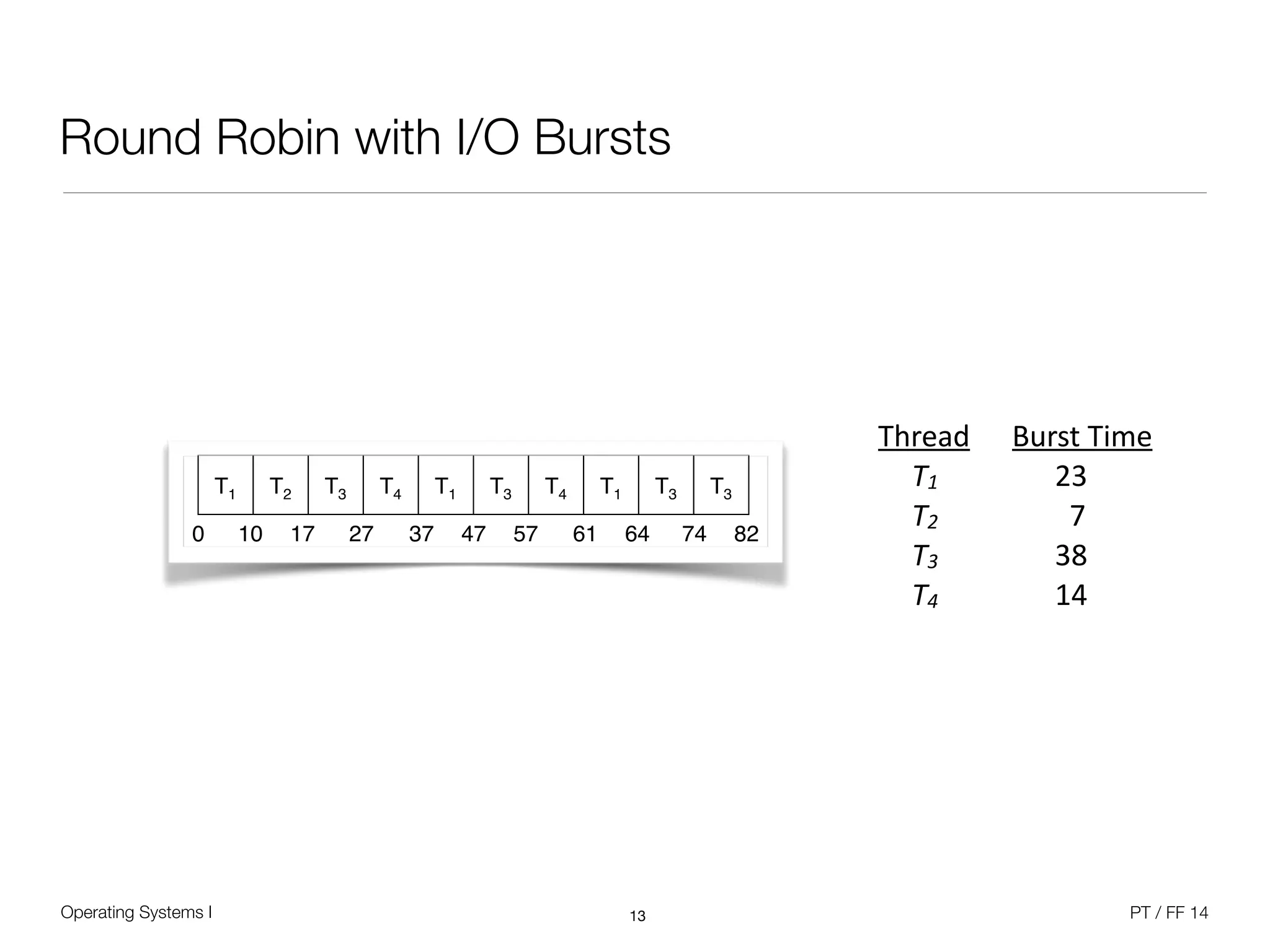



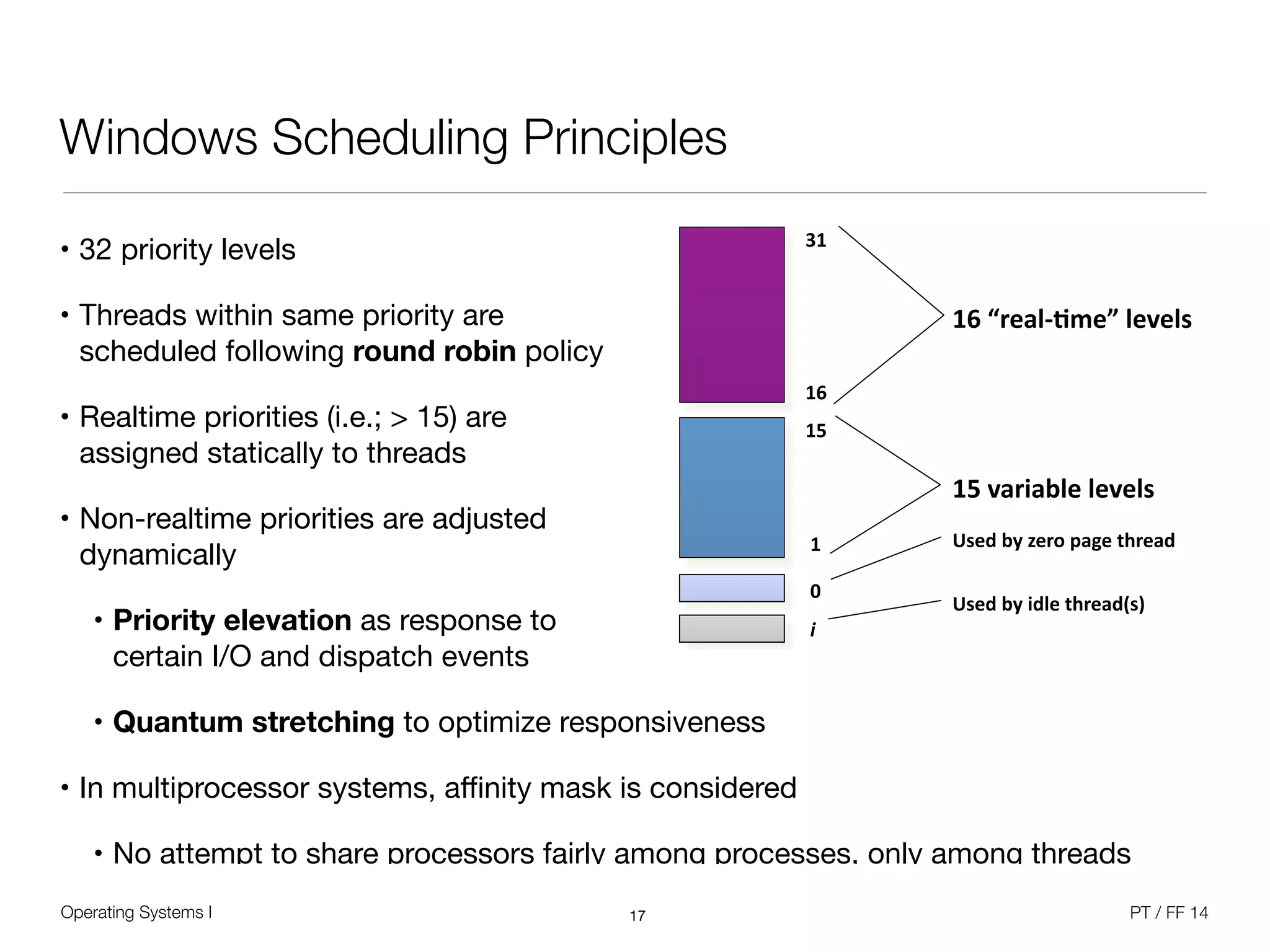




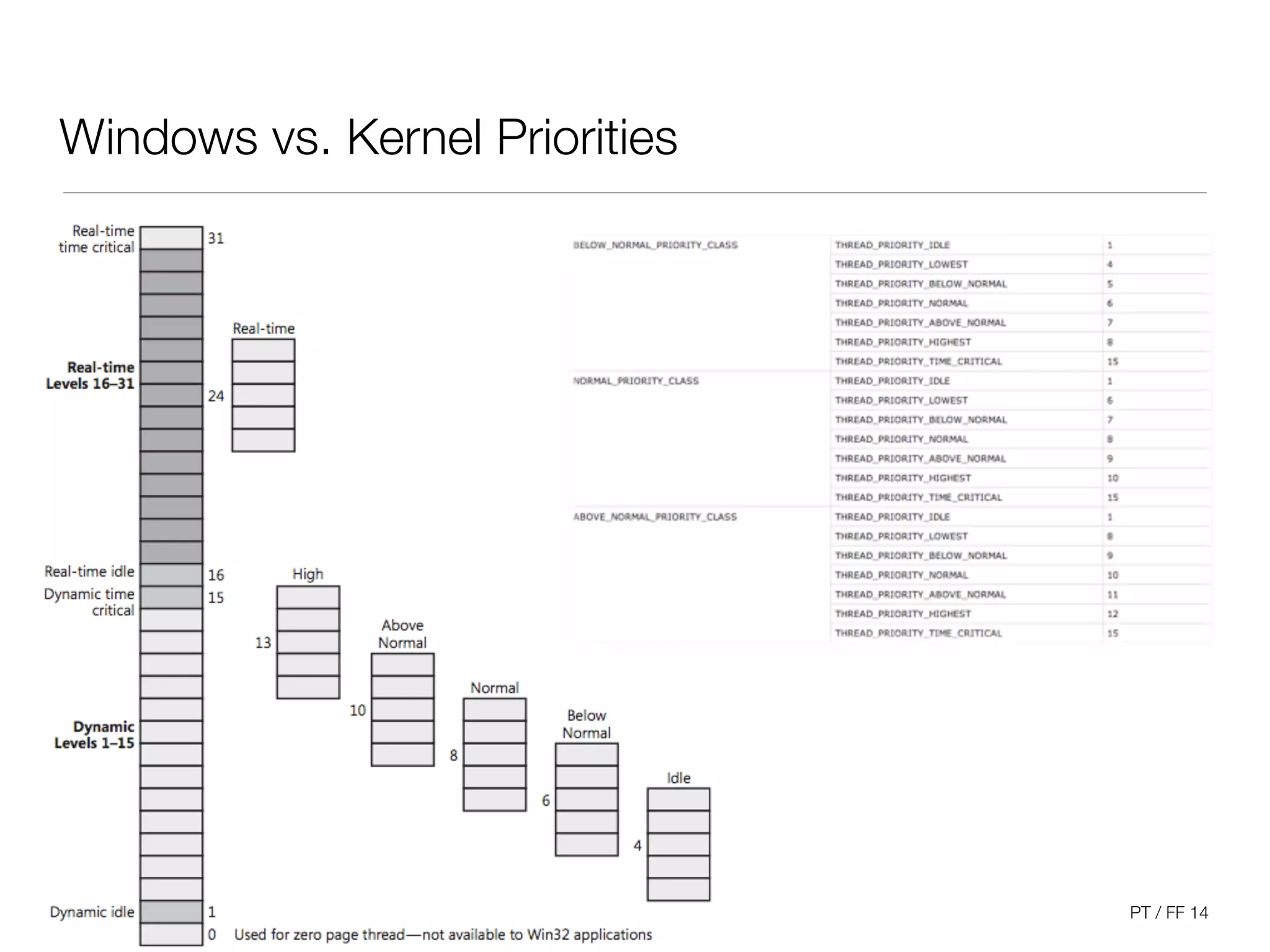
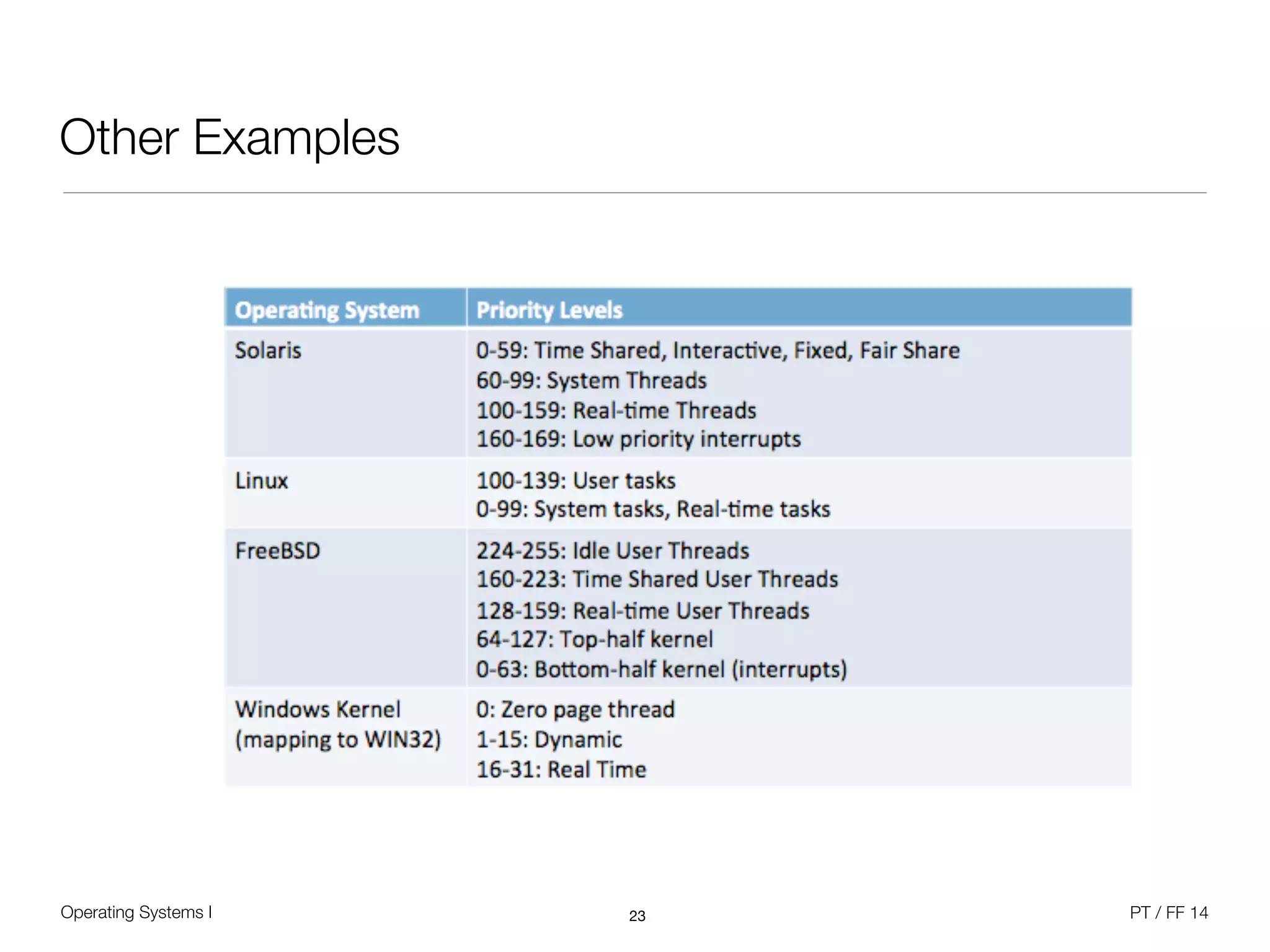

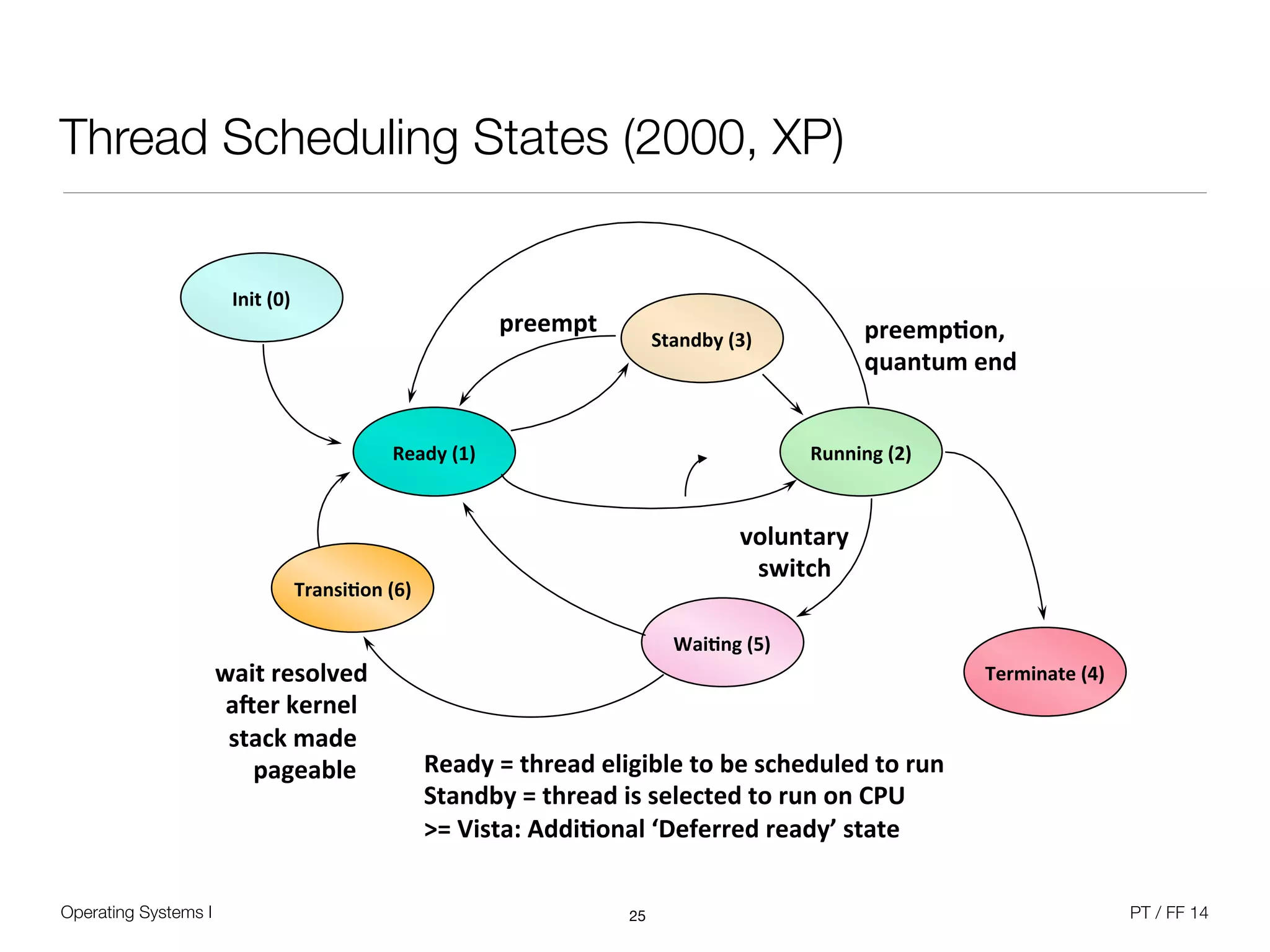
















The document discusses processes and scheduling in operating systems. It covers key concepts like processes, threads, scheduling criteria, and different scheduling algorithms like round robin and priority-based scheduling. It also discusses scheduling in multiprocessor systems and provides examples of scheduling in Windows.