Download as PDF, PPTX


![Dependable Systems Course PT 2014
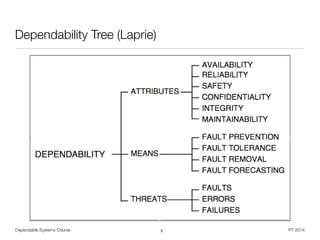
Dependability
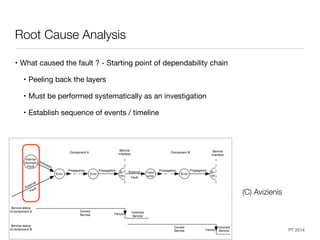
• Umbrella term for operational requirements on a system
• IFIP WG 10.4: "[..] the trustworthiness of a computing system which allows reliance
to be justifiably placed on the service it delivers [..]"
• IEC IEV: "dependability (is) the collective term used to describe the availability
performance and its influencing factors : reliability performance, maintainability
performance and maintenance support performance"
• Laprie: „ Trustworthiness of a computer system such that
reliance can be placed on the service it delivers to the user “
• Adds a third dimension to system quality
• General question: How to deal with unexpected events ?
• In German: ,Verlässlichkeit‘ vs. ,Zuverlässigkeit‘
2](https://image.slidesharecdn.com/dahqdrn7qsyyhs2kltks-signature-2292d91f37599d8e10b4aa90485a8bd8ad3ab0f99049b3bc375985ccda8022ce-poli-150219025901-conversion-gate02/85/Dependable-Systems-Summary-16-16-2-320.jpg)


![Dependable Systems Course PT 2014
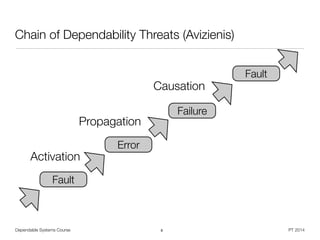
Dependability Stakeholders
• System - Entity with function, behavior, and structure
• A number of components or subsystems, which interact under the control of a
design [Robinson]
• Service - System behavior abstraction, as perceived by the user
• User - Human or physical system that interacts with the systems service
• Specification - Definition of expected service and delivery conditions
• On different levels, can lead to specification fault
• Reliance demands assessment of non-functional dependability attributes
• Provide ability for trustworthy service delivery by dependability means
• Undesired (maybe expected) circumstances form dependability threats
6](https://image.slidesharecdn.com/dahqdrn7qsyyhs2kltks-signature-2292d91f37599d8e10b4aa90485a8bd8ad3ab0f99049b3bc375985ccda8022ce-poli-150219025901-conversion-gate02/85/Dependable-Systems-Summary-16-16-6-320.jpg)








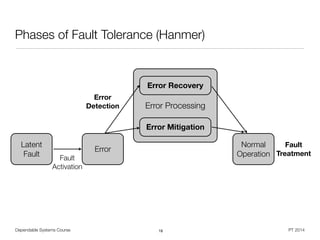







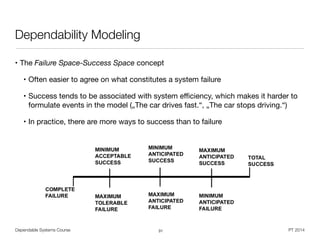
![Dependable Systems Course PT 2014
MTTR << MTTF [Fox]
• Armando Fox on ,Recovery-Oriented Computing‘
• A = MTTF / (MTTF + MTTR)
• 10x decrease of MTTR as good as 10x increase of MTTF ?
• MTTF‘s are not claimable, but MTTR claims are verifiable
• Proving MTTF numbers demands system-years of observation and experience
• Lowering MTTR directly improves user experience of one specific outage,
since MTTF is typically longer than one user session
• HCI factor of failed system
• Miller, 1968: >1sec “sluggish”, >10sec “distracted” (user moves away)
• 2001 Web user study: ~5sec „acceptable”, ~10sec „excessively slow“
29](https://image.slidesharecdn.com/dahqdrn7qsyyhs2kltks-signature-2292d91f37599d8e10b4aa90485a8bd8ad3ab0f99049b3bc375985ccda8022ce-poli-150219025901-conversion-gate02/85/Dependable-Systems-Summary-16-16-29-320.jpg)


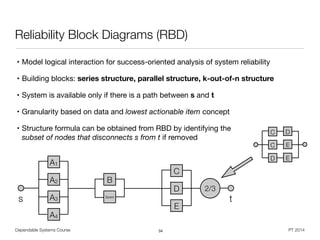
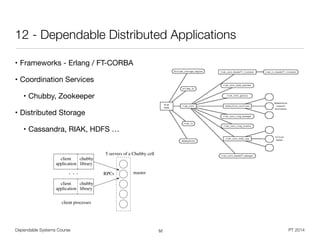
![S = cLB (cW S1 ⇥ cW S2) (cDB1 ⇥ cDB2)
Asite = aLB ⇥ AW Sset ⇥ ADBset
= aLB ⇥ [1 (1 aW S)nW S
] ⇥ [1 (1 aDB)nDB
]
Dependable Systems Course PT 2014
Examples
33
aWS
aWS
aDB
aDB
aLB](https://image.slidesharecdn.com/dahqdrn7qsyyhs2kltks-signature-2292d91f37599d8e10b4aa90485a8bd8ad3ab0f99049b3bc375985ccda8022ce-poli-150219025901-conversion-gate02/85/Dependable-Systems-Summary-16-16-33-320.jpg)







![Dependable Systems Course PT 2014
Reliability Data
• Field (operational) failure data
• Meaningful source of information, experience from real world operation
• Operational and environmental conditions may be not fully known
• Service life data with / without failure
• Helpful in assessing time characteristics of reliability issues
• Data from engineering tests
• Example: Accelerated life tests
• Results from controlled environment
• Trustworthy for analysis purposes
• Lack of failure information is the ,greatest deficiency‘ in reliability research [Misra]
46](https://image.slidesharecdn.com/dahqdrn7qsyyhs2kltks-signature-2292d91f37599d8e10b4aa90485a8bd8ad3ab0f99049b3bc375985ccda8022ce-poli-150219025901-conversion-gate02/85/Dependable-Systems-Summary-16-16-46-320.jpg)






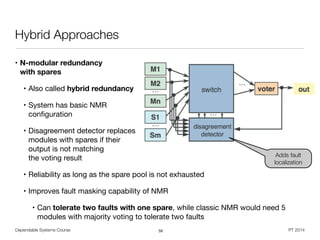


![Dependable Systems Course PT 2014
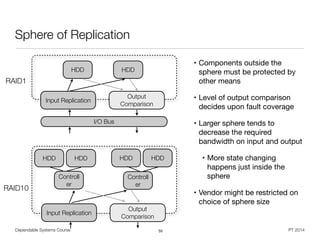
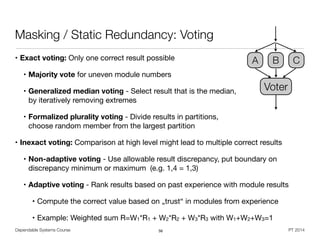
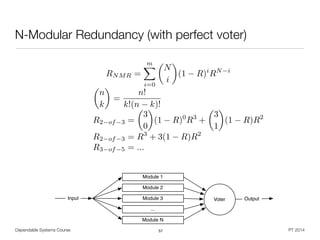
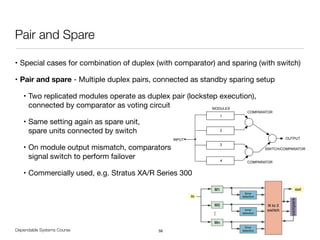
RAID
• Redundant Array of Independent Disks (RAID) [Patterson et al. 1988]
• Improve I/O performance and / or reliability by building raid groups
• Replication for information reconstruction on disk failure (degrading)
• Requires computational effort (dedicated controller vs. software)
• Assumes failure independence
62](https://image.slidesharecdn.com/dahqdrn7qsyyhs2kltks-signature-2292d91f37599d8e10b4aa90485a8bd8ad3ab0f99049b3bc375985ccda8022ce-poli-150219025901-conversion-gate02/85/Dependable-Systems-Summary-16-16-62-320.jpg)
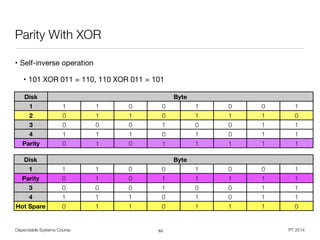


![Dependable Systems Course PT 2014
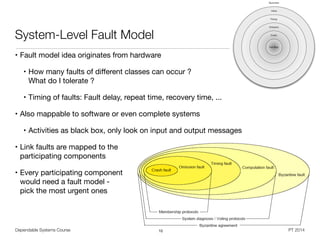
Software Fault Model [Goloubeva]
• Example: Control loop writing computation result to a variable
• Temporary fault: Write NULL to result variable after end of usage
• Permanent fault: Compute and store incorrect output from input data
• Single vs. multiple faults depends on granularity level of investigation
• On source code level
• Program: Structured collection of features with syntax and semantic
• Syntax allows to describe fault model
• Negation of semantic properties defines a fault model
• Examples: Calling non-existent functions, Functions not returning a value, values
out of their type range, missing input parameters
• On executable level, e.g. stack overflow due to recursion
67](https://image.slidesharecdn.com/dahqdrn7qsyyhs2kltks-signature-2292d91f37599d8e10b4aa90485a8bd8ad3ab0f99049b3bc375985ccda8022ce-poli-150219025901-conversion-gate02/85/Dependable-Systems-Summary-16-16-67-320.jpg)
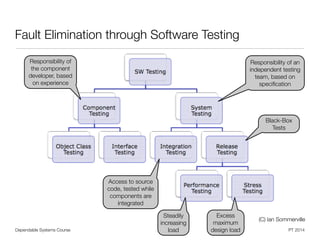
![Dependable Systems Course PT 2014
Fault-Tolerant Software -
Another categorization [Lyu 95]
• Single version techniques
• Add mechanisms for detection, containment, and handling of errors to the
software component itself
• Examples: Software structure and actions approaches, error detection,
exception handling, checkpointing and restart, process pairs, data diversity
• Multi version techniques
• Rely on structured utilization of variants of the same software
• Examples: Recovery blocks, N-version programming
• Principles can be applied to any software layer
• Identify source of most design faults
• Typically no problem with parallel application, beside cost factor
68](https://image.slidesharecdn.com/dahqdrn7qsyyhs2kltks-signature-2292d91f37599d8e10b4aa90485a8bd8ad3ab0f99049b3bc375985ccda8022ce-poli-150219025901-conversion-gate02/85/Dependable-Systems-Summary-16-16-68-320.jpg)

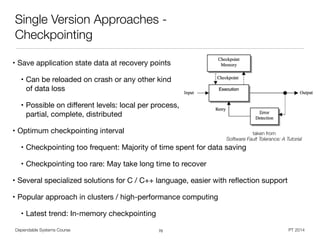
![Dependable Systems Course PT 2014
Single Version Approaches -
Data Diversity [Ammann 88]
71
takenfrom
SoftwareFaultTolerance:ATutorial](https://image.slidesharecdn.com/dahqdrn7qsyyhs2kltks-signature-2292d91f37599d8e10b4aa90485a8bd8ad3ab0f99049b3bc375985ccda8022ce-poli-150219025901-conversion-gate02/85/Dependable-Systems-Summary-16-16-71-320.jpg)
![Dependable Systems Course PT 2014
Single Version Approaches -
High-Level Instruction Duplication [Goloubeva]
• Introduce data and code redundancy through
high-level transformation
• Duplicate every variable
• Perform every write operation on both copies
of the variable
• After each read operation, the copies must be
checked for consistency
• Should be close to read operation,
in order to avoid error propagation
• Includes also expression evaluation
• Procedure parameters treated as variables
• Independent from underlying hardware,
targets cache / main memory faults
72
a=b;
.. becomes ...
a0=b0;
a1=b1;
if (b0 != b1)
error();
...
a=b+c;
... becomes ...
a0=b0+c0;
a1=b1+c1;
if ((b0!=b1)||(c0!=c1))
error();](https://image.slidesharecdn.com/dahqdrn7qsyyhs2kltks-signature-2292d91f37599d8e10b4aa90485a8bd8ad3ab0f99049b3bc375985ccda8022ce-poli-150219025901-conversion-gate02/85/Dependable-Systems-Summary-16-16-72-320.jpg)
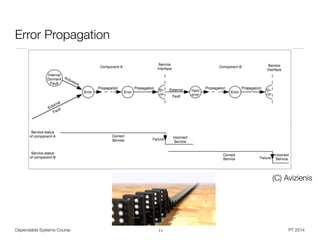
![Dependable Systems Course PT 2014
Control Flow Error
• Control flow error (CFE) leads to unexpected instruction
execution
• Terminology:
• Basic block (BB) - branch-free serial code fragment
• Branch / jump instruction is modeled as last instruction
of a basic block
• Control flow graph (CFG) - one node per basic block
• Illegal branch - Node transition is not part of the CFG
• Wrong branch - Node transition is already part of the CFG
• Inter-block error - Erroneous branch to different block
• Intra-block errors - Erroneous branch inside a block
73
i=0;
while(i<n) {
------------------
if (a[i] < b[i])
------------------
x[i]=a[i];
------------------
else
x[i]=b[i];
------------------
i++;
}
------------------
BB 0
BB 1
BB 2 BB 3
B 4
BB 5](https://image.slidesharecdn.com/dahqdrn7qsyyhs2kltks-signature-2292d91f37599d8e10b4aa90485a8bd8ad3ab0f99049b3bc375985ccda8022ce-poli-150219025901-conversion-gate02/85/Dependable-Systems-Summary-16-16-73-320.jpg)


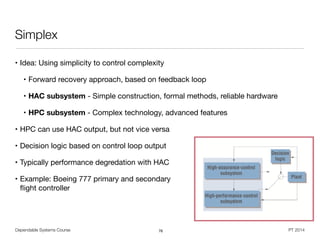
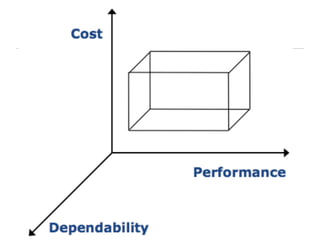

This document provides an overview of dependability and dependable systems. It defines dependability as an umbrella term that includes reliability, availability, maintainability, and other attributes that allow systems to be trusted. Dependability addresses how systems can continue operating correctly even when faults occur. Key topics covered include fault tolerance techniques, error processing, failure modes, and modeling approaches for analyzing dependability. The goal of the course is to understand how to design systems that can be relied upon to deliver their services as specified, even in the presence of faults or unexpected events.





























![Separation of concerns is a design concept [Dij82] that suggests that any com...](https://cdn.slidesharecdn.com/ss_thumbnails/272547621-250624182023-7f9053e3-thumbnail.jpg?width=640&height=640&fit=bounds)






















































