Downloaded 204 times



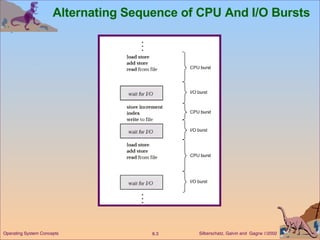
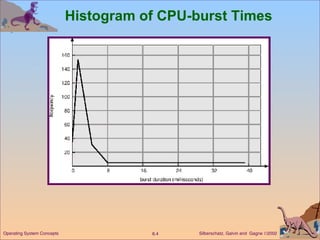




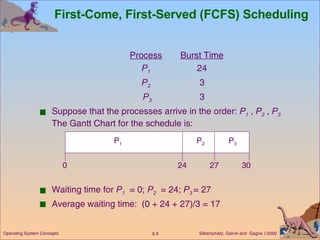


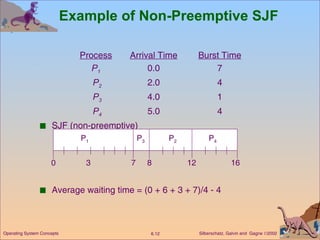


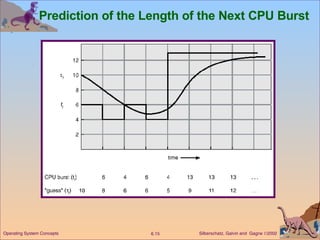





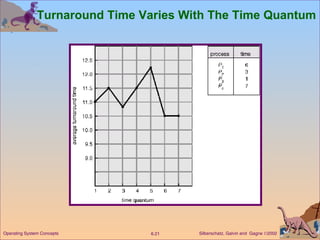




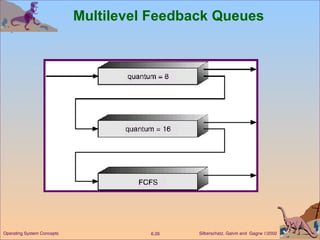


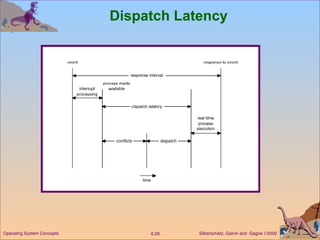

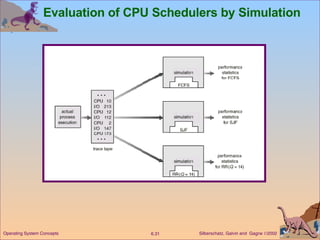
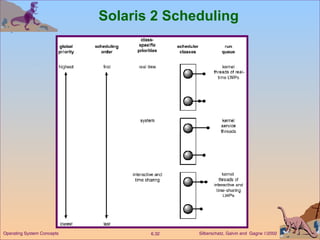
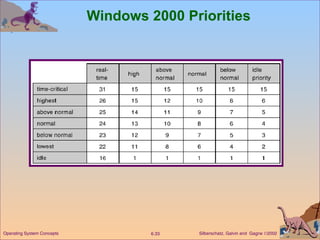

This document discusses various CPU scheduling algorithms and concepts. It covers scheduling criteria like CPU utilization and turnaround time. Algorithms discussed include first-come first-served (FCFS), shortest job first (SJF), priority scheduling, and round robin (RR). It also covers multiple processor scheduling, real-time scheduling, and evaluating scheduling algorithms.


































































































