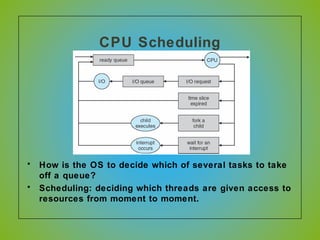
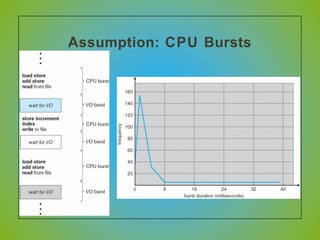
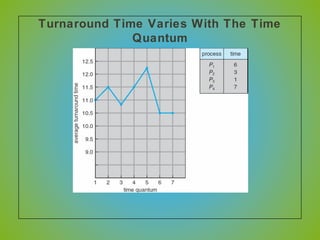
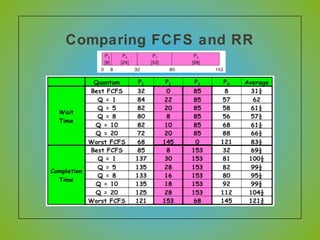
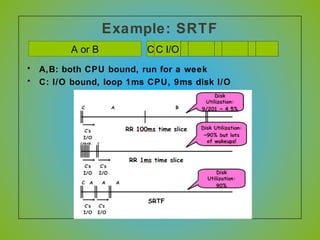
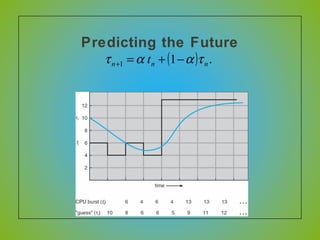
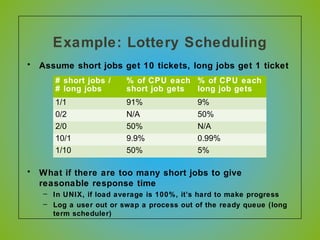
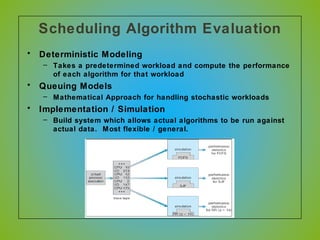
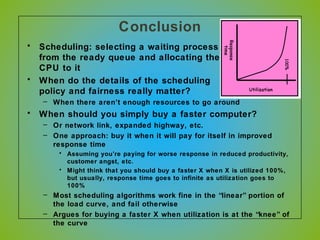
The document discusses various CPU scheduling algorithms used in operating systems including first-come, first-served (FCFS), round robin (RR), shortest job first (SJF), and shortest remaining time first (SRTF). It explains the assumptions, goals, and tradeoffs of each algorithm such as minimizing response time, maximizing throughput, and ensuring fairness. Examples are provided to illustrate how each algorithm works and its performance compared to others under different conditions involving job lengths. Predicting future job lengths is also discussed as it can impact the performance of algorithms like SRTF.