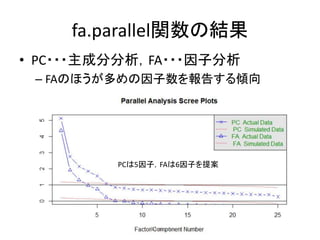
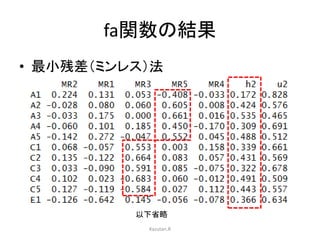
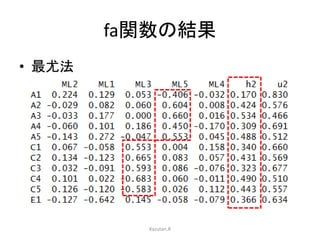
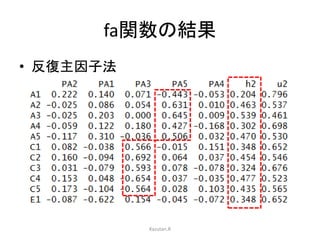
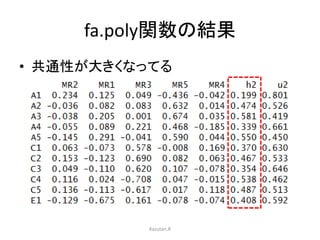
Rのpsychパッケージを用いた,因子分析の方法についてまとめています。 特に,SPSSやSASなどの商用ソフトでは実行できない,多様な分析法がpsychを使えば可能になります。その辺りの分析方法について触れています。 具体的には,因子数の決定方法,因子の抽出,回転方法,カテゴリカル因子分析などです。