例1
• xを定数 cから d へ変化させたときの yへの因果効果
= E( y | 母集団全員のxをdにする )
- E( y | ・・・ xをcにする )
=
=
=
yyxyyx ecbEedbE
cdbyx
cxdoyEdxdoyE ||
yyx
x
exby
ex
モデル1:
x
y
ex
ey yyx exby
dx
モデル1’:
x
y
d
ey
22
23.
例2
• yを定数 cから d へ変化させたときの xへの因果効果
= E( x | 母集団全員のyをdにする )
- E( x| ・・・ yをcにする )
=
=
=
xx eEeE
0
cydoxEdydoxE ||
yyx
x
exby
ex
モデル1:
x
y
ex
ey dy
ex x
モデル1’’:
x
y
ex
d
23
24.
同じ の値 :同じ個体(x以外の条件は同じ)
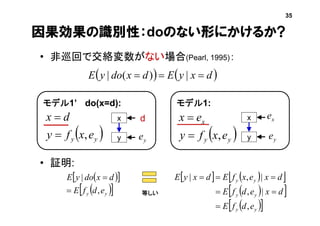
補足:個体における因果 (Pearl, 2000)
• do(x=d)のモデルでのゼウスのyと
do(x=c)のモデルでのゼウスのyを比較
cdb
ecbedbyy
yx
yyxyyxcxdx
ゼウスゼウスゼウスゼウス
yyx
x
exby
ex
モデル1:
x
y
ex
ey yyx exby
dx
モデル1’ do(x=d):
x
y
d
ey
ye ゼウス
ye
24
ゼウスゼウス
yyyy ecfedf ,,
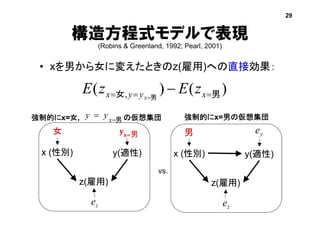
構造方程式モデルで表現
(Robins & Greenland,1992; Pearl, 2001)
• xを男から女に変えたときのz(雇用)への直接効果:
)()( , 男女 男 xyyx zEzE x
x (性別) y(適性)
z(雇用)
女
強制的にx=女, の仮想集団
x (性別) y(適性)
z(雇用)
男
強制的にx=男の仮想集団男
x
yy
𝐲 𝐱=男
29
ze ze
ye
vs.
30.
間接効果 (Pearl, 2001)
•間接効果:性別は男のまま、
適性を性別を女に変えた場合と同じにしたとしたら、
雇用される確率はどのくらい変わるか?
– 性差別を取り除いた時の、性別から雇用への効果
x (性別) y (適性)
z (雇用)
30
ye
ze
xe
31.
構造方程式モデルで表現 (Pearl, 2001)
•xを男から女に変えたときのz(雇用)への間接効果:
)()( , 男男 女 xyyx zEzE x
x (性別) y(適性)
z(雇用)
男
x (性別) y(適性)
z(雇用)
男
強制的にx=男の仮想集団
𝒚 𝒙=女
強制的にx=男, の仮想集団女
x
yy
31
ze ze
ye
vs.
LiNGAMモデルの尤度
(Hyvarinen et al.,2010)
• 生成順序𝑘 𝑖 が与えられた時の対数尤度 :
• 生成順序𝑘 𝑖 を求める必要
– 総当たりで探すのは大変: p!通り
• 分布を特定しなくても良い方法がbetter
t i i
i
i
T
i
i T
tt
pL
logloglog
xbx
X
si
2
=
1
T
xi t( )-b0,i
T
x( )
2
t
åここで ,ii epp
86
因果推論に関するレビュー
• 因果推論全般
– J.Pearl. Causal inference in statistics: An overview. Statistics Surveys
3: 96--146, 2009.
• 因果構造探索
– P. Spirtes, C. Glymour, R. Scheines, and R. E. Tillman. Automated
search for causal relations: Theory and practice. In Heuristics,
Probability, and Causality, College Publications, pp. 467-506, 2010.
• 因果構造探索法の応用(生命科学・社会科学)
– 脳: S. M. Smith. The future of FMRI connectivity. NeuroImage 62(2):
1257--1266, 2012.
– 遺伝子: P. Bühlmann. Causal statistical inference in high dimensions.
Mathematical Methods of Operations Research, 2012. In press.
– 経済: A. Moneta, N. Chlaß, D. Entner, and P. O. Hoyer. Causal search in
structural vector autoregressive models. In JMLR Workshop and
Conference Proceedings, Causality in Time Series, 12: 95-118, 2011.
• ソフトウェア(無料): TETRAD (http://www.phil.cmu.edu/projects/tetrad/).
130
















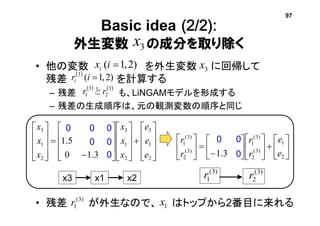
![(ノンパラ)構造方程式モデル:一般に
• 以下の四つ組(Pearl, 2000):
• 関数fと分布p(u)から分布p(v)が決まる
• vのうちの観測変数oの分布p(o)から
統計的推測を行う
:)(
,
:},,{
:],,[
:],,[
1
1
1
u
uv
f
u
v
p
fv
ff
uu
vv
ii
p
q
p
-- 構造方程式
内生変数
外生変数
(決定的)関数
外生変数の分布
16
𝑣1
𝑣2
パス図
2u
1u
o = [ 𝑣1 𝑣3] 𝑇
𝑣3 3u](https://image.slidesharecdn.com/bsj2012tutorialfinalweb-141203052348-conversion-gate02/85/slide-16-320.jpg)




















![補足: 予測との目的の違い
• 予測: 何かを観測したとき、他の何かはどのくらいか?
– 薬を飲んだ時、治癒する確率は?
– 推定したい量:
条件付き期待値: E( 治癒 | 薬=飲む)
• 因果: 何かを変化させると、他の何かがどう変化するか
– 薬を飲ませると、治癒する確率はどう変わる?
– 推定したい量:
因果効果: E[ 治癒 | do( 薬 = 飲む ) ]
– E[ 治癒 | do( 薬 = 飲まない ) ]
• 多くの場合: E[ 治癒 | do( 薬 = 飲む ) ] E( 治癒 | 薬=飲む)
39
](https://image.slidesharecdn.com/bsj2012tutorialfinalweb-141203052348-conversion-gate02/85/slide-39-320.jpg)































![独立成分分析モデル (ICAモデル)
(Jutten & Herault, 1991; Comon, 1994)
• 観測変数ベクトルxのデータ生成過程:
ここで
– 潜在変数(独立成分) 𝑠𝑖 は分散が非ゼロ、
非ガウスな密度関数、 互いに独立
– 混合行列 A = [𝑎𝑖𝑗]は正方行列でフル列ランク
• 混合行列Aは(列の置換PとスケーリングDを除いて)
識別可能:
Asx
p
j
jiji sax
1
or
APDA ica
71](https://image.slidesharecdn.com/bsj2012tutorialfinalweb-141203052348-conversion-gate02/85/slide-71-320.jpg)










































































![SSII2022 [SS2] 少ないデータやラベルを効率的に活用する機械学習技術 〜 足りない情報をどのように補うか?〜](https://cdn.slidesharecdn.com/ss_thumbnails/ss2ssii2022-220607054716-2760bd30-thumbnail.jpg?width=640&height=640&fit=bounds)




![[DL輪読会]近年のエネルギーベースモデルの進展](https://cdn.slidesharecdn.com/ss_thumbnails/energybasedmodel-200124020855-thumbnail.jpg?width=640&height=640&fit=bounds)
































