FLOPs ≠ 処理速度
•Convの部分がFLOPsで見える部分
5
N. Ma, X. Zhang, H. Zheng, and J. Sun, "ShuffleNet V2: Practical Guidelines for Efficient CNN
Architecture Design," in Proc. of ECCV, 2018.
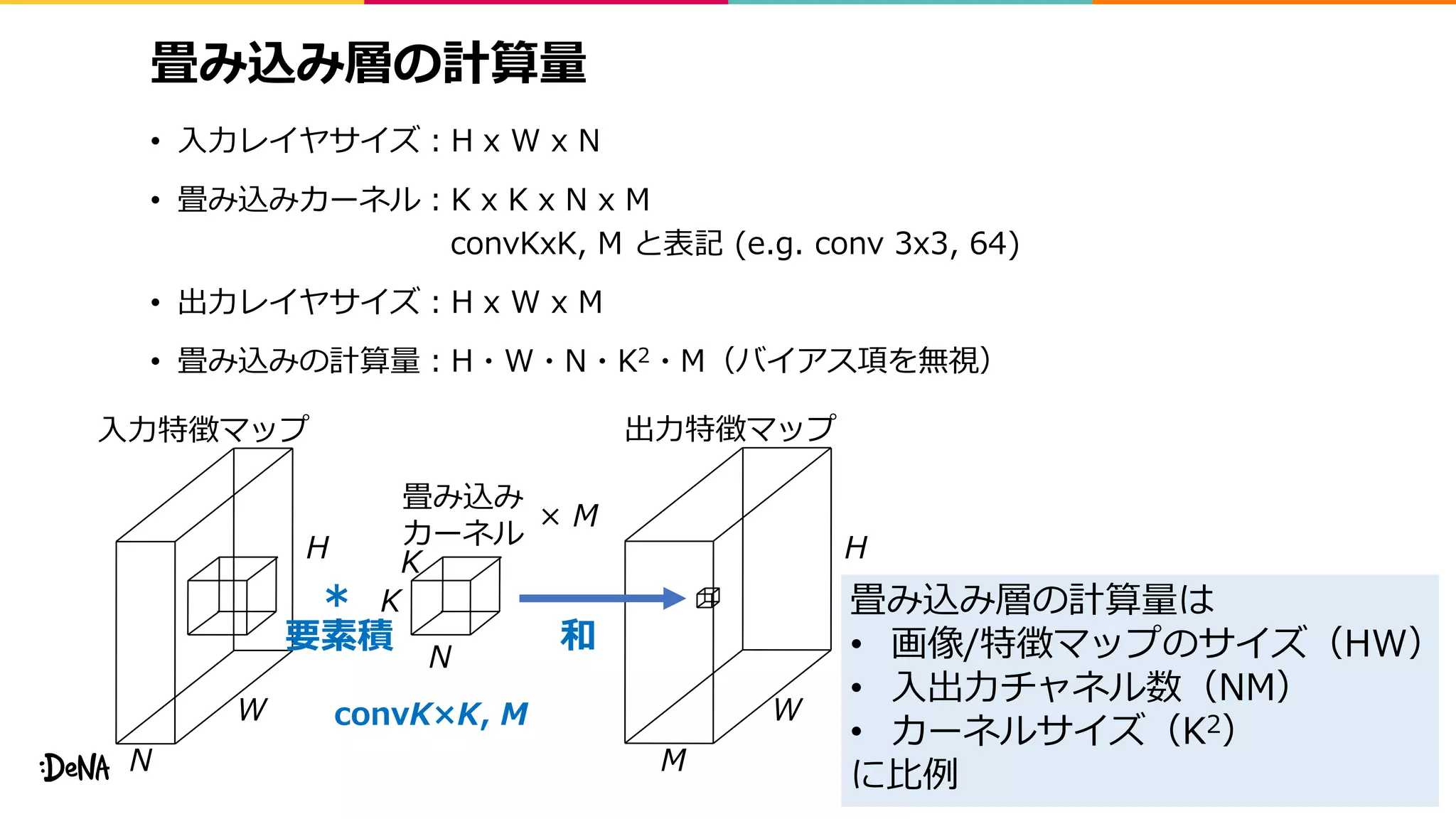
畳み込み層の計算量
• 入力レイヤサイズ:H xW x N
• 畳み込みカーネル:K x K x N x M
convKxK, M と表記 (e.g. conv 3x3, 64)
• 出力レイヤサイズ:H x W x M
• 畳み込みの計算量:H・W・N・K2・M(バイアス項を無視)
8
W
H
N M
K
K
W
H
入力特徴マップ
畳み込み
カーネル
N
出力特徴マップ
*
和要素積
× M
convK×K, M
畳み込み層の計算量は
• 画像/特徴マップのサイズ(HW)
• 入出力チャネル数(NM)
• カーネルサイズ(K2)
に比例
9.
空間方向の分解
• 大きな畳み込みカーネルを小さな畳み込みカーネルに分解
• 例えば5x5の畳み込みを3x3の畳み込み2つに分解
•これらは同じサイズの受容野を持つが分解すると計算量は25:18
• Inception-v2 [4] では最初の7x7畳み込みを3x3畳み込み3つに分解
• 以降のSENetやShuffleNetV2等の実装でも利用されている[18]
9
特徴マップ
conv5x5 conv3x3 - conv3x3
[4] C. Szegedy, et al., "Rethinking the Inception Architecture for Computer Vision," in Proc. of CVPR, 2016.
[18] T. He, et al., "Bag of Tricks for Image Classification with Convolutional Neural Networks," in Proc. of
CVPR, 2019.
SqueezeNet
• 戦略
• 3x3の代わりに1x1のフィルタを利用する
•3x3への入力となるチャネル数を少なくする(1x1で次元圧縮)
11
conv 1x1, s1x1
conv 1x1, e1x1 conv 3x3, e3x3
concat
Fire
module
32
128128
256
256
Squeeze layer
Expand layer
F. N. Iandola, S. Han, M. W. Moskewicz, K. Ashraf, W. J. Dally, and K. Keutzer, "SqueezeNet: AlexNet-level
accuracy with 50x fewer parameters and <0.5MB model size," in arXiv:1602.07360, 2016.
12.
空間方向とチャネル方向の分解 (separable conv)
•空間方向とチャネル方向の畳み込みを独立に行う
• Depthwise畳み込み(空間方向)
• 特徴マップに対しチャネル毎に畳み込み
• 計算量:H・W・N・K2・M (M=N)
H・W・K2・N
• Pointwise畳み込み(チャネル方向)
• 1x1の畳み込み
• 計算量:H・W・N・K2・M (K=1)
H・W・N・M
• Depthwise + pointwise (separable)
• 計算量:H・W・N・(K2 + M)
≒ H・W・N・M (※M >> K2)
• H・W・N・K2・M から大幅に計算量を削減
12W
H
W
H
N
1
1
M
W
H
W
H
N
K
K
N
W
H
W
H
N M
K
K通常
depthwise
pointwise
MobileNet[7]
• depthwise/pointwise convを多用
•改良版のMobileNetV2[13]/V3[20]もある
14
通常の畳み込み MobileNetの1要素
[7] A. Howard, et al., "MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications,"
in arXiv:1704.04861, 2017.
[13] M. Sandler, et al., "MobileNetV2: Inverted Residuals and Linear Bottlenecks," in Proc. of CVPR, 2018.
[20] A. Howard, et al., "Searching for MobileNetV3," in Proc. of ICCV’19.
MNasNet
• 後述のアーキテクチャ探索手法
• Mobileinverted bottleneck
にSEモジュールを追加
(MBConv)
• MBConv3 (k5x5)
→ボトルネックでチャネル数を3倍
depthwiseのカーネルが5x5
16
M. Tan, B. Chen, R. Pang, V. Vasudevan, M. Sandler, A. Howard, and Q. V. Le, "MnasNet: Platform-Aware
Neural Architecture Search for Mobile," in Proc. of CVPR, 2019.
EfficientNet
• あるネットワークが与えられ、それをベースに
より大きなネットワークを構成しようとした際の
depth, width,resolutionの増加の最適割り当て
• EfficientNet-B0 (ほぼMnasNet)
で割り当てを求め、
以降は同じように
指数的に増加させる
18
M. Tan and Q. V. Le, "EfficientNet: Rethinking Model Scaling for Convolutional Neural
Networks," in Proc. of ICML, 2019.
畳み込み層の計算量は
• 画像/特徴マップのサイズ(HW)
• 入出力チャネル数(NM)
• カーネルサイズ(K2)
に比例
19.
ShuffleNet[8]
• MobileNetのボトルネックとなっているconv1x1を
group conv1x1+ channel shuffleに置換
• group conv: 入力の特徴マップをG個にグループ化し
各グループ内で個別に畳み込みを行う
(計算量 H・W・N・K2・M → H・W・N・K2・M / G)
• channel shuffle: チャネルの順序を入れ替える
reshape + transposeの操作で実現可能
c shuffle
depthwise conv
gconv 1x1
spatial channel
gconv 1x1
[8] X. Zhang, et al., "ShuffleNet: An Extremely Efficient
Convolutional Neural Network for Mobile Devices," in
arXiv:1707.01083, 2017.
20.
ShuffleNet V2
• FLOPsではなく対象プラットフォームでの実速度を見るべき
•効率的なネットワーク設計のための4つのガイドラインを提言
1. メモリアクセス最小化のためconv1x1は入力と出力を同じにす
べし
2. 行き過ぎたgroup convはメモリアクセスコストを増加させる
3. モジュールを細分化しすぎると並列度を低下させる
4. 要素毎の演算(ReLUとかaddとか)コストは無視できない
• これらの妥当性がtoyネットワークを通して実験的に示されている
20
N. Ma, X. Zhang, H. Zheng, and J. Sun, "ShuffleNet V2: Practical Guidelines for Efficient CNN Architecture
Design," in Proc. of ECCV, 2018.
21.
ShuffleNet V2
• その上で新たなアーキテクチャを提案
21
N.Ma, X. Zhang, H. Zheng, and J. Sun, "ShuffleNet V2: Practical Guidelines for Efficient CNN Architecture
Design," in Proc. of ECCV, 2018.
22.
ChannelNet[11]
• チャネル方向に1次元の畳み込みを行う
22
[11] H.Gao, Z. Wang, and S. Ji, "ChannelNets: Compact and Efficient Convolutional Neural Networks
via Channel-Wise Convolutions", in Proc. of NIPS, 2018.
他にも…
25
G. Huang, S.Liu, L. Maaten, and K. Weinberger, "CondenseNet: An Efficient DenseNet using Learned
Group Convolutions," in Proc. of CVPR, 2018.
T. Zhang, G. Qi, B. Xiao, and J. Wang. Interleaved group convolutions for deep neural networks," in Proc.
of ICCV, 2017.
G. Xie, J. Wang, T. Zhang, J. Lai, R. Hong, and G. Qi, "IGCV2: Interleaved Structured Sparse
Convolutional Neural Networks, in Proc. of CVPR, 2018.
K. Sun, M. Li, D. Liu, and J. Wang, "IGCV3: Interleaved Low-Rank Group Convolutions for Efficient Deep
Neural Networks," in BMVC, 2018.
J. Zhang, "Seesaw-Net: Convolution Neural Network With Uneven Group Convolution," in
arXiv:1905.03672, 2019.
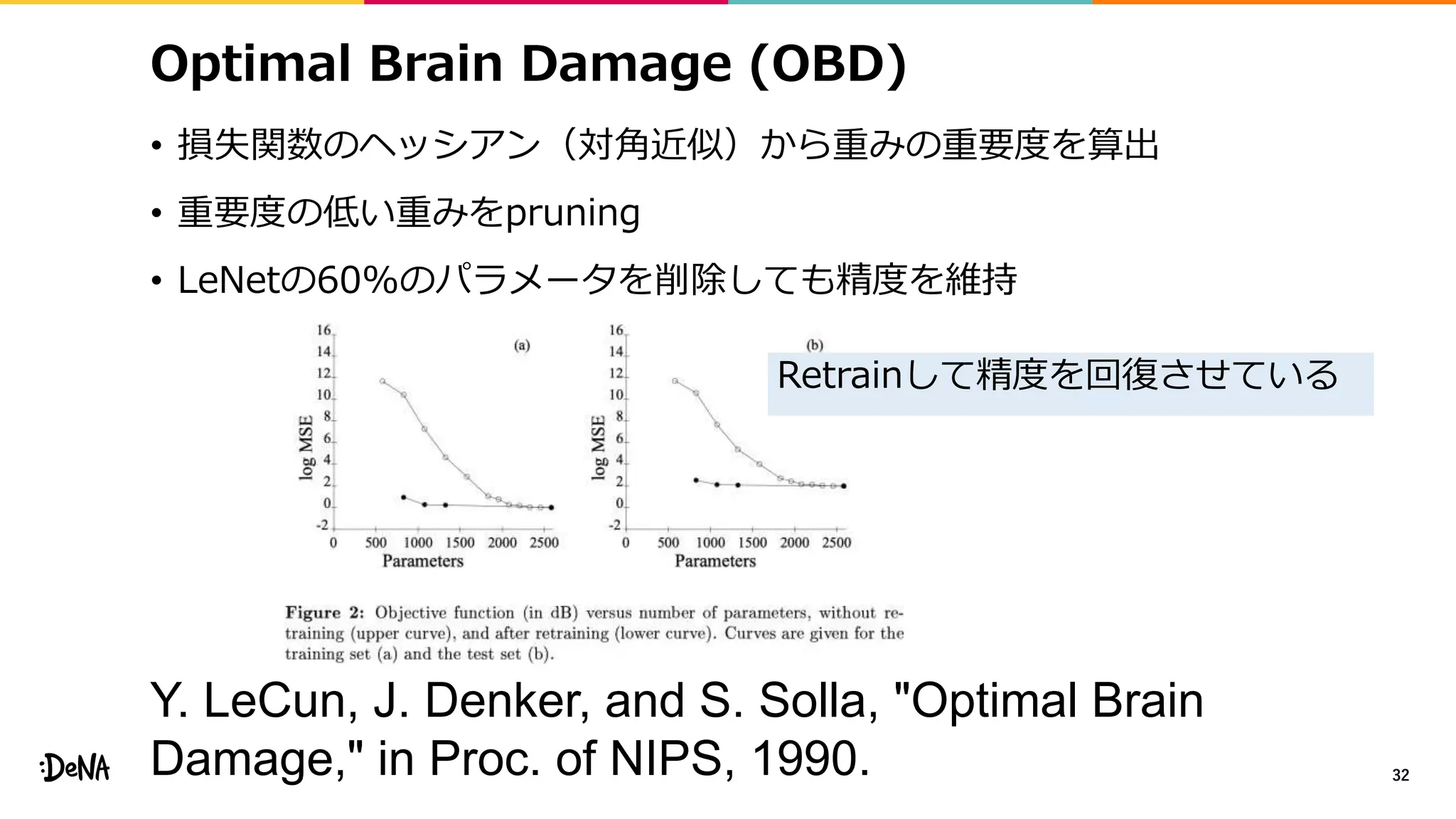
Optimal Brain Damage(OBD)
• 損失関数のヘッシアン(対角近似)から重みの重要度を算出
• 重要度の低い重みをpruning
• LeNetの60%のパラメータを削除しても精度を維持
31
Y. LeCun, J. Denker, and S. Solla, "Optimal Brain
Damage," in Proc. of NIPS, 1990.
32.
Optimal Brain Damage(OBD)
• 損失関数のヘッシアン(対角近似)から重みの重要度を算出
• 重要度の低い重みをpruning
• LeNetの60%のパラメータを削除しても精度を維持
32
Y. LeCun, J. Denker, and S. Solla, "Optimal Brain
Damage," in Proc. of NIPS, 1990.
Retrainして精度を回復させている
33.
Deep Compression[23, 25,26]
• Unstructuredなpruning
• L2正則化を加えて学習し、絶対値が小さいweightを0に
• 実際に高速に動かすには専用ハードが必要[26]
33
[23] S. Han, et al., "Learning both Weights and Connections for Efficient Neural Networks," in Proc. of NIPS, 2015.
[25] S. Han, et al., "Deep Compression: Compressing Deep Neural Networks with Pruning, Trained Quantization
and Huffman Coding," in Proc. of ICLR, 2016.
[26] S. Han, et al., "EIE: Efficient Inference Engine on Compressed Deep Neural Network," in Proc. of ISCA, 2016.
34.
Pruning Filters forEfficient ConvNets[30]
• Structured pruning(チャネルレベルのpruning)
• 各レイヤについて、フィルタの重みの絶対値の総和が
小さいものからpruning
• 各レイヤのpruning率はpruningへのsensitivityから
人手で調整
• Pruning後にfinetune
34[30] H. Li, et al., "Pruning Filters for Efficient ConvNets," in Proc. of ICLR, 2017.
35.
Network Slimming[33]
• BatchnormのパラメータγにL1ロスをかけて学習
• 学習後、γが小さいチャネルを削除し、fine-tune
35
チャネル毎に入力を平均0分散1に正規化、γとβでscale & shift
チャネルi
Batch
normalization
[33] Z. Liu, et al., "Learning Efficient Convolutional Networks through Network Slimming," in Proc. of ICCV,
2017.
36.
L0ではなくLasso
に緩和して解く
Channel Pruning[34]
• あるfeaturemapのチャネル削除した場合に
次のfeature mapの誤差が最小となるようチャネルを選択
• Wも最小二乗で調整
36[34] Y. He, et al., "Channel Pruning for Accelerating Very Deep Neural Networks," in Proc. of ICCV, 2017.
AutoML for ModelCompression and Acceleration (AMC)[41]
• 強化学習(off-policy actor-critic)により各レイヤ毎の最適な
pruning率を学習(実際のpruningは他の手法を利用)
• 入力は対象レイヤの情報とそれまでのpruning結果、
報酬は –エラー率×log(FLOPs) or log(#Params)
38
[41] Y. He, et al., "AMC - AutoML for Model Compression and Acceleration on Mobile Devices," in Proc. of
ECCV, 2018.
39.
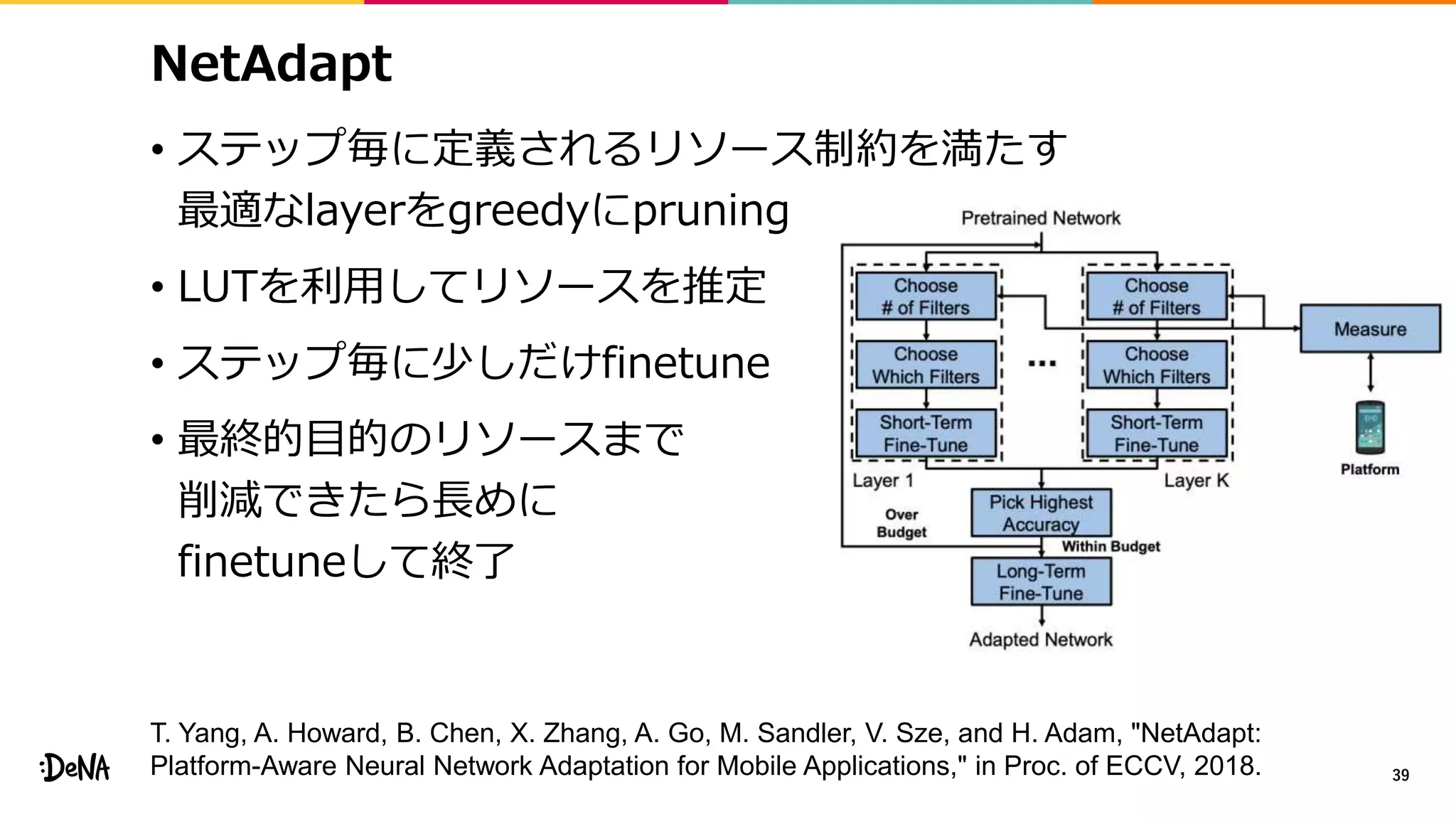
NetAdapt
• ステップ毎に定義されるリソース制約を満たす
最適なlayerをgreedyにpruning
• LUTを利用してリソースを推定
•ステップ毎に少しだけfinetune
• 最終的目的のリソースまで
削減できたら長めに
finetuneして終了
39
T. Yang, A. Howard, B. Chen, X. Zhang, A. Go, M. Sandler, V. Sze, and H. Adam, "NetAdapt:
Platform-Aware Neural Network Adaptation for Mobile Applications," in Proc. of ECCV, 2018.
40.
Lottery Ticket Hypothesis(ICLR’19 Best Paper)[44]
• NNには、「部分ネットワーク構造」と「初期値」の
組み合わせに「当たり」が存在し、それを引き当てると
効率的に学習が可能という仮説
• Unstructuredなpruningでその構造と初期値を見つけることができた
40
https://www.slideshare.net/YosukeShinya/the-lottery-ticket-hypothesis-finding-small-trainable-neural-networks
[44] Jonathan Frankle, Michael Carbin, "The Lottery Ticket Hypothesis: Finding Sparse, Trainable Neural
Networks," in Proc. of ICLR, 2019.
41.
Network Pruning asArchitecture Search[45]
• Structuredなpruning後のネットワークをscratchから学習させても
finetuneと同等かそれより良い結果が得られるという主張
• つまりpruningは、重要な重みを探索しているのではなく
各レイヤにどの程度のチャネル数を割り当てるかという
Neural Architecture Search (NAS) をしているとみなせる
• Lottery Ticket Hypothesisではunstructuredで、低LRのみ、
実験も小規模ネットワークのみ
41[45] Z. Liu, et al., "Rethinking the Value of Network Pruning," in Proc. of ICLR, 2019.
42.
Slimmable Neural Networks*
•1モデルだが複数の計算量(精度)で動かせるモデルを学習
• Incremental trainingだと精度が出ない
• 同時学習だとBNの統計量が違うため学習できない
→ 切替可能なモデルごとにBN層だけを個別に持つ!
• もっと連続的に変化できるモデル**や、そこからgreedyにpruning
する(精度低下が最も小さいレイヤを削っていく)拡張***も
42
* J. Yu, L. Yang, N. Xu, J. Yang, and T. Huang, "Slimmable Neural Networks," in Proc. of ICLR, 2019.
** J. Yu and T. Huang, "Universally Slimmable Networks and Improved Training Techniques," in
arXiv:1903.05134, 2019.
*** J. Yu and T. Huang, "Network Slimming by Slimmable Networks: Towards One-Shot Architecture
Search for Channel Numbers," in arXiv:1903.11728, 2019.
43.
MetaPruning
• Pruning後のネットワークの重みを
出力するPruningNetを学習
• Blockへの入力はNetworkencoding vector
前および対象レイヤのランダムなpruning率
• 全部入れたほうが良さそうな気がするが
著者に聞いたところ効果なし
• End-to-endで学習できる!
• 学習が終わると精度vs.速度のトレードオフの
優れたモデルを探索(手法は何でも良い)ここではGA
43
Z. Liu, H. Mu, X. Zhang, Z. Guo, X. Yang, T. Cheng, and J. Sun, "MetaPruning: Meta Learning for
Automatic Neural Network Channel Pruning," in Proc. of ICCV’19.
アーキテクチャ探索 (NAS)
• NNのアーキテクチャを自動設計する手法
•探索空間、探索手法、精度評価手法で大まかに分類される
• 探索空間
• Global, cell-based
• 探索手法
• 強化学習、進化的アルゴリズム、gradientベース、random
• 精度測定手法
• 全学習、部分学習、weight-share、枝刈り探索
45
T. Elsken, J. Metzen, and F. Hutter, "Neural Architecture Search: A Survey," in JMLR, 2019.
M. Wistuba, A. Rawat, and T. Pedapati, "A Survey on Neural Architecture Search," in arXiv:1905.01392, 2019.
https://github.com/D-X-Y/awesome-NAS
46.
NAS with ReinforcementLearning
• 探索空間:global、探索手法:REINFORCE
• RNNのcontrollerがネットワーク構造を生成
• 畳み込み層のパラメータと、skip connectionの有無を出力
• 生成されたネットワークを学習し、その精度を報酬にする
46Zoph and Q. V. Le, "Neural architecture search with reinforcement learning," in Proc. of ICLR, 2017.
47.
NAS with ReinforcementLearning
• 800GPUs for 28 daysの成果
47Zoph and Q. V. Le, "Neural architecture search with reinforcement learning," in Proc. of ICLR, 2017.
48.
NASNet[52]
• 探索空間:cell、
探索手法:強化学習 (ProximalPolicy Optimization)
• Globalな設計にドメイン知識を活用、
構成するcellのみを自動設計
→探索空間を大幅に削減
• Normal cell x Nとreduction cellのスタック
• Reduction cellは最初にstride付きのOPで
特徴マップをダウンサンプル
• Reduction cell以降でチャネルを倍に
48
[52] B. Zoph, V. Vasudevan, J. Shlens, and Q. V. Le, "Learning transferable architectures for scalable
image recognition," in Proc. of CVPR, 2018.
49.
NASNetのコントローラの動作
1. Hidden state※11, 2を選択
2. それらへのOPsを選択※2
3. それらを結合するOP (add or concat)
を選択し新たなhidden stateとする
※1 Hidden state: 緑のブロックとhi, hi-I
※2 Hidden stateへのOP候補
49
[52] B. Zoph, V. Vasudevan, J. Shlens, and Q. V. Le, "Learning transferable architectures for scalable
image recognition," in Proc. of CVPR, 2018.
50.
NASNetのコントローラの動作
1. Hidden state※11, 2を選択
2. それらへのOPsを選択※2
3. それらを結合するOP (add or concat)
を選択し新たなhidden stateとする
※1 Hidden state: 緑のブロックとhi, hi-I
※2 Hidden stateへのOP候補
50
[52] B. Zoph, V. Vasudevan, J. Shlens, and Q. V. Le, "Learning transferable architectures for scalable
image recognition," in Proc. of CVPR, 2018.
51.
NASNetのコントローラの動作
1. Hidden state※11, 2を選択
2. それらへのOPsを選択※2
3. それらを結合するOP (add or concat)
を選択し新たなhidden stateとする
※1 Hidden state: 緑のブロックとhi, hi-I
※2 Hidden stateへのOP候補
51
sep
3x3
avg
3x3
[52] B. Zoph, V. Vasudevan, J. Shlens, and Q. V. Le, "Learning transferable architectures for scalable
image recognition," in Proc. of CVPR, 2018.
52.
NASNetのコントローラの動作
1. Hidden state※11, 2を選択
2. それらへのOPsを選択※2
3. それらを結合するOP (add or concat)
を選択し新たなhidden stateとする
※1 Hidden state: 緑のブロックとhi, hi-I
※2 Hidden stateへのOP候補
52
concat
sep
3x3
avg
3x3
[52] B. Zoph, V. Vasudevan, J. Shlens, and Q. V. Le, "Learning transferable architectures for scalable
image recognition," in Proc. of CVPR, 2018.
53.
ENAS[54]
• 探索空間:cell、探索手法:強化学習 (REINFORCE)
•Cellの構造を出力するRNNコントローラと、
コントローラーが出力する全てのネットワークをサブグラフとして
保持できる巨大な計算グラフ(ネットワーク)を同時に学習
→生成したネットワークの学習が不要に(1GPU for 0.45 days!)
• Single shot, weight share
• 詳細は神資料*を参照
53
[54] H. Pham, M. Y. Guan, B. Zoph, Q. V. Le, and Jeff Dean, "Efficient Neural Architecture
Search via Parameter Sharing," in Proc. of ICML, 2018.
* https://www.slideshare.net/tkatojp/efficient-neural-architecture-search-via-parameters-
sharing-icml2018
FBNet[61]
• DARTSと同じくgradient-based
• 各OPの実デバイス上での処理時間をlookuptableに保持
• 処理時間を考慮したロスをかける
• ブロック毎に違う構造
56
[61] B. Wu, et al., "FBNet: Hardware-Aware Efficient ConvNet Design via Differentiable Neural Architecture
Search", in Proc. of CVPR, 2019.
クロスエントロピー 処理時間
57.
Random Search系
• Weightshare + random search (ASHA) が良い*
• Asynchronous Successive Halving (ASHA):複数のモデルを平行
に学習を進めながら有望なものだけを残して枝刈り
• Optunaで使えるよ!**
• 探索空間を、ランダムなDAG生成アルゴリズムが生成するグラフ
にすると想像以上に良い***
57
* L. Li and A. Talwalkar, "Random search and reproducibility for neural architecture search," in
arXiv:1902.07638, 2019.
** https://www.slideshare.net/shotarosano5/automl-in-neurips-2018
*** S. Xie, A. Kirillov, R. Girshick, and K. He, "Exploring Randomly Wired Neural Networks for Image
Recognition," in arXiv:1904.01569, 2019.
58.
他にも
[58] H. Cai,L. Zhu, and S. Han, "ProxylessNAS: Direct Neural Architecture
Search on Target Task and Hardware," in Proc. of ICLR, 2019.
[59] M. Tan, B. Chen, R. Pang, V. Vasudevan, M. Sandler, A. Howard, and Q.
V. Le, "MnasNet: Platform-Aware Neural Architecture Search for Mobile," in
Proc. of CVPR, 2019.
[60] X. Dai, et al., "ChamNet: Towards Efficient Network Design through
Platform-Aware Model Adaptation," in Proc. of CVPR, 2019.
[62] D. Stamoulis, et al., "Single-Path NAS: Device-Aware Efficient ConvNet
Design," in Proc. of ICMLW, 2019.
58
Spatially Adaptive ComputationTime (SACT)[66]
• ACT: 各ResBlockがhalting scoreを出力、合計が1を超えると
以降の処理をスキップ(空間領域でも行うとSACT)
62
計算量に関する勾配を追加
[66] M. Figurnov, et al., "Spatially Adaptive Computation Time for Residual Networks," in Proc. of CVPR, 2017.
63.
Runtime Neural Pruning[68]
•各レイヤ毎に、直前までの特徴マップを入力とするRNNが
利用する畳み込みフィルタ集合を決定
• Keepした畳み込みフィルタ数と元タスクの損失関数(最終層の場
合)を負の報酬としてQ学習でRNNを学習
63[68] J. Lin, et al., "Runtime Neural Pruning," in Proc. of NIPS, 2017.
64.
BlockDrop[73]
• Policy networkに画像を入力、どのBlockをスキップするかを出力
•KeepとなったResBlockのみをforward
• 認識が失敗した場合は負の報酬を、成功した場合にはスキップ率に
応じた正の報酬を与えることでpolicy networkを学習
64[73] Z. Wu, et al., "BlockDrop: Dynamic Inference Paths in Residual Networks," in Proc. of CVPR, 2018.
Distilling the Knowledgein a Neural Network[77]
67
……
学習画像
学習済みモデル
学習するモデル
…
正解ラベル
(ハード
ターゲッ
ト)
通常T = 1のsoftmaxのTを大きくした
ソフトターゲットを利用
…
ソフトターゲット
ソフト
ターゲット
ハード
ターゲット
正解ラベルと
学習モデル出力の
両方を利用
[77] G. Hinton, et al., "Distilling the Knowledge in a
Neural Network," in Proc. of NIPS Workshop, 2014.
WAGE[96]
• weights (W),activations (A), gradients (G), errors (E)
の全てを量子化
72[96] S. Wu, et al., "Training and Inference with Integers in Deep Neural Networks," in Proc. of ICLR, 2018.
73.
WAGE[96]
• weights (W),activations (A), gradients (G), errors (E)
73
バイナリ
[96] S. Wu, et al., "Training and Inference with Integers in Deep Neural Networks," in Proc. of ICLR, 2018.
74.
Quantization and Trainingof Neural Networks for
Efficient Integer-Arithmetic-Only Inference[97]
• 推論時にuint8の演算がメインとなるように
学習時に量子化をシミュレーションしながら学習
• TensorFlow公式に実装が存在*
74
[97] B. Jacob, et al., "Quantization and Training of Neural Networks for Efficient Integer-Arithmetic-Only
Inference," in Proc. of CVPR, 2018.
* https://github.com/tensorflow/tensorflow/blob/master/tensorflow/contrib/quantize/README.md
畳み込みの分解
[1] L. Sifreand S. Mallat, "Rotation, Scaling and Deformation Invariant Scattering for Texture Discrimination," in Proc. of CVPR, 2013.
[2] L. Sifre, "Rigid-motion Scattering for Image Classification, in Ph.D. thesis, 2014.
[3] M. Lin, Q. Chen, and S. Yan, "Network in Network," in Proc. of ICLR, 2014.
[4] C. Szegedy, et al., "Rethinking the Inception Architecture for Computer Vision," in Proc. of CVPR, 2016.
[5] F. N. Iandola, S. Han, M. W. Moskewicz, K. Ashraf, W. J. Dally, and K. Keutzer, "SqueezeNet: AlexNet-level accuracy with 50x fewer parameters and
<0.5MB model size," in arXiv:1602.07360, 2016.
[6] F. Chollet, "Xception: Deep learning with depthwise separable convolutions," in Proc. of CVPR, 2017.
[7] A. Howard, et al., "MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications," in arXiv:1704.04861, 2017.
[8] X. Zhang, et al., "ShuffleNet: An Extremely Efficient Convolutional Neural Network for Mobile Devices," in arXiv:1707.01083, 2017.
[9] B. Wu, et al., "Shift: A Zero FLOP, Zero Parameter," in arXiv:1711.08141, 2017.
[10] N. Ma, X. Zhang, H. Zheng, and J. Sun, "ShuffleNet V2: Practical Guidelines for Efficient CNN Architecture Design," in Proc. of ECCV, 2018.
[11] H. Gao, Z. Wang, and S. Ji, "ChannelNets: Compact and Efficient Convolutional Neural Networks via Channel-Wise Convolutions", in Proc. of NIPS,
2018.
[12] G. Huang, S. Liu, L. Maaten, and K. Weinberger, "CondenseNet: An Efficient DenseNet using Learned Group Convolutions," in Proc. of CVPR, 2018.
[13] M. Sandler, et al., "MobileNetV2: Inverted Residuals and Linear Bottlenecks," in Proc. of CVPR, 2018.
[14] G. Xie, J. Wang, T. Zhang, J. Lai, R. Hong, and G. Qi, "IGCV2: Interleaved Structured Sparse Convolutional Neural Networks, in Proc. of CVPR, 2018.
82
83.
畳み込みの分解
[15] T. Zhang,G. Qi, B. Xiao, and J. Wang, "Interleaved group convolutions for deep neural networks," in Proc. of ICCV, 2017.
[16] Z. Qin, Z. Zhang, X. Chen, and Y. Peng, "FD-MobileNet: Improved MobileNet with a Fast Downsampling Strategy," in Proc. of ICIP, 2018.
[17] K. Sun, M. Li, D. Liu, and J. Wang, "IGCV3: Interleaved Low-Rank Group Convolutions for Efficient Deep Neural Networks," in BMVC, 2018.
[18] T. He, et al., "Bag of Tricks for Image Classification with Convolutional Neural Networks," in Proc. of CVPR, 2019.
[19] Y. Chen, et al., "Drop an Octave: Reducing Spatial Redundancy in Convolutional Neural Networks with Octave Convolution," in arXiv:1904.05049,
2019.
[20] A. Howard, et al., "Searching for MobileNetV3," in arXiv:1905.02244, 2019.
[21] J. Zhang, "Seesaw-Net: Convolution Neural Network With Uneven Group Convolution," in arXiv:1905.03672, 2019.
83
84.
枝刈り
[22] Y. LeCun,J. Denker, and S. Solla, "Optimal Brain Damage," in Proc. of NIPS, 1990.
[23] S. Han, J. Pool, J. Tran, and W. Dally, "Learning both Weights and Connections for Efficient Neural Networks," in Proc. of NIPS, 2015.
[24] W. Wen, C. Wu, Y. Wang, Y. Chen, and H. Li, "Learning Structured Sparsity in Deep Neural Networks," in Proc. of NIPS, 2016.
[25] S. Han, et al., "Deep Compression: Compressing Deep Neural Networks with Pruning, Trained Quantization and Huffman Coding," in Proc. of ICLR,
2016.
[26] S. Han, J. Pool, J. Tran, and W. Dally, "EIE: Efficient Inference Engine on Compressed Deep Neural Network," in Proc. of ISCA, 2016.
[27] S. Anwar, K. Hwang, and W. Sung, "Structured Pruning of Deep Convolutional Neural Networks," in JETC, 2017.
[28] S. Changpinyo, M. Sandler, and A. Zhmoginov, "The Power of Sparsity in Convolutional Neural Networks," in arXiv:1702.06257, 2017.
[29] S. Scardapane, D. Comminiello, A. Hussain, and A. Uncini, "Group Sparse Regularization for Deep Neural Networks," in Neurocomputing, 2017.
[30] H. Li, et al., "Pruning Filters for Efficient ConvNets," in Proc. of ICLR, 2017.
[31] P. Molchanov, S. Tyree, T. Karras, T. Aila, and J. Kautz, "Pruning Convolutional Neural Networks for Resource Efficient Inference," in Proc. of ICLR,
1017.
[32] D. Molchanov, A. Ashukha, and D. Vetrov, "Variational Dropout Sparsifies Deep Neural Networks," in Proc. of ICML, 2017.
[33] Z. Liu, et al., "Learning Efficient Convolutional Networks through Network Slimming," in Proc. of ICCV, 2017.
[34] Y. He, et al., "Channel Pruning for Accelerating Very Deep Neural Networks," in Proc. of ICCV, 2017.
[35] J. Luo, et al., "ThiNet: A Filter Level Pruning Method for Deep Neural Network Compression," in Proc. of ICCV, 2017.
[36] C. Louizos, K. Ullrich, and M. Welling, "Bayesian Compression for Deep Learning," in Proc. of NIPS, 2017.
84
85.
枝刈り
[37] Kirill Neklyudov,Dmitry Molchanov, Arsenii Ashukha, Dmitry Vetrov, "Structured Bayesian Pruning via Log-Normal Multiplicative Noise," in Proc. of
NIPS, 2017.
[38] M. Zhu and S. Gupta, "To prune, or not to prune: exploring the efficacy of pruning for model compression," in Proc. of ICLRW, 2018.
[39] T. Yang, Y. Chen, and V. Sze, "Designing Energy-Efficient Convolutional Neural Networks Using Energy-Aware Pruning," in Proc. of CVPR, 2017.
[40] Y. He, G. Kang, X. Dong, Y. Fu, and Y. Yang, "Soft Filter Pruning for Accelerating Deep Convolutional Neural Networks," in Proc. of IJCAI, 2018.
[41] Y. He, et al., "AMC - AutoML for Model Compression and Acceleration on Mobile Devices," in Proc. of ECCV, 2018.
[42] T. Yang, A. Howard, B. Chen, X. Zhang, A. Go, M. Sandler, V. Sze, and H. Adam, "NetAdapt: Platform-Aware Neural Network Adaptation for Mobile
Applications," in Proc. of ECCV, 2018.
[43] J. Luo and J. Wu, "AutoPruner: An End-to-End Trainable Filter Pruning Method for Efficient Deep Model Inference," in arXiv:1805.08941, 2018.
[44] J. Frankle and M. Carbin, "The Lottery Ticket Hypothesis: Finding Sparse, Trainable Neural Networks," in Proc. of ICLR, 2019.
[45] Z. Liu, et al., "Rethinking the Value of Network Pruning," in Proc. of ICLR, 2019.
[46] J. Yu, L. Yang, N. Xu, J. Yang, and T. Huang, "Slimmable Neural Networks," in Proc. of ICLR, 2019.
[47] S. Lin, R. Ji, C. Yan, B. Zhang, L. Cao, Q. Ye, F. Huang, and D. Doermann, "Towards Optimal Structured CNN Pruning via Generative Adversarial
Learning," in Proc. of CVPR, 2019. GAN
[48] J. Yu and T. Huang, "Universally Slimmable Networks and Improved Training Techniques," in arXiv:1903.05134, 2019.
[49] J. Yu and T. Huang, "Network Slimming by Slimmable Networks: Towards One-Shot Architecture Search for Channel Numbers," in arXiv:1903.11728,
2019.
[50] Z. Liu, H. Mu, X. Zhang, Z. Guo, X. Yang, T. Cheng, and J. Sun, "MetaPruning: Meta Learning for Automatic Neural Network Channel Pruning," in
arXiv:1903.10258, 2019.
85
86.
アーキテクチャ探索
[51] B. Zophand Q. V. Le, "Neural architecture search with reinforcement learning," in Proc. of ICLR, 2017.
[52] B. Zoph, V. Vasudevan, J. Shlens, and Q. V. Le, "Learning transferable architectures for scalable image recognition," in Proc. of CVPR, 2018.
[53] C. Liu, et al., "Progressive Neural Architecture Search," in Proc. of ECCV, 2018.
[54] H. Pham, M. Y. Guan, B. Zoph, Q. V. Le, and Jeff Dean, "Efficient Neural Architecture Search via Parameter Sharing," in Proc. of ICML, 2018.
[55] H. Liu, K. Simonyan, O. Vinyals, C. Fernando, and K. Kavukcuoglu, "Hierarchical Representations for Efficient Architecture Search," in Proc. of ICLR,
2018.
[56] E. Real, A. Aggarwal, Y. Huang, Q. V. Le, "Regularized Evolution for Image Classifier Architecture Search," in Proc. of AAAI, 2019.
[57] H. Liu, K. Simonyan, and Y. Yang, "DARTS: Differentiable Architecture Search," in Proc. of ICLR, 2019.
[58] H. Cai, L. Zhu, and S. Han, "ProxylessNAS: Direct Neural Architecture Search on Target Task and Hardware," in Proc. of ICLR, 2019.
[59] M. Tan, B. Chen, R. Pang, V. Vasudevan, M. Sandler, A. Howard, and Q. V. Le, "MnasNet: Platform-Aware Neural Architecture Search for Mobile," in
Proc. of CVPR, 2019.
[60] X. Dai, et al., "ChamNet: Towards Efficient Network Design through Platform-Aware Model Adaptation," in Proc. of CVPR, 2019.
[61] B. Wu, et al., "FBNet: Hardware-Aware Efficient ConvNet Design via Differentiable Neural Architecture Search", in Proc. of CVPR, 2019.
[62] D. Stamoulis, et al., "Single-Path NAS: Device-Aware Efficient ConvNet Design," in Proc. of ICMLW, 2019.
[63] L. Li and A. Talwalkar, "Random search and reproducibility for neural architecture search," in arXiv:1902.07638, 2019.
86
87.
早期終了、動的計算グラフ
[64] Y. Guo,A. Yao, and Y. Chen, "Dynamic Network Surgery for Efficient DNNs," in Proc. of NIPS, 2016.
[65] S. Teerapittayanon, et al., "BranchyNet: Fast Inference via Early Exiting from Deep Neural Networks," in Proc. of ICPR, 2016.
[66] M. Figurnov, et al., "Spatially Adaptive Computation Time for Residual Networks," in Proc. of CVPR, 2017.
[67] T. Bolukbasi, J. Wang, O. Dekel, and V. Saligrama, "Adaptive Neural Networks for Efficient Inference," in Proc. of ICML, 2017.
[68] J. Lin, et al., "Runtime Neural Pruning," in Proc. of NIPS, 2017.
[69] G. Huang, D. Chen, T. Li, F. Wu, L. Maaten, and K. Weinberger, "Multi-Scale Dense Networks for Resource Efficient Image Classification," in Proc. of
ICLR, 2018.
[70] X. Wang, F. Yu, Z. Dou, T. Darrell, and J. Gonzalez, "SkipNet: Learning Dynamic Routing in Convolutional Networks," in Proc. of ECCV, 2018.
[71] A. Veit and S. Belongie, "Convolutional Networks with Adaptive Inference Graphs," in Proc. of ECCV, 2018.
[72] L. Liu and J. Deng, "Dynamic Deep Neural Networks: Optimizing Accuracy-Efficiency Trade-Offs by Selective Execution," in Proc. of AAAI, 2018.
[73] Z. Wu, et al., "BlockDrop: Dynamic Inference Paths in Residual Networks," in Proc. of CVPR, 2018.
[74] R, Yu, et al., "NISP: Pruning Networks using Neuron Importance Score Propagation," in Proc. of CVPR, 2018.
[75] J. Kuen, X. Kong, Z. Lin, G. Wang, J. Yin, S. See, and Y. Tan, "Stochastic Downsampling for Cost-Adjustable Inference and Improved Regularization
in Convolutional Networks," in Proc. of CVPR, 2018.
[76] X. Gao, Y. Zhao, L. Dudziak, R. Mullins, and C. Xu, "Dynamic Channel Pruning: Feature Boosting and Suppression," in Proc. of ICLR, 2019.
87
88.
蒸留
[77] G. Hinton,et al., "Distilling the Knowledge in a Neural Network," in Proc. of NIPS Workshop, 2014.
[78] J. Ba and R. Caruana, "Do Deep Nets Really Need to be Deep?," in Proc. of NIPS, 2014.
[79] A. Romero, et al., "FitNets: Hints for Thin Deep Nets," in Proc. of ICLR, 2015.
[80] T. Chen, I. Goodfellow, and J. Shlens, "Net2Net: Accelerating Learning via Knowledge Transfer," in Proc. of ICLR, 2016.
[81] G. Urban, et al., "Do Deep Convolutional Nets Really Need to be Deep and Convolutional?," in Proc. of ICLR, 2017.
[82] J. Yim, D. Joo, J. Bae, and J. Kim, "A Gift from Knowledge Distillation: Fast Optimization, Network Minimization and Transfer Learning," in Proc. of
CVPR, 2017.
[83] A. Mishra and D. Marr, "Apprentice: Using Knowledge Distillation Techniques To Improve Low-Precision Network Accuracy," in Proc. of ICLR, 2018.
[84] T. Furlanello, Z. Lipton, M. Tschannen, L. Itti, and A. Anandkumar, "Born Again Neural Networks," in Proc. of ICML, 2018.
[85] Y. Zhang, T. Xiang, T. Hospedales, and H. Lu, "Deep Mutual Learning," in Proc. of CVPR, 2018.
[86] X. Lan, X. Zhu, and S. Gong, "Knowledge Distillation by On-the-Fly Native Ensemble," in Proc. of NIPS, 2018.
[87] W. Park, D. Kim, Y. Lu, and M. Cho, "Relational Knowledge Distillation," in Proc. of CVPR, 2019.
88
89.
量子化
[88] M. Courbariaux,Y. Bengio, and J. David, "BinaryConnect: Training Deep Neural Networks with binary weights during propagations," in Proc. of NIPS,
2015.
[89] I. Hubara, M. Courbariaux, D. Soudry, R. El-Yaniv, and Y. Bengio, "Binarized Neural Networks," in Proc. of NIPS, 2016.
[90] M. Rastegari, V. OrdonezJoseph, and R. Farhadi, "XNOR-Net: ImageNet Classification Using Binary Convolutional Neural Networks," in Proc. of ECCV,
2016.
[91] J. Wu, C. Leng, Y. Wang, Q. Hu, and J. Cheng, "Quantized Convolutional Neural Networks for Mobile Devices," in Proc. of CVPR, 2016.
[92] F. Li, B. Zhang, and B. Liu, "Ternary Weight Networks," in arXiv:1605.04711, 2016.
[93] S. Zhou, Y. Wu, Z. Ni, X. Zhou, H. Wen, and Y. Zou, "DoReFa-Net: Training Low Bitwidth Convolutional Neural Networks with Low Bitwidth
Gradients," in arXiv:1606.06160, 2016.
[94] C. Zhu, S. Han, H. Mao, and W. Dally, "Trained Ternary Quantization," in Proc. of ICLR, 2017.
[95] A. Zhou, A. Yao, Y. Guo, L. Xu, and Y. Chen, "Incremental Network Quantization: Towards Lossless CNNs with Low-Precision Weights," in Proc. of
ICLR, 2017.
[96] S. Wu, G. Li, F. Chen, and L. Shi, "Training and Inference with Integers in Deep Neural Networks," in Proc. of ICLR, 2018.
[97] B. Jacob, et al., "Quantization and Training of Neural Networks for Efficient Integer-Arithmetic-Only Inference," in Proc. of CVPR, 2018.
[98] Z. Liu, B. Wu, W. Luo, X. Yang, W. Liu, and K. Cheng, "Bi-Real Net: Enhancing the Performance of 1-bit CNNs With Improved Representational
Capability and Advanced Training Algorithm," in Proc. of ECCV, 2018.
[99] N. Wang, J. Choi, D. Brand, C. Chen, and K. Gopalakrishnan, "Training Deep Neural Networks with 8-bit Floating Point Numbers," in Proc. of NIPS,
2018.
[100] G. Yang, et al., "SWALP : Stochastic Weight Averaging in Low-Precision Training," in Proc. of ICML, 2019.
89







![空間方向の分解
• 大きな畳み込みカーネルを小さな畳み込みカーネルに分解
• 例えば5x5の畳み込みを3x3の畳み込み2つに分解
• これらは同じサイズの受容野を持つが分解すると計算量は25:18
• Inception-v2 [4] では最初の7x7畳み込みを3x3畳み込み3つに分解
• 以降のSENetやShuffleNetV2等の実装でも利用されている[18]
9
特徴マップ
conv5x5 conv3x3 - conv3x3
[4] C. Szegedy, et al., "Rethinking the Inception Architecture for Computer Vision," in Proc. of CVPR, 2016.
[18] T. He, et al., "Bag of Tricks for Image Classification with Convolutional Neural Networks," in Proc. of
CVPR, 2019.](https://image.slidesharecdn.com/dlaccel-190927142747/75/2019-9-2048.jpg)
![空間方向の分解
• nxnを1xnとnx1に分解することも
10[4] C. Szegedy, et al., "Rethinking the Inception Architecture for Computer Vision," in Proc. of CVPR, 2016.](https://image.slidesharecdn.com/dlaccel-190927142747/75/2019-10-2048.jpg)


![Xception[6]
• Separable convを多用したモデル
13[6] F. Chollet, "Xception: Deep learning with depthwise separable convolutions," in Proc. of CVPR, 2017.](https://image.slidesharecdn.com/dlaccel-190927142747/75/2019-13-2048.jpg)
![MobileNet[7]
• depthwise/pointwise convを多用
• 改良版のMobileNetV2[13]/V3[20]もある
14
通常の畳み込み MobileNetの1要素
[7] A. Howard, et al., "MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications,"
in arXiv:1704.04861, 2017.
[13] M. Sandler, et al., "MobileNetV2: Inverted Residuals and Linear Bottlenecks," in Proc. of CVPR, 2018.
[20] A. Howard, et al., "Searching for MobileNetV3," in Proc. of ICCV’19.](https://image.slidesharecdn.com/dlaccel-190927142747/75/2019-14-2048.jpg)




![ShuffleNet[8]
• MobileNetのボトルネックとなっているconv1x1を
group conv1x1 + channel shuffleに置換
• group conv: 入力の特徴マップをG個にグループ化し
各グループ内で個別に畳み込みを行う
(計算量 H・W・N・K2・M → H・W・N・K2・M / G)
• channel shuffle: チャネルの順序を入れ替える
reshape + transposeの操作で実現可能
c shuffle
depthwise conv
gconv 1x1
spatial channel
gconv 1x1
[8] X. Zhang, et al., "ShuffleNet: An Extremely Efficient
Convolutional Neural Network for Mobile Devices," in
arXiv:1707.01083, 2017.](https://image.slidesharecdn.com/dlaccel-190927142747/75/2019-19-2048.jpg)


![ChannelNet[11]
• チャネル方向に1次元の畳み込みを行う
22
[11] H. Gao, Z. Wang, and S. Ji, "ChannelNets: Compact and Efficient Convolutional Neural Networks
via Channel-Wise Convolutions", in Proc. of NIPS, 2018.](https://image.slidesharecdn.com/dlaccel-190927142747/75/2019-22-2048.jpg)









![Deep Compression[23, 25, 26]
• Unstructuredなpruning
• L2正則化を加えて学習し、絶対値が小さいweightを0に
• 実際に高速に動かすには専用ハードが必要[26]
33
[23] S. Han, et al., "Learning both Weights and Connections for Efficient Neural Networks," in Proc. of NIPS, 2015.
[25] S. Han, et al., "Deep Compression: Compressing Deep Neural Networks with Pruning, Trained Quantization
and Huffman Coding," in Proc. of ICLR, 2016.
[26] S. Han, et al., "EIE: Efficient Inference Engine on Compressed Deep Neural Network," in Proc. of ISCA, 2016.](https://image.slidesharecdn.com/dlaccel-190927142747/75/2019-33-2048.jpg)
![Pruning Filters for Efficient ConvNets[30]
• Structured pruning(チャネルレベルのpruning)
• 各レイヤについて、フィルタの重みの絶対値の総和が
小さいものからpruning
• 各レイヤのpruning率はpruningへのsensitivityから
人手で調整
• Pruning後にfinetune
34[30] H. Li, et al., "Pruning Filters for Efficient ConvNets," in Proc. of ICLR, 2017.](https://image.slidesharecdn.com/dlaccel-190927142747/75/2019-34-2048.jpg)
![Network Slimming[33]
• Batch normのパラメータγにL1ロスをかけて学習
• 学習後、γが小さいチャネルを削除し、fine-tune
35
チャネル毎に入力を平均0分散1に正規化、γとβでscale & shift
チャネルi
Batch
normalization
[33] Z. Liu, et al., "Learning Efficient Convolutional Networks through Network Slimming," in Proc. of ICCV,
2017.](https://image.slidesharecdn.com/dlaccel-190927142747/75/2019-35-2048.jpg)
![L0ではなくLasso
に緩和して解く
Channel Pruning[34]
• あるfeature mapのチャネル削除した場合に
次のfeature mapの誤差が最小となるようチャネルを選択
• Wも最小二乗で調整
36[34] Y. He, et al., "Channel Pruning for Accelerating Very Deep Neural Networks," in Proc. of ICCV, 2017.](https://image.slidesharecdn.com/dlaccel-190927142747/75/2019-36-2048.jpg)
![ThiNet[35]
• 前述の手法と同じように、次のfeature mapの誤差が
最小となるレイヤをgreedy削除
• 削除後に、畳み込みの重みを誤差が最小になるように
調整→finetune
37
[35] J. Luo, et al., "ThiNet: A Filter Level Pruning Method for Deep Neural Network Compression," in Proc.
of ICCV, 2017.](https://image.slidesharecdn.com/dlaccel-190927142747/75/2019-37-2048.jpg)
![AutoML for Model Compression and Acceleration (AMC)[41]
• 強化学習(off-policy actor-critic)により各レイヤ毎の最適な
pruning率を学習(実際のpruningは他の手法を利用)
• 入力は対象レイヤの情報とそれまでのpruning結果、
報酬は –エラー率×log(FLOPs) or log(#Params)
38
[41] Y. He, et al., "AMC - AutoML for Model Compression and Acceleration on Mobile Devices," in Proc. of
ECCV, 2018.](https://image.slidesharecdn.com/dlaccel-190927142747/75/2019-38-2048.jpg)
![Lottery Ticket Hypothesis (ICLR’19 Best Paper)[44]
• NNには、「部分ネットワーク構造」と「初期値」の
組み合わせに「当たり」が存在し、それを引き当てると
効率的に学習が可能という仮説
• Unstructuredなpruningでその構造と初期値を見つけることができた
40
https://www.slideshare.net/YosukeShinya/the-lottery-ticket-hypothesis-finding-small-trainable-neural-networks
[44] Jonathan Frankle, Michael Carbin, "The Lottery Ticket Hypothesis: Finding Sparse, Trainable Neural
Networks," in Proc. of ICLR, 2019.](https://image.slidesharecdn.com/dlaccel-190927142747/75/2019-40-2048.jpg)
![Network Pruning as Architecture Search[45]
• Structuredなpruning後のネットワークをscratchから学習させても
finetuneと同等かそれより良い結果が得られるという主張
• つまりpruningは、重要な重みを探索しているのではなく
各レイヤにどの程度のチャネル数を割り当てるかという
Neural Architecture Search (NAS) をしているとみなせる
• Lottery Ticket Hypothesisではunstructuredで、低LRのみ、
実験も小規模ネットワークのみ
41[45] Z. Liu, et al., "Rethinking the Value of Network Pruning," in Proc. of ICLR, 2019.](https://image.slidesharecdn.com/dlaccel-190927142747/75/2019-41-2048.jpg)






![NASNet[52]
• 探索空間:cell、
探索手法:強化学習 (Proximal Policy Optimization)
• Globalな設計にドメイン知識を活用、
構成するcellのみを自動設計
→探索空間を大幅に削減
• Normal cell x Nとreduction cellのスタック
• Reduction cellは最初にstride付きのOPで
特徴マップをダウンサンプル
• Reduction cell以降でチャネルを倍に
48
[52] B. Zoph, V. Vasudevan, J. Shlens, and Q. V. Le, "Learning transferable architectures for scalable
image recognition," in Proc. of CVPR, 2018.](https://image.slidesharecdn.com/dlaccel-190927142747/75/2019-48-2048.jpg)
![NASNetのコントローラの動作
1. Hidden state※1 1, 2を選択
2. それらへのOPsを選択※2
3. それらを結合するOP (add or concat)
を選択し新たなhidden stateとする
※1 Hidden state: 緑のブロックとhi, hi-I
※2 Hidden stateへのOP候補
49
[52] B. Zoph, V. Vasudevan, J. Shlens, and Q. V. Le, "Learning transferable architectures for scalable
image recognition," in Proc. of CVPR, 2018.](https://image.slidesharecdn.com/dlaccel-190927142747/75/2019-49-2048.jpg)
![NASNetのコントローラの動作
1. Hidden state※1 1, 2を選択
2. それらへのOPsを選択※2
3. それらを結合するOP (add or concat)
を選択し新たなhidden stateとする
※1 Hidden state: 緑のブロックとhi, hi-I
※2 Hidden stateへのOP候補
50
[52] B. Zoph, V. Vasudevan, J. Shlens, and Q. V. Le, "Learning transferable architectures for scalable
image recognition," in Proc. of CVPR, 2018.](https://image.slidesharecdn.com/dlaccel-190927142747/75/2019-50-2048.jpg)
![NASNetのコントローラの動作
1. Hidden state※1 1, 2を選択
2. それらへのOPsを選択※2
3. それらを結合するOP (add or concat)
を選択し新たなhidden stateとする
※1 Hidden state: 緑のブロックとhi, hi-I
※2 Hidden stateへのOP候補
51
sep
3x3
avg
3x3
[52] B. Zoph, V. Vasudevan, J. Shlens, and Q. V. Le, "Learning transferable architectures for scalable
image recognition," in Proc. of CVPR, 2018.](https://image.slidesharecdn.com/dlaccel-190927142747/75/2019-51-2048.jpg)
![NASNetのコントローラの動作
1. Hidden state※1 1, 2を選択
2. それらへのOPsを選択※2
3. それらを結合するOP (add or concat)
を選択し新たなhidden stateとする
※1 Hidden state: 緑のブロックとhi, hi-I
※2 Hidden stateへのOP候補
52
concat
sep
3x3
avg
3x3
[52] B. Zoph, V. Vasudevan, J. Shlens, and Q. V. Le, "Learning transferable architectures for scalable
image recognition," in Proc. of CVPR, 2018.](https://image.slidesharecdn.com/dlaccel-190927142747/75/2019-52-2048.jpg)
![ENAS[54]
• 探索空間:cell、探索手法:強化学習 (REINFORCE)
• Cellの構造を出力するRNNコントローラと、
コントローラーが出力する全てのネットワークをサブグラフとして
保持できる巨大な計算グラフ(ネットワーク)を同時に学習
→生成したネットワークの学習が不要に(1GPU for 0.45 days!)
• Single shot, weight share
• 詳細は神資料*を参照
53
[54] H. Pham, M. Y. Guan, B. Zoph, Q. V. Le, and Jeff Dean, "Efficient Neural Architecture
Search via Parameter Sharing," in Proc. of ICML, 2018.
* https://www.slideshare.net/tkatojp/efficient-neural-architecture-search-via-parameters-
sharing-icml2018](https://image.slidesharecdn.com/dlaccel-190927142747/75/2019-53-2048.jpg)

![DARTS[57]
• 探索空間:cell、探索手法:gradient
• グラフの接続やOPの選択をsoftmaxで実現することで、
構造探索もforward-backwardで実現
• ENASと同じくshared param、wと構造を交互に最適化
55[57] H. Liu, K. Simonyan, and Y. Yang, "DARTS: Differentiable Architecture Search," in Proc. of ICLR, 2019.](https://image.slidesharecdn.com/dlaccel-190927142747/75/2019-55-2048.jpg)
![FBNet[61]
• DARTSと同じくgradient-based
• 各OPの実デバイス上での処理時間をlookup tableに保持
• 処理時間を考慮したロスをかける
• ブロック毎に違う構造
56
[61] B. Wu, et al., "FBNet: Hardware-Aware Efficient ConvNet Design via Differentiable Neural Architecture
Search", in Proc. of CVPR, 2019.
クロスエントロピー 処理時間](https://image.slidesharecdn.com/dlaccel-190927142747/75/2019-56-2048.jpg)

![他にも
[58] H. Cai, L. Zhu, and S. Han, "ProxylessNAS: Direct Neural Architecture
Search on Target Task and Hardware," in Proc. of ICLR, 2019.
[59] M. Tan, B. Chen, R. Pang, V. Vasudevan, M. Sandler, A. Howard, and Q.
V. Le, "MnasNet: Platform-Aware Neural Architecture Search for Mobile," in
Proc. of CVPR, 2019.
[60] X. Dai, et al., "ChamNet: Towards Efficient Network Design through
Platform-Aware Model Adaptation," in Proc. of CVPR, 2019.
[62] D. Stamoulis, et al., "Single-Path NAS: Device-Aware Efficient ConvNet
Design," in Proc. of ICMLW, 2019.
58](https://image.slidesharecdn.com/dlaccel-190927142747/75/2019-58-2048.jpg)


![BranchyNet[65]
• ネットワークの途中に結果の出力層を追加
• 学習時にはすべての出力層に適当なweightをかけて学習
• そのsoftmaxのエントロピーが閾値以下の場合にExit
61
[65] S. Teerapittayanon, et al., "BranchyNet: Fast Inference via Early Exiting from Deep Neural Networks,"
in Proc. of ICPR, 2016.](https://image.slidesharecdn.com/dlaccel-190927142747/75/2019-61-2048.jpg)
![Spatially Adaptive Computation Time (SACT)[66]
• ACT: 各ResBlockがhalting scoreを出力、合計が1を超えると
以降の処理をスキップ(空間領域でも行うとSACT)
62
計算量に関する勾配を追加
[66] M. Figurnov, et al., "Spatially Adaptive Computation Time for Residual Networks," in Proc. of CVPR, 2017.](https://image.slidesharecdn.com/dlaccel-190927142747/75/2019-62-2048.jpg)
![Runtime Neural Pruning[68]
• 各レイヤ毎に、直前までの特徴マップを入力とするRNNが
利用する畳み込みフィルタ集合を決定
• Keepした畳み込みフィルタ数と元タスクの損失関数(最終層の場
合)を負の報酬としてQ学習でRNNを学習
63[68] J. Lin, et al., "Runtime Neural Pruning," in Proc. of NIPS, 2017.](https://image.slidesharecdn.com/dlaccel-190927142747/75/2019-63-2048.jpg)
![BlockDrop[73]
• Policy networkに画像を入力、どのBlockをスキップするかを出力
• KeepとなったResBlockのみをforward
• 認識が失敗した場合は負の報酬を、成功した場合にはスキップ率に
応じた正の報酬を与えることでpolicy networkを学習
64[73] Z. Wu, et al., "BlockDrop: Dynamic Inference Paths in Residual Networks," in Proc. of CVPR, 2018.](https://image.slidesharecdn.com/dlaccel-190927142747/75/2019-64-2048.jpg)


![Distilling the Knowledge in a Neural Network[77]
67
……
学習画像
学習済みモデル
学習するモデル
…
正解ラベル
(ハード
ターゲッ
ト)
通常T = 1のsoftmaxのTを大きくした
ソフトターゲットを利用
…
ソフトターゲット
ソフト
ターゲット
ハード
ターゲット
正解ラベルと
学習モデル出力の
両方を利用
[77] G. Hinton, et al., "Distilling the Knowledge in a
Neural Network," in Proc. of NIPS Workshop, 2014.](https://image.slidesharecdn.com/dlaccel-190927142747/75/2019-67-2048.jpg)
![FitNet[79]
• 教師よりもdeepかつthinな生徒を学習する
• 生徒のguided layerが、教師のhit layerの出力を
正確に模擬する (regression) ロスを追加
68[79] A. Romero, et al., "FitNets: Hints for Thin Deep Nets," in Proc. of ICLR, 2015.](https://image.slidesharecdn.com/dlaccel-190927142747/75/2019-68-2048.jpg)



![WAGE[96]
• weights (W), activations (A), gradients (G), errors (E)
の全てを量子化
72[96] S. Wu, et al., "Training and Inference with Integers in Deep Neural Networks," in Proc. of ICLR, 2018.](https://image.slidesharecdn.com/dlaccel-190927142747/75/2019-72-2048.jpg)
![WAGE[96]
• weights (W), activations (A), gradients (G), errors (E)
73
バイナリ
[96] S. Wu, et al., "Training and Inference with Integers in Deep Neural Networks," in Proc. of ICLR, 2018.](https://image.slidesharecdn.com/dlaccel-190927142747/75/2019-73-2048.jpg)
![Quantization and Training of Neural Networks for
Efficient Integer-Arithmetic-Only Inference[97]
• 推論時にuint8の演算がメインとなるように
学習時に量子化をシミュレーションしながら学習
• TensorFlow公式に実装が存在*
74
[97] B. Jacob, et al., "Quantization and Training of Neural Networks for Efficient Integer-Arithmetic-Only
Inference," in Proc. of CVPR, 2018.
* https://github.com/tensorflow/tensorflow/blob/master/tensorflow/contrib/quantize/README.md](https://image.slidesharecdn.com/dlaccel-190927142747/75/2019-74-2048.jpg)






![畳み込みの分解
[1] L. Sifre and S. Mallat, "Rotation, Scaling and Deformation Invariant Scattering for Texture Discrimination," in Proc. of CVPR, 2013.
[2] L. Sifre, "Rigid-motion Scattering for Image Classification, in Ph.D. thesis, 2014.
[3] M. Lin, Q. Chen, and S. Yan, "Network in Network," in Proc. of ICLR, 2014.
[4] C. Szegedy, et al., "Rethinking the Inception Architecture for Computer Vision," in Proc. of CVPR, 2016.
[5] F. N. Iandola, S. Han, M. W. Moskewicz, K. Ashraf, W. J. Dally, and K. Keutzer, "SqueezeNet: AlexNet-level accuracy with 50x fewer parameters and
<0.5MB model size," in arXiv:1602.07360, 2016.
[6] F. Chollet, "Xception: Deep learning with depthwise separable convolutions," in Proc. of CVPR, 2017.
[7] A. Howard, et al., "MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications," in arXiv:1704.04861, 2017.
[8] X. Zhang, et al., "ShuffleNet: An Extremely Efficient Convolutional Neural Network for Mobile Devices," in arXiv:1707.01083, 2017.
[9] B. Wu, et al., "Shift: A Zero FLOP, Zero Parameter," in arXiv:1711.08141, 2017.
[10] N. Ma, X. Zhang, H. Zheng, and J. Sun, "ShuffleNet V2: Practical Guidelines for Efficient CNN Architecture Design," in Proc. of ECCV, 2018.
[11] H. Gao, Z. Wang, and S. Ji, "ChannelNets: Compact and Efficient Convolutional Neural Networks via Channel-Wise Convolutions", in Proc. of NIPS,
2018.
[12] G. Huang, S. Liu, L. Maaten, and K. Weinberger, "CondenseNet: An Efficient DenseNet using Learned Group Convolutions," in Proc. of CVPR, 2018.
[13] M. Sandler, et al., "MobileNetV2: Inverted Residuals and Linear Bottlenecks," in Proc. of CVPR, 2018.
[14] G. Xie, J. Wang, T. Zhang, J. Lai, R. Hong, and G. Qi, "IGCV2: Interleaved Structured Sparse Convolutional Neural Networks, in Proc. of CVPR, 2018.
82](https://image.slidesharecdn.com/dlaccel-190927142747/75/2019-82-2048.jpg)
![畳み込みの分解
[15] T. Zhang, G. Qi, B. Xiao, and J. Wang, "Interleaved group convolutions for deep neural networks," in Proc. of ICCV, 2017.
[16] Z. Qin, Z. Zhang, X. Chen, and Y. Peng, "FD-MobileNet: Improved MobileNet with a Fast Downsampling Strategy," in Proc. of ICIP, 2018.
[17] K. Sun, M. Li, D. Liu, and J. Wang, "IGCV3: Interleaved Low-Rank Group Convolutions for Efficient Deep Neural Networks," in BMVC, 2018.
[18] T. He, et al., "Bag of Tricks for Image Classification with Convolutional Neural Networks," in Proc. of CVPR, 2019.
[19] Y. Chen, et al., "Drop an Octave: Reducing Spatial Redundancy in Convolutional Neural Networks with Octave Convolution," in arXiv:1904.05049,
2019.
[20] A. Howard, et al., "Searching for MobileNetV3," in arXiv:1905.02244, 2019.
[21] J. Zhang, "Seesaw-Net: Convolution Neural Network With Uneven Group Convolution," in arXiv:1905.03672, 2019.
83](https://image.slidesharecdn.com/dlaccel-190927142747/75/2019-83-2048.jpg)
![枝刈り
[22] Y. LeCun, J. Denker, and S. Solla, "Optimal Brain Damage," in Proc. of NIPS, 1990.
[23] S. Han, J. Pool, J. Tran, and W. Dally, "Learning both Weights and Connections for Efficient Neural Networks," in Proc. of NIPS, 2015.
[24] W. Wen, C. Wu, Y. Wang, Y. Chen, and H. Li, "Learning Structured Sparsity in Deep Neural Networks," in Proc. of NIPS, 2016.
[25] S. Han, et al., "Deep Compression: Compressing Deep Neural Networks with Pruning, Trained Quantization and Huffman Coding," in Proc. of ICLR,
2016.
[26] S. Han, J. Pool, J. Tran, and W. Dally, "EIE: Efficient Inference Engine on Compressed Deep Neural Network," in Proc. of ISCA, 2016.
[27] S. Anwar, K. Hwang, and W. Sung, "Structured Pruning of Deep Convolutional Neural Networks," in JETC, 2017.
[28] S. Changpinyo, M. Sandler, and A. Zhmoginov, "The Power of Sparsity in Convolutional Neural Networks," in arXiv:1702.06257, 2017.
[29] S. Scardapane, D. Comminiello, A. Hussain, and A. Uncini, "Group Sparse Regularization for Deep Neural Networks," in Neurocomputing, 2017.
[30] H. Li, et al., "Pruning Filters for Efficient ConvNets," in Proc. of ICLR, 2017.
[31] P. Molchanov, S. Tyree, T. Karras, T. Aila, and J. Kautz, "Pruning Convolutional Neural Networks for Resource Efficient Inference," in Proc. of ICLR,
1017.
[32] D. Molchanov, A. Ashukha, and D. Vetrov, "Variational Dropout Sparsifies Deep Neural Networks," in Proc. of ICML, 2017.
[33] Z. Liu, et al., "Learning Efficient Convolutional Networks through Network Slimming," in Proc. of ICCV, 2017.
[34] Y. He, et al., "Channel Pruning for Accelerating Very Deep Neural Networks," in Proc. of ICCV, 2017.
[35] J. Luo, et al., "ThiNet: A Filter Level Pruning Method for Deep Neural Network Compression," in Proc. of ICCV, 2017.
[36] C. Louizos, K. Ullrich, and M. Welling, "Bayesian Compression for Deep Learning," in Proc. of NIPS, 2017.
84](https://image.slidesharecdn.com/dlaccel-190927142747/75/2019-84-2048.jpg)
![枝刈り
[37] Kirill Neklyudov, Dmitry Molchanov, Arsenii Ashukha, Dmitry Vetrov, "Structured Bayesian Pruning via Log-Normal Multiplicative Noise," in Proc. of
NIPS, 2017.
[38] M. Zhu and S. Gupta, "To prune, or not to prune: exploring the efficacy of pruning for model compression," in Proc. of ICLRW, 2018.
[39] T. Yang, Y. Chen, and V. Sze, "Designing Energy-Efficient Convolutional Neural Networks Using Energy-Aware Pruning," in Proc. of CVPR, 2017.
[40] Y. He, G. Kang, X. Dong, Y. Fu, and Y. Yang, "Soft Filter Pruning for Accelerating Deep Convolutional Neural Networks," in Proc. of IJCAI, 2018.
[41] Y. He, et al., "AMC - AutoML for Model Compression and Acceleration on Mobile Devices," in Proc. of ECCV, 2018.
[42] T. Yang, A. Howard, B. Chen, X. Zhang, A. Go, M. Sandler, V. Sze, and H. Adam, "NetAdapt: Platform-Aware Neural Network Adaptation for Mobile
Applications," in Proc. of ECCV, 2018.
[43] J. Luo and J. Wu, "AutoPruner: An End-to-End Trainable Filter Pruning Method for Efficient Deep Model Inference," in arXiv:1805.08941, 2018.
[44] J. Frankle and M. Carbin, "The Lottery Ticket Hypothesis: Finding Sparse, Trainable Neural Networks," in Proc. of ICLR, 2019.
[45] Z. Liu, et al., "Rethinking the Value of Network Pruning," in Proc. of ICLR, 2019.
[46] J. Yu, L. Yang, N. Xu, J. Yang, and T. Huang, "Slimmable Neural Networks," in Proc. of ICLR, 2019.
[47] S. Lin, R. Ji, C. Yan, B. Zhang, L. Cao, Q. Ye, F. Huang, and D. Doermann, "Towards Optimal Structured CNN Pruning via Generative Adversarial
Learning," in Proc. of CVPR, 2019. GAN
[48] J. Yu and T. Huang, "Universally Slimmable Networks and Improved Training Techniques," in arXiv:1903.05134, 2019.
[49] J. Yu and T. Huang, "Network Slimming by Slimmable Networks: Towards One-Shot Architecture Search for Channel Numbers," in arXiv:1903.11728,
2019.
[50] Z. Liu, H. Mu, X. Zhang, Z. Guo, X. Yang, T. Cheng, and J. Sun, "MetaPruning: Meta Learning for Automatic Neural Network Channel Pruning," in
arXiv:1903.10258, 2019.
85](https://image.slidesharecdn.com/dlaccel-190927142747/75/2019-85-2048.jpg)
![アーキテクチャ探索
[51] B. Zoph and Q. V. Le, "Neural architecture search with reinforcement learning," in Proc. of ICLR, 2017.
[52] B. Zoph, V. Vasudevan, J. Shlens, and Q. V. Le, "Learning transferable architectures for scalable image recognition," in Proc. of CVPR, 2018.
[53] C. Liu, et al., "Progressive Neural Architecture Search," in Proc. of ECCV, 2018.
[54] H. Pham, M. Y. Guan, B. Zoph, Q. V. Le, and Jeff Dean, "Efficient Neural Architecture Search via Parameter Sharing," in Proc. of ICML, 2018.
[55] H. Liu, K. Simonyan, O. Vinyals, C. Fernando, and K. Kavukcuoglu, "Hierarchical Representations for Efficient Architecture Search," in Proc. of ICLR,
2018.
[56] E. Real, A. Aggarwal, Y. Huang, Q. V. Le, "Regularized Evolution for Image Classifier Architecture Search," in Proc. of AAAI, 2019.
[57] H. Liu, K. Simonyan, and Y. Yang, "DARTS: Differentiable Architecture Search," in Proc. of ICLR, 2019.
[58] H. Cai, L. Zhu, and S. Han, "ProxylessNAS: Direct Neural Architecture Search on Target Task and Hardware," in Proc. of ICLR, 2019.
[59] M. Tan, B. Chen, R. Pang, V. Vasudevan, M. Sandler, A. Howard, and Q. V. Le, "MnasNet: Platform-Aware Neural Architecture Search for Mobile," in
Proc. of CVPR, 2019.
[60] X. Dai, et al., "ChamNet: Towards Efficient Network Design through Platform-Aware Model Adaptation," in Proc. of CVPR, 2019.
[61] B. Wu, et al., "FBNet: Hardware-Aware Efficient ConvNet Design via Differentiable Neural Architecture Search", in Proc. of CVPR, 2019.
[62] D. Stamoulis, et al., "Single-Path NAS: Device-Aware Efficient ConvNet Design," in Proc. of ICMLW, 2019.
[63] L. Li and A. Talwalkar, "Random search and reproducibility for neural architecture search," in arXiv:1902.07638, 2019.
86](https://image.slidesharecdn.com/dlaccel-190927142747/75/2019-86-2048.jpg)
![早期終了、動的計算グラフ
[64] Y. Guo, A. Yao, and Y. Chen, "Dynamic Network Surgery for Efficient DNNs," in Proc. of NIPS, 2016.
[65] S. Teerapittayanon, et al., "BranchyNet: Fast Inference via Early Exiting from Deep Neural Networks," in Proc. of ICPR, 2016.
[66] M. Figurnov, et al., "Spatially Adaptive Computation Time for Residual Networks," in Proc. of CVPR, 2017.
[67] T. Bolukbasi, J. Wang, O. Dekel, and V. Saligrama, "Adaptive Neural Networks for Efficient Inference," in Proc. of ICML, 2017.
[68] J. Lin, et al., "Runtime Neural Pruning," in Proc. of NIPS, 2017.
[69] G. Huang, D. Chen, T. Li, F. Wu, L. Maaten, and K. Weinberger, "Multi-Scale Dense Networks for Resource Efficient Image Classification," in Proc. of
ICLR, 2018.
[70] X. Wang, F. Yu, Z. Dou, T. Darrell, and J. Gonzalez, "SkipNet: Learning Dynamic Routing in Convolutional Networks," in Proc. of ECCV, 2018.
[71] A. Veit and S. Belongie, "Convolutional Networks with Adaptive Inference Graphs," in Proc. of ECCV, 2018.
[72] L. Liu and J. Deng, "Dynamic Deep Neural Networks: Optimizing Accuracy-Efficiency Trade-Offs by Selective Execution," in Proc. of AAAI, 2018.
[73] Z. Wu, et al., "BlockDrop: Dynamic Inference Paths in Residual Networks," in Proc. of CVPR, 2018.
[74] R, Yu, et al., "NISP: Pruning Networks using Neuron Importance Score Propagation," in Proc. of CVPR, 2018.
[75] J. Kuen, X. Kong, Z. Lin, G. Wang, J. Yin, S. See, and Y. Tan, "Stochastic Downsampling for Cost-Adjustable Inference and Improved Regularization
in Convolutional Networks," in Proc. of CVPR, 2018.
[76] X. Gao, Y. Zhao, L. Dudziak, R. Mullins, and C. Xu, "Dynamic Channel Pruning: Feature Boosting and Suppression," in Proc. of ICLR, 2019.
87](https://image.slidesharecdn.com/dlaccel-190927142747/75/2019-87-2048.jpg)
![蒸留
[77] G. Hinton, et al., "Distilling the Knowledge in a Neural Network," in Proc. of NIPS Workshop, 2014.
[78] J. Ba and R. Caruana, "Do Deep Nets Really Need to be Deep?," in Proc. of NIPS, 2014.
[79] A. Romero, et al., "FitNets: Hints for Thin Deep Nets," in Proc. of ICLR, 2015.
[80] T. Chen, I. Goodfellow, and J. Shlens, "Net2Net: Accelerating Learning via Knowledge Transfer," in Proc. of ICLR, 2016.
[81] G. Urban, et al., "Do Deep Convolutional Nets Really Need to be Deep and Convolutional?," in Proc. of ICLR, 2017.
[82] J. Yim, D. Joo, J. Bae, and J. Kim, "A Gift from Knowledge Distillation: Fast Optimization, Network Minimization and Transfer Learning," in Proc. of
CVPR, 2017.
[83] A. Mishra and D. Marr, "Apprentice: Using Knowledge Distillation Techniques To Improve Low-Precision Network Accuracy," in Proc. of ICLR, 2018.
[84] T. Furlanello, Z. Lipton, M. Tschannen, L. Itti, and A. Anandkumar, "Born Again Neural Networks," in Proc. of ICML, 2018.
[85] Y. Zhang, T. Xiang, T. Hospedales, and H. Lu, "Deep Mutual Learning," in Proc. of CVPR, 2018.
[86] X. Lan, X. Zhu, and S. Gong, "Knowledge Distillation by On-the-Fly Native Ensemble," in Proc. of NIPS, 2018.
[87] W. Park, D. Kim, Y. Lu, and M. Cho, "Relational Knowledge Distillation," in Proc. of CVPR, 2019.
88](https://image.slidesharecdn.com/dlaccel-190927142747/75/2019-88-2048.jpg)
![量子化
[88] M. Courbariaux, Y. Bengio, and J. David, "BinaryConnect: Training Deep Neural Networks with binary weights during propagations," in Proc. of NIPS,
2015.
[89] I. Hubara, M. Courbariaux, D. Soudry, R. El-Yaniv, and Y. Bengio, "Binarized Neural Networks," in Proc. of NIPS, 2016.
[90] M. Rastegari, V. OrdonezJoseph, and R. Farhadi, "XNOR-Net: ImageNet Classification Using Binary Convolutional Neural Networks," in Proc. of ECCV,
2016.
[91] J. Wu, C. Leng, Y. Wang, Q. Hu, and J. Cheng, "Quantized Convolutional Neural Networks for Mobile Devices," in Proc. of CVPR, 2016.
[92] F. Li, B. Zhang, and B. Liu, "Ternary Weight Networks," in arXiv:1605.04711, 2016.
[93] S. Zhou, Y. Wu, Z. Ni, X. Zhou, H. Wen, and Y. Zou, "DoReFa-Net: Training Low Bitwidth Convolutional Neural Networks with Low Bitwidth
Gradients," in arXiv:1606.06160, 2016.
[94] C. Zhu, S. Han, H. Mao, and W. Dally, "Trained Ternary Quantization," in Proc. of ICLR, 2017.
[95] A. Zhou, A. Yao, Y. Guo, L. Xu, and Y. Chen, "Incremental Network Quantization: Towards Lossless CNNs with Low-Precision Weights," in Proc. of
ICLR, 2017.
[96] S. Wu, G. Li, F. Chen, and L. Shi, "Training and Inference with Integers in Deep Neural Networks," in Proc. of ICLR, 2018.
[97] B. Jacob, et al., "Quantization and Training of Neural Networks for Efficient Integer-Arithmetic-Only Inference," in Proc. of CVPR, 2018.
[98] Z. Liu, B. Wu, W. Luo, X. Yang, W. Liu, and K. Cheng, "Bi-Real Net: Enhancing the Performance of 1-bit CNNs With Improved Representational
Capability and Advanced Training Algorithm," in Proc. of ECCV, 2018.
[99] N. Wang, J. Choi, D. Brand, C. Chen, and K. Gopalakrishnan, "Training Deep Neural Networks with 8-bit Floating Point Numbers," in Proc. of NIPS,
2018.
[100] G. Yang, et al., "SWALP : Stochastic Weight Averaging in Low-Precision Training," in Proc. of ICML, 2019.
89](https://image.slidesharecdn.com/dlaccel-190927142747/75/2019-89-2048.jpg)



![[DL輪読会]Swin Transformer: Hierarchical Vision Transformer using Shifted Windows](https://cdn.slidesharecdn.com/ss_thumbnails/swintransformer-210514020542-thumbnail.jpg?width=640&height=640&fit=bounds)



![[DL輪読会]When Does Label Smoothing Help?](https://cdn.slidesharecdn.com/ss_thumbnails/yokota20191227dl-191227001522-thumbnail.jpg?width=640&height=640&fit=bounds)







![SSII2022 [TS1] Transformerの最前線〜 畳込みニューラルネットワークの先へ 〜](https://cdn.slidesharecdn.com/ss_thumbnails/ts120220608ssiitransformerr2-220607054025-3adacf07-thumbnail.jpg?width=640&height=640&fit=bounds)



![[DL輪読会] Spectral Norm Regularization for Improving the Generalizability of De...](https://cdn.slidesharecdn.com/ss_thumbnails/dlhackspectralnorm1-170907072536-thumbnail.jpg?width=640&height=640&fit=bounds)





![[DL輪読会] マルチエージェント強化学習と心の理論](https://cdn.slidesharecdn.com/ss_thumbnails/0917imai-211210044729-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DL輪読会]Learning Transferable Visual Models From Natural Language Supervision](https://cdn.slidesharecdn.com/ss_thumbnails/dlkobayashi0115-210115012308-thumbnail.jpg?width=640&height=640&fit=bounds)



![[DL輪読会]NAS-FPN: Learning Scalable Feature Pyramid Architecture for Object Det...](https://cdn.slidesharecdn.com/ss_thumbnails/20190419misono-190513060423-thumbnail.jpg?width=640&height=640&fit=bounds)
![[論文紹介] BlendedMVS: A Large-scale Dataset for Generalized Multi-view Stereo Ne...](https://cdn.slidesharecdn.com/ss_thumbnails/blendedmvsslideshare-200630044345-thumbnail.jpg?width=640&height=640&fit=bounds)


![[unofficial] Pyramid Scene Parsing Network (CVPR 2017)](https://cdn.slidesharecdn.com/ss_thumbnails/pyramidsceneparsingnetwork-170815035025-thumbnail.jpg?width=640&height=640&fit=bounds)




































![Vibe Coding vs. Spec-Driven Development [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/vibecodingvsspecdrivendevelopment-251209105622-43f455e7-thumbnail.jpg?width=640&height=640&fit=bounds)















