ハードウェア構成に関する考慮事項
DB Tech Showcase2017 - GPU/SSDがPostgreSQLを加速する-27
① PCIeスイッチを介して
SSDとGPUが接続の場合
OK
② CPUがPCIeバスを管理し、
SSDにGPU直接接続の場合
Workable
③ SSDとGPUが互いに異なる
CPUに接続の場合
Not Supported
CPU CPU
PLX
SSD GPU
PCIeスイッチ
この接続トポロジは HeteroDB 環境で検証済
み。
転送レート~9.5GB/sまでは記録した実績あ
り。
(CPUはXeon E5-2650 v4)
非常に遅い。数十~数百MB/s程度の
転送レートしか出ないので、避けな
ければならない。
CPU CPU
SSD GPU
CPU CPU
SSD GPU
QPI
Pros:
対応HWが入手しやすい
Cons:
最大スループットが
PLXよりも低い
Pros:
最大限のスループットを
発揮できる(らしい)
Cons:
対応HWが限られる。
Pros:
なし
Cons:
遅い or 動かない
GpuScan + GpuJoin+ GpuPreAgg Combined Kernel (1/5)
Aggregation
GROUP BY
JOIN
SCAN
SELECT cat, count(*), avg(x)
FROM t0 JOIN t1 ON t0.id = t1.id
WHERE y like ‘%abc%’
GROUP BY cat;
count(*), avg(x)
GROUP BY cat
t0 JOIN t1
ON t0.id = t1.id
WHERE y like ‘%abc%’
実行結果
DB Tech Showcase 2017 - GPU/SSDがPostgreSQLを加速する-41
GpuScan
GpuJoin
Agg
+
GpuPreAgg




![GPU活用による計算 – 縮約アルゴリズムの例
●item[0]
step.1 step.2 step.4step.3
GPUを用いた
Σi=0...N-1item[i]
配列総和の計算
◆
●
▲ ■ ★
● ◆
●
● ◆ ▲
●
● ◆
●
● ◆ ▲ ■
●
● ◆
●
● ◆ ▲
●
● ◆
●
item[1]
item[2]
item[3]
item[4]
item[5]
item[6]
item[7]
item[8]
item[9]
item[10]
item[11]
item[12]
item[13]
item[14]
item[15]
log2N ステップで
items[]の総和を計算
HW支援によるコア間の同期機構
SELECT count(X),
sum(Y),
avg(Z)
FROM my_table;
集約関数の計算で用いる仕組み
DB Tech Showcase 2017 - GPU/SSDがPostgreSQLを加速する-5](https://image.slidesharecdn.com/20170906dbtsgpussdacceleratespostgresqljp-170906073226/85/GPU-SSD-PostgreSQL-10GB-s-DB-Tech-Showcase-Tokyo-2017-5-320.jpg)
![画像データ処理はSQL処理に似ている?
画像データ =
int/float[]型配列
転置
ID X Y Z
SELECT * FROM my_table
WHERE X BETWEEN 40 AND 60
並列処理
GPUの得意分野:同一の演算を大量のデータに対して適用する
DB Tech Showcase 2017 - GPU/SSDがPostgreSQLを加速する-6](https://image.slidesharecdn.com/20170906dbtsgpussdacceleratespostgresqljp-170906073226/85/GPU-SSD-PostgreSQL-10GB-s-DB-Tech-Showcase-Tokyo-2017-6-320.jpg)

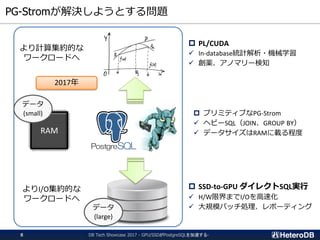







![簡単なマイクロベンチマーク
DB Tech Showcase 2017 - GPU/SSDがPostgreSQLを加速する-16
▌Test Query:
SELECT cat, count(*), avg(x)
FROM t0 NATURAL JOIN t1 [NATURAL JOIN t2 ...]
GROUP BY cat;
✓ t0 contains 100M rows, t1...t8 contains 100K rows (like a star schema)
8.48
13.23
18.28
23.42
28.88
34.50
40.77
47.16
5.00 5.46 5.91 6.45 7.17 8.07
9.22 10.21
0.0
5.0
10.0
15.0
20.0
25.0
30.0
35.0
40.0
45.0
50.0
2 3 4 5 6 7 8 9
QueryResponseTime[sec]
Number of tables joined
PG-Strom microbenchmark with JOIN/GROUP BY
PostgreSQL v9.6 PG-Strom 2.0devel
CPU: Xeon E5-2650v4
GPU: Tesla P40
RAM: 128GB
OS: CentOS 7.3
DB: PostgreSQL 9.6.2 +
PG-Strom 2.0devel](https://image.slidesharecdn.com/20170906dbtsgpussdacceleratespostgresqljp-170906073226/85/GPU-SSD-PostgreSQL-10GB-s-DB-Tech-Showcase-Tokyo-2017-16-320.jpg)








![ベンチマーク結果 (1/2)
351GBのlineorderテーブルに対し、下記のクエリQ1~Q4をそれぞれ実行。
(351 * 1024)/(クエリ応答時間)を処理スループットとして定義。
Q1... SELECT count(*) FROM lineorder;
Q2... SELECT count(*),sum(lo_revenue),sum(lo_supplycost) FROM lineorder;
Q3... SELECT count(*) FROM lineorder GROUP BY lo_orderpriority;
Q4... SELECT count(*),sum(lo_revenue),sum(lo_supplycost)
FROM lineorder GROUP BY lo_shipmode;
※ PostgreSQL v9.6のCPU並列度は24を指定、PG-Strom v2.0develのCPU並列度は4を指定。
889.05 859.31 875.69 842.04
5988.0 5989.9 5988.8 5979.6
0
1000
2000
3000
4000
5000
6000
Q1 Q2 Q3 Q4
QueryExecutionThroughput[MB/s]
PostgreSQL v9.6 + SN260 PG-Strom v2.0 + SN260
DB Tech Showcase 2017 - GPU/SSDがPostgreSQLを加速する-25](https://image.slidesharecdn.com/20170906dbtsgpussdacceleratespostgresqljp-170906073226/85/GPU-SSD-PostgreSQL-10GB-s-DB-Tech-Showcase-Tokyo-2017-25-320.jpg)
![ベンチマーク結果 (2/2)
物理メモリ 128GB のマシンで351GBのテーブルを全件スキャンしている事から、
ワークロードの律速要因はストレージ。
PG-Stromの場合、SSDのカタログスペックに近い読出し速度を達成できている。
PostgreSQLの場合、I/Oに伴うオーバーヘッドが大きい。
0
1000
2000
3000
4000
5000
6000
7000
0 100 200 300 400
StorageReadThroughput[MB/s]
Elapsed Time for Query Execution [sec]
Time Series Results (Q4) with iostat
PG-Strom v2.0devel + SN260 PostgreSQL v9.6 + SN260
[kaigai@saba ~]$ iostat -cdm 1
:
Device: tps MB_read/s MB_wrtn/s MB_read MB_wrtn
sda 6.00 0.19 0.00 0 0
sdb 0.00 0.00 0.00 0 0
sdc 0.00 0.00 0.00 0 0
nvme0n1 24059.00 5928.41 0.00 5928 0
:
DB Tech Showcase 2017 - GPU/SSDがPostgreSQLを加速する-26](https://image.slidesharecdn.com/20170906dbtsgpussdacceleratespostgresqljp-170906073226/85/GPU-SSD-PostgreSQL-10GB-s-DB-Tech-Showcase-Tokyo-2017-26-320.jpg)















































![[GTCJ2018]CuPy -NumPy互換GPUライブラリによるPythonでの高速計算- PFN奥田遼介](https://cdn.slidesharecdn.com/ss_thumbnails/gtcj2018cupypfnryosukeokuta-181009073034-thumbnail.jpg?width=640&height=640&fit=bounds)



![[B23] PostgreSQLのインデックス・チューニング by Tomonari Katsumata](https://cdn.slidesharecdn.com/ss_thumbnails/b23ntt-140624233630-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)







![[DI01] 窓は開かれた! SQL Server on Linux で拡がる可能性](https://cdn.slidesharecdn.com/ss_thumbnails/di01-170605023800-thumbnail.jpg?width=640&height=640&fit=bounds)









































