そもそもなんでKafka on AWS
lプラットフォーム⾮依存
l 海外への展開も考慮し、その都度適切なクラウドプラットフォームを選べるようにしたかった
l 肝であるプラットフォームの⼊り⼝はつくりこみたかった
l 今回の仕組み上、⼊り⼝兼プラットフォーム全体のバッファであるメッセージングは⾊々とつく
り込みたかったため、挙動やクセも含め中⾝のわかるプロダクトが適していた
l 機密なデータも扱うのでVPC(閉域に閉じたかった)
l 製造に必要な機密情報もやりとりされるため閉域網内でやりとりしたい・蓄積したい
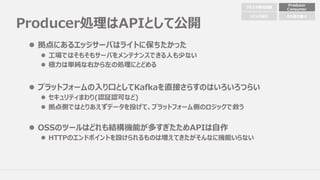
Producer処理はAPIとして公開
l 拠点にあるエッジサーバはライトに保ちたかった
l ⼯場ではそもそもサーバをメンテナンスできる⼈も少ない
l極⼒は単純な右から左の処理にとどめる
l プラットフォームの⼊り⼝としてKafkaを直接さらすのはいろいろつらい
l セキュリティまわり(認証認可など)
l 拠点側ではとりあえずデータを投げて、プラットフォーム側のロジックで救う
l OSSのツールはどれも結構機能が多すぎたためAPIは⾃作
l HTTPのエンドポイントを設けられるものは増えてきたがそんなに機能いらない
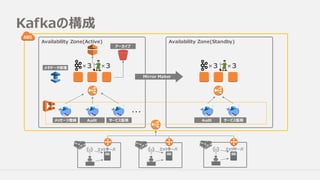
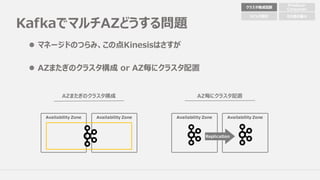
クラスタ構成配置
Producer
Consumer
トピック設計 その他の細々
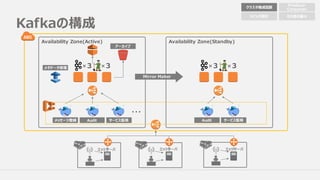
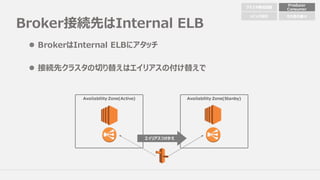
Broker接続先はInternal ELB
l BrokerはInternalELBにアタッチ
l 接続先クラスタの切り替えはエイリアスの付け替えで
クラスタ構成配置
Producer
Consumer
Availability Zone(Active) Availability Zone(Stanby)
トピック設計 その他の細々
エイリアスつけかえ
25.
Consumerは無難
l Spark Streamingon EMRがConsumerのメイン
l 待機系として利⽤するAZでは、当該AZに切り替わった時に⽴ち上げる
l ⼀部Consumerアプリケーションはあるが部分的
l 正直SaramaはConsumer処理の実装が弱いため
クラスタ構成配置
Producer
Consumer
トピック設計 その他の細々
26.
トピック設計
l トピックの作成単位は製造拠点(⼯場単位)
l ⼯場* 製品 * ⼯程 * 利⽤⽤途(順序性を考慮するか等) * 連携システム などを考慮し
た単位でトピック作成していくと爆発的に増えていくことを懸念
l 後続のSpark Streamingでロジックに応じた加⼯やルーティングを実施
l いったんKafkaにさえ⼊ってしまえばこっちのもの
クラスタ構成配置
Producer
Consumer
トピック設計 その他の細々
27.
レプリカ & Acks
lトピックの利⽤⽤途に応じて設定は変更
l 業務利⽤(使えないと業務が⽌まるレベル)はロストさせない/早く失敗させる
l 運⽤管理⽤途(ログの収集など)はほどほどに
l 業務的に重要なものは以下でトピック作成(それ以外は適宜)
l acks = all
l replication.factor=3
l min.insync.replica=3
クラスタ構成配置
Producer
Consumer
トピック設計 その他の細々
28.
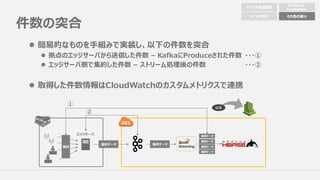
件数の突合
l 簡易的なものを⼿組みで実装し、以下の件数を突合
l 拠点のエッジサーバから送信した件数– KafkaにProduceされた件数 ・・・①
l エッジサーバ側で集約した件数 – ストリーム処理後の件数 ・・・②
l 取得した件数情報はCloudWatchのカスタムメトリクスで連携
クラスタ構成配置
Producer
Consumer
トピック設計 その他の細々
エッジサーバ
集約
①
②
集約データ 集約データ
個別データ
個別データ
個別データ
個別データ
結果











![Kafkaのメトリクス取得
l Consumerのオフセット値取得や遅延監視にlinkedin/Burrowを利⽤
l https://github.com/linkedin/Burrow
クラスタ構成配置
Producer
Consumer
トピック設計 その他の細々
{
"error": false,
"message": "consumer group topic offsets returned",
"offsets": [
26,
29,
28
],
"request": {
"cluster": “cluster01",
"group": ”consumer-group01",
"host": “hostname",
"topic": ”some_topic",
"url": "/v2/kafka/local/consumer/consumer-group01/topic/some_topic"
}
}
http://<Burow稼働ホスト>:8000/v2/kafka/cluster01/consumer/consumer-group01/topic/some_topic](https://image.slidesharecdn.com/awsapachekafka-161214113900/85/Aws-apache-kafka-29-320.jpg)