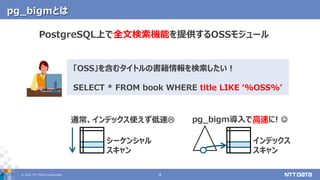
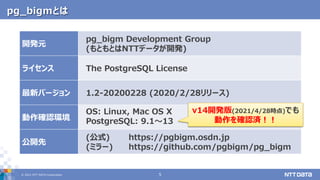
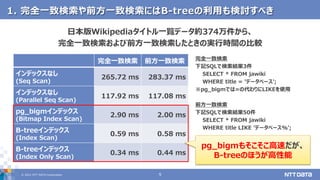
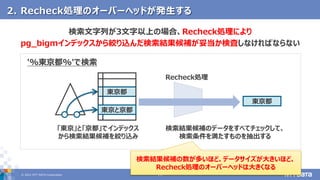
pg_bigmで全文検索するときに気を付けたい5つのポイント (第23回PostgreSQLアンカンファレンス@オンライン 発表資料) 2021年5月11日 株式会社NTTデータ 技術開発本部 先進コンピューティング技術センタ 藤井 雅雄