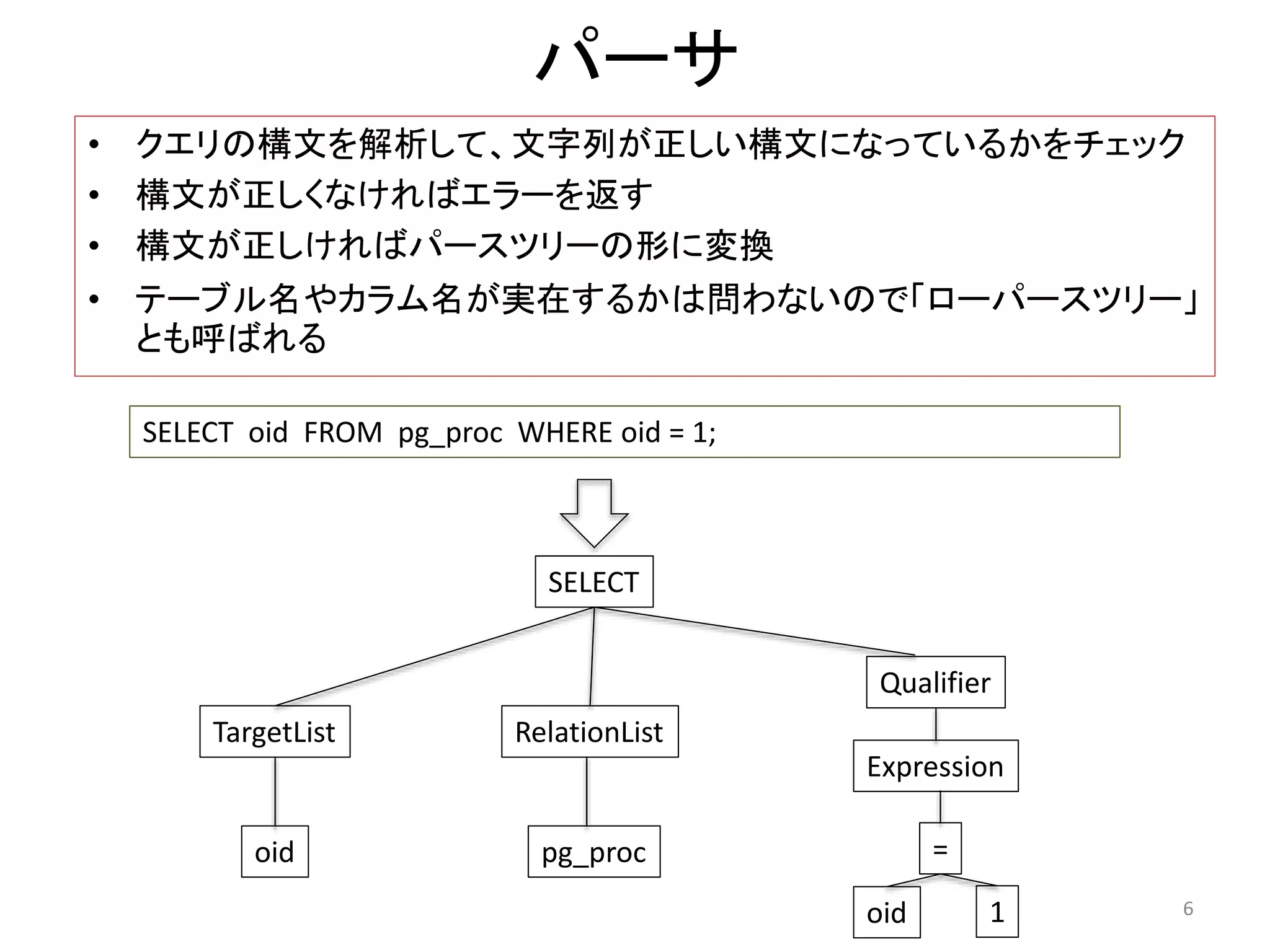
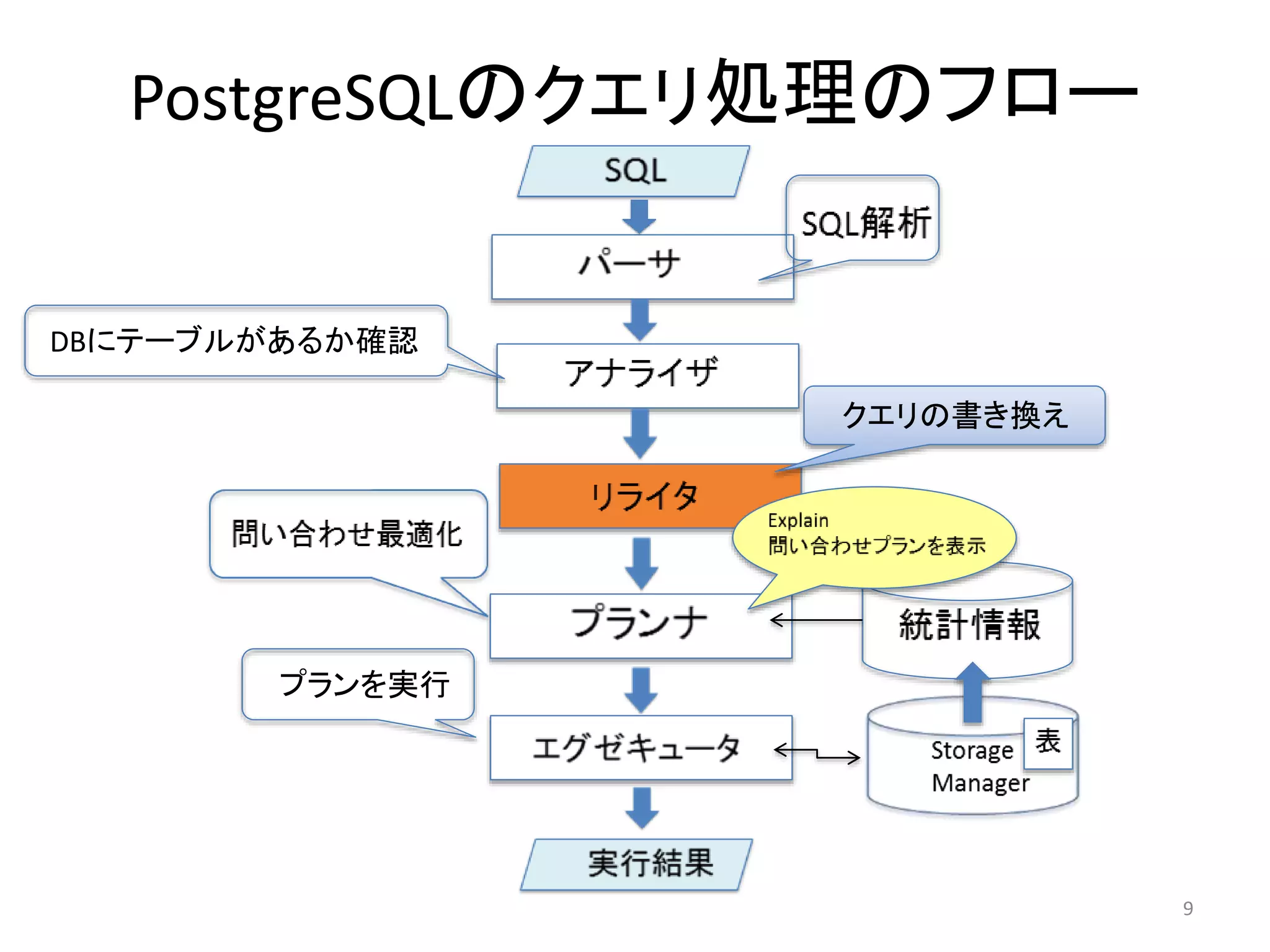
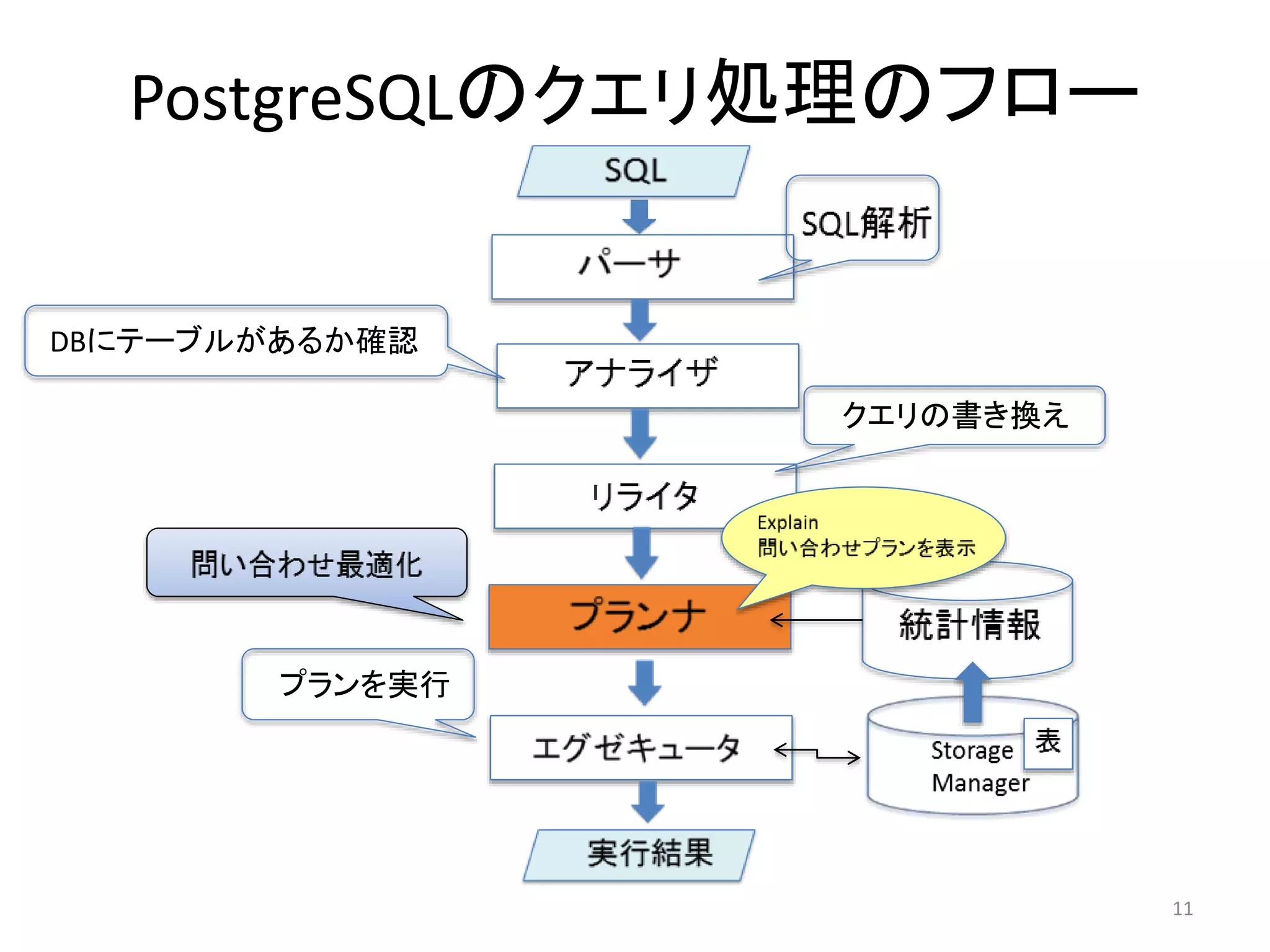
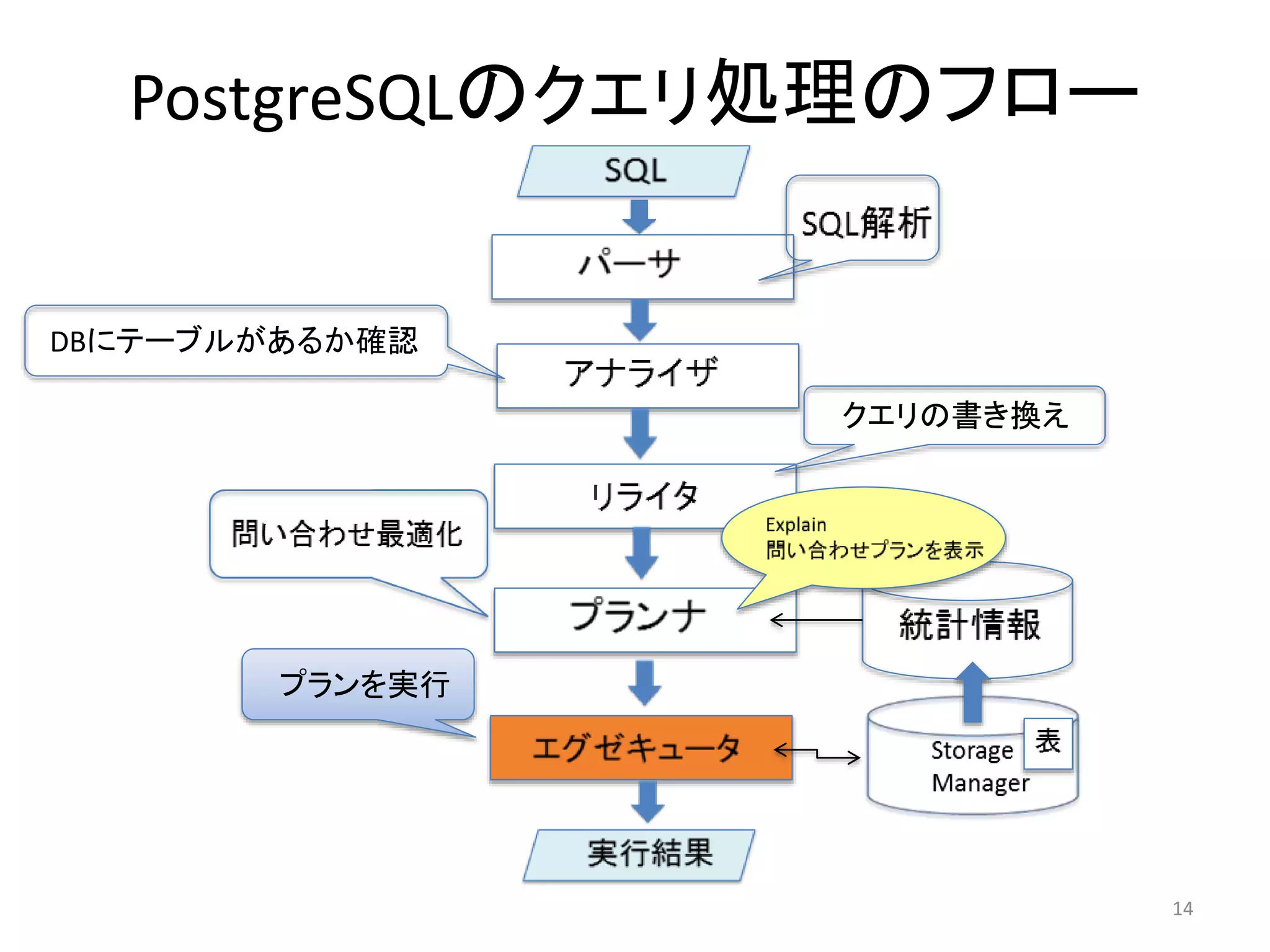
パーサ
• クエリの構文を解析して、文字列が正しい構文になっているかをチェック
• 構文が正しくなければエラーを返す
• 構文が正しければパースツリーの形に変換
• テーブル名やカラム名が実在するかは問わないので「ローパースツリー」
とも呼ばれる
SELECT oid FROM pg_proc WHERE oid = 1;
SELECT
TargetList
oid
RelationList
pg_proc
Qualifier
Expression
=
oid 1 6
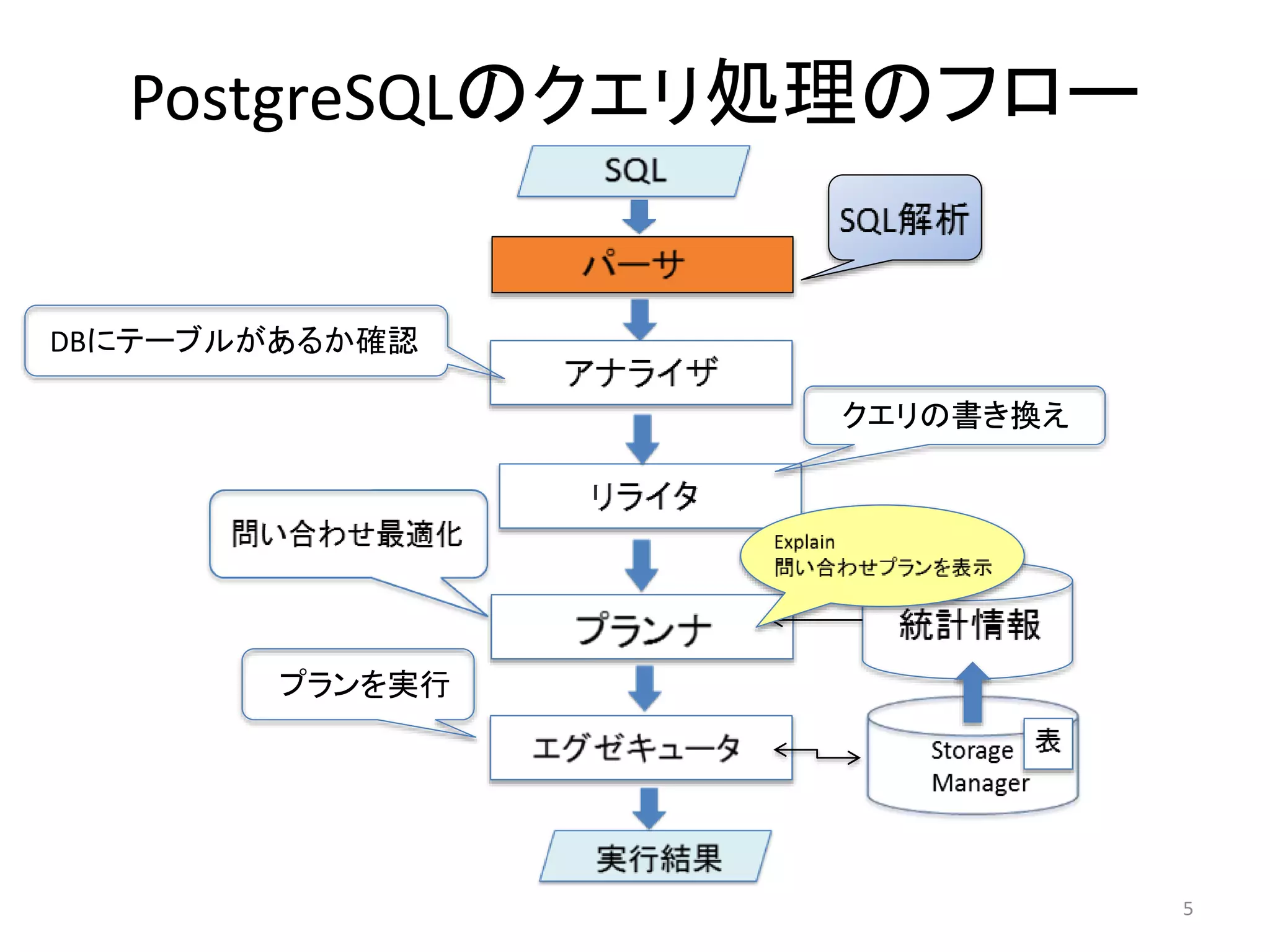
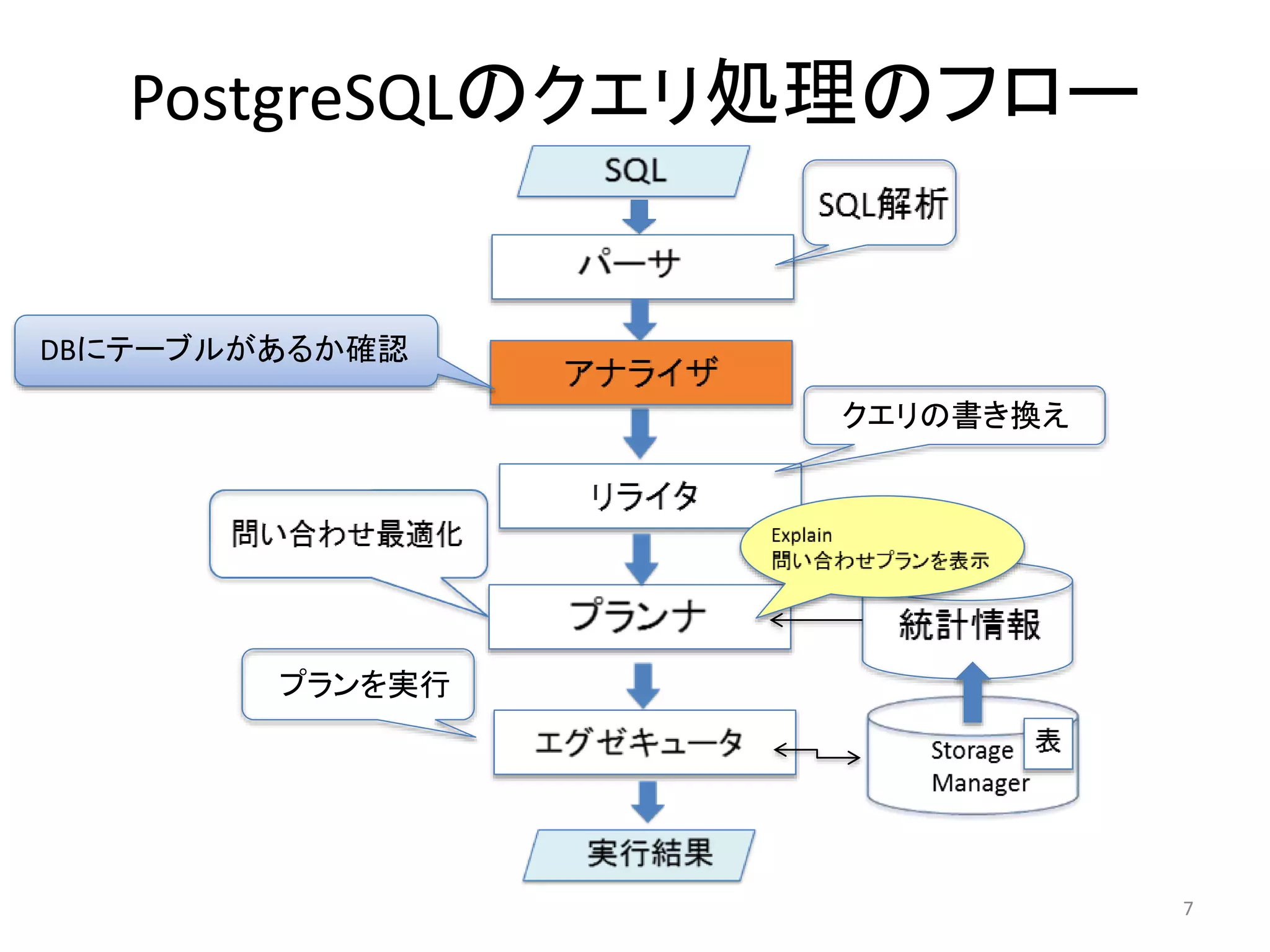
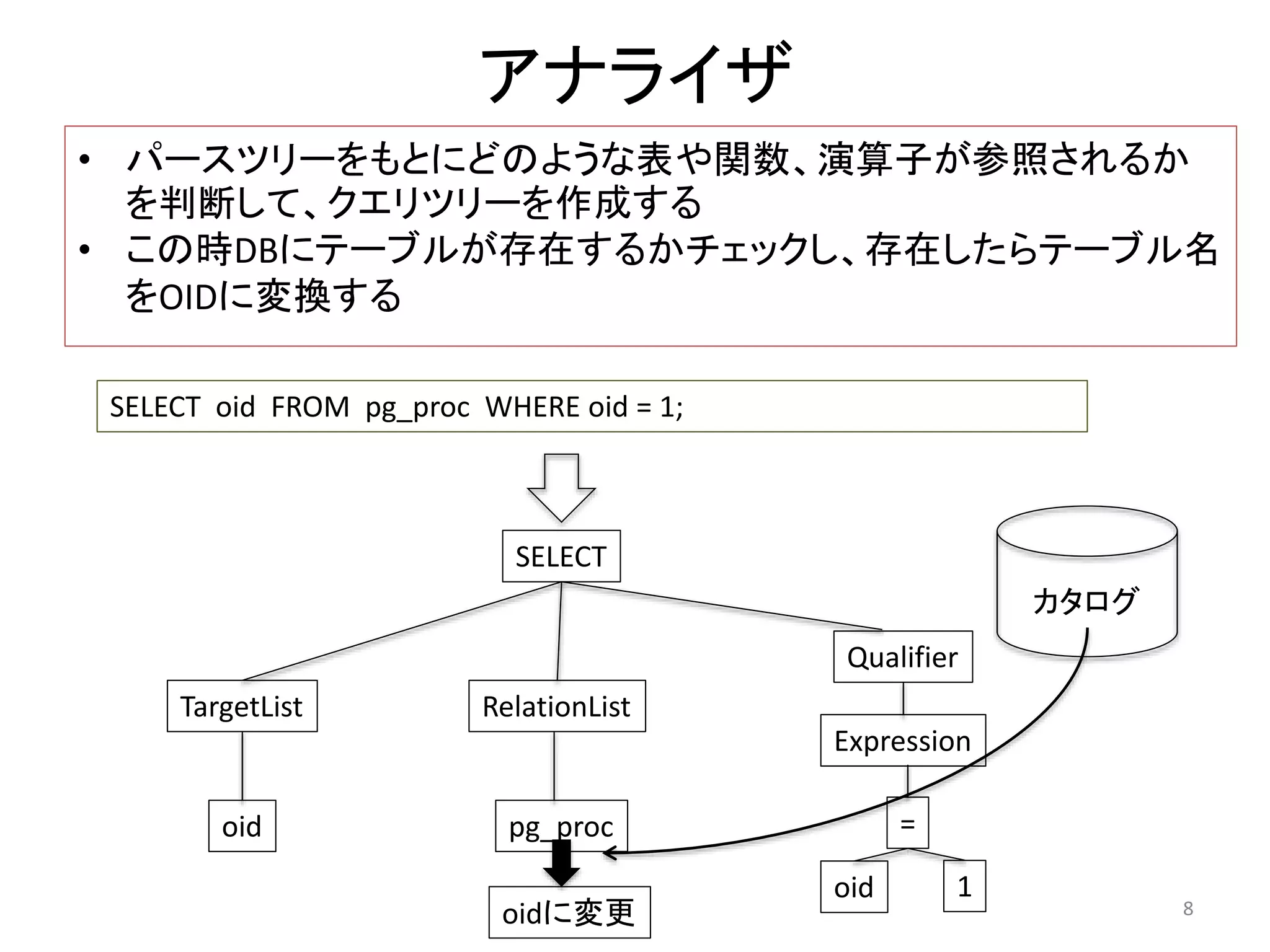
アナライザ
• パースツリーをもとにどのような表や関数、演算子が参照されるか
を判断して、クエリツリーを作成する
• この時DBにテーブルが存在するかチェックし、存在したらテーブル名
をOIDに変換する
SELECT oid FROM pg_proc WHERE oid = 1;
SELECT
TargetList
oid
RelationList
pg_proc
Qualifier
Expression
=
oid 1
カタログ
oidに変更8
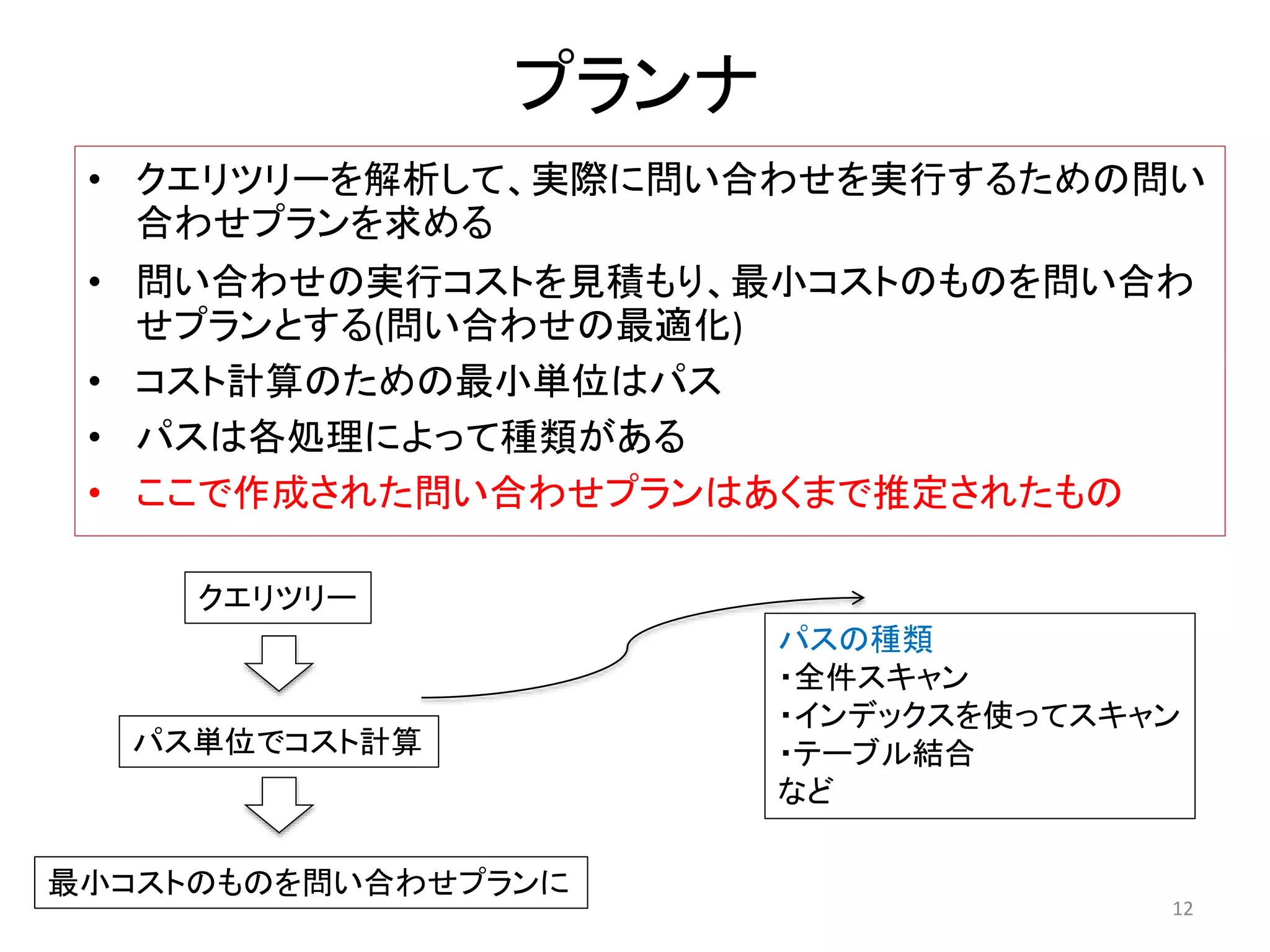
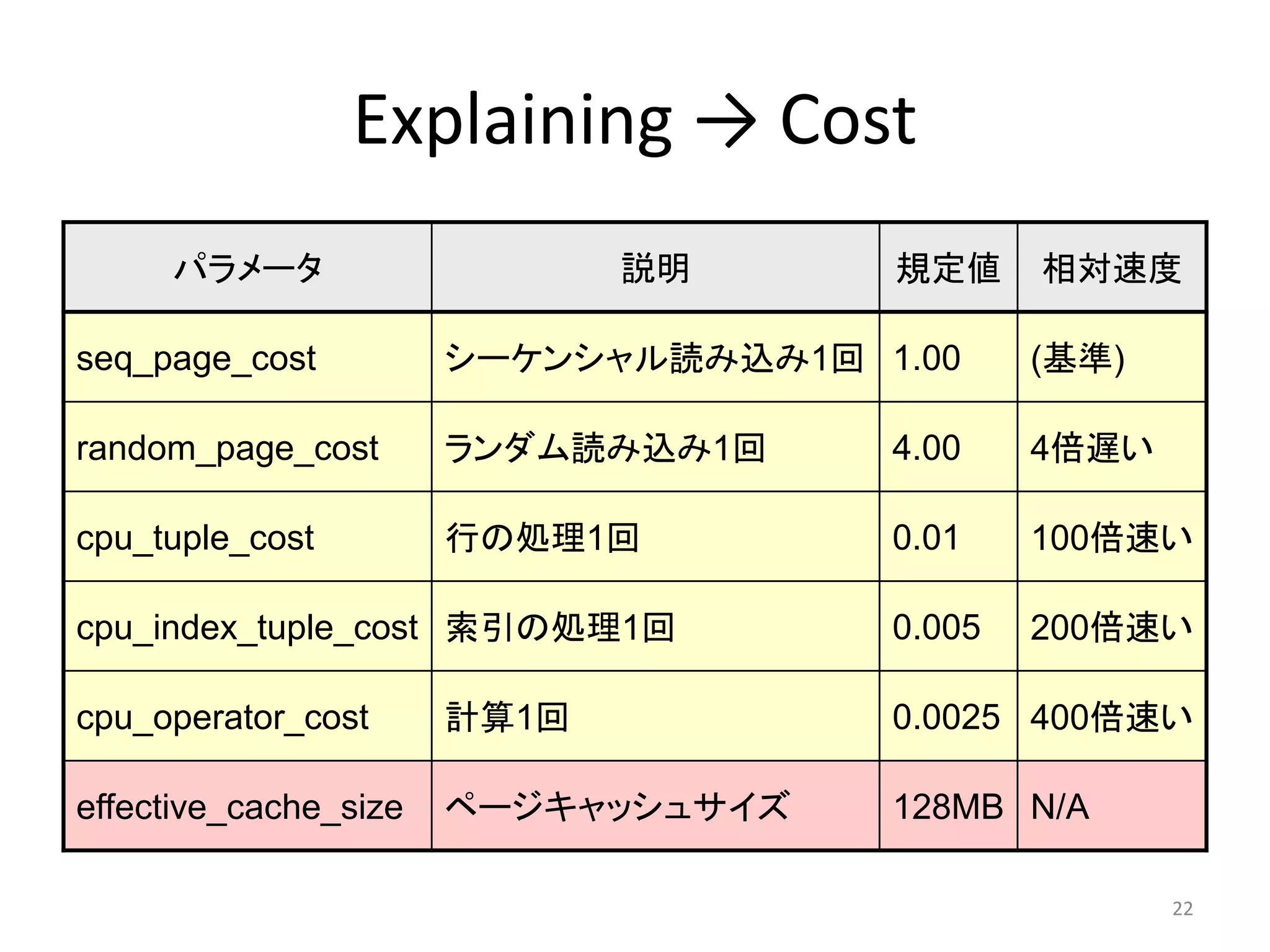
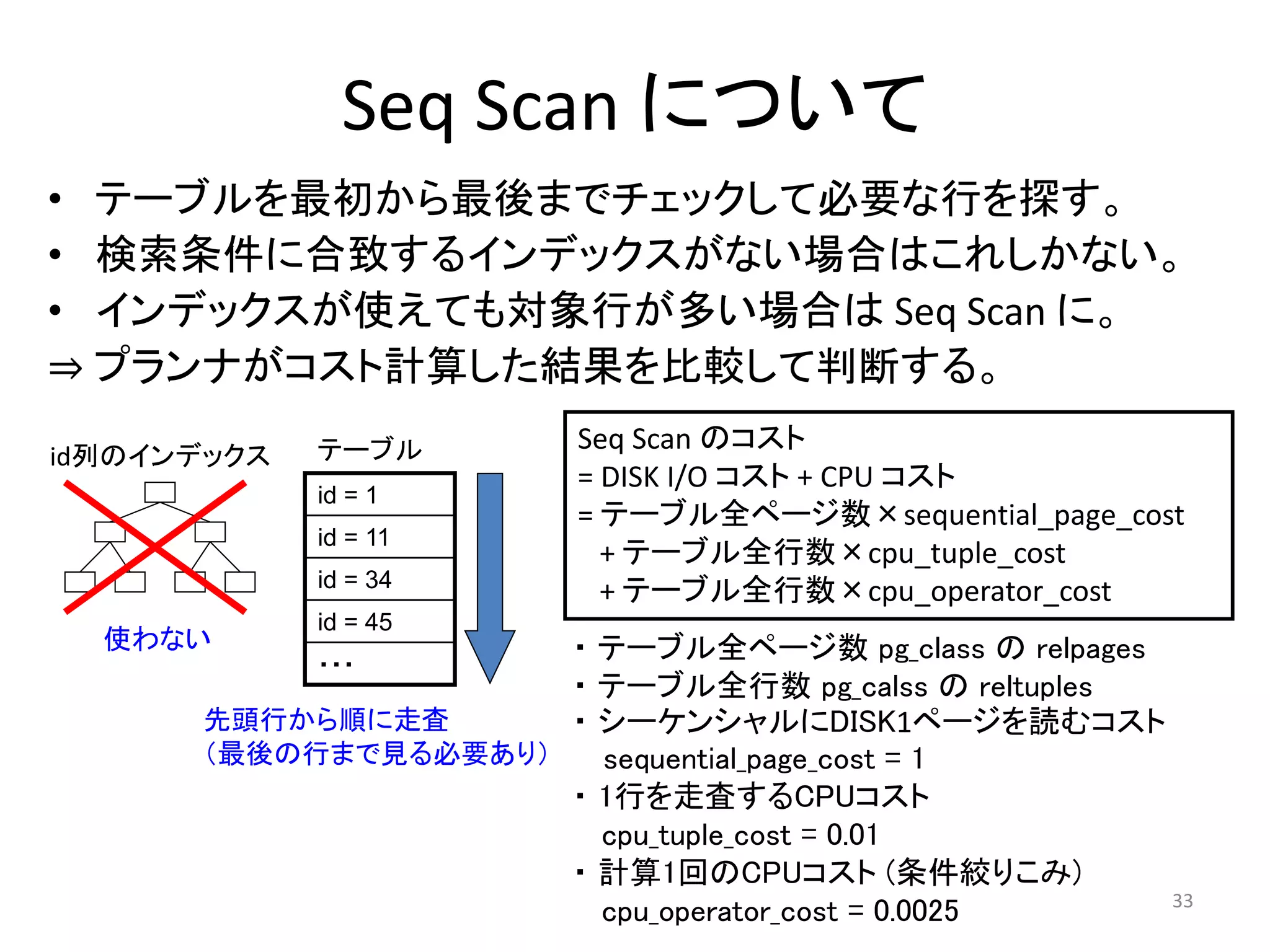
Seq Scanのコスト計算
SeqScanのコスト= (DISK I/Oコスト)+(CPUコスト)
=(テーブル全ページ数×Seq_page_cost)
+(テーブル全行数×cpu_tuple_cost )
+(テーブル全行数×cpu_operator_cost)
34
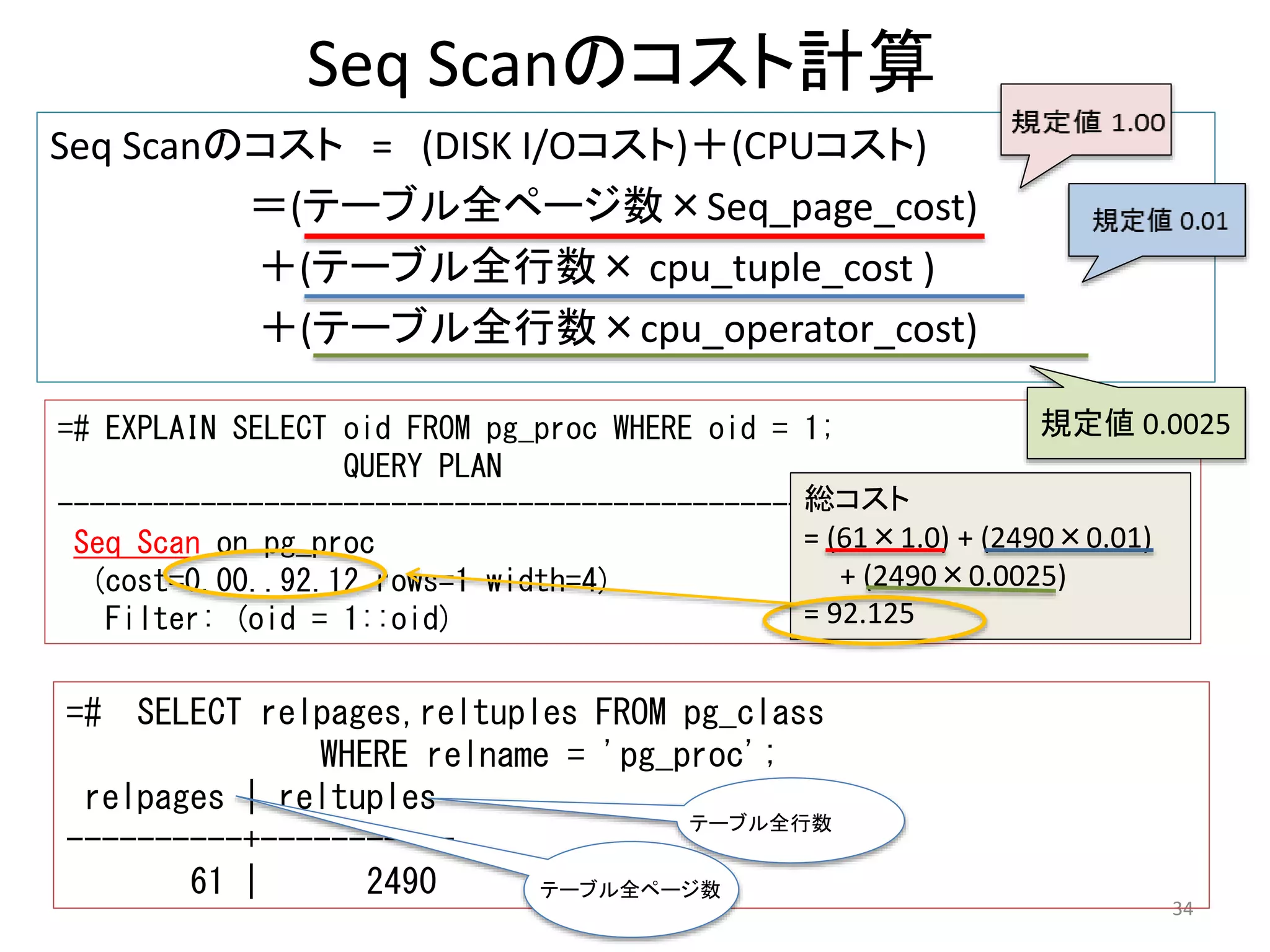
=# EXPLAIN SELECT oid FROM pg_proc WHERE oid = 1;
QUERY PLAN
--------------------------------------------------
Seq Scan on pg_proc
(cost=0.00..92.12 rows=1 width=4)
Filter: (oid = 1::oid)
=# SELECT relpages,reltuples FROM pg_class
WHERE relname = 'pg_proc';
relpages | reltuples
----------+-----------
61 | 2490
総コスト
= (61×1.0) + (2490×0.01)
+ (2490×0.0025)
= 92.125
テーブル全行数
テーブル全ページ数
規定値0.0025
35.
-----------------------------------------------------
Index Scanusing pg_proc_oid_index on pg_proc
35
Index Scan 演算子
=# EXPLAIN SELECT oid FROM pg_proc WHERE oid=1;
QUERY PLAN
(cost=0.00..5.99 rows=1 width=4)
Index Cond: (oid = 1::oid)
• 特に大きなテーブルではコストが低くなるので選ば
れる可能性が高い
• Index Condが無い場合は、ソートの代わりとして使
われるインデックス順のフルスキャンを表す
36.
36
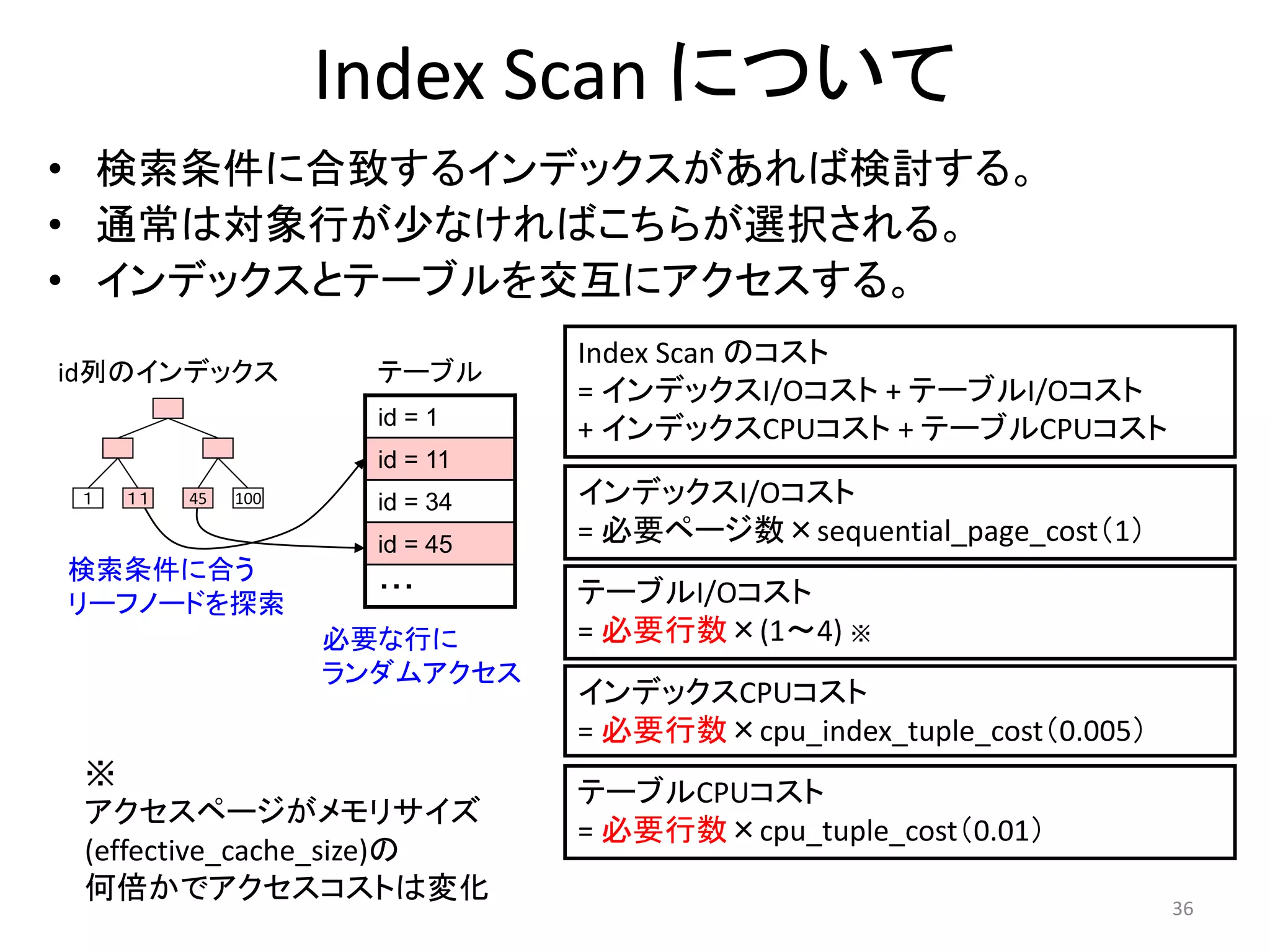
Index Scanについて
• 検索条件に合致するインデックスがあれば検討する。
• 通常は対象行が少なければこちらが選択される。
• インデックスとテーブルを交互にアクセスする。
id列のインデックステーブル
id = 1
id = 11
id = 34
id = 45
・・・
1 11 45 100
検索条件に合う
リーフノードを探索
必要な行に
ランダムアクセス
Index Scan のコスト
= インデックスI/Oコスト+ テーブルI/Oコスト
+ インデックスCPUコスト+ テーブルCPUコスト
インデックスI/Oコスト
= 必要ページ数×sequential_page_cost(1)
テーブルI/Oコスト
= 必要行数×(1~4) ※
インデックスCPUコスト
= 必要行数×cpu_index_tuple_cost(0.005)
テーブルCPUコスト
= 必要行数×cpu_tuple_cost(0.01)
※
アクセスページがメモリサイズ
(effective_cache_size)の
何倍かでアクセスコストは変化
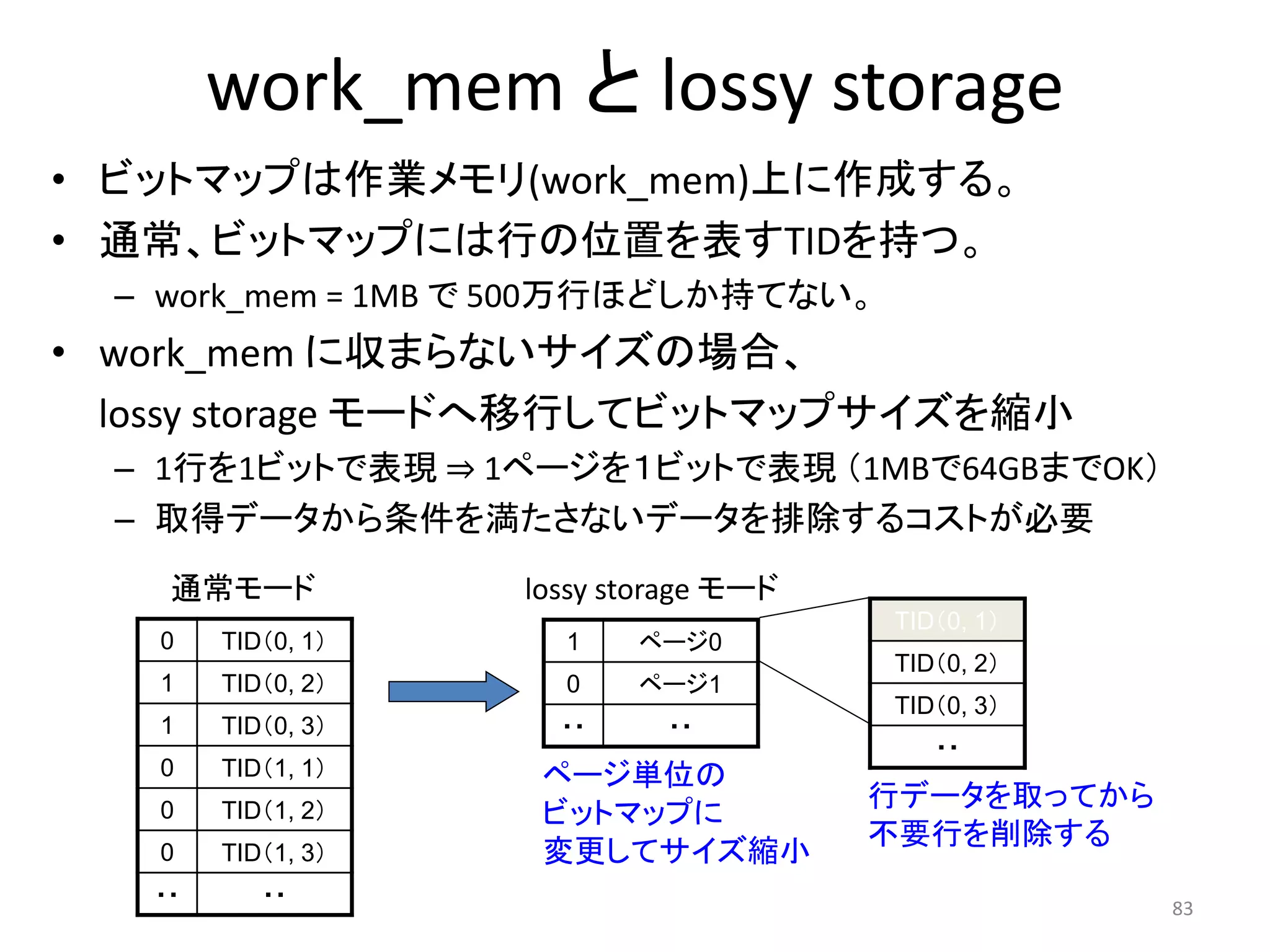
Index Only Scan
• 9.2で追加された
• 取得したい値にインデックスが含まれるとき、テーブ
ルのアクセスを省略して検索する
• 非常に高速(しかしindex only scanが選ばれるには
条件が…)
40
41.
Index Only Scanのスキャン方法
• Index Only ScanはまずインデックスからVisibility
Mapを参照しに行く(早速テーブルには行かない)
• そして高速に値を返せるか返せないかは、実はこの
Visibility Mapにかかっている
→このVisibility Mapって一体何者なの?
41
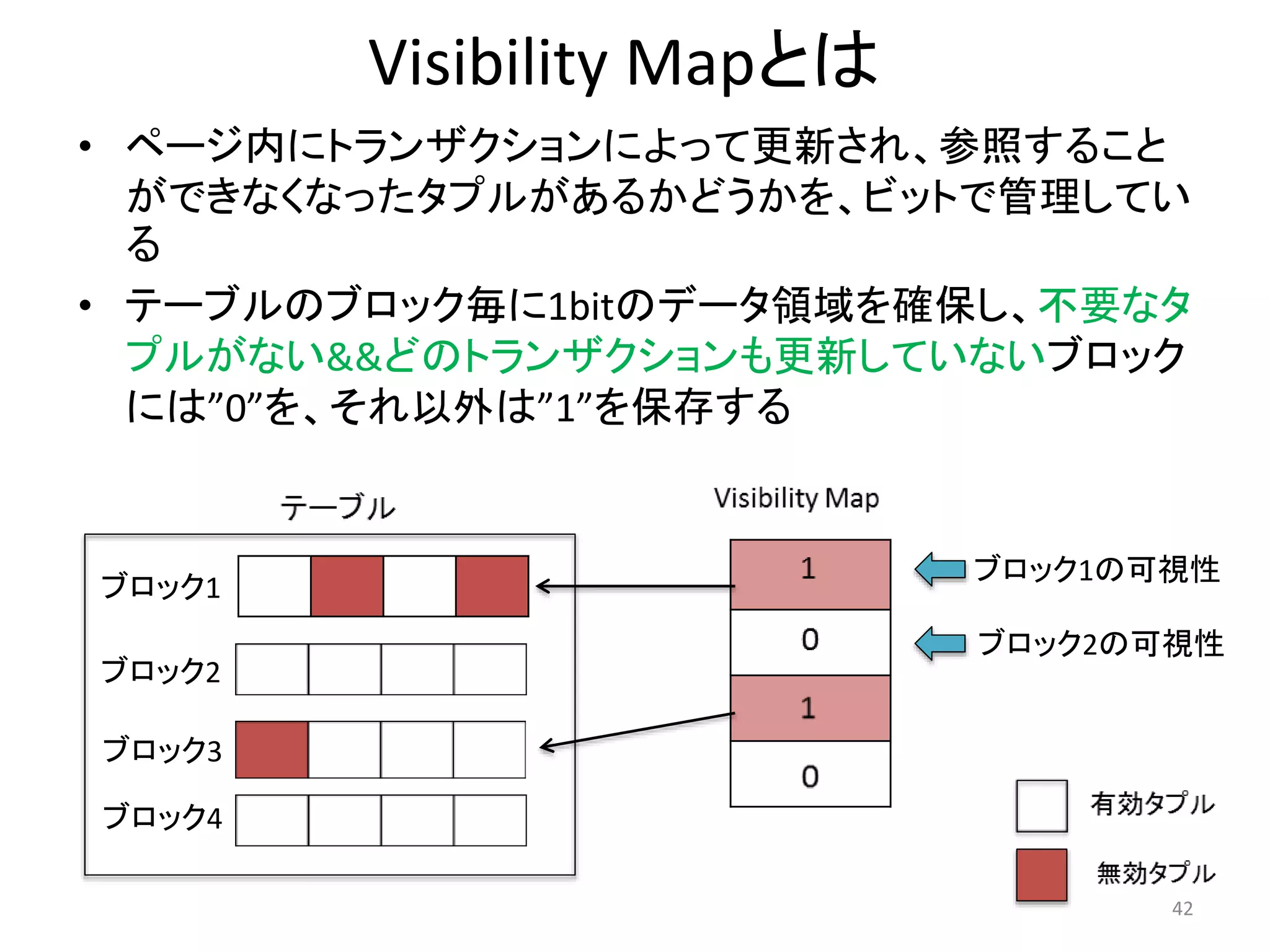
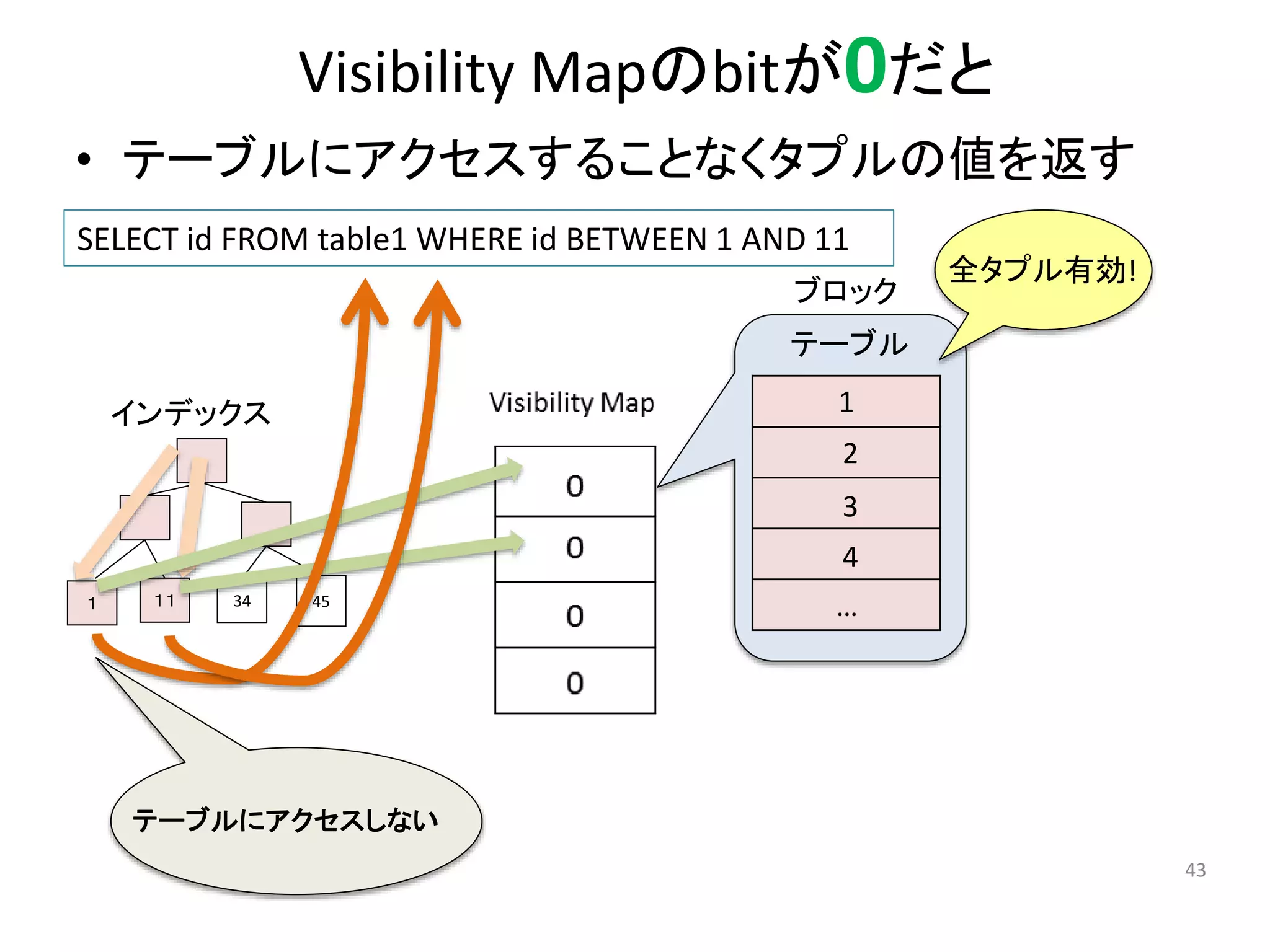
Visibility Mapのbitが0だと
•テーブルにアクセスすることなくタプルの値を返す
43
SELECT id FROM table1 WHERE id BETWEEN 1 AND 11
ブロック
1
2
3
4
…
全タプル有効!
インデックス
1 11 34 45
テーブル
テーブルにアクセスしない
44.
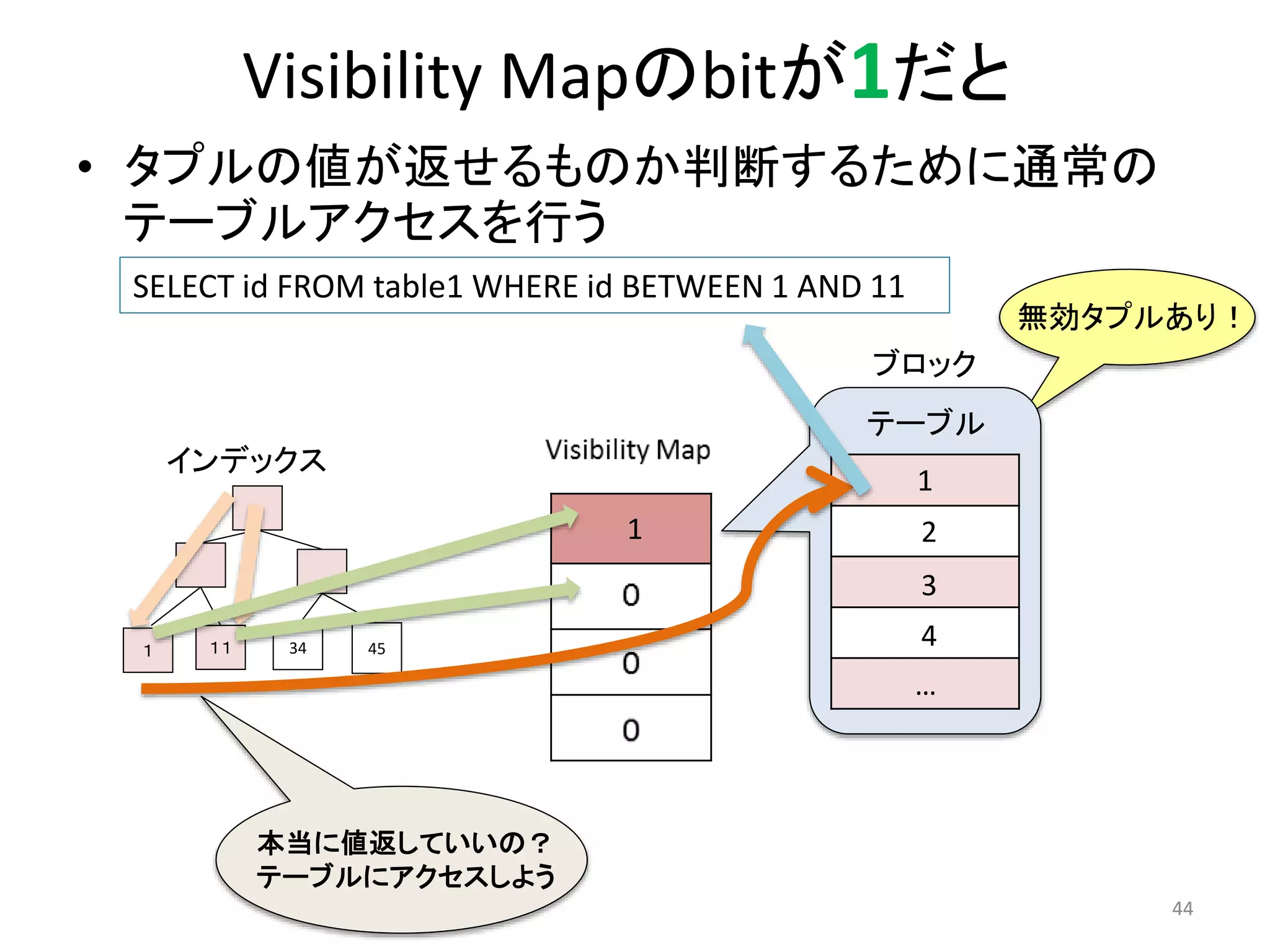
Visibility Mapのbitが1だと
•タプルの値が返せるものか判断するために通常の
テーブルアクセスを行う
無効タプルあり!
44
SELECT id FROM table1 WHERE id BETWEEN 1 AND 11
ブロック
1
2
3
4 1 11 34 45
…
インデックス
テーブル
1
本当に値返していいの?
テーブルにアクセスしよう
46
Tid Scan演算子
=# EXPLAIN SELECT oid FROM pg_proc WHERE ctid = '(0,1)';
QUERY PLAN
------------------------------------------------------
Tid Scan on pg_proc (cost=0.00..4.01 rows=1 width=4)
Filter: (ctid = '(0,1)'::tid)
• カラムタプルID
• “ctid=”がクエリに指定された場合のみ使われる
• 滅多に使わない、非常に速い
47.
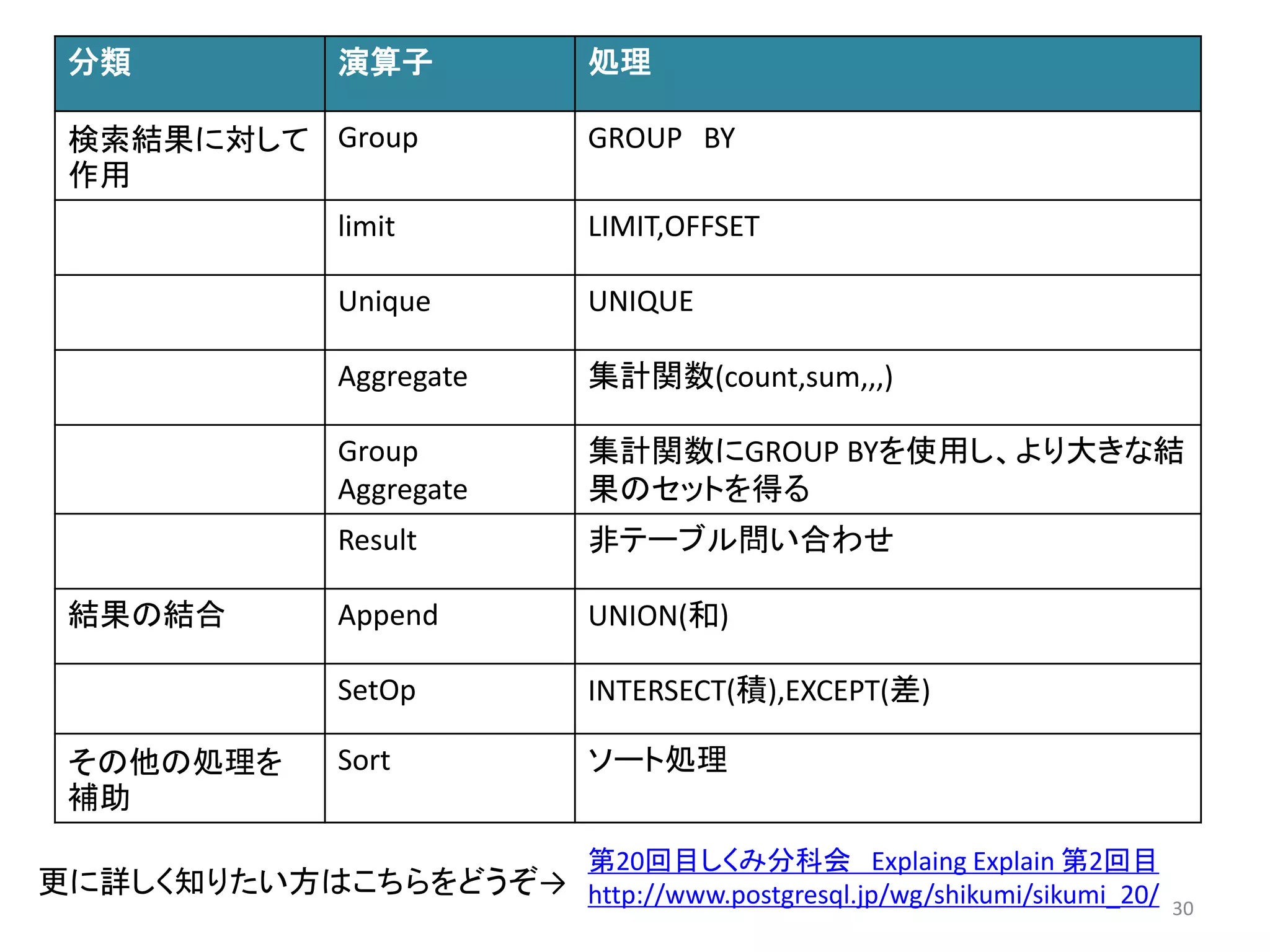
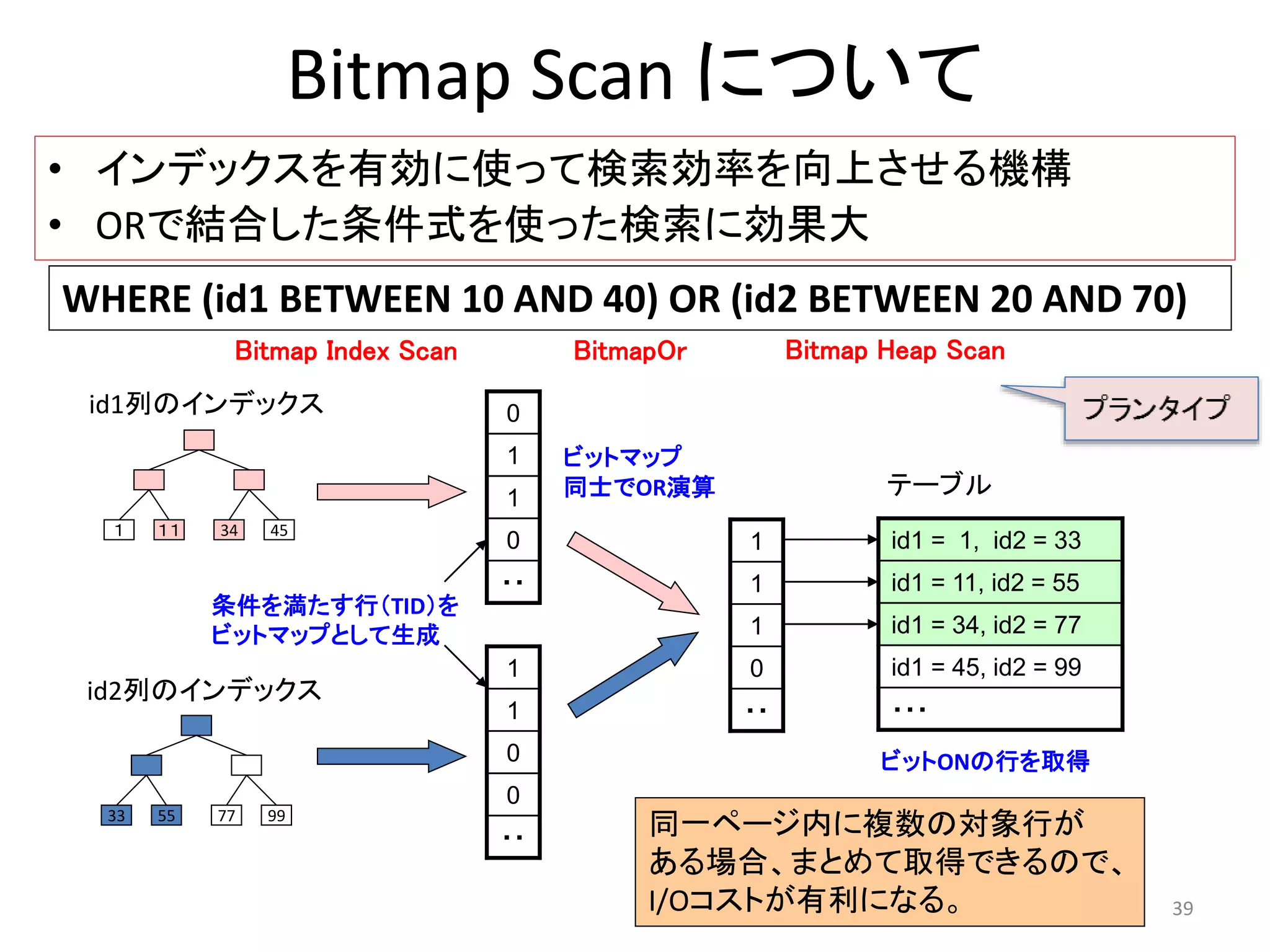
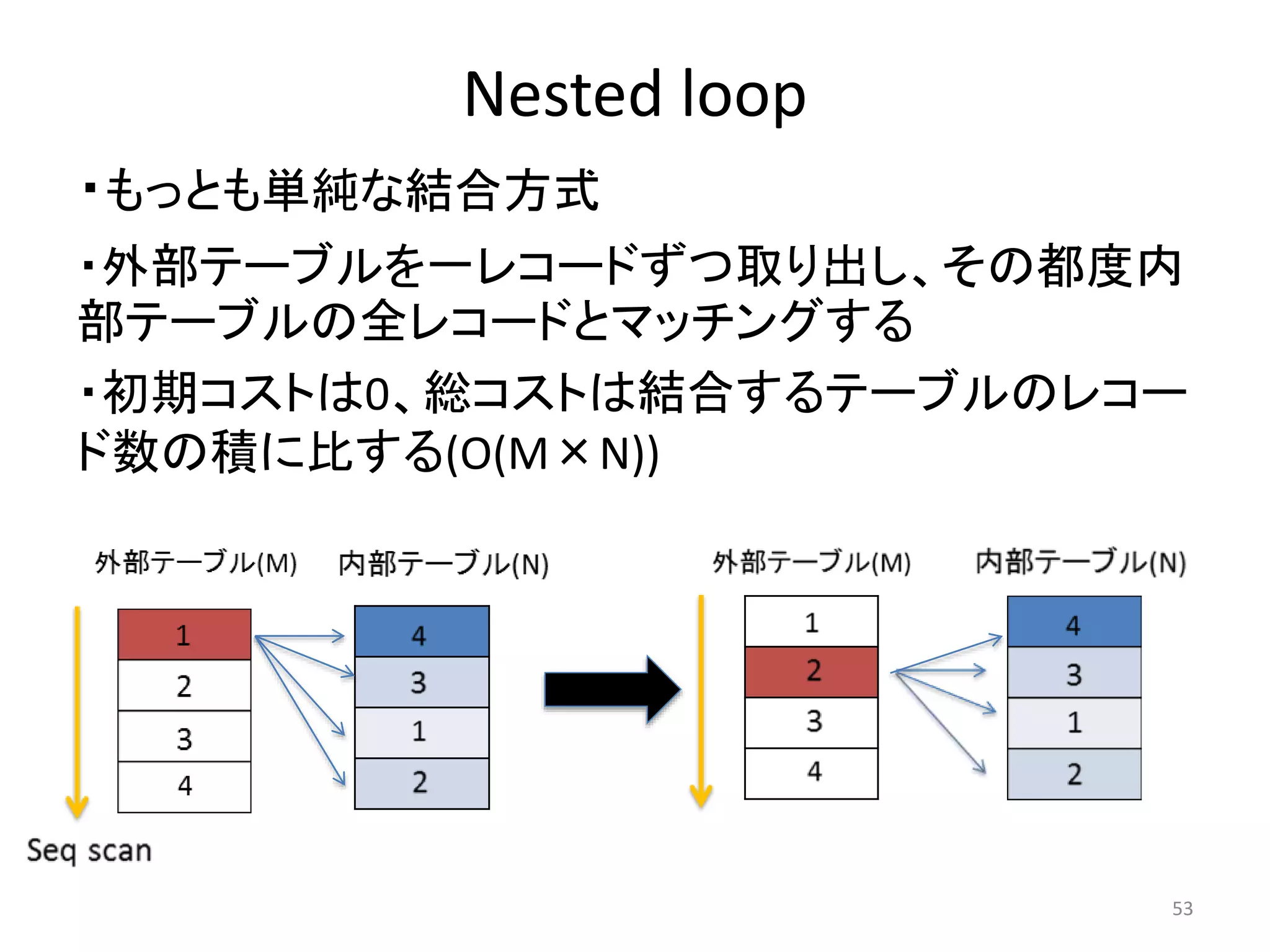
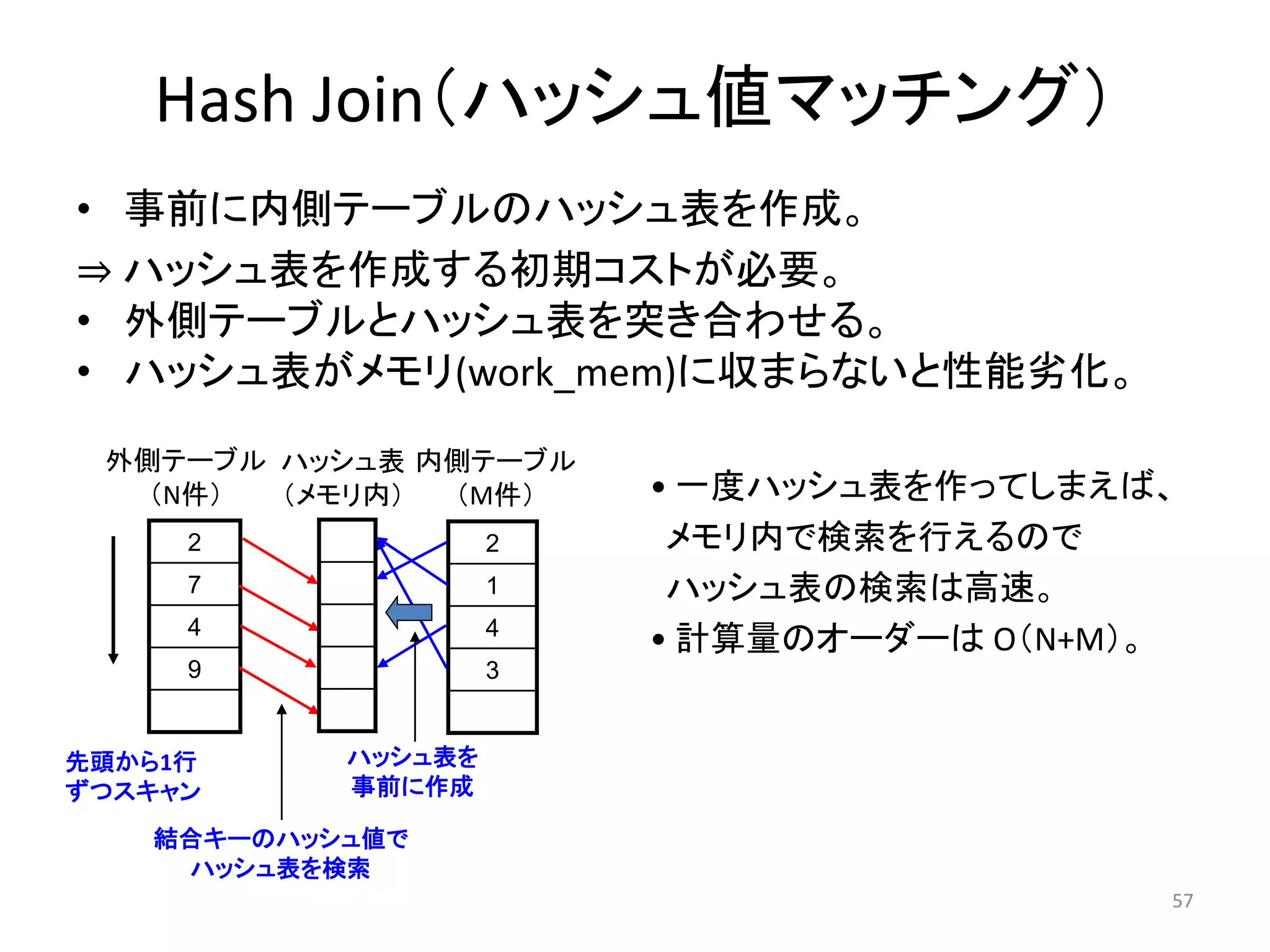
処理を補助する演算子
47
分類演算子
テーブルスキャンSeq Scan
Index Scan
Bitmap Scan
Index Only Scan
Tid Scan
その他スキャンFunction Scan
テーブルの結合Nested Loop
Merge Join
Hash Join
分類演算子
検索結果に対して
作用
Group
limit
Unique
Aggregate
Group Aggregate
Result
結果の結合Append
SetOp
その他の処理を補
助
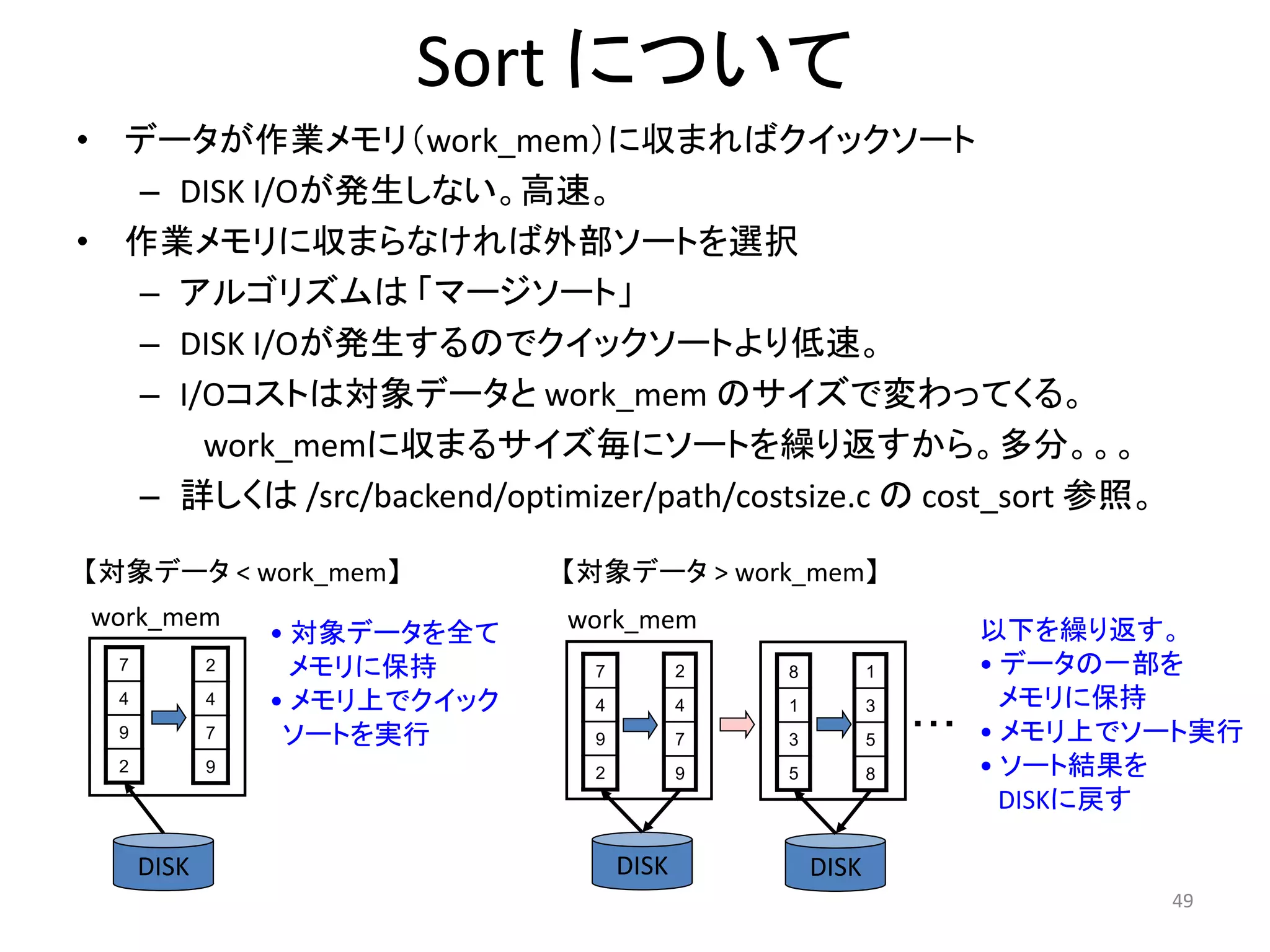
Sort
48.
48
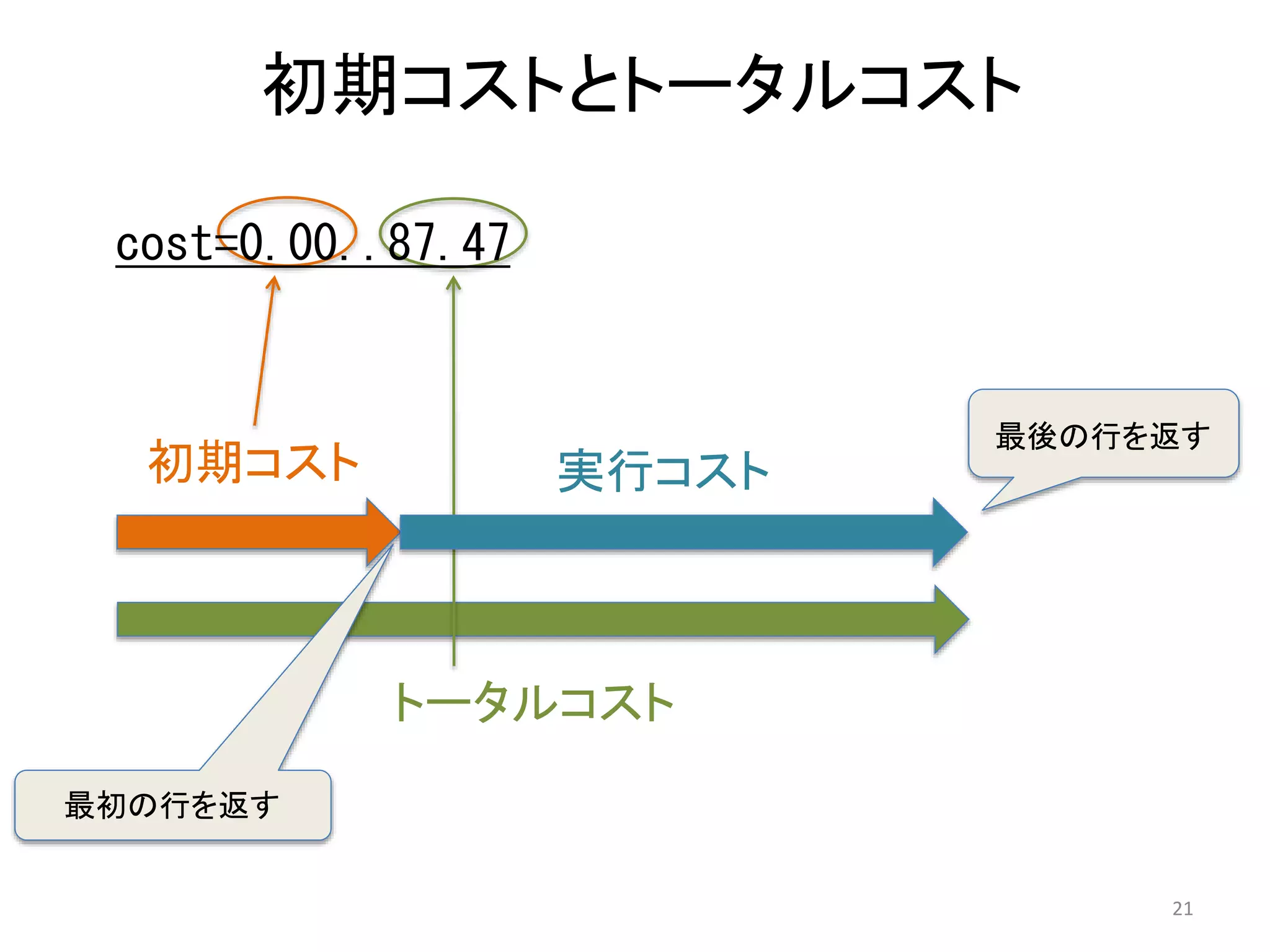
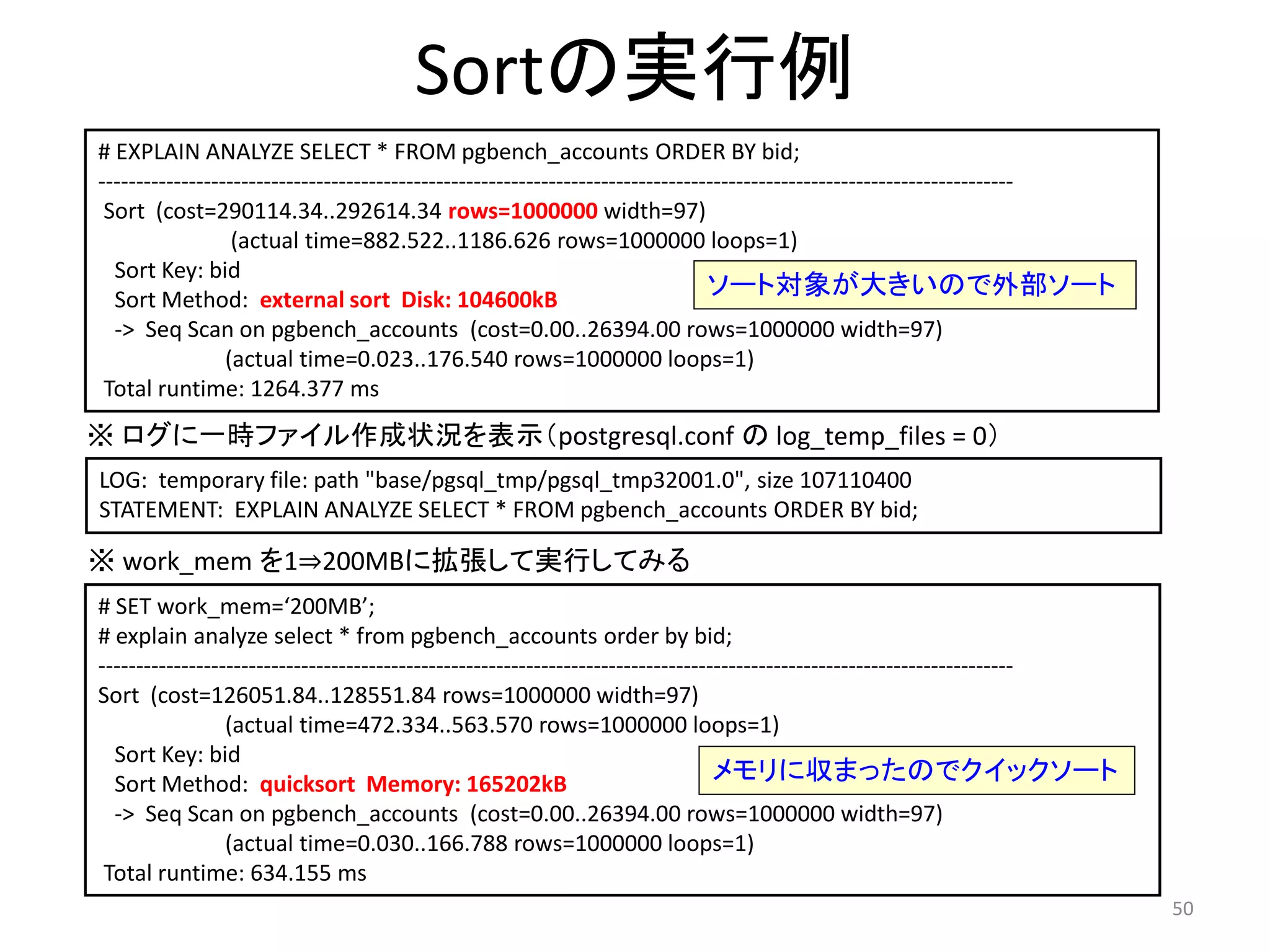
Sort 演算子
=# EXPLAIN SELECT oid FROM pg_proc ORDER BY oid;
QUERY PLAN
---------------------------------------------
Sort (cost=181.55..185.92 rows=1747 width=4)
Sort Key: oid
-> Seq Scan on pg_proc
(cost=0.00..87.47 rows=1747 width=4)
• 明示的なソート: ORDER BY句
• 暗黙的なソート: Unique, Sort-Merge Join など
• 開始コストを持っている: 最初の値はすぐには返却
されない
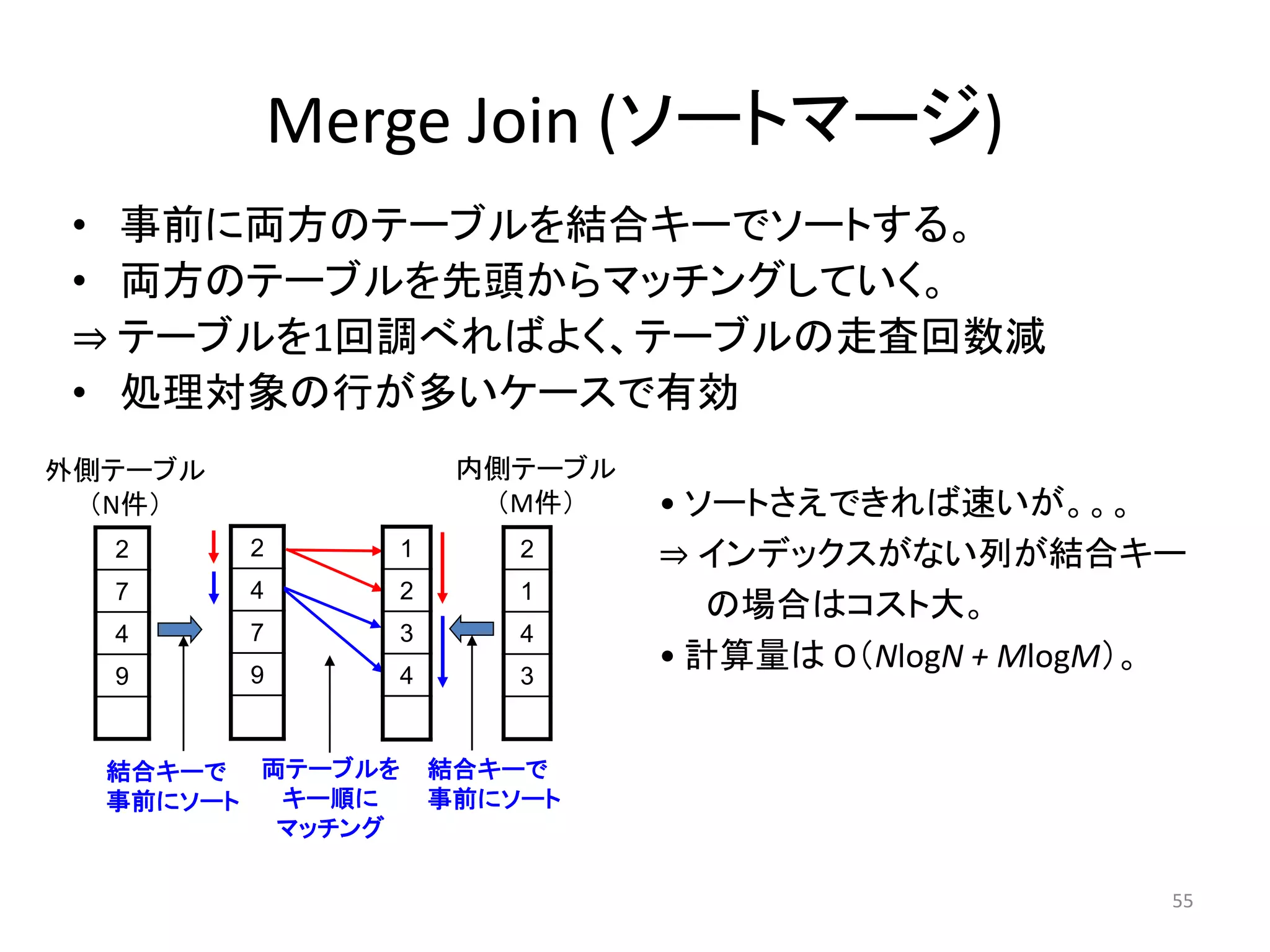
Merge Join 演算子
# EXPLAIN SELECT * FROM pgbench_accounts AS a,
pgbench_tellers AS t where a.aid = t.tid;
QUERY PLAN
---------------------------------------------------------------
Merge Join (cost=5.94..11.25 rows=100 width=449)
Merge Cond: (a.aid = t.tid)
-> Index Scan using pgbench_accounts_pkey on pgbench_accounts a
(cost=0.42..39669.43 rows=1000000 width=97)
-> Sort (cost=5.32..5.57 rows=100 width=352)
Sort Key: t.tid
-> Seq Scan on pgbench_tellers t
(cost=0.00..2.00 rows=100 width=352)
• 二つのデータセットをJOINする:outerとinner
• Merge Right JoinとMerge In Joinがある
• データセットはあらかじめソートされていなければならず、また両方同
時に走査される。
54
検索結果に対して作用する演算子
59
分類演算子
テーブルスキャンSeq Scan
Index Scan
Bitmap Scan
Index Only Scan
Tid Scan
その他スキャンFunction Scan
テーブルの結合Nested Loop
Merge Join
Hash Join
分類演算子
検索結果に対して
作用
Group
limit
Unique
Aggregate
Group Aggregate
Result
結果の結合Append
SetOp
その他の処理を補
助
Sort
60.
60
Limit 演算子
=# EXPLAIN SELECT oid FROM pg_proc LIMIT 5;
QUERY PLAN
------------------------------------------
Limit (cost=0.00..0.25 rows=5 width=4)
-> Seq Scan on pg_proc
(cost=0.00..87.47 rows=1747 width=4)
• 行は指定された数に等しい
• 最初の行を即時に返す
• 少量の開始コスト追加でオフセットの扱いも可
=# EXPLAIN SELECT oid FROM pg_proc LIMIT 5 OFFSET 5;
QUERY PLAN
------------------------------------------
Limit (cost=0.25..0.50 rows=5 width=4)
-> Seq Scan on pg_proc
(cost=0.00..87.47 rows=1747 width=4)
61.
61
Result 演算子
=# EXPLAIN SELECT 1 + 1 ;
QUERY PLAN
------------------------------------------
Result (cost=0.00..0.01 rows=1 width=0)
• 非テーブル問い合わせ
• テーブルを参照せずに結果が得られる場合
62.
結果を結合する演算子
62
分類演算子
テーブルスキャンSeq Scan
Index Scan
Bitmap Scan
Index Only Scan
Tid Scan
その他スキャンFunction Scan
テーブルの結合Nested Loop
Merge Join
Hash Join
分類演算子
検索結果に対して
作用
Group
limit
Unique
Aggregate
Group Aggregate
Result
結果の結合Append
SetOp
その他の処理を補
助
Sort
63.
63
Append 演算子
=# EXPLAIN SELECT oid FROM pg_proc
UNION ALL SELECT oid ORDER BY pg_proc;
QUERY PLAN
--------------------------------------------------------------
Append (cost=0.00..209.88 rows=3494 width=4)
-> Seq Scan on pg_proc (cost=0.00..87.47 rows=1747 width=4)
-> Seq Scan on pg_proc (cost=0.00..87.47 rows=1747 width=4)
• UNION (ALL) によるトリガー, 継承
• 開始コスト無し
• コストは単に全ての入力の合計
64.
------------------------------------------------------------------------
SetOp Intersect(cost=415.51..432.98 rows=349 width=4)
-> Subquery Scan "*SELECT* 1" (cost=0.00..104.94 rows=1747)
-> Subquery Scan "*SELECT* 2" (cost=0.00..104.94 rows=1747)
64
SetOp 演算子
=# EXPLAIN SELECT oid FROM pg_proc INTERSECT SELECT oid FROM pg_proc;
QUERY PLAN
-> Sort (cost=415.51..424.25 rows=3494 width=4)
Sort Key: oid
-> Append (cost=0.00..209.88 rows=3494 width=4)
-> Seq Scan on pg_proc (cost=0.00..87.47 rows=1747)
-> Seq Scan on pg_proc (cost=0.00..87.47 rows=1747)
• INTERSECT, INTERSECT ALL, EXCEPT, EXCEPT ALL句
のために使用される
– SetOp Intersect, Intersect All, Except, Except All
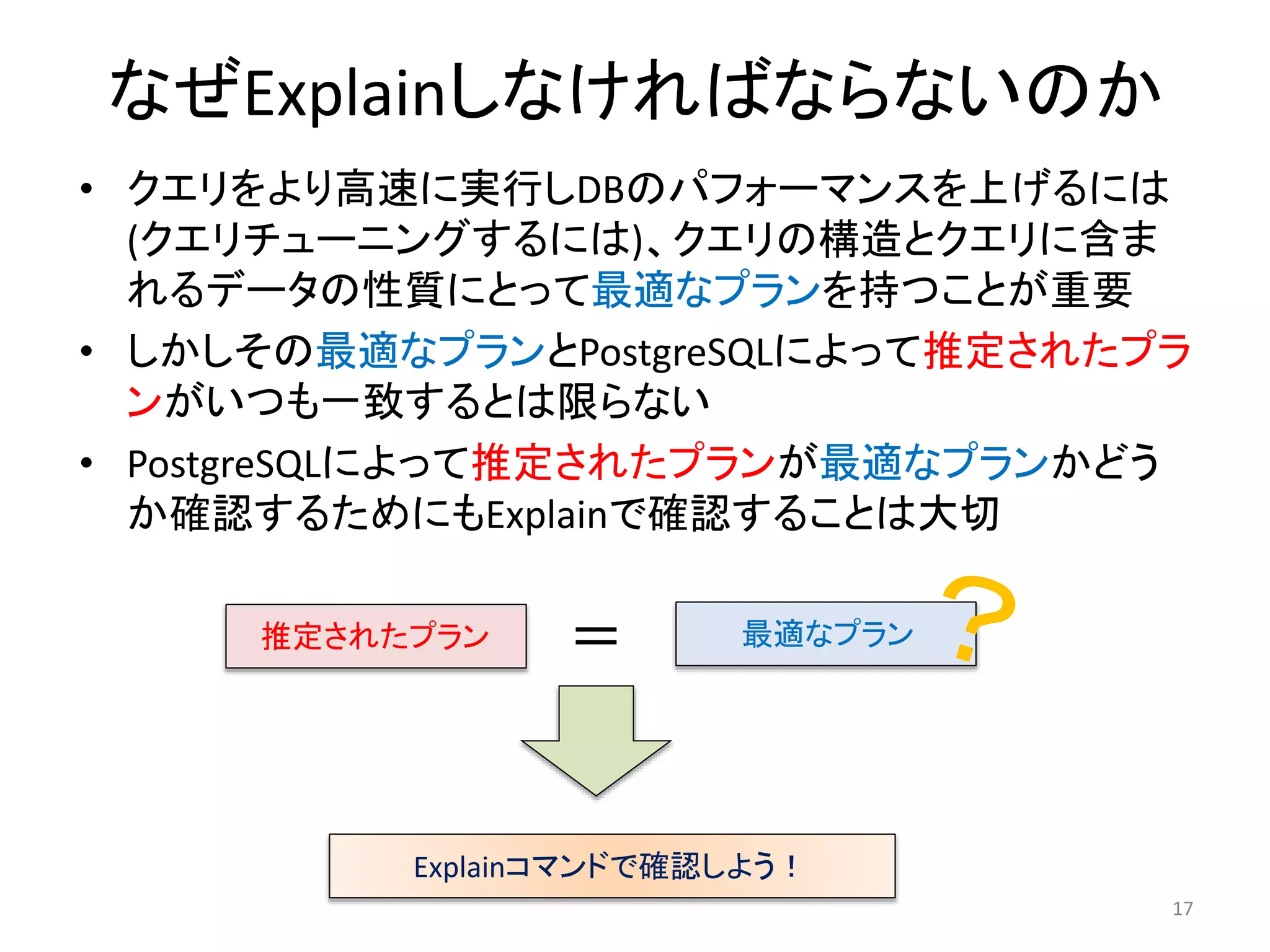
その前に
• どの問い合わせプランを選んでくれるかは基本的に
はPostgreSQL任せ
• プランナーは人より賢いのでむやみに強制しないほ
うが良い
• PostgreSQLコミュニティの考えも以下のよう
• We are not interested in implementing hints in the exact ways they are commonly
implemented on other databases. Proposals based on "because they've got them"
will not be welcomed. If you have an idea that avoids the problems that have been
observed with other hint systems, that could lead to valuable discussion.
• →他のDBにあるからなんて理由でPostgreSQLにヒント機能を持たせるのは歓迎し
ません。もし既存のヒント機能における問題点を避けれるようなアイデアがあるな
ら、そこで初めて議論しましょう。
• 他方では、プランナーは推測しかしない
– 統計情報を正しい状態に保つため定期的なANALYZEを。
66
pg_hint_planの実行例
=# EXPLAINSELECT aid FROM pgbench_accounts ;
QUERY PLAN
---------------------------------------------------------------------
- Index Only Scan using pgbench_accounts_pkey on pgbench_accounts
(cost=0.00..2384.26 rows=100000 width=4)
=# /*+ SeqScan(pgbench_accounts) */ explain select aid from
pgbench_accounts;
QUERY PLAN
---------------------------------------------------------------------
- Seq Scan on pgbench_accounts (cost=0.00..2588.00 rows=100000
width=4)
68
70
SETコマンドの実行例
=#EXPLAIN ANALYZE SELECT * FROM pg_class WHERE oid > 2112;
QUERY PLAN
------------------------------------------------
Seq Scan on pg_class
(cost=0.00..7.33 rows=62 width=164)
(actual time=0.087..1.700 rows=174 loops=1)
Filter: (oid > 2112::oid)
Total runtime: 2.413 ms
=# SET enable_seqscan = off;
=# EXPLAIN ANALYZE SELECT * ORDER BY pg_class WHERE oid > 2112;
QUERY PLAN
------------------------------------------------
Index Scan using pg_class_oid_index on pg_class
(cost=0.00..22.84 rows=62 width=164)
(actual time=0.144..1.802 rows=174 loops=1)
Index Cond: (oid > 2112::oid)
Total runtime: 2.653 ms
71.
71
Seq Scanの強制
=# EXPLAIN SELECT * FROM pg_class;
QUERY PLAN
-------------------------------------------------------
Seq Scan on pg_class
(cost=100000000.00..100000006.86 rows=186 width=164)
• 始動コストに100000000.0 を足すだけ
– /src/backend/optimizer/path/costsize.c
85
Function Scan演算子
=# CREATE FUNCTION foo(integer) RETURNS SETOF integer AS
$$
select $1;
$$
LANGUAGE sql;
=# EXPLAIN SELECT * FROM foo(12);
QUERY PLAN
------------------------------------------------------------
Function Scan on foo (cost=0.00..12.50 rows=1000 width=4)
• 関数がデータをgatherするときに出てくる
• トラブルシューティングの観点からは若干ミステリアス
• 関数の中で使われているクエリについてexplainを走らせるべき
86.
86
Unique 演算子
=# EXPLAIN SELECT distinct oid FROM pg_proc;
QUERY PLAN
--------------------------------------------------
Unique (cost=181.55..190.29 rows=1747 width=4)
-> Sort (cost=181.55..185.92 rows=1747 width=4)
Sort Key: oid
-> Seq Scan on pg_proc
(cost=0.00..87.47 rows=1747 width=4)
• 入力セットから重複する値を削除
• 行の並べ替えはせず、単に重複する行を取り除く
• 入力セットは予めソート済み(Sort演算子の後に行う)
• タプルコストごとに「CPU演算」×2
• DISTINCT とUNION で使用される
87.
87
Aggregate 演算子
=# EXPLAIN SELECT count(*) FROM pg_proc;
QUERY PLAN
--------------------------------------------------------------
Aggregate (cost=91.84..91.84 rows=1 width=0)
-> Seq Scan on pg_proc (cost=0.00..87.47 rows=1747 width=0)
• count, sum, min, max, avg, sttdev, varianceを使用
• GROUP BY 使用の場合差異が認められることがあり
=# EXPLAIN SELECT count(oid), oid FROM pg_proc GROUP BY oid;
QUERY PLAN
-------------------------------------------------------------
HashAggregate (cost=96.20..100.57 rows=1747 width=4)
-> Seq Scan on pg_proc (cost=0.00..87.47 rows=1747 width=4)
88.
Sort Key: oid
-> Seq Scan on pg_foo (cost=0.00..13520.54 rows=234654 width=4)
88
GroupAggregate 演算子
=# EXPLAIN SELECT count(*) FROM pg_foo GROUP BY oid;
QUERY PLAN
-----------------------------------------------------------------
GroupAggregate (cost=37442.53..39789.07 rows=234654 width=4)
-> Sort (cost=37442.53..38029.16 rows=234654 width=4)
• GROUP BYを使用し、より大きな結果セット上に集
約を行う












![一般的なデータ型のサイズについて
24
Explaining → Widths
=# EXPLAIN SELECT oid FROM pg_proc;
QUERY PLAN
------------------------------------------
Seq Scan on pg_proc
(cost=0.00..87.47 rows=1747 width=4)
• このレベルにおける推定さ
れた入力サイズを表示する。
• それほど重要ではない
smallint 2
integer 4
bigint 8
boolean 1
char(n) n+1
~
n+4
varchar(n)
text [ n文字]](https://image.slidesharecdn.com/postgresqlexplain-141014012101-conversion-gate02/75/PostgreSQL-Explain-24-2048.jpg)


































![このようなテーブルを用意
73
exception
exception_id
complete
exception_notice_map
exception_notice_map_id
exception_id
notice_id
[boolean]
SELECT exception_id FROM exception
JOIN exception_notice_map
USING (exception_id)
WHERE complete IS FALSE AND notice_id = 3;
インデックス
exception_id
部分インデックスcomplete=FALSE
全体の0.25%](https://image.slidesharecdn.com/postgresqlexplain-141014012101-conversion-gate02/75/PostgreSQL-Explain-73-2048.jpg)



































![[Cloud OnAir] BigQuery の仕組みからベストプラクティスまでのご紹介 2018年9月6日 放送](https://cdn.slidesharecdn.com/ss_thumbnails/dddddd-180906091548-thumbnail.jpg?width=640&height=640&fit=bounds)











![[よくわかるクラウドデータベース] Amazon RDS for PostgreSQL検証報告](https://cdn.slidesharecdn.com/ss_thumbnails/20140117rdsforpgsqlbenchreport-140216194106-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)

































