Download as PDF, PPTX









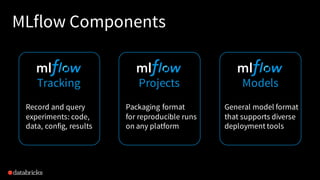
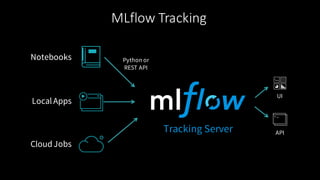



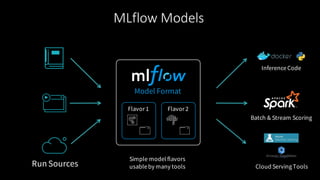











The document provides an overview of MLflow, an open-source platform designed to standardize and simplify the machine learning lifecycle across various tools and languages. It discusses the challenges in machine learning development, the design philosophy of MLflow, its modular components, and the roadmap for future improvements. The aim is to enhance usability for data scientists and integrate seamlessly into existing workflows.




















































































![Lect 1 Number systems and base conversions. [Autosaved].pptx](https://cdn.slidesharecdn.com/ss_thumbnails/lect1numbersystemsandbaseconversions-260111134109-67c2d865-thumbnail.jpg?width=640&height=640&fit=bounds)


